
## Java专题三:集合
[TOC]

### 3.1. ArrayList
```java
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData; // non-private to simplify nested class access
private int size;
}
```
ArrayList 内部维护了一个Object类型的能**自动扩容的数组**,当ArrayList对象调用add方法添加元素时,会先将elementData数组所含元素个数+1(size+1)与elementData的容量(elementData.length)进行比较,如果超过了当前,则申请一个合适容量大小的Object数组,并将老的数组元素拷贝到新的elementData数组。
**插入元素**:
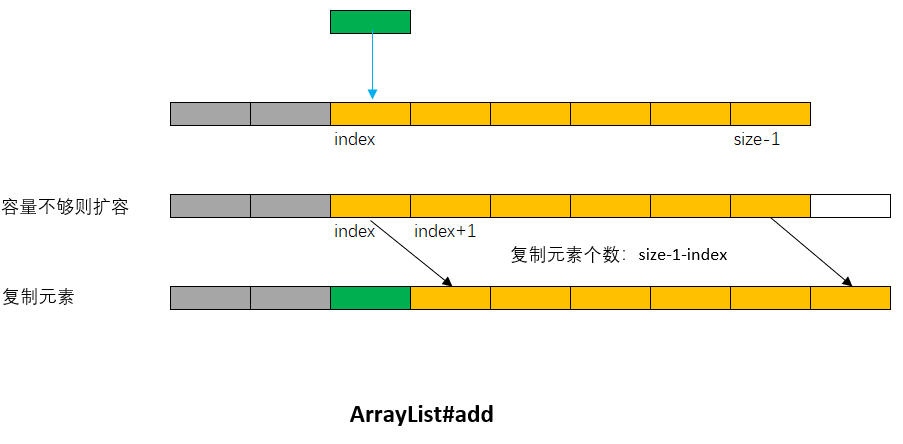
在长度为size的List指定位置index处插入元素,如果容量不够,先扩容,然后使用System.arraycopy方法从index处开始拷贝size-1-index个元素至index+1处,并将待插入元素直接插入到index处。
**删除元素**:
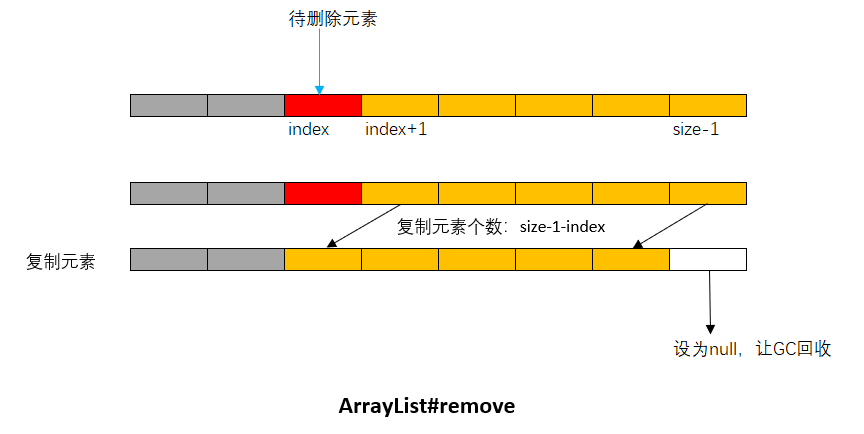
在长度为size的List指定位置index处删除元素,使用System.arraycopy方法从index+1开始拷贝size-1-index个元素至index处,并将最后一个元素[size-1]置为空,给GC回收。
### 3.2. LinkedList
```java
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
```
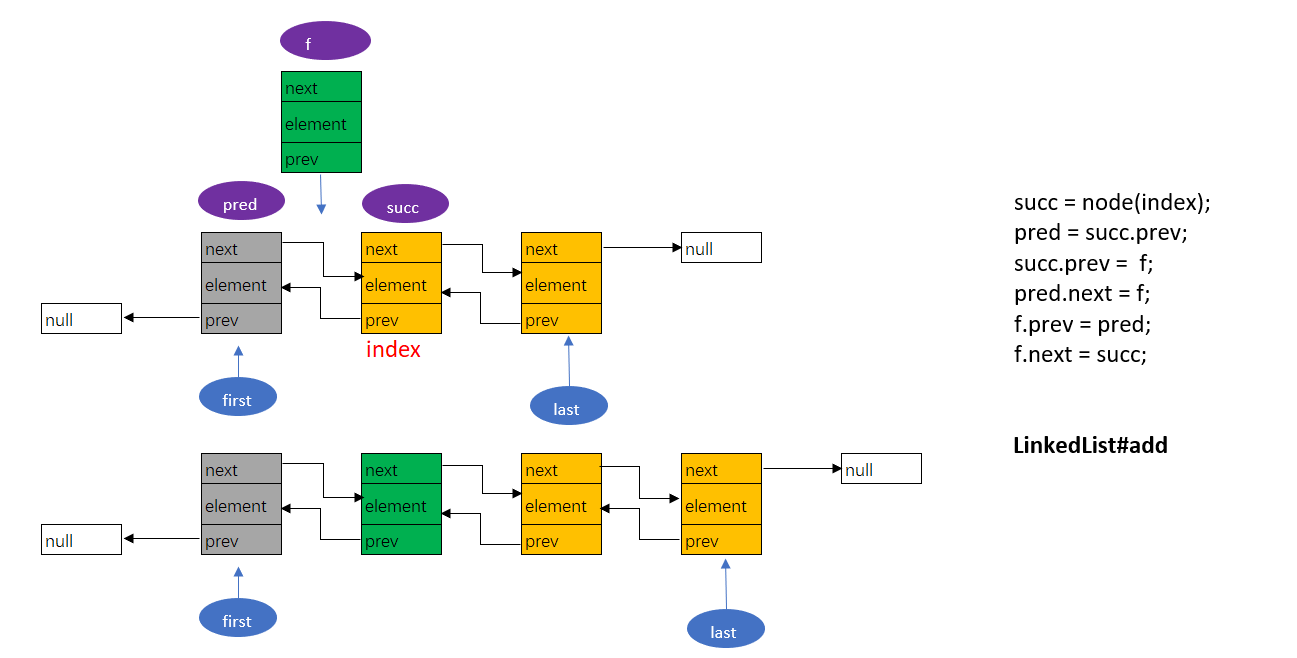
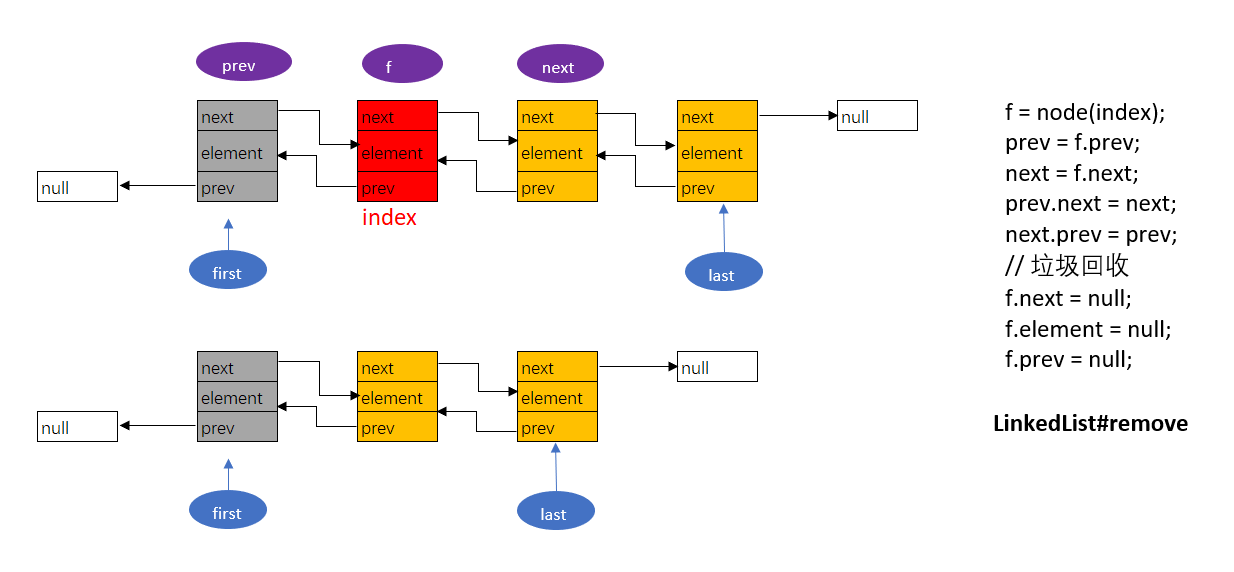
LinkedList是使用**双向链表**数据结构来实现的,其中节点数据类型(与C语言之中的结构体类似)使用内部类实现。
### 3.3. HashMap
```java
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
transient Node<K,V>[] table;//哈希表
