[TOC]
# :-: **RxJS框架介绍及使⽤详解**
# **概念**
**RxJS**是 **Reactive Extensions for JavaScript**的缩写,起源于 **Reactive Extensions**,是⼀个基于可观测数据流 **Stream**结合观察者模式和迭代器模式的⼀种异步编程的应⽤库。 **RxJS**是 **Reactive****Extensions**在 **JavaScript**上的实现。
注意!它跟 **React**没啥关系,笔者最初眼花把它看成了 **React.js**的缩写(耻辱啊!!!)
对于陌⽣的技术⽽⾔,我们⼀般的思路莫过于,打开百度(google),搜索,然后查看官⽅⽂档,或者从零散的博客当中,去找寻能够理解这项技术的信息。但在很多时候,仅从⼀些只⾔⽚语中,的确也很难真正了解到⼀门技术的来龙去脉。
本⽂将从学习的⾓度来解析这项技术具备的价值以及能给我们现有项⽬中带来的好处。
# **背景**
从开发者⾓度来看,对于任何⼀项技术⽽⾔,我们经常会去谈论的,莫过于以下⼏点:
* 应⽤场景?
* 如何落地?
* 上⼿难易程度如何?
* 为什么需要它?它解决了什么问题?
针对以上问题,我们可以由浅⼊深的来刨析⼀下 **RxJS**的相关理念。
# **应⽤场景?**
假设我们有这样⼀个需求:
我们上传⼀个⼤⽂件之后,需要实时监听他的进度,并且待进度进⾏到 100 的时候停⽌监听。
对于⼀般的做法我们可以采⽤短轮询的⽅式来实现,在对于异步请求的封装的时候,如果我们采⽤ **Promise**的⽅式,那么我们⼀般的做法就可以采⽤编写⼀个⽤于轮询的⽅法,获取返回值进⾏处理,如果进度没有完成则延迟⼀定时间再次调⽤该⽅法,同时在出现错误的时候需要捕获错误并处理。显然,这样的处理⽅式⽆疑在⼀定程度上给开发者带来了⼀定开发和维护成本,因为这个过程更像是我们在观察⼀个事件,这个事件会多次触发并让我感知到,不仅如此还要具备取消订阅的能⼒, **Promise**在处理这种事情时的⽅式其实并不友好,⽽ **RxJS**对于异步数据流的管理就更加符合这种范式。
引⽤尤⼤的话:
我个⼈倾向于在适合 **Rx**的地⽅⽤ **Rx**,但是不强求 **Rx for everything**。⽐较合适的例⼦就是⽐如多个服务端实时消息流,通过 **Rx**进⾏⾼阶处理,最后到 **view**层就是很清晰的⼀个 **Observable**,但是 **view**层本⾝处理⽤户事件依然可以沿⽤现有的范式。
# **如何落地?**
针对现有项⽬来说,如何与实际结合并保证原有项⽬的稳定性也的确是我们应该优先考虑的问题,毕竟任何⼀项技术如果⽆法落地实践,那么必然给我们带来的收益是⽐较有限的。
这⾥如果你是⼀名使⽤ **Angular**的开发者,或许你应该知道 **Angular**中深度集成了 **Rxjs**,只要你使⽤ **Angular**框架,你就不可避免的会接触到 RxJs 相关的知识。
在⼀些需要对事件进⾏更为精确控制的场景下,⽐如我们想要监听点击事件 (click event),但点击三次之后不再监听。
那么这个时候引⼊ **RxJS**进⾏功能开发是⼗分便利⽽有效的,让我们能省去对事件的监听并且记录点击的状态,以及需要处理取消监听的⼀些逻辑上的⼼理负担。
你也可以选择为你的⼤型项⽬引⼊ **RxJS**进⾏数据流的统⼀管理规范,当然也不要给本不适合 **RxJS**理念的场景强加使⽤,这样实际带来的效果可能并不明显。
# **上⼿难易程度如何?**
如果你是⼀名具备⼀定开发经验的 **JavaScript**开发者,那么⼏分钟或许你就能将 **RxJS**应⽤到⼀些简单的实践中了。
# **为什么需要它?它解决了什么问题?**
如果你是⼀名使⽤ **JavaScript**的开发者,在⾯对众多的事件处理,以及复杂的数据解析转化时,是否常常容易写出⼗分低效的代码或者是臃肿的判断以及⼤量脏逻辑语句?
不仅如此,在 **JavaScript**的世界⾥,就众多处理异步事件的场景中来看,“⿇烦” 两个字似乎经常容易被提起,我们可以先从 **JS**的异步事件的处理⽅式发展史中来细细品味 **RxJS**带来的价值。

# **回调函数时代(callback)**
使⽤场景:
* 事件回调
* **Ajax**请求
* **Node API**
* **setTimeout**、 **setInterval**等异步事件回调
在上述场景中,我们最开始的处理⽅式就是在函数调⽤时传⼊⼀个回调函数,在同步或者异步事件完成之后,执⾏该回调函数。可以说在⼤部分简单场景下,采⽤回调函数的写法⽆疑是很⽅便的,⽐如我们熟知的⼏个⾼阶函数:
* **forEach**
* **map**
* **filter**
```
[1, 2, 3].forEach(function (item, index) { console.log(item, index);})
```
他们的使⽤⽅式只需要我们传⼊⼀个回调函数即可完成对⼀组数据的批量处理,很⽅便也很清晰明了。
但在⼀些复杂业务的处理中,我们如果仍然秉持不抛弃不放弃的想法顽强的使⽤回调函数的⽅式就可能会出现下⾯的情况:
```
fs.readFile('a.txt', 'utf-8', function(err, data)
{fs.readFile('b.txt', 'utf-8', function(err, data1)
{fs.readFile('c.txt', 'utf-8', function(err, data2) {
})
})
})
```
当然作为编写者来说,你可能觉得说这个很清晰啊,没啥不好的。但是如果再复杂点呢,如果调⽤的函数都不⼀样呢,如果每⼀个回调⾥⾯的内容都⼗分复杂呢。短期内⾃⼰可能清楚为什么这么写,⽬的是什么,但是过了⼀个⽉、三个⽉、⼀年后,你确定在众多业务代码中你还能找回当初的本⼼吗?
你会不会迫不及待的查找提交记录,这是哪个憨批写的,跟**shit** ,卧槽怎么是我写的。
这时候,⾯对众多开发者苦不堪⾔的 回调地域,终于还是有⼈出来造福⼈类了......
# **Promise 时 代**
**Promise**最初是由社区提出(毕竟作为每天与奇奇怪怪的业务代码打交道的我们来说,⼀直⽤回调顶不住了啊),后来官⽅正式在 **ES6**中将其加⼊语⾔标准,并进⾏了统⼀规范,让我们能够原⽣就能 **new**⼀个 **Promise**。
就优势⽽⾔, **Promise**带来了与回调函数不⼀样的编码⽅式,它采⽤链式调⽤,将数据⼀层⼀层往后抛,并且能够进⾏统⼀的异常捕获,不像使⽤回调函数就直接炸了,还得在众多的代码中⼀个个 **try catch**。
话不多说,看码!
