

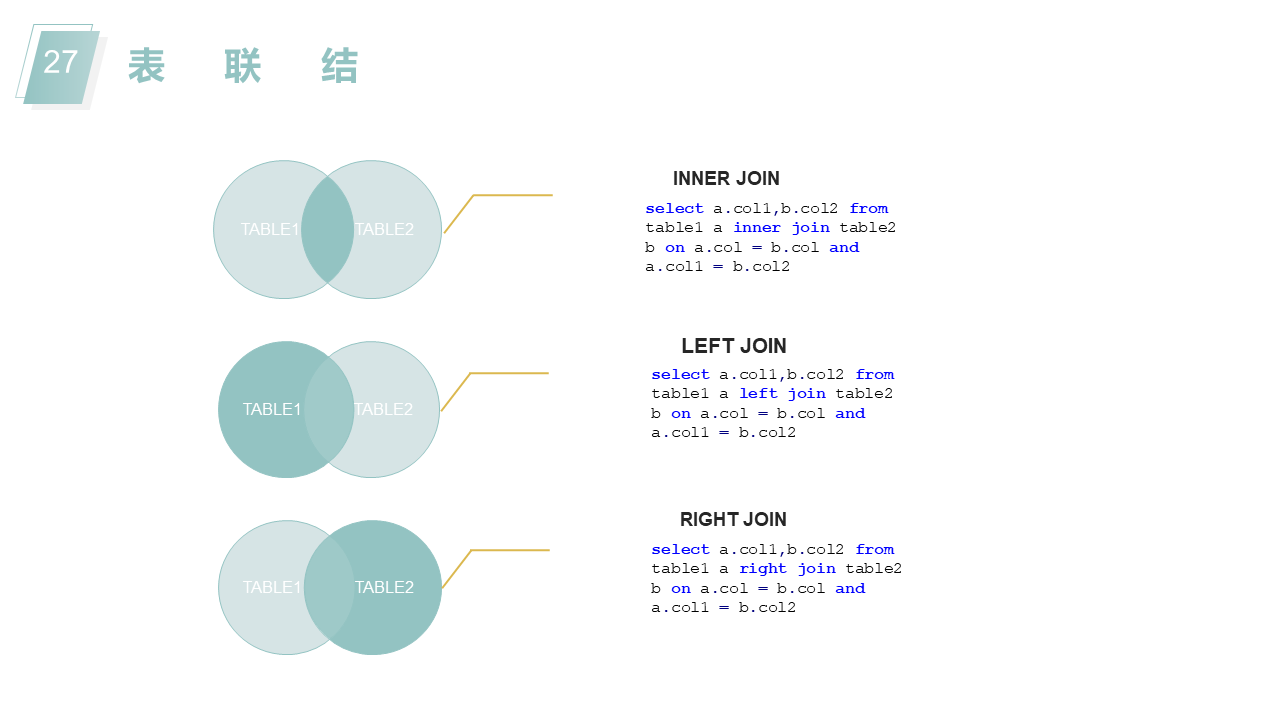
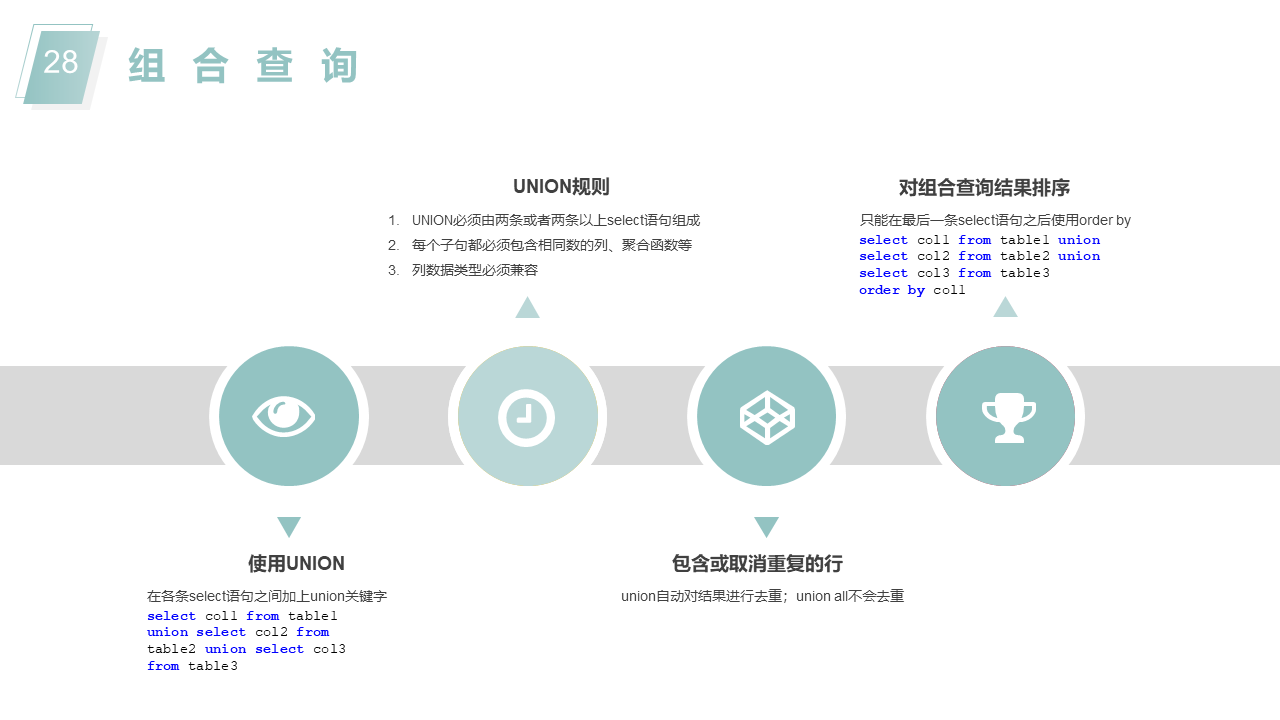

