
[TOC]
[推荐地址](https://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856896.html)
# 简短说明
` `Linux grep 命令用于查找文件里符合条件的字符串。
` `grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
## 语法
~~~
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
~~~
## 参数
**-a 或 --text** : 不要忽略二进制的数据。
**-A 或 --after-context=** : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
**-b 或 --byte-offset** : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
**-B 或 --before-context=** : 除了显示符合样式的那一行之外,并显示该行之前的内容。
**-c 或 --count** : 计算符合样式的列数。
**-C 或 --context=或-** : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
**-d 或 --directories=** : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
**-e 或 --regexp=** : 指定字符串做为查找文件内容的样式。
**-E 或 --extended-regexp** : 将样式为延伸的正则表达式来使用。
**-f 或 --file=** : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
* **-F 或 --fixed-regexp** : 将样式视为固定字符串的列表。
* **-G 或 --basic-regexp** : 将样式视为普通的表示法来使用。
* **-h 或 --no-filename** : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
* **-H 或 --with-filename** : 在显示符合样式的那一行之前,表示该行所属的文件名称。
* **-i 或 --ignore-case** : 忽略字符大小写的差别。
* **-l 或 --file-with-matches** : 列出文件内容符合指定的样式的文件名称。
* **-L 或 --files-without-match** : 列出文件内容不符合指定的样式的文件名称。
* **-n 或 --line-number** : 在显示符合样式的那一行之前,标示出该行的列数编号。
* **-o 或 --only-matching** : 只显示匹配PATTERN 部分。
* **-q 或 --quiet或--silent** : 不显示任何信息。
* **-r 或 --recursive** : 此参数的效果和指定"-d recurse"参数相同。
* **-s 或 --no-messages** : 不显示错误信息。
* **-v 或 --revert-match** : 显示不包含匹配文本的所有行。
* **-V 或 --version** : 显示版本信息。
* **-w 或 --word-regexp** : 只显示全字符合的列。
* **-x --line-regexp** : 只显示全列符合的列。
* **-y** : 此参数的效果和指定"-i"参数相同。
## 示例
1、在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
~~~
grep test *file
~~~
```
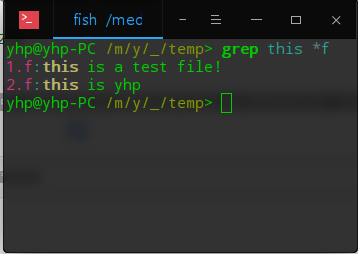
查找文件后缀为f的文件中含有this字符的字符串
yhp@yhp-PC /m/y/_/temp> grep this *f
1.f:this is a test file!
2.f:this is yhp
yhp@yhp-PC /m/y/_/temp>
```
```
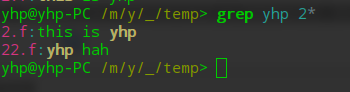
查找文件前缀含有2的文件中含有yhp字符串的行
yhp@yhp-PC /m/y/_/temp> grep yhp 2*
2.f:this is yhp
22.f:yhp hah
yhp@yhp-PC /m/y/_/temp>
```
2、以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串"update"的文件,并打印出该字符串所在行的内容,使用的命令为:
~~~
grep -r update /etc/acpi
~~~
输出结果如下:
~~~
$ grep -r update /etc/acpi #以递归的方式查找“etc/acpi”
#下包含“update”的文件
/etc/acpi/ac.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.)
Rather than
/etc/acpi/resume.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of
IO.) Rather than
/etc/acpi/events/thinkpad-cmos:action=/usr/sbin/thinkpad-keys--update
~~~
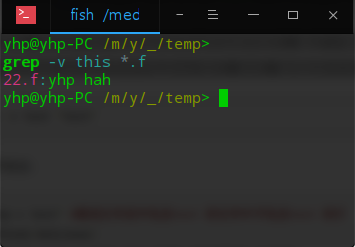
3、反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。
查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为:
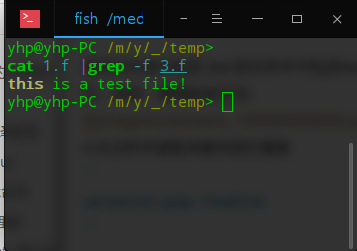
4.从文件中读取关键字进行搜索
```
cat test.txt | grep -f test2.txt
```
# 详解
## 简介
` `grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
` `Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
## grep常用用法
```
[root@www ~]# grep [-acinv] [--color=auto] '搜寻字符串' filename
选项与参数:
-a :将 binary 文件以 text 文件的方式搜寻数据
-c :计算找到 '搜寻字符串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!
--color=auto :可以将找到的关键词部分加上颜色的显示喔!