```
function readData(filePath) {
return new Promise((resolve, reject) => {
fs.readFile(filePath, 'utf-8', (err, data) => {
if (err) reject(err); resolve(data);
})
});
}
readData('a.txt').then(res => {
return readData('b.txt');
}).then(res => {
return readData('c.txt');
}).then(res => {
return readData('d.txt');
}).catch(err => {
console.log(err);
})
```
对⽐⼀下,这种写法会不会就更加符合我们正常的思维逻辑了,这种顺序下,让⼈看上去⼗分舒畅,也更利于代码的维护。
优点:
* 状态改变就不会再变,任何时候都能得到相同的结果
* 将异步事件的处理流程化,写法更⽅便
缺点:
* ⽆法取消
* 错误⽆法被 **try****catch**(但是可以使⽤ **.catch**⽅式)
* **pending**状态时⽆法得知现在处在什么阶段
虽然 **Promise**的出现在⼀定程度上提⾼了我们处理异步事件的效率,但是在需要与⼀些同步事件的进⾏混合处理时往往我们还需要⾯临⼀些并不太友好的代码迁移,我们需要把原本放置在外层的代码移到 **Promise**的内部才能保证某异步事件完成之后再进⾏继续执⾏。
# **Generator 函 数**
**ES6**新引⼊了 **Generator**函数,可以通过 **yield**关键字,把函数的执⾏流挂起,为改变执⾏流程提供了可能,从⽽为异步编程提供解决⽅案。形式上也是⼀个普通函数,但有⼏个显著的特征:
* **function**关键字与函数名之间有⼀个星号 "\*" (推荐紧挨着 **function**关键字)
* **yield·** 表达式,定义不同的内部状态(可以有多个yield`)
* **Generator**函数并不会执⾏,也不会返回运⾏结果,⽽是返回⼀个遍历器对象( **Iterator Object**)
* 依次调⽤遍历器对象的 **next**⽅法,遍历 **Generator**函数内部的每⼀个状态
```
function read(){
let a= yield '666';
console.log(a);
let b = yield 'ass';
console.log(b); return 2
}
let it = read();
console.log(it.next());
console.log(it.next());
console.log(it.next());
console.log(it.next());
```
这种模式的写法我们可以⾃由的控制函数的执⾏机制,在需要的时候再让函数执⾏,但是对于⽇常项⽬中来说,这种写法也是不够友好的,⽆法给与使⽤者最直观的感受。
# **async / await**
相信在经过许多⾯试题的洗礼后,⼤家或多或少应该也知道这玩意其实就是⼀个语法糖,内部就是把 **Generator**函数与⾃动执⾏器 **co**进⾏了结合, 让我们能以同步的⽅式编写异步代码,⼗分畅快。
有⼀说⼀,这玩意着实好⽤,要不是要考虑兼容性,真就想⼤⾯积使⽤这种⽅式。 再来看看⽤它编写的代码有多快乐:
```
async readFileData() {
const data = await Promise.all([
'异步事件⼀',
'异步事件⼆',
'异步事件三'
]);
console.log(data);
}
```
直接把它当作同步⽅式来写,完全不要考虑把⼀堆代码复制粘贴的⼀个其他异步函数内部,属实简洁明了。
# **RxJS**
它在使⽤⽅式上,跟 **Promise**有点像,但在能⼒上⽐ **Promise**强⼤多了,不仅仅能够以流的形式对数据进⾏控制,还内置许许多多的内置⼯具⽅法让我们能⼗分⽅便的处理各种数据层⾯的操作,让我们的代码如丝⼀般顺滑。
优势:
* 代码量的⼤幅度减少
* 代码可读性的提⾼
* 很好的处理异步
* 事件管理、调度引擎
* ⼗分丰富的操作符
* 声明式的编程风格
```
function readData(filePath) {
return new Observable((observer) => {
fs.readFile(filePath, 'utf-8', (err, data) => {
if (err) observer.error(err);
observer.next(data);
})
});
}
Rx.Observable
.forkJoin(readData('a.txt'),
readData('b.txt'),
readData('c.txt'))
.subscribe(data => console.log(data));
```
这⾥展⽰的仅仅是 **RxJS**能表达能量的冰⼭⼀⾓,对于这种场景的处理办法还有多种⽅式。 **RxJS**擅长处理异步数据流,⽽且具有丰富的库函数。对于 **RxJS**⽽⾔,他能将任意的 **Dom**事件,或者是 **Promise**转换成 **observables**。
## **前置知识点**
在正式进⼊ **RxJS**的世界之前,我们⾸先需要明确和了解⼏个概念:
* 响应式编程( **Reactive Programming**) 流( **Stream**)
