
>[success] # node 中常用的IO
Node.js 是一个基于事件驱动、非阻塞I/O模型的JavaScript运行时,因此在 Node.js 中,I/O 操作是非常重要的一部分。以下是 Node.js 中常用的 I/O 操作:
1. 文件 I/O:Node.js 提供了一组文件系统(fs)API,可以对文件进行读写操作,例如:读取文件、写入文件、创建目录和删除文件等。
2. 网络 I/O:Node.js 提供了一组网络 API,可以创建和管理网络连接,例如:创建 HTTP/HTTPS 服务器、创建 TCP/UDP 客户端等,还可以使用 Socket.IO 等库进行 WebSocket 编程。
3. 控制台 I/O:Node.js 提供了控制台输出 API,例如:console.log()、console.error() 等,可以在控制台输出日志信息。
4. 进程 I/O:Node.js 提供了一组进程 API,可以对进程进行管理,例如:创建子进程、发送信号等。
5. 事件 I/O:Node.js 是基于事件驱动的,因此事件 I/O 是非常重要的一部分。Node.js 提供了一组事件相关的 API,例如:EventEmitter、process.nextTick() 等。
>[success] # 理解node 中 I/O
`Node.js`的**I/O模型属于事件驱动和异步I/O模型**。这种设计使得 Node.js 可以通过事件驱动和异步 I/O 处理**大量并发连接或文件访问**。因此**非阻塞 I/O 的特性,使得它在处理高并发场景下具有很好的性能**。
`Node.js` 提供了多种 `API `来支持各种 I/O 操作,**包括文件系统操作,网络操作**等。由于 `Node.js`
[图片来自](https://juejin.cn/book/7171733571638738952/section/7172100279058300935)
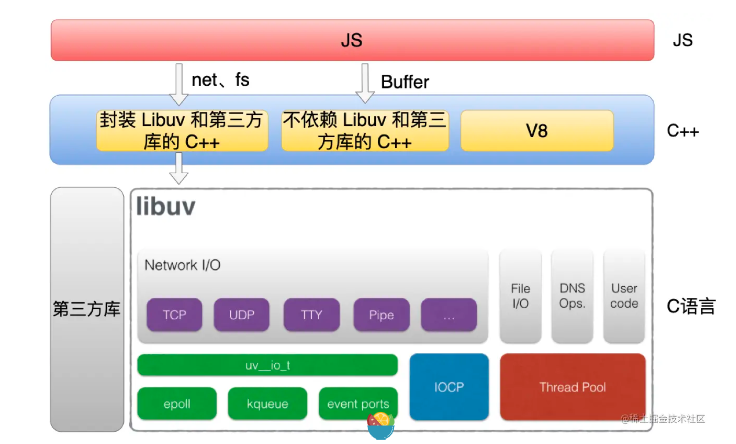
>[danger] ##### node 中异步I/O模型
在 `Node.js` 中,`I/O` 操作的实现方式是**异步非阻塞的模型**,即当发起一个` I/O `请求时,`Node.js` 并不会阻塞主线程的执行,而是将其放到一个专门的 `I/O` 线程中执行,**然后通过事件循环机制等待 I/O 线程完成操作,将结果返回给主线程进行后续处**
*****
不是说`js` 是单线程么,怎么出现了一个 `I/O` 线程?**node单线程是对我们观察而言。对底层可不是,只不过其他线程对你不开放的**,如果node真的只是单纯的单线程那么就变成**同步阻塞模型**,这种模型下的 I/O 操作会阻塞主线程的执行,直到 I/O 操作完成并返回结果后才能继续执行后面的代码。这种模型在高并发的情况下效率低下,容易导致系统瓶颈和响应延迟。
>[info] ## node 的事件循环机制
我们知道 JS 是单线程的(node并不是),如果线程池处理完一个任务之后,直接执行上层回调,上层代码就完全乱了。这时候就需要一个**异步通知的机制**,也就是说当一个线程处理完任务的时候,它不是直接去执行上程回调的,而是**通过异步机制去通知主线程来执行这个回调**
*****
在node 的I/O线程执行完的数据是怎么回到主线程。这个过程,I/O操作则委托给`libuv`库处理,`libuv`会将I/O操作分发到系统线程池中的线程中进行处理,当`I/O`操作完成时,线程会将结果通知到`libuv`,`libuv`再将结果通知到`JavaScript`线程,`JavaScript`线程再执行回调函数处理结果。**这个过程有点像发布订阅,将耗时的 I/O 操作交给其他线程或者线程池来完成,然后在主线程中继续执行其他任务,等到 I/O 操作完成后再通过回调函数或者事件来通知主线程获取返回结果**例如,如果是文件读取即读取的内容已经在I/O 线程执行获取完了
>[danger] ##### libuv
`libuv `是 Node.js 的一个重要的跨平台库,主要用于处理 I/O 操作、文件系统访问、网络操作、定时器等异步操作。它的作用在于提供一个事件循环机制,用于管理 Node.js 的异步操作,并支持在多个平台上的异步事件处理。libuv 采用非阻塞 I/O 的方式,可以支持 Node.js 处理大量并发连接或文件访问,从而保证了 Node.js 在处理高并发场景下的性能和稳定性。Node.js 中受到 libuv 的管理的事件,基本都是通过回调函数的方式来处理的。同时,libuv 还提供了线程池机制,**可以用于处理 CPU 密集型的任务,以减轻主线程的压力,从而避免造成阻塞。**
* 我们编写的JavaScript代码会经过V8引擎,再通过Node.js的Bindings,将任务放到Libuv的事件循环中;libuv(Unicorn Velociraptor—独角伶盗龙)是使用C语言编写的库;libuv提供了**事件循环、文件系统读写、网络IO、线程池**等等内容;在对应的线程位置(workThreads)处理对应的模块,处理完后将结果在(executecallback)在回到对应的事件队列中
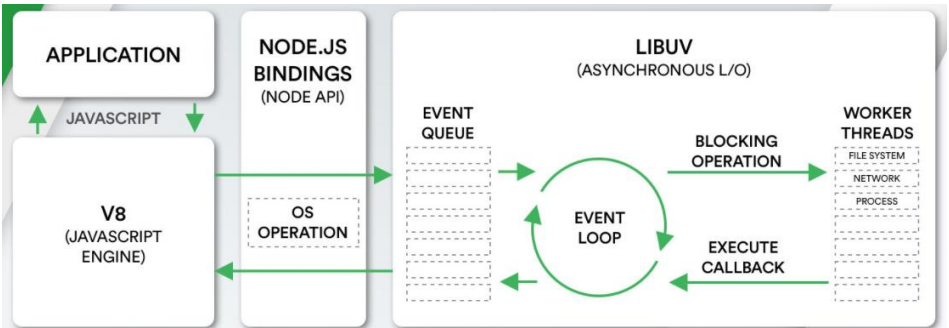
>[danger] ##### 浏览器中的事件循环机制
在浏览器中,JavaScript 代码是运行在主线程中的,如果执行一个耗时的 I/O 操作,比如发送 AJAX 请求,就会阻塞主线程,导致用户界面无响应或卡顿。