```
### 将/etc/passwd,有出现 root 的行取出来
```
# grep root /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
或
# cat /etc/passwd | grep root
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
```
### 将/etc/passwd,有出现 root 的行取出来,同时显示这些行在/etc/passwd的行号
```
# grep -n root /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
30:operator:x:11:0:operator:/root:/sbin/nologin
```
` `在关键字的显示方面,grep 可以使用 --color=auto 来将关键字部分使用颜色显示。 这可是个很不错的功能啊!但是如果每次使用 grep 都得要自行加上 --color=auto 又显的很麻烦~ 此时那个好用的 alias 就得来处理一下啦!你可以在 ~/.bashrc 内加上这行:『alias grep='grep --color=auto'』再以『 source ~/.bashrc 』来立即生效即可喔! 这样每次运行 grep 他都会自动帮你加上颜色显示啦
### 将/etc/passwd,将没有出现 root 的行取出来
~~~
# grep -v root /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
~~~
### 将/etc/passwd,将没有出现 root 和nologin的行取出来
~~~
# grep -v root /etc/passwd | grep -v nologin
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
~~~
### 用 dmesg 列出核心信息,再以 grep 找出内含 eth 那行,要将捉到的关键字显色,且加上行号来表示
~~~
[root@www ~]# dmesg | grep -n --color=auto 'eth'
247:eth0: RealTek RTL8139 at 0xee846000, 00:90:cc:a6:34:84, IRQ 10
248:eth0: Identified 8139 chip type 'RTL-8139C'
294:eth0: link up, 100Mbps, full-duplex, lpa 0xC5E1
305:eth0: no IPv6 routers present
# 你会发现除了 eth 会有特殊颜色来表示之外,最前面还有行号喔!
~~~
### 根据文件内容递归查找目录
```
# grep ‘energywise’ * #在当前目录搜索带'energywise'行的文件
# grep -r ‘energywise’ * #在当前目录及其子目录下搜索'energywise'行的文件
# grep -l -r ‘energywise’ * #在当前目录及其子目录下搜索'energywise'行的文件,但是不显示匹配的行,只显示匹配的文件
```
这几个命令很使用,是查找文件的利器。
## grep与正规表达式
**字符类**
字符类的搜索:如果我想要搜寻 test 或 taste 这两个单字时,可以发现到,其实她们有共通的 't?st' 存在~这个时候,我可以这样来搜寻:
~~~
[root@www ~]# grep -n 't[ae]st' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
~~~
其实 [] 里面不论有几个字节,他都谨代表某『一个』字节, 所以,上面的例子说明了,我需要的字串是『tast』或『test』两个字串而已!
字符类的反向选择 [^] :如果想要搜索到有 oo 的行,但不想要 oo 前面有 g,如下
~~~
[root@www ~]# grep -n '[^g]oo' regular_express.txt
2:apple is my favorite food.
3:Football game is not use feet only.
18:google is the best tools for search keyword.
19:goooooogle yes!
~~~
第 2,3 行没有疑问,因为 foo 与 Foo 均可被接受!
但是第 18 行明明有 google 的 goo 啊~别忘记了,因为该行后面出现了 tool 的 too 啊!所以该行也被列出来~ 也就是说, 18 行里面虽然出现了我们所不要的项目 (goo) 但是由於有需要的项目 (too) , 因此,是符合字串搜寻的喔!
至於第 19 行,同样的,因为 goooooogle 里面的 oo 前面可能是 o ,例如: go(ooo)oogle ,所以,这一行也是符合需求的!
字符类的连续:再来,假设我 oo 前面不想要有小写字节,所以,我可以这样写 [^abcd....z]oo , 但是这样似乎不怎么方便,由於小写字节的 ASCII 上编码的顺序是连续的, 因此,我们可以将之简化为底下这样:
~~~
[root@www ~]# grep -n '[^a-z]oo' regular_express.txt
3:Football game is not use feet only.
~~~
也就是说,当我们在一组集合字节中,如果该字节组是连续的,例如大写英文/小写英文/数字等等, 就可以使用[a-z],[A-Z],[0-9]等方式来书写,那么如果我们的要求字串是数字与英文呢? 呵呵!就将他全部写在一起,变成:[a-zA-Z0-9]。
我们要取得有数字的那一行,就这样:
~~~
[root@www ~]# grep -n '[0-9]' regular_express.txt
5:However, this dress is about $ 3183 dollars.
15:You are the best is mean you are the no. 1.