* 观察者模式(发布订阅)
* 迭代器模式
## **响应式编程(Reactive Programming)**
响应式编程( **Reactive Programming**),它是⼀种基于事件的模型。在上⾯的异步编程模式中,我们描述了两种获得上⼀个任务执⾏结果的⽅式,
⼀个就是主动轮训,我们把它称为 **Proactive**⽅式。另⼀个就是被动接收反馈,我们称为 **Reactive**。简单来说,在 **Reactive**⽅式中,上⼀个任务的结果的反馈就是⼀个事件,这个事件的到来将会触发下⼀个任务的执⾏。
响应式编程的思路⼤概如下:你可以⽤包括 **Click**和 **Hover**事件在内的任何东西创建 **Data stream**(也称 “流”,后续章节详述)。 **Stream**廉价且常见,任何东西都可以是⼀个 **Stream**:变量、⽤户输⼊、属性、 **Cache**、数据结构等等。举个例⼦,想像⼀下你的 **Twitter feed**就像是**Click events**那样的 **Data stream**,你可以监听它并相应的作出响应。
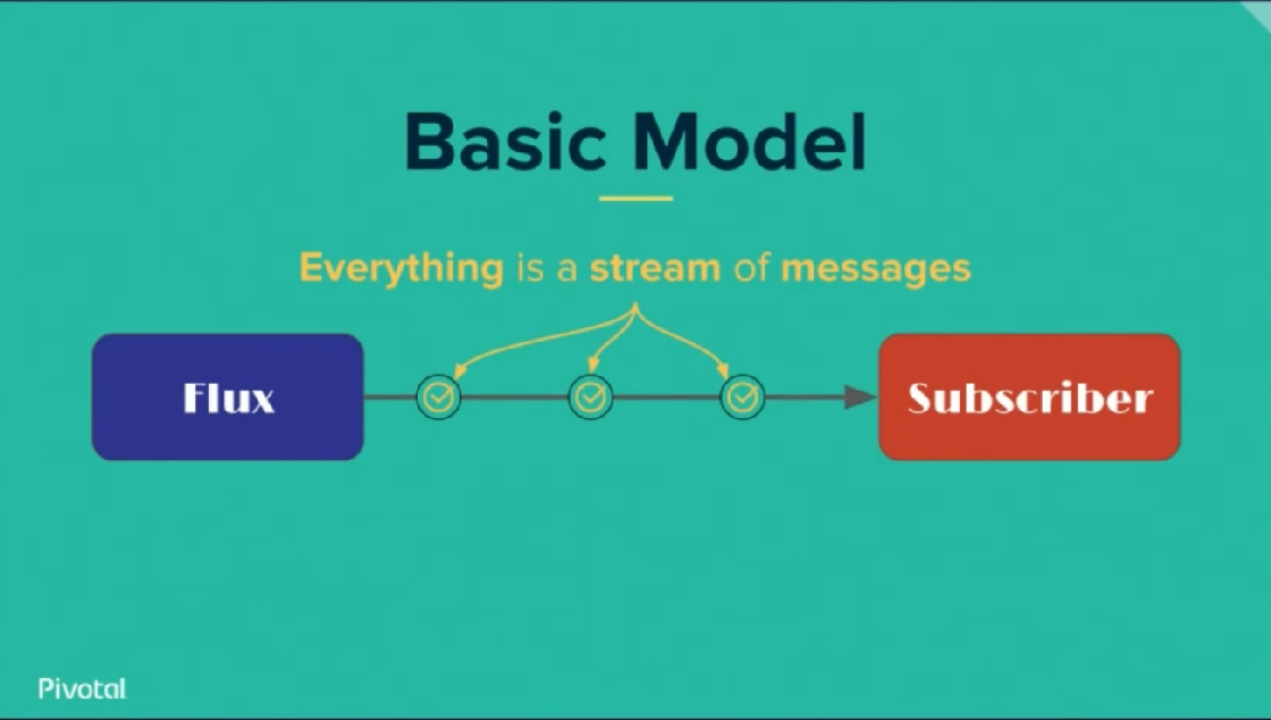
结合实际,如果你使⽤过 **Vue**,必然能够第⼀时间想到, **Vue**的设计理念不也是⼀种响应式编程范式么,我们在编写代码的过程中,只需要关注数据的变化,不必⼿动去操作视图改变,这种 **Dom**层的修改将随着相关数据的改变⽽⾃动改变并重新渲染。
**流(** **Stream** **)**
流作为概念应该是语⾔⽆关的。⽂件 **IO**流, **Unix**系统标准输⼊输出流,标准错误流 ( **stdin**, **stdout**, **stderr**),还有⼀开始提到的 **TCP**流,还有⼀些 **Web**后台技术(如 **Nodejs**)对 **HTTP**请求 / 响应流的抽象,都可以见到流的概念。作为响应式编程的核⼼,流的本质是⼀个按时间顺序排列的进⾏中事件的序列集合。
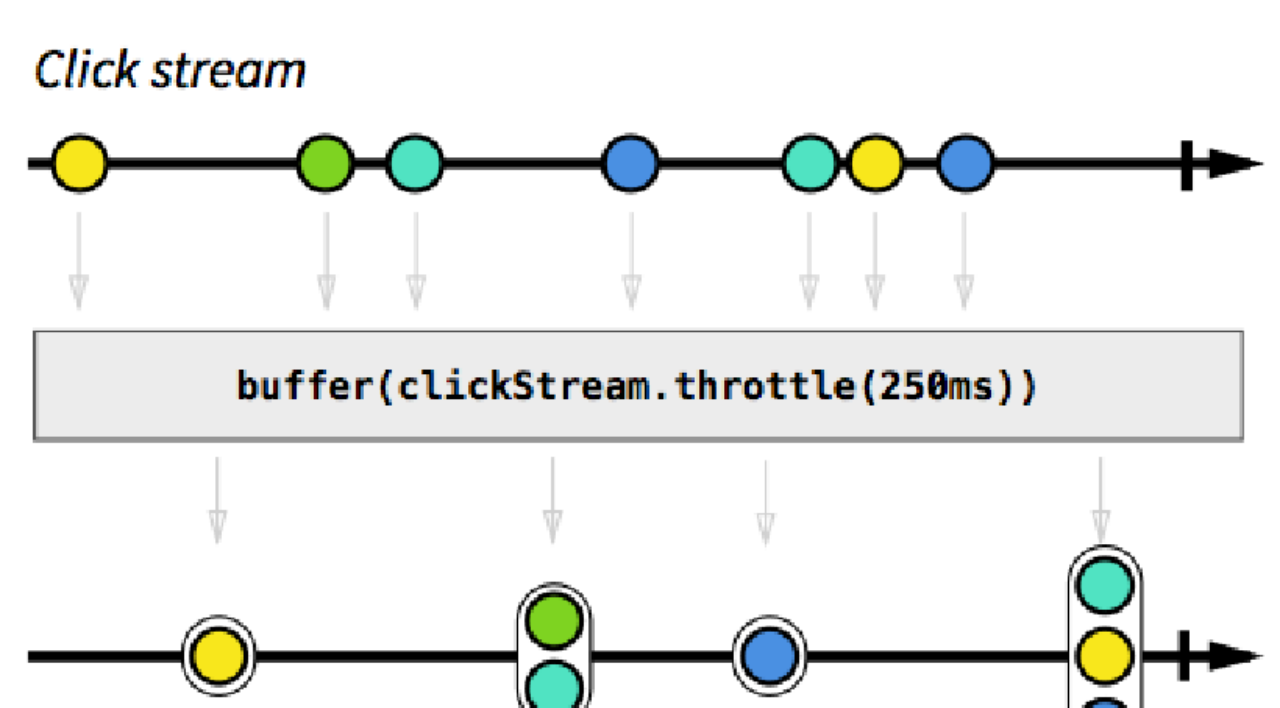
对于⼀流或多个流来说,我们可以对他们进⾏转化,合并等操作,⽣成⼀个新的流,在这个过程中,流是不可改变的,也就是只会在原来的基础返回⼀个新的 **stream**。
## **观察者模式**
在众多设计模式中,观察者模式可以说是在很多场景下都有着⽐较明显的作⽤。
观察者模式是⼀种⾏为设计模式,允许你定义⼀种订阅机制, 可在对象事件发⽣时通知多个 “观察” 该对象的其他对象。
⽤实际的例⼦来理解,就⽐如你订了⼀个银⾏卡余额变化短信通知的服务,那么这个时候,每次只要你转账或者是购买商品在使⽤这张银⾏卡消费之后,银⾏的系统就会给你推送⼀条短信,通知你消费了多少多少钱,这种其实就是⼀种观察者模式,⼜称发布 - 订阅模式。
在这个过程中,银⾏卡余额就是被观察的对象,⽽⽤户就是观察者。
优点:
* 降低了⽬标与观察者之间的耦合关系,两者之间是抽象耦合关系。
* 符合依赖倒置原则。
* ⽬标与观察者之间建⽴了⼀套触发机制。
* ⽀持⼴播通信
不⾜:
* ⽬标与观察者之间的依赖关系并没有完全解除,⽽且有可能出现循环引⽤。
* 当观察者对象很多时,通知的发布会花费很多时间,影响程序的效率。
## **迭代器模式**
迭代器( **Iterator**)模式⼜叫游标( **Sursor**)模式,在⾯向对象编程⾥,迭代器模式是⼀种设计模式,是⼀种最简单也最常见的设计模式。迭代器模式可以把迭代的过程从从业务逻辑中分离出来,它可以让⽤户透过特定的接⼝巡访容器中的每⼀个元素⽽不⽤了解底层的实现。

```
const iterable = [1, 2, 3];
const iterator = iterable[Symbol.iterator]();
iterator.next();
iterator.next();
iterator.next();
iterator.next();
```
作为前端开发者来说,我们最常遇到的部署了 **iterator**接⼝的数据结构不乏有: **Map**、 **Set**、 **Array**、类数组等等,我们在使⽤他们的过程中,均能使⽤同⼀个接⼝访问每个元素就是运⽤了迭代器模式。
**Iterator**作⽤:
* 为各种数据结构,提供⼀个统⼀的、简便的访问接⼝;
* 使得数据结构的成员能够按某种次序排列;
* 为新的遍历语法 **for...of**实现循环遍历
在许多⽂章中,有⼈会喜欢把迭代器和遍历器混在⼀起进⾏概念解析,其实他们表达的含义是⼀致的,或者可以说(迭代器等于遍历器)。
## **Observable**
表⽰⼀个概念,这个概念是⼀个可调⽤的未来值或事件的集合。它能被多个 **observer**订阅,每个订阅关系相互独⽴、互不影响。
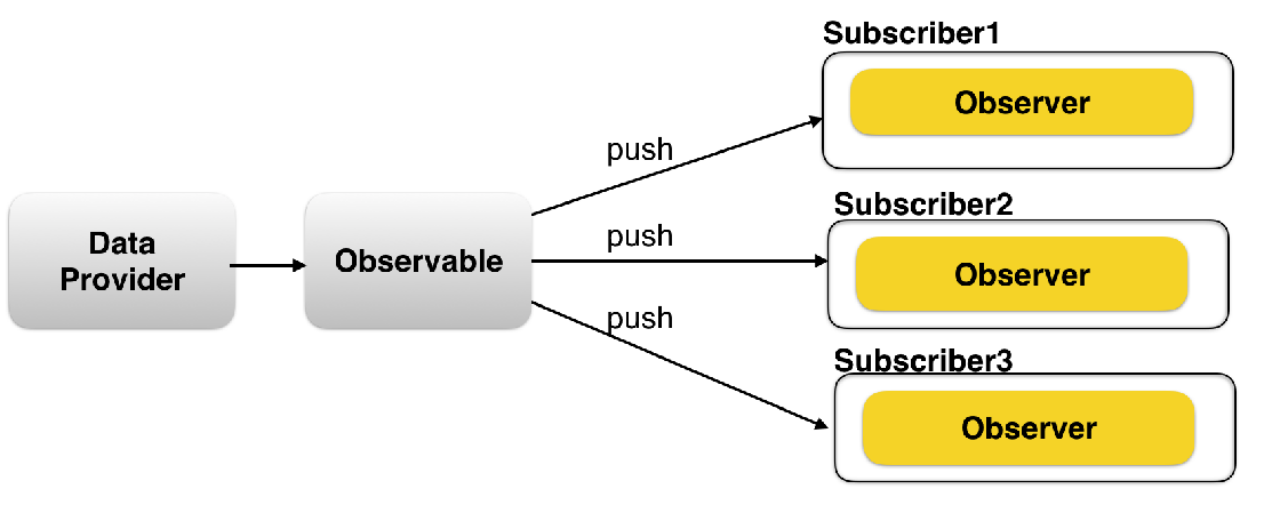
举个栗⼦:
假设你订阅了⼀个博客或者是推送⽂章的服务号(微信公众号之类的),之后只要公众号更新了新的内容,那么该公众号就会把新的⽂章推送给你,在这段关系中,这个公众号就是⼀个 **Observable**,⽤来产⽣数据的数据源。
相信看完上⾯的描述,你应该对 **Observable**是个什么东西有了⼀定的了解了,那么这就好办了,下⾯我们来看看在 **RxJS**中如何创建⼀个 **Observable**。
```
const Rx = require('rxjs/Rx')