为了避免这个问题,浏览器的网络模块通常是运行在独立的线程中的,这个线程叫做网络线程(network thread)。当 JavaScript 代码调用异步 API 发起网络请求时,浏览器会将这个请求交给网络线程去处理,然后立即返回到 JavaScript 代码中执行下一行代码。网络线程会在后台执行这个 I/O 操作,等到 I/O 操作完成后,就会触发一个事件,告诉 JavaScript 代码请求已经完成,可以获取返回结果了。
由于 JavaScript 代码是运行在主线程中的,因此网络请求的结果不能直接返回给 JavaScript 代码,而是需要通过事件回调的方式来完成。当网络线程完成请求后,它会将请求结果传递给浏览器的主线程(也就是 JavaScript 线程),然后触发相应的事件,告诉 JavaScript 代码请求已经完成,可以获取返回结果了。这个过程是通过事件驱动来实现的。
>[danger] ##### 二者总结
[浏览器与Node的事件循环(Event Loop)有何区别? | Fundebug博客 - 一行代码搞定BUG监控 - 网站错误监控|JS错误监控|资源加载错误|网络请求错误|小程序错误监控|Java异常监控|监控报警|Source Map|用户行为|可视化重现](https://blog.fundebug.com/2019/01/15/diffrences-of-browser-and-node-in-event-loop/)
**Node.js 是通过 libuv 库来实现异步 I/O 操作和事件循环机制的,而浏览器是通过 Web API 实现异步操作**,同时也采用了事件循环机制来保证异步操作的高效执行。无论是在 Node.js 还是在浏览器中,事件循环机制都是实现异步编程的关键,通过将异步操作的回调函数注册到事件循环中,可以保证异步操作的非阻塞和高效执行。
>[danger] ##### 深入案例
当需要从数据库中查询数据并返回给客户端时,可以使用同步和异步两种方式来实现: 同步方式:
~~~javascript
javascriptCopy codeconst http = require('http');
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'password',
database: 'test'
});
const server = http.createServer((req, res) => {
const result = connection.query('SELECT * FROM users'); // 同步查询数据库
res.end(JSON.stringify(result)); // 返回结果给客户端
});
server.listen(3000, () => {
console.log('Server is running at http://localhost:3000');
});
~~~
在上面的代码中,使用了同步方式查询数据库,这会阻塞程序的执行,直到查询完成并返回结果。在查询期间,程序无法处理其他的请求,因此会导致程序的性能下降。 异步方式:
~~~javascript
javascriptCopy codeconst http = require('http');
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'password',
database: 'test'
});
const server = http.createServer((req, res) => {
connection.query('SELECT * FROM users', (err, result) => { // 异步查询数据库
if (err) {
return console.error(err);
}
res.end(JSON.stringify(result)); // 返回结果给客户端
});
});
server.listen(3000, () => {
console.log('Server is running at http://localhost:3000');
});
~~~
在上面的代码中,使用了异步方式查询数据库,这不会阻塞程序的执行,而是将查询操作放到一个队列中,然后立即返回结果给客户端。当查询完成后,会调用回调函数将查询结果返回给客户端。这种方式可以充分利用系统的资源,提高程序的性能和并发处理能力。
???????????
https://juejin.cn/post/7002106372200333319#heading-0
- 基础
- 什么是Node.js
- 理解 I/O 模型
- 理解node 中 I/O
- 对比node 和java 使用场景
- node 模块管理
- 内置模块 -- buffer
- 内置模块 -- fs
- fs -- 文件描述符
- fs -- 打开文件 api
- fs -- 文件读取 api
- fs -- 文件写入 api
- fs -- 创建目录 api
- fs -- 读取文件目录结构 api
- fs -- 文件状态(信息) api
- fs -- 删除文件/目录 api
- fs -- 重命名 api
- fs -- 复制文件 api
- 内置模块 -- events
- 内置模块 -- stream
- 可读流 -- Readable
- 可写流 -- Writable
- Duplex
- Transform
- 内置模块 -- http
- http -- 从客户端发起
- http -- 从服务端发起
- 内置模块 -- url
- 网络开发