~~~
- 0 工具
- 0.1 图片无损放大
- 1 deepin系统
- 1.1 deepin系统安装
- 1.2 deepin创建desktop文件
- 1.3 浏览器运行虚拟机
- 1.4 linux的百度网盘突然打不
- 1.5 deepin安装后个人配置
- 1.5.1 安装公式编辑器AxMath
- 1.5.2 Deepin标题栏太高的解决办法(自定义高度)
- 1.5.3 linux下配置VS Code的标题栏风格
- 1.5.4 安装脚本解释器fish
- 1.6 关于软件安装
- 1.6.1 rpm和deb包想换转换的方法
- 1.7 deepin开机自启的设置方法
- 2 tiny core系统
- 2.1 安装系统到硬盘
- 2.2 系统软件安装介绍
- 2.3 安装控制台计算器bc
- 2.4 关机保存的方法
- 2.5 linux文件结构说明
- 2.6 为tinycore配置ssh
- 3 使用Linux中的一些技巧
- 3.1 软连接的使用
- 3.2 LInux下解压
- 3.3 删除操作
- 3.4 Zenity-在命令行和Shell脚本中创建图形(GTK +)对话框
- 3.4.1 列表框
- 3.4.2 口令对话框
- 3.4.3 消息对话框
- 3.4.3.1 信息对话框
- 3.4.3.2 错误框
- 3.4.3.3 问题对话框
- 3.4.3.4 警告对话框
- 3.4.4 范围对话框(滑条)
- 3.4.5 文件选择对话框
- 3.4.6 表单对话框
- 3.4.7 文本信息框
- 3.4.8 进度框
- 3.4.9 文本输入框
- 3.4.10 通知区域图标
- 3.4.11 日历对话框
- 3.4.12 颜色对话框
- 3.4.13 上述对话框测试文件
- 3.4.14 使用C++调用zenity
- 3.5 Linux whereis、find和locate命令
- 3.6 字体下载
- 3.7 使用Electron 创建跨平台的应用程序
- 3.8 shell的使用
- 3.8.1 $$,$?等表示什么
- 3.8.2 shell随机产生某一个范围内的整数
- 3.8.3 写shel脚本的一些使用操作
- 3.8.4 linux shell操作二进制文件
- 3.8.5 shell中的一些实用技巧
- 3.8.5.1 列出当前路径下的所有文件夹
- 3.8.5.2 列出当前路径下所有文件
- 3.8.5.3 获取当前虚拟终端的大小
- 3.8.5.4 判断输入字符串是否为数字
- 3.8.5.5 bash中的数学运算
- 3.8.5.6 按照文件创建时间顺序列出文件
- 3.8.5.7 echo输出含空格不换行的设置方法
- 3.8.5.8 find 递归/不递归 查找子目录的方法
- 3.8.5.9 echo显示颜色设置
- 3.8.5.10 bash中使用${}字符操作方法
- 3.8.5.11 ls查找目录,文件,软连接等的方法
- 3.8.5.12 检测某个程序是否在运行
- 3.8.5.13 bash/shell 解析命令行参数工具:getopts/getopt
- 3.8.5.14 获取脚本的绝对路径
- 3.8.6 使用bash写的脚本管理脚本
- 3.9 Linux创建自定义命令
- 3.10 deepin挂载远程文件夹到本地
- 3.11 linux root用户添加用户
- 3.12 实用脚本或者命令
- 3.12.1 命令行 将ppt转换为 pdf
- 3.12.2 deepin上实现自定义命令
- 4 slitaz系统
- 4.1 系统安装
- 4.2 安装软件命令tazpkg
- 4.3 使用说明
- 4.4 用 tazlito 构建 livecd自制linux系统
- 4.5 英文显示支持设置方法
- 4.6 配置ssh
- 5 busybox的编译使用
- 5.1 busybox介绍
- 5.2 busybox编译使用
- 6 配置自己的linux
- 6.1 在deepin上编译linux内核
- 7 每天一个linux命令
- 7.1 文件管理类
- 7.1.1 cat--接文件并打印到标准输出设备上
- 7.1.2 chattr--改变文件属性
- 7.1.3 chgrp--变更文件或目录的所属群组
- 7.1.4 chmod --控制文件如何被他人所调
- 7.1.5 chown命令--指定文件的拥有者改为指定的用户或组
- 7.1.6 grep命令--用于查找文件里符合条件的字符串
- 7.1.7 其他
- 7.2 文档编辑类
- 7.2.1 col--过滤控制字符
- 7.2.2 colrm--滤掉指定的行
- 7.2.3 comm --比较两个已排过序的文件
- 7.2.4 awk--一种处理文本文件的语言,是一个强大的文本分析工具
- 7.2.5 sed命令
- 7.3 文件传输类
- 7.3.1 prm--将一个工作由打印机贮列中移除
- 7.4 磁盘管理类
- 7.4.1 cd--切换当前工作目录至 dirName(目录参数)。
- 7.4.2 df--显示目前在Linux系统上的文件系统的磁盘使用情况统计
- 7.4.3 dirs--显示目录记录
- 7.4.5 du--显示目录或文件的大小
- 8 其他系统
- 8.1 Alpine Liunx
- 8.1.2 简介
- 8.1.2 本地安装
- 8.1.3 apk软件包管理
- 8.1.4 配置ssh