const myObservable = Rx.Observable.create(observer =>
{ observer.next('foo');
setTimeout(() => observer.next('bar'), 1000);
});
```
我们可以调⽤ **Observable.create**⽅法来创建⼀个 **Observable**,这个⽅法接受⼀个函数作为参数,这个函数叫做 **producer**函数, ⽤来⽣成
**Observable**的值。这个函数的⼊参是 **observer**,在函数内部通过调⽤ **observer.next()**便可⽣成有⼀系列值的⼀个 **Observable**。
我们先不应理会 **observer**是个什么东西,从创建⼀个 **Observable**的⽅式来看,其实也就是调⽤⼀个 **API**的事,⼗分简单,这样⼀个简单的 **Observable**对象就创建出来了。
## **Observer**
⼀个回调函数的集合,它知道如何去监听由 **Observable**提供的值。 **Observer**在信号流中是⼀个观察者(哨兵)的⾓⾊,它负责观察任务执⾏的状态并向流中发射信号。
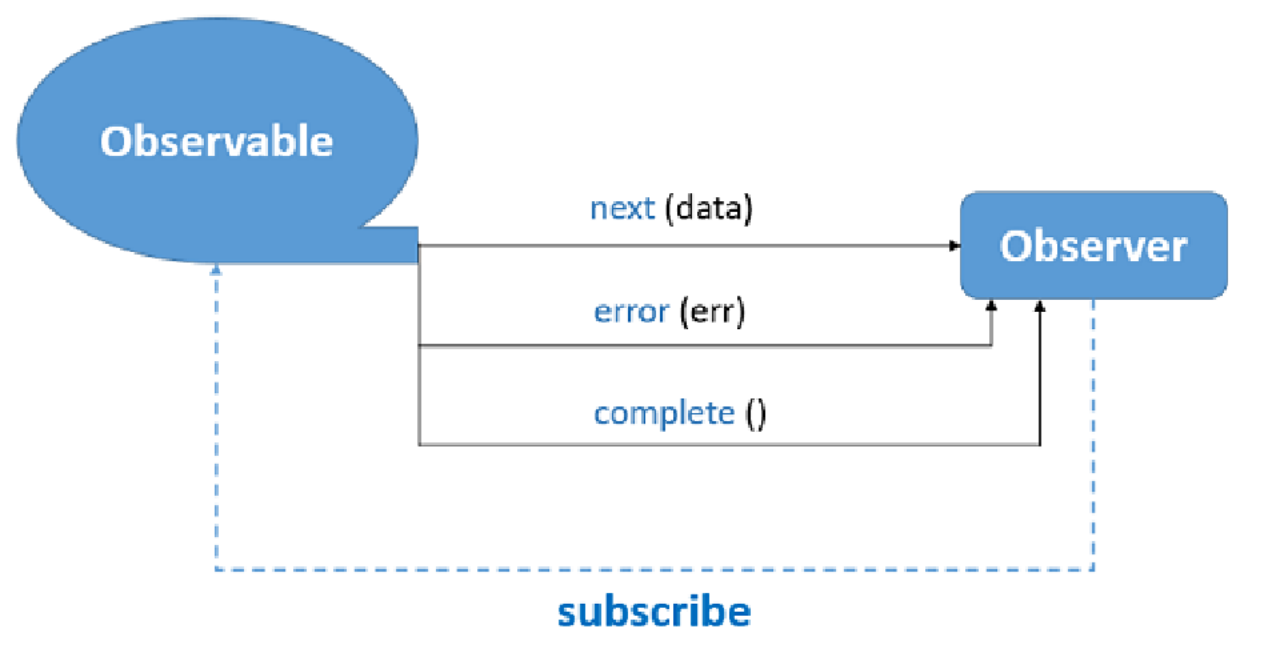
这⾥我们简单实现⼀下内部的构造:
```
const observer = {
next: function(value) {
console.log(value);
},
error: function(error) {
console.log(error)
},
complete: function() {
console.log('complete')
}
}
```
在 **RxJS**中, **Observer**是可选的。在 **next**、 **error**和 **complete**处理逻辑部分缺失的情况下, **Observable**仍然能正常运⾏,为包含的特定通知类型的处理逻辑会被⾃动忽略。
⽐如我们可以这样定义:
```
const observer = {
next: function(value) {
console.log(value);
},
error: function(error) {
console.log(error)
}
}
```
它依旧是可以正常的运⾏。
那么它⼜是怎么来配合我们在实际战⽃中使⽤的呢:
```
const myObservable = Rx.Observable.create((observer) =>
{observer.next('111')
setTimeout(() => {
observer.next('777')
}, 3000)
})
myObservable.subscribe((text) => console.log(text));
```
这⾥直接使⽤ **subscribe**⽅法让⼀个 **observer**订阅⼀个 **Observable**,我们可以看看这个 **subscribe**的函数定义来看看怎么实现订阅的:
```
subscribe(next?: (value: T) => void, error?: (error: any) => void, complete?: () => void): Subscription;
```
源码是⽤ **ts**写的,代码即⽂档,⼗分清晰,这⾥笔者给⼤家解读⼀下,我们从⼊参来看,从左⾄右依次是 **next**、 **error**, **complete**,且是可选的, 我们可以⾃⼰选择性的传⼊相关回调,从这⾥也就印证了我们上⾯所说 **next**、 **error**和 **complete**处理逻辑部分缺失的情况下仍可以正常运⾏,因为他们都是可选的。
## **Subscription 与 Subject**
### **Subscription**
**Subscription**就是表⽰ **Observable**的执⾏,可以被清理。这个对象最常⽤的⽅法就是 **unsubscribe**⽅法,它不需要任何参数,只是⽤来清理由 **Subscription**占⽤的资源。同时,它还有 **add**⽅法可以使我们取消多个订阅。
```
const myObservable = Rx.Observable.create(observer =>
{ observer.next('foo');
setTimeout(() =>
observer.next('bar'), 1000);
});
const subscription = myObservable.subscribe(x => console.log(x)); subscription.unsubscribe();
```
### **Subject ( 主体)**
它是⼀个代理对象,既是⼀个 **Observable**⼜是⼀个 **Observer**,它可以同时接受 **Observable**发射出的数据,也可以向订阅了它的 **observer**发射数据,同时, **Subject**会对内部的 **observers**清单进⾏多播 ( **multicast**)
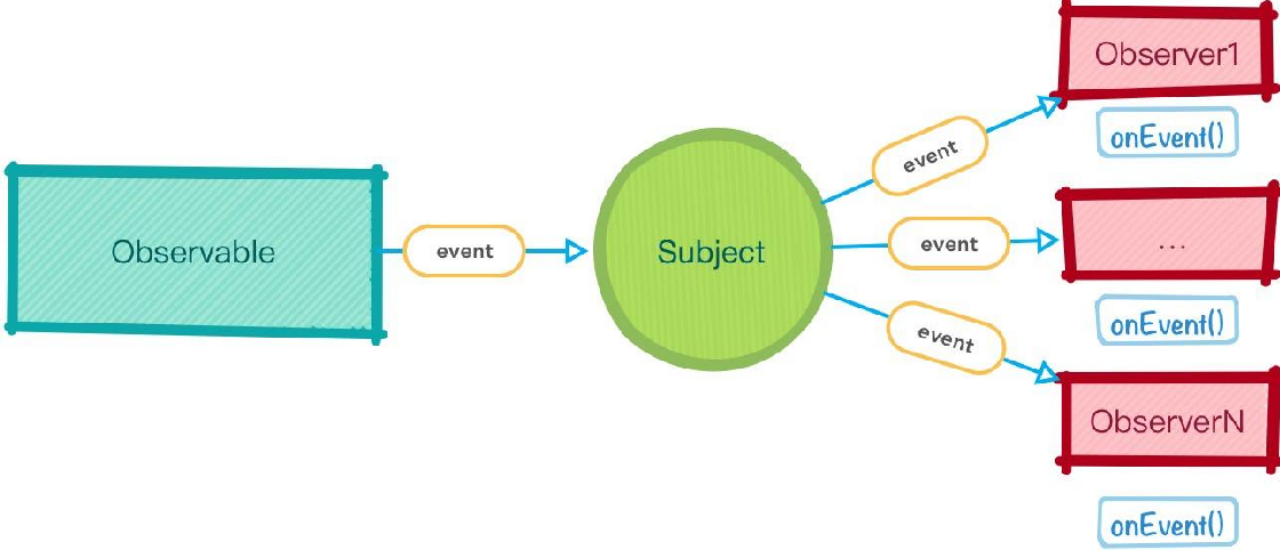
**Subjects**是将任意 **Observable**执⾏共享给多个观察者的唯⼀⽅式这个时候眼尖的读者会发现,这⾥产⽣了⼀个新概念——多播。
* 那么多播⼜是什么呢?