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
}
```
HashMap使用**哈希表**数据结构,其哈希函数为:H(key) = (n-1) & hash; 并使用链表数据结构处理冲突。
其中:
```java
n = table.length;
hash = hash(key);
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
```
说明:HashMap如果Key相等(equal方法返回true)则认为是同一元素,插入key相同的键值对,后面插入的value会覆盖前面的value。
#### 3.3.1. 插入元素
1. 根据哈希函数计算判断哈希表中该位置index是否已插入元素,如果没有,则进入第2步,否则进入第3步
2. 直接给哈希表index位置赋值即可,如table[index] = newNode;插入结束。
3. 根据键key是否相等(equal方法)判断是否是同一元素,如果是同一元素,则替换掉value,插入结束,否则进入第4步。
4. 产生了冲突,使用链表尾插法将新元素插入。
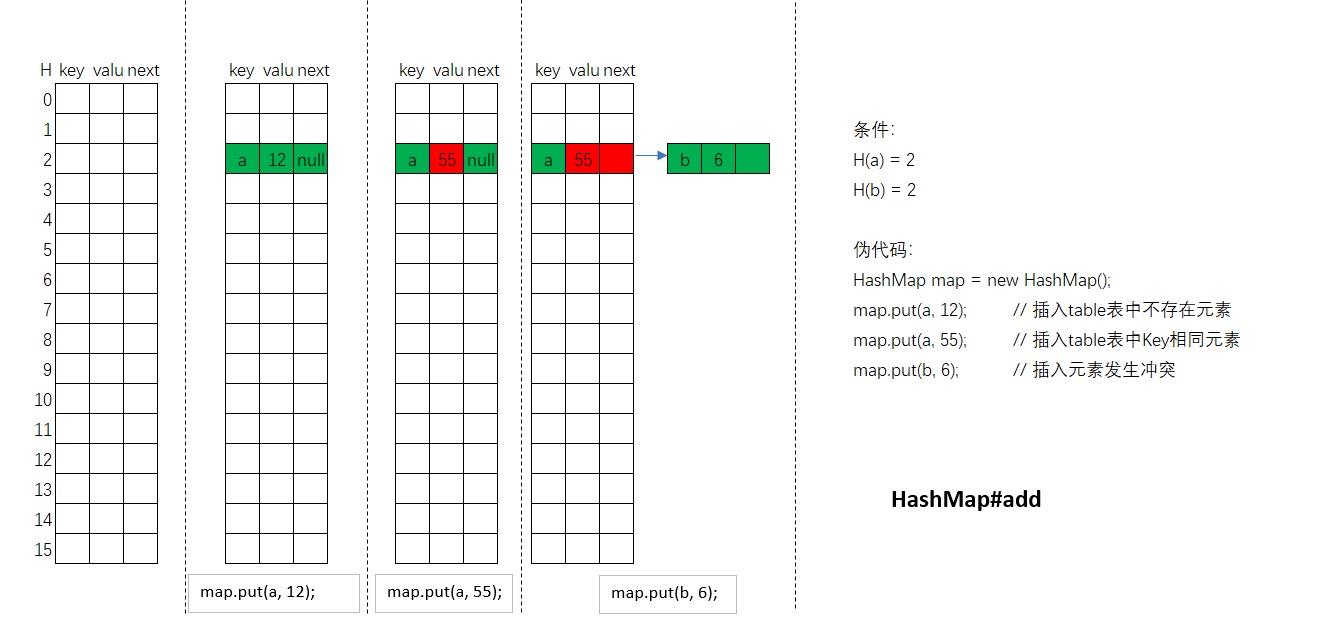
#### 3.3.2. 删除元素
1. 根据哈希函数计算判断哈希表中该位置index判断是否为null,如果不是null,则进入第2步,否则直接返回null,删除结束。
2. 遍历表中index位置的链表,查找与删除元素Key相同的元素,找到的话进入第3步,否则返回null,删除结束。
3. 根据链表的删除元素方法删除元素,删除结束。
#### 3.3.3. 扩容
- `initialCapacity`: 初始容量,默认值为16(`DEFAULT_INITIAL_CAPACITY`),也可以通过构造方法`HashMap(int initialCapacity)`指定`initialCapacity`的值
- `MAXIMUM_CAPACITY`: 最大容量,HashMap的容量是动态增长的,但不是无限增长的
- `loadFactor`: 装填因子,默认值为0.75f(`DEFAULT_LOAD_FACTOR`),也可以通过构造方法`HashMap(int initialCapacity, float loadFactor)`指定`loadFactor`的值,表示在哈希表中能填充的最佳百分比,超过了该百分比发生冲突的可能性就比较大
