### 1.1.1. 生成器
列表生成器产生的列表很占用内存空间,我们每次在计算使用的时候都是对单个元素进行操作,这样其它元素占用的空间就白白浪费了。所以如果列表内的元素可以按照某种算法推算出来,这样我们就可以在循环过程中不断的推算下一个元素,从而避免创建完整的列表而占用大量内存。 在Python中我们把一边循环一边计算的的机制称为**生成器:generator.**
生成器类似于返回值为数组的一个函数,这个函数可以接受参数,可以被调用,但是,不同于一般的函数会一次性返回包括了所有数值的数组,生成器一次只能产生一个值,这样消耗的内存数量将大大减小,而且允许调用函数可以很快的处理前几个返回值,因此生成器看起来像是一个函数,但是表现得却像是迭代器

### 1.1.2. 迭代器
**迭代器 Iterator**
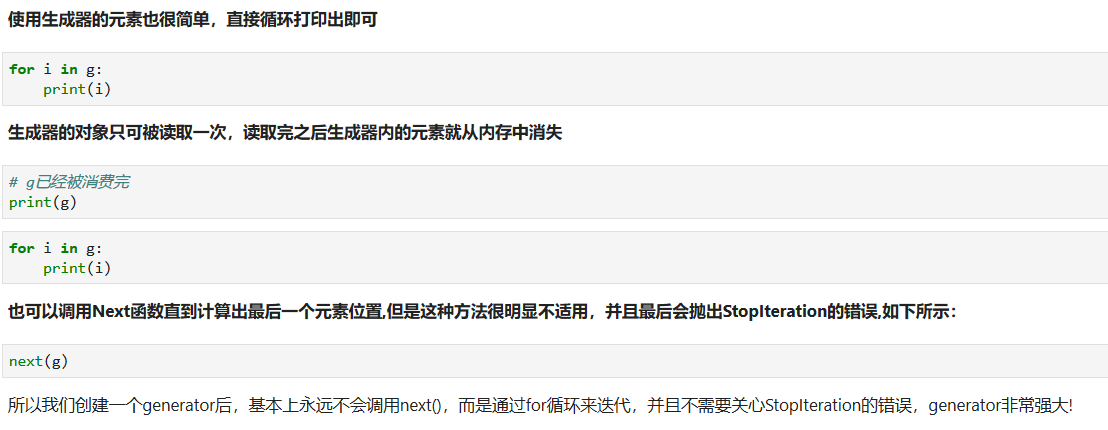
1. 迭代器包含有next方法的实现,在正确的范围内返回期待的数据以及超出范围后能够抛出StopIteration的错误停止迭代。
2. 我们已经知道,可以直接作用于for循环的数据类型有以下几种:
* 一类是集合数据类型,如list,tuple,dict,set,str等
* 一类是generator,包括生成器和带yield的generator function
这些可以直接作用于for 循环的对象统称为**可迭代对象:Iterable**
可以使用isinstance()判断一个对象是否为可Iterable对象
```
# 把list、dict、str等Iterable变成Iterator可以使用iter()函数:
a = [1,2,3,4]
iter_a = iter(a)
```
```
s='hello' #字符串是可迭代对象,但不是迭代器
l=[1,2,3,4] #列表是可迭代对象,但不是迭代器
t=(1,2,3) #元组是可迭代对象,但不是迭代器
d={'a':1} #字典是可迭代对象,但不是迭代器
set={1,2,3} #集合是可迭代对象,但不是迭代器
```
**为什么list、dict、str等数据类型不是Iterator?**
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
一个实现了iter方法和next方法的对象就是迭代器
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的