* 有了多播是不是还有单播?
* 他们的区别⼜是什么呢?](images/screenshot_1661654475959.png)
接下来就让笔者给⼤家好好分析这两个概念吧。

### **单播**
普通的 **Observable**是单播的,那么什么是单播呢?
单播的意思是,每个普通的 **Observables**实例都只能被⼀个观察者订阅,当它被其他观察者订阅的时候会产⽣⼀个新的实例。也就是普通
**Observables**被不同的观察者订阅的时候,会有多个实例,不管观察者是从何时开始订阅,每个实例都是从头开始把值发给对应的观察者。
```
const Rx = require('rxjs/Rx')
const source = Rx.Observable.interval(1000).take(3);
source.subscribe((value) => console.log('A ' + value))
setTimeout(() => {
source.subscribe((value) => console.log('B ' + value))
}, 1000)
```
看到陌⽣的调⽤不要慌,后⾯会进⾏详细解析,这⾥的 **source**你可以理解为就是⼀个每隔⼀秒发送⼀个从 0 开始递增整数的 **Observable**就⾏了, 且只会发送三次( **take**操作符其实也就是限定拿多少个数就不在发送数据了。)。
从这⾥我们可以看出两个不同观察者订阅了同⼀个源( **source**),⼀个是直接订阅,另⼀个延时⼀秒之后再订阅。
从打印的结果来看, **A**从 0 开始每隔⼀秒打印⼀个递增的数,⽽ **B**延时了⼀秒,然后再从 0 开始打印,由此可见, **A**与 **B**的执⾏是完全分开的,也就是每次订阅都创建了⼀个新的实例。
在许多场景下,我们可能会希望 **B**能够不从最初始开始接受数据,⽽是接受在订阅的那⼀刻开始接受当前正在发送的数据,这就需要⽤到多播能
⼒了。
### **多播**
那么如果实现多播能⼒呢,也就是实现我们不论什么时候订阅只会接收到实时的数据的功能。
可能这个时候会有⼩伙伴跳出来了,直接给个中间⼈来订阅这个源,然后将数据转发给 **A**和 **B**不就⾏了?
```
const source = Rx.Observable.interval(1000).take(3);
const subject = {
observers: [],
subscribe(target) {
this.observers.push(target);
},
next: function(value) {
this.observers.forEach((next) => next(value))
}
}
source.subscribe(subject);
subject.subscribe((value) => console.log('A ' + value))
setTimeout(() => {
subject.subscribe((value) => console.log('B ' + value))
}, 1000)
```
先分析⼀下代码, **A**和 **B**的订阅和单播⾥代码并⽆差别,唯⼀变化的是他们订阅的对象由 **source**变成了 **subject**,然后再看看这个 **subject**包含了什么,这⾥做了⼀些简化,移除了 **error**、 **complete**这样的处理函数,只保留了 **next**,然后内部含有⼀个 **observers**数组,这⾥包含了所有的订阅者,暴露⼀个 **subscribe**⽤于观察者对其进⾏订阅。
在使⽤过程中,让这个中间商 **subject**来订阅 **source**,这样便做到了统⼀管理,以及保证数据的实时性,因为本质上对于 **source**来说只有⼀个订阅者。
这⾥主要是⽅便理解,简易实现了 **RxJS**中的 **Subject**的实例,这⾥的中间⼈可以直接换成 **RxJS**的 **Subject**类实例,效果是⼀样的
```
const source = Rx.Observable.interval(1000).take(3);
const subject = new Rx.Subject(); source.subscribe(subject);
subject.subscribe((value) => console.log('A ' + value))
setTimeout(() => {
subject.subscribe((value) => console.log('B ' + value))
}, 1000)
```
同样先来看看打印的结果是否符合预期,⾸先 **A**的打印结果并⽆变化, **B**⾸次打印的数字现在是从 1 开始了,也就当前正在传输的数据,这下满
⾜了我们需要获取实时数据的需求了。
不同于单播订阅者总是需要从头开始获取数据,多播模式能够保证数据的实时性。除了以上这些, **RxJS**还提供了 **Subject**的三个变体:
* **BehaviorSubject**
* **ReplaySubject**
* **AsyncSubject**
https://blog.csdn.net/web220507/article/details/128913157
### **Behavior** **Subject**
**BehaviorSubject**是⼀种在有新的订阅时会额外发出最近⼀次发出的值的 **Subject**。
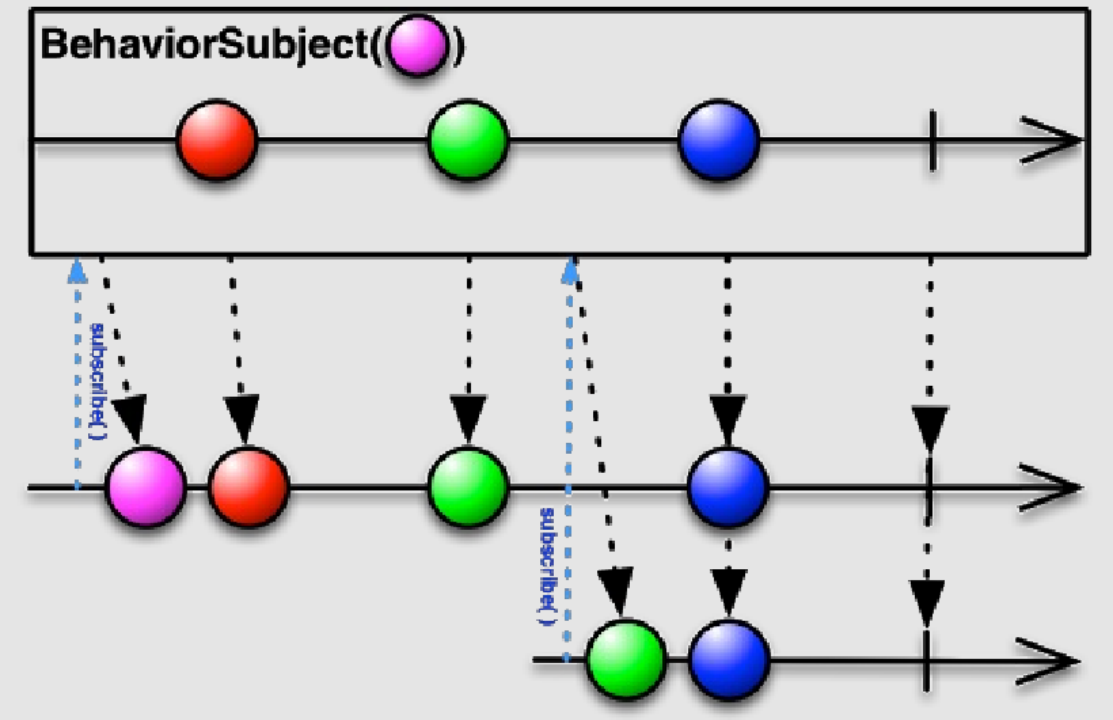
同样我们结合现实场景来进⾏理解,假设有我们需要使⽤它来维护⼀个状态,在它变化之后给所有重新订阅的⼈都能发送⼀个当前状态的数据,这 就好⽐我们要实现⼀个计算属性,我们只关⼼该计算属性最终的状态,⽽不关⼼过程中变化的数,那么⼜该怎么处理呢?