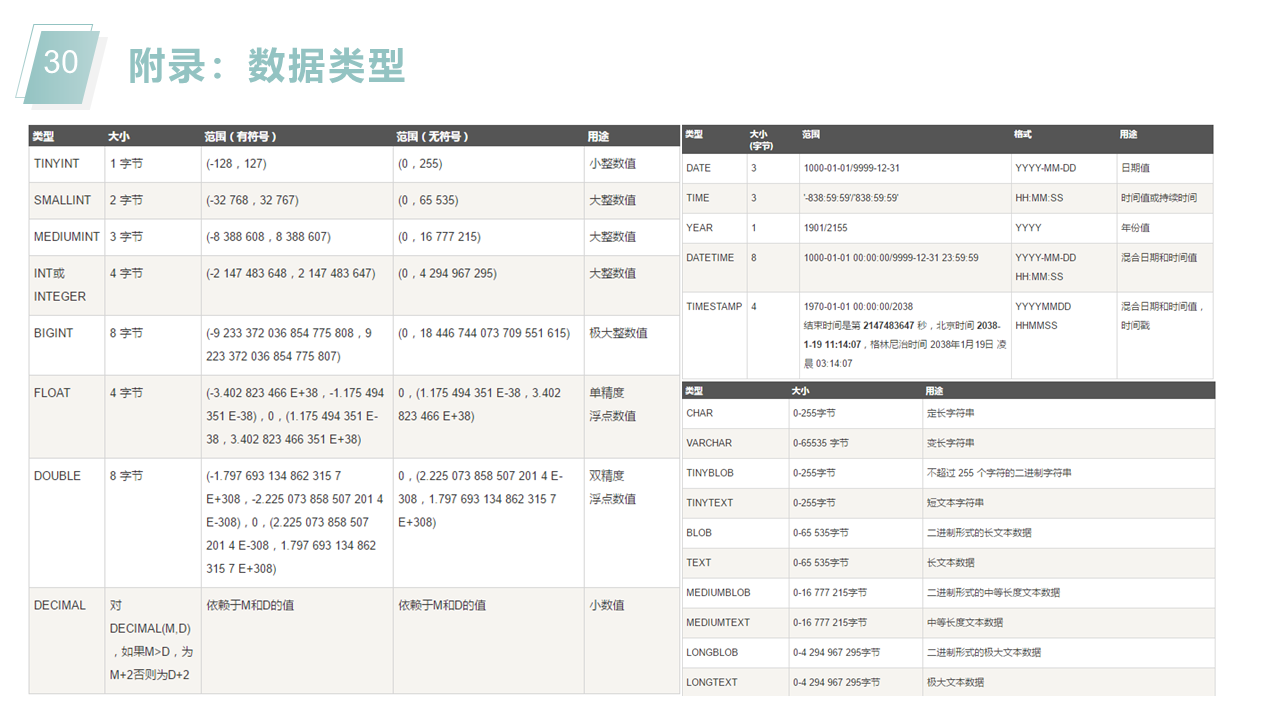

表名区分大小写
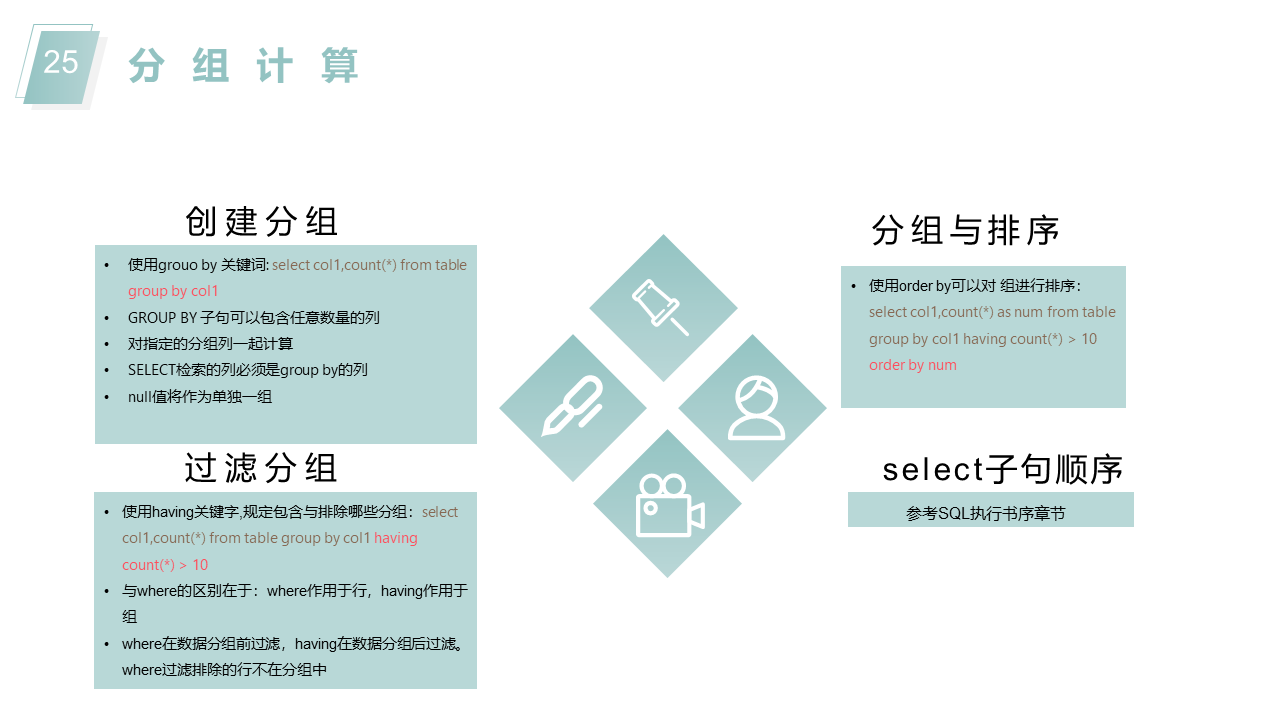
分组后,聚集函数作用于每个组。如avg和count
显示表中唯一值用group by的速度比用distinct的速度快。
having count(*) >10 的意思是筛选出组内条目数>10的组
having avg(*) > 50000,保留平均数 > 50000的组
