### 前⾔
有⼈可能会问,为什么⼀定要⽤搜索引擎呢?我们的所有数据不是都可以放在数据库⾥吗?⽽且 Mysql,Oracle,SQL Server 等数据库⾥不是也能提供查询搜索功能,直接通过数据库查询不就可以了吗?
###
确实,我们⼤部分的查询功能都可以通过数据库查询获得,如果查询效率低下,还可以通过新建数据库索引,优化SQL等⽅式进⾏提升效率,甚⾄通过引⼊缓存⽐如redis,memcache来加快数据的返回速度。如果数据量更⼤,还可以通过分库分表来分担查询压⼒。那为什么还要全⽂搜索引擎呢?我们从⼏个⻆度来说。
###
### 数据类型
全⽂索引搜索很好的⽀持⾮结构化数据的搜索,可以更好地快速搜索⼤量存在的任何单词⾮结构化⽂本。例如Google,百度类的⽹站搜索,它们都是根据⽹⻚中的关键字⽣成索引,我们在搜索的时候输⼊关键字,它们会将该关键字即索引匹配到的所有⽹⻚返回;还有常⻅的项⽬中应⽤⽇志的搜索等等。对于这些⾮结构化的数据⽂本,关系型数据库搜索不是能很好的⽀持。
###
### 搜索性能
如果使⽤mysql做搜索,⽐如有个player表,这个表有user\_name这个字段,我们要查找出user\_name以james开头的球员,和含有James的球员。我们⼀般怎么做?数据量达到千万级别的时候怎么办?
`select * from player where user_name like 'james%';`
###
### 灵活的搜索
###
如果我们想查出名字叫james的球员,但是⽤户输⼊了jame,我们想提示他⼀些关键字
###
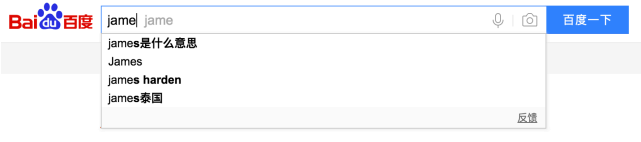
###
如果我们想查出带有"冠军"关键字的⽂章,但是⽤户输⼊了"总冠军",我们也希望能查出来。
###
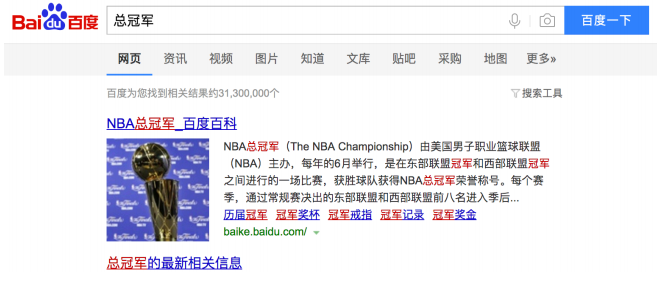
###
### 索引的维护
###
⼀般传统数据库,全⽂搜索都实现的很鸡肋,因为⼀般也没⼈⽤数据库存⻓⽂本字段,因为进⾏全⽂搜索的时候需要扫描整个表,如果数据量⼤的话即使对SQL的语法进⾏优化,也是效果甚微。即使建⽴了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
###
### 适合全⽂索引引擎的场景
1. 搜索的数据对象是⼤量的⾮结构化的⽂本数据。
3. ⽂本数据量达到数⼗万或数百万级别,甚⾄更多。
5. ⽀持⼤量基于交互式⽂本的查询。
7. 需求⾮常灵活的全⽂搜索查询。
9. 对安全事务,⾮⽂本数据操作的需求相对较少的情况。
- 基础概念
- 为什么不使用mysql做全文搜索
- 常见的搜索引擎
- 快速安装部署es
- 补充ES和kibana认证
- 补充kibana中文显示
- ES的目录以及核心概念介绍
- RESTful风格介绍
- 索引的各类操作
- 映射的各类操作
- 文档的各类操作
- 搜索的使用
- 中文分词器
- 常见字段类型
- kibana的安装
- es批量导入数据
- es的term的多种查询
- es的范围查询
- es的布尔查询
- es的排序查询
- es的指标聚合查询
- es的桶聚合查询
- es的别名操作
- es重建索引
- es的refresh操作
- es的高亮查询
- es的查询建议
- java实操es之集成
- 补充java操作es集成认证
- 补充java连接es集群
- java实操es之准备工作
- java实操es之各种骚操作(一期)
- java实战之数据库文件
- java实操es之各种骚操作(二期)
- java实操es之各种骚操作(三期)
- es分布式集群概念介绍
- es分布式集群的搭建
- es分布式集群kibana的配置
- es分布式集群分片管理
- es分布式集群节点健康管理
- es故障排查总结