我们知道普通的 **Subject**只会在当前有新数据的时候发送当前的数据,⽽发送完毕之后就不会再发送已发送过的数据,那么这个时候我们就可以引⼊**BehaviorSubject**来进⾏终态维护了,因为订阅了该对象的观察者在订阅的同时能够收到该对象发送的最近⼀次的值,这样就能满⾜我们上述的需求了。
然后再结合代码来分析这种 **Subject**应⽤的场景:
```
const subject = new Rx.Subject();
subject.subscribe((value) => console.log('A:' + value))
subject.next(1);
subject.next(2);
setTimeout(() => {
subject.subscribe((value) => console.log('B:' + value));
}, 1000)
```
⾸先演⽰的是采⽤普通 **Subject**来作为订阅的对象,然后观察者 **A**在实例对象 **subject**调⽤ **next**发送新的值之前订阅的,然后观察者是延时⼀秒之后订阅的,所以 **A**接受数据正常,那么这个时候由于 **B**在数据发送的时候还没订阅,所以它并没有收到数据。
那么我们再来看看采⽤ **BehaviorSubject**实现的效果:
```
const subject = new Rx.BehaviorSubject(0);
subject.subscribe((value: number) => console.log('A:' + value))
subject.next(1);
subject.next(2);
setTimeout(() => {
subject.subscribe((value: number) => console.log('B:' + value))
}, 1000)
```
同样从打印的结果来看,与普通 **Subject**的区别在于,在订阅的同时源对象就发送了最近⼀次改变的值(如果没改变则发送初始值),这个时候我们的 **B**也如愿获取到了最新的状态。
这⾥在实例化 **BehaviorSubject**的时候需要传⼊⼀个初始值。
### **Replay** **Subject**
在理解了 **BehaviorSubject**之后再来理解 **ReplaySubject**就⽐较轻松了, **ReplaySubject**会保存所有值,然后回放给新的订阅者,同时它提供了⼊参⽤于控制重放值的数量(默认重放所有)。

什么?还不理解?看码:
```
const subject = new Rx.ReplaySubject(2);
subject.next(0); subject.next(1); subject.next(2);
subject.subscribe((value:number)=>console.log('A:+ value))
subject.next(3);
subject.next(4);
setTimeout(() => {
subject.subscribe((value: number) => console.log('B:' + value))
}, 1000)
```
我们先从构造函数传参来看, **BehaviorSubject**与 **ReplaySubject**都需要传⼊⼀个参数,对 **BehaviorSubject**来说是初始值,⽽对于 **ReplaySubject**来说就是重放先前多少次的值,如果不传⼊重放次数,那么它将重放所有发射过的值。
从结果上看,如果你不传⼊确定的重放次数,那么实现的效果与之前介绍的单播效果⼏乎没有差别。所以我们再分析代码可以知道在订阅的那⼀刻,观察者们就能收到源对象前多少次发送的值。
### **Async** **Subject**
**AsyncSubject**只有当 **Observable**执⾏完成时 (执⾏ **complete()**),它才会将执⾏的最后⼀个值发送给观察者,如果因异常⽽终⽌, **AsyncSubject**将不会释放任何数据,但是会向 **Observer**传递⼀个异常通知。
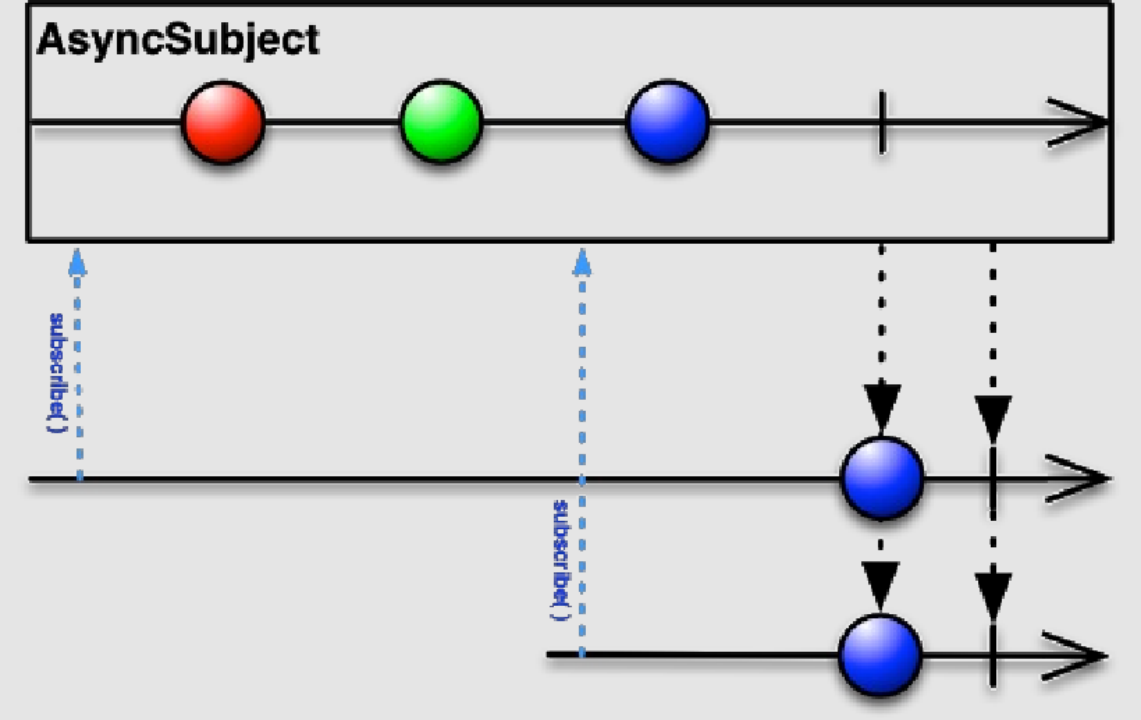
**AsyncSubject**⼀般⽤的⽐较少,更多的还是使⽤前⾯三种。
```
const subject = new Rx.AsyncSubject();
subject.next(1);
subject.subscribe(res => { console.log('A:' + res);
});
subject.next(2);
subject.subscribe(res => {
console.log('B:' + res);
});
subject.next(3);
subject.subscribe(res => {
console.log('C:' + res);
});
subject.complete(); subject.next(4);
```
从打印结果来看其实已经很好理解了,也就是说对于所有的观察者们来说,源对象只会在所有数据发送完毕也就是调⽤ **complete**⽅法之后才会把最后⼀个数据返回给观察者们。
这就好⽐⼩说⾥经常有的,当你要放技能的时候,先要打⼀套起⼿式,打完之后才会放出你的⼤招。
## **Cold- Observables 与 Hot- Observables**
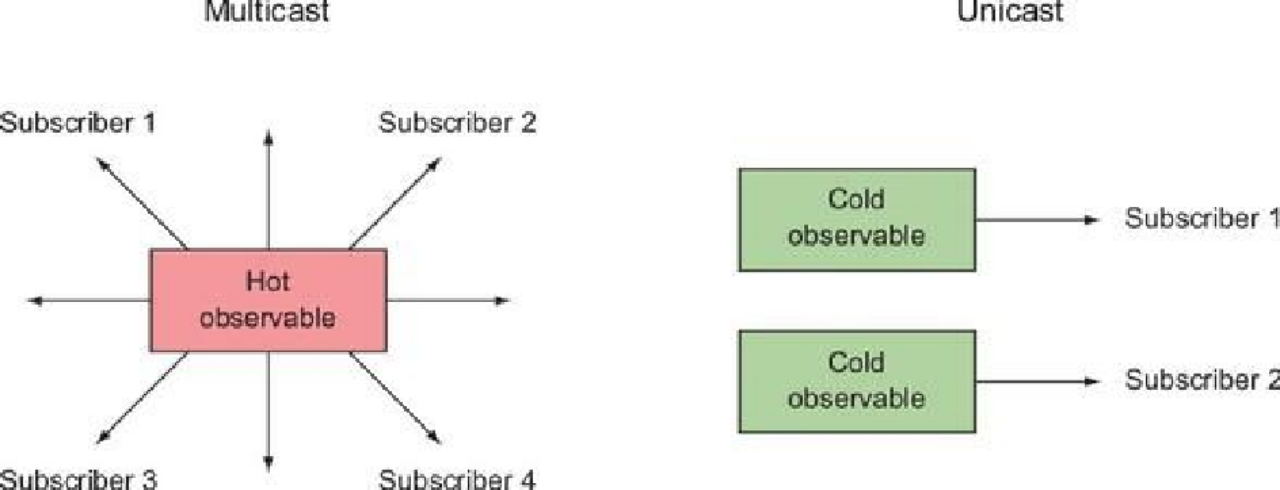
### **Cold** **Observables**
**Cold Observables**只有被 **observers**订阅的时候,才会开始产⽣值。是单播的,有多少个订阅就会⽣成多少个订阅实例,每个订阅都是从第⼀个产⽣的值开始接收值,所以每个订阅接收到的值都是⼀样的。
如果⼤家想要参考 **Cold Observables**相关代码,直接看前⾯的单播⽰例就⾏了。
正如单播描述的能⼒,不管观察者们什么时候开始订阅,源对象都会从初始值开始把所有的数都发给该观察者。
### **Hot****Observables**
**Hot****Observables**不管有没有被订阅都会产⽣值。是多播的,多个订阅共享同⼀个实例,是从订阅开始接受到值,每个订阅接收到的值是不同的, 取决于它们是从什么时候开始订阅。
这⾥有⼏种场景,我们可以逐⼀分析⼀下便于理解:
#### **“ 加热”**
⾸先可以忽略代码中出现的陌⽣的函数,后⾯会细说。
```
const source = Rx.Observable.of(1, 2).publish();
source.connect();
source.subscribe((value) => console.log('A:' + value));
setTimeout(() => {
source.subscribe((value) => console.log('B:' + value));
}, 1000);
```
这⾥⾸先⽤ **Rx**的操作符 **of**创建了⼀个 **Observable**,并且后⾯跟上了⼀个 **publish**函数,在创建完之后调⽤ **connect**函数进⾏开始数据发送。
最终代码的执⾏结果就是没有任何数据打印出来,分析⼀下原因其实也⽐较好理解,由于开启数据发送的时候还没有订阅,并且这是⼀个 **Hot****Observables**,它是不会理会你是否有没有订阅它,开启之后就会直接发送数据,所以 **A**和 **B**都没有接收到数据。
当然你这⾥如果把 **connect**⽅法放到最后,那么最终的结果就是 **A**接收到了, **B**还是接不到,因为 **A**在开启发数据之前就订阅了,⽽ **B**还要等⼀秒。
#### **更直观的场景**
正如上述多播所描述的,其实我们更多想看到的现象是能够 **A**和 **B**两个观察者能够都有接收到数据,然后观察数据的差别,这样会⽅便理解。这⾥直接换⼀个发射源:
```
const source = Rx.Observable.interval(1000).take(3).publish(); source.subscribe((value: number) => console.log('A:' + value));
setTimeout(() => {
source.subscribe((value: number) => console.log('B:' + value));
}, 3000);
source.connect();
```
这⾥我们利⽤ **interval**配合 **take**操作符每秒发射⼀个递增的数,最多三个,然后这个时候的打印结果就更清晰了, **A**正常接收到了三个数, **B**三秒之后才订阅,所以只接收到了最后⼀个数 2,这种⽅式就是上述多播所描述的并⽆⼀⼆。
### **两者对⽐**
* **Cold** **Observables**:举个栗⼦会⽐较好理解⼀点:⽐如我们上 B 站看番,更新了新番,我们不论什么时候去看,都能从头开始看到完整的剧集,与其他⼈看不看毫⽆关联,互不⼲扰。
* **Hot Observables**:这就好⽐我们上 B 站看直播,直播开始之后就直接开始播放了,不管是否有没有订阅者,也就是说如果你没有⼀开始就订阅它,那么你过⼀段时候后再去看,是不知道前⾯直播的内容的。
### **上述代码中出现的操作符解析**
在创建 **Hot Observables**时我们⽤到了 **publish**与 **connect**函数的结合,其实调⽤了 **publish**操作符之后返回的结果是⼀个 **ConnectableObservable**,然后该对象上提供了 **connect**⽅法让我们控制发送数据的时间。
* **publish**:这个操作符把正常的 **Observable**( **Cold Observables**)转换成 **ConnectableObservable**。
* **ConnectableObservable**: **ConnectableObservable**是多播的共享 **Observable**,可以同时被多个 **observers**共享订阅,它是 **Hot**
**Observables**。 **ConnectableObservable**是订阅者和真正的源头 **Observables**(上⾯例⼦中的 **interval**,每隔⼀秒发送⼀个值,就是源头
**Observables**)的中间⼈, **ConnectableObservable**从源头 **Observables**接收到值然后再把值转发给订阅者。
* **connect()**: **ConnectableObservable**并不会主动发送值,它有个 **connect**⽅法,通过调⽤ **connect**⽅法,可以启动共享 **ConnectableObservable** 发送值。当我们调⽤ **ConnectableObservable.prototype.connect**⽅法,不管有没有被订阅,都会发送值。订阅者共享同⼀个实例,订阅者接收到的值取决于它们何时开始订阅。
其实这种⼿动控制的⽅式还挺⿇烦的,有没有什么更加⽅便的操作⽅式呢,⽐如监听到有订阅者订阅了才开始发送数据,⼀旦所有订阅者都取消了,就停⽌发送数据?其实也是有的,让我们看看引⽤计数( **refCount**):
### **引⽤计数**
这⾥主要⽤到了 **publish**结合 **refCount**实现⼀个 “⾃动挡” 的效果。
```
const source = Rx.Observable.interval(1000).take(3).publish().refCount(); setTimeout(() => {
source.subscribe(data => { console.log("A:" + data) });
setTimeout(() => {
source.subscribe(data => { console.log("B:" + data) });
}, 1000);
}, 2000);
```
我们透过结果看本质,能够很轻松的发现,只有当 **A**订阅的时候才开始发送数据( **A**拿到的数据是从 0 开始的),并且当 **B**订阅时,也是只能获取到当前发送的数据,⽽不能获取到之前的数据。
不仅如此,这种 “⾃动挡” 当所有订阅者都取消订阅的时候它就会停⽌再发送数据了。
## **Schedulers( 调度器)**
⽤来控制并发并且是中央集权的调度员,允许我们在发⽣计算时进⾏协调,例如 **setTimeout**或 **requestAnimationFrame**或其他。
* 调度器是⼀种数据结构。 它知道如何根据优先级或其他标准来存储任务和将任务进⾏排序。
* 调度器是执⾏上下⽂。 它表⽰在何时何地执⾏任务 (举例来说,⽴即的,或另⼀种回调函数机制 (⽐如 **setTimeout**或 **process.nextTick**),或动画帧)。
* 调度器有⼀个 (虚拟的) 时钟。 调度器功能通过它的 **getter**⽅法 **now()**提供了 “时间” 的概念。在具体调度器上安排的任务将严格遵循该时钟所表⽰的时间。
学到这相信⼤家也已经或多或少对 **RxJS**有⼀定了解了,不知道⼤家有没有发现⼀个疑问,前⾯所展⽰的代码⽰例中有同步也有异步,⽽笔者却没有显⽰的控制他们的执⾏,他们的这套执⾏机制到底是什么呢?
其实他们的内部的调度就是靠的 **Schedulers**来控制数据发送的时机,许多操作符会预设不同的 **Scheduler**,所以我们不需要进⾏特殊处理他们就能良好的进⾏同步或异步运⾏。
```
const source = Rx.Observable.create(function (observer: any)
{ observer.next(1);
observer.next(2);
observer.next(3);
observer.complete();
});
console.log(' 订 阅 前 ');
source.observeOn(Rx.Scheduler.async)
.subscribe({
next: (value) => { console.log(value); },
error: (err) => { console.log('Error: ' + err); },
complete: () => { console.log('complete'); }
});
console.log('订阅后');
```
从打印结果上来看,数据的发送时机的确已经由同步变成了异步,如果不进⾏调度⽅式修改,那么 “订阅后” 的打印应该是在数据发送完毕之后才会执⾏的。
看完⽰例之后我们再来研究这个调度器能做哪⼏种调度:
* **queue**
* **asap**
* **async**
* **animationFrame**
### **queue**
将每个下⼀个任务放在队列中,⽽不是⽴即执⾏
**queue**延迟使⽤调度程序时,其⾏为与 **async**调度程序相同。
当没有延迟使⽤时,它将同步安排给定的任务 - 在安排好任务后⽴即执⾏。但是,当递归调⽤时(即在已调度的任务内部),将使⽤队列调度程序调度另⼀个任务,⽽不是⽴即执⾏,该任务将被放⼊队列并等待当前任务完成。
这意味着,当您使⽤ **queue**调度程序执⾏任务时,您确定它会在该调度程序调度的其他任何任务开始之前结束。这个同步与我们平常理解的同步可能不太⼀样,笔者当时也都困惑了⼀会。
还是⽤⼀个官⽅的例⼦来讲解这种调度⽅式是怎么理解吧:
```
import { queueScheduler } from 'rxjs';
queueScheduler.schedule(() => {
queueScheduler.schedule(() =>
console.log('second'));
console.log('first');
});
```
我们⽆需关注陌⽣的函数调⽤,我们这⾥着重于看这种调度⽅式与平常的同步调度的区别。
⾸先我们调⽤ **queueScheduler**的 **schedule**⽅法开始执⾏,然后函数内部⼜同样再以同样的⽅式调⽤(这⾥也可以改成递归,不过这⾥⽤这个⽰例去理解可能会好⼀点),并且传⼊⼀个函数,打印 **second**。
然后继续看下⾯的语句,⼀个普通的 **console.log('first')**,然后我们再来看看打印结果:
是不是有点神奇,如果没看明⽩为啥的,可以再回头看看前⾯ **queue**对于递归执⾏的处理⽅式。也就是说如果递归调⽤,它内部会维护⼀个队
列,然后等待先加⼊队列的任务先执⾏完成(也就是上⾯的 **console.log('first')**执⾏完才会执⾏ **console.log('second')**,因为 **console.log('second')**这个任务是后加⼊该队列的)。
### **asap**
内部基于 **Promise**实现( **Node**端采⽤ **process.nextTick**),他会使⽤可⽤的最快的异步传输机制,如果不⽀持 **Promise**或 **process.nextTick**或者 **Web**
**Worker**的 **MessageChannel**也可能会调⽤ **setTimeout**⽅式进⾏调度。
### **async**
与 **asap**⽅式很像,只不过内部采⽤ **setInterval**进⾏调度,⼤多⽤于基于时间的操作符。
### **animationFrame**
从名字看其实相信⼤家已经就能略知⼀⼆了,内部基于 **requestAnimationFrame**来实现调度,所以执⾏的时机将与 **window.requestAnimationFrame**保持⼀致,适⽤于需要频繁渲染或操作动画的场景。
## **Operators**
### **Operator 概 念**
采⽤函数式编程风格的纯函数 ( **pure function**),使⽤像 **map**、 **filter**、 **concat**、 **flatMap**等这样的操作符来处理集合。也正因为他的纯函数定义, 所以我们可以知道调⽤任意的操作符时都不会改变已存在的 **Observable**实例,⽽是会在原有的基础上返回⼀个新的 **Observable**。
尽管 **RxJS**的根基是 **Observable**,但最有⽤的还是它的操作符。操作符是允许复杂的异步代码以声明式的⽅式进⾏轻松组合的基础代码单元。
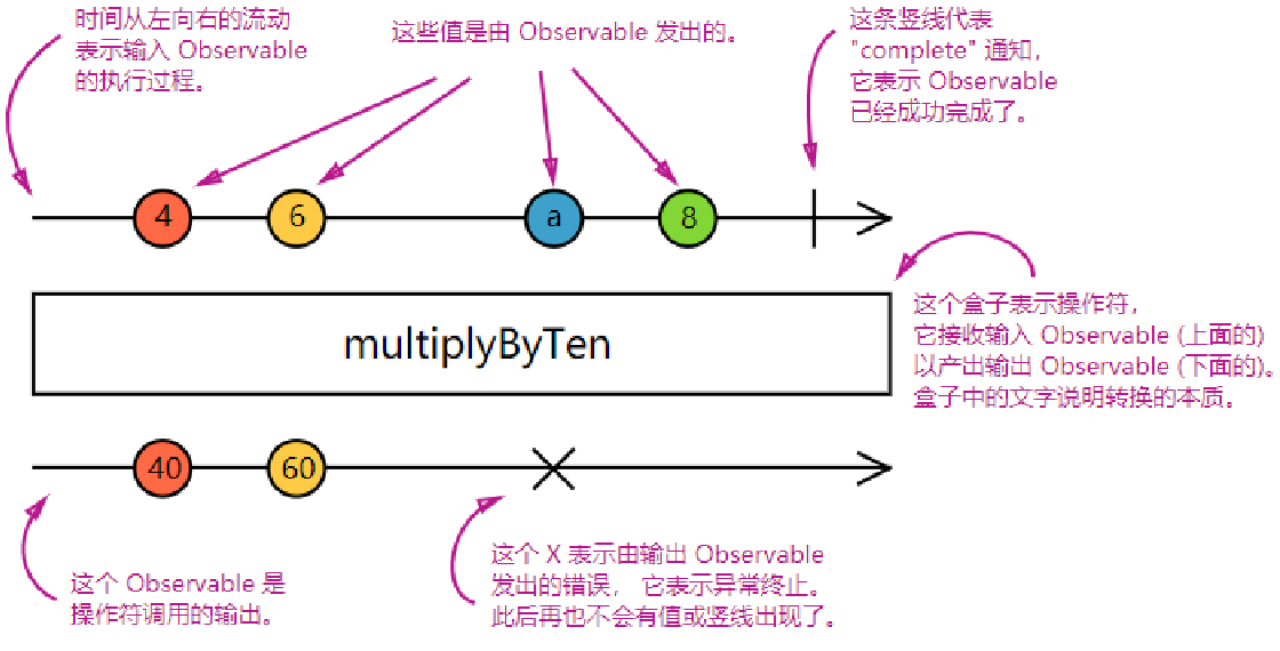
### **学习 RxJS 操作符**
https://rxjs-cn.github.io/learn-rxjs-operators/operators/creation/create.html