- `size`: 初始容量,HashMap中已经插入的key-value对的数量
- `threshold`: 临界值,当`size`大于这个临界值,HashMap就得重新扩容
~~~
public class HashMap {
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient int size;
int threshold;
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
}
~~~
### 3.4. HashSet
```java
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
}
```
HashSet内部维护了一个HashMap对象,通过HashMap的Key相同为同一元素原则确保HashSet添加元素不重复。
### 3.5. Hashtable
是线程安全的,不推荐使用
```java
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
private transient Entry<?,?>[] table;
private transient int count;
private int threshold;
private float loadFactor;// 装填因子
}
```
#### 3.5.1. 哈希与冲突方法
Hashtable使用**哈希表**数据结构,其构造哈希表的哈希函数(除留余数法)为:
```java
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
```
处理冲突方法,与HashMap一样,采用链地址法,但是在表头插入:
```java
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
```
#### 3.5.2. Hashtable为什么key和value都不能为null
```
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
```
首先判断了value是否为空,为空则抛出NullPointerException,
然后执行key.hashCode()方法时,如果key为null,不能在空指针上调用方法,也会抛出异常,
因此Hashtable中key和value都不能为null
### 3.6. TreeMap
```java
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable {
private final Comparator<? super K> comparator;//用于接收用户自定义的比较器
private transient Entry<K,V> root;//红黑树的根节点
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
}
```
TreeMap内部使用**红黑树**数据结构,其中每个节点类型定义为内部类Entry类型,与TreeSet一样能够对插入的元素进行自动排序,元素规范与TreeSet一样。
**什么是红黑树?**
首先红黑树是**二叉查找树**,它们当中每一个节点的比较值都必须大于或等于在它的左子树中的所有节点,并且小于或等于在它的右子树中的所有节点。
**红黑树特点**:
1.根节点与叶节点都是黑色节点,其中叶节点为NULL节点。
2.每个红色节点的两个子节点都是黑色节点。
3.从根节点到所有叶子节点上的黑色节点数量是相同的。
### 3.7. EnumSet
> 添加枚举类元素的专用集合类
#### 3.7.1. 与其他集合类区别:
- `EnumSet`内部实现不使用常见的`数据结构`,比如数组(`ArrayList`),链表(`LinkedList`),哈系表(`HashMap、Hashtable、HashSet`),红黑树(`TreeMap、TreeSet`)而是使用`位运算`完成集合的基本操作
- `EnumSet`是抽象类,只能通过`静态工厂方法`构造EnumSet对象,具体如下:
`EnumSet<E> noneOf(Class<E> elementType)`:构造一个空的集合
`EnumSet<E> allOf(Class<E> elementType)`:构造一个包含枚举类中所有枚举项的集合
`EnumSet<E> of(E e)`:构造包含1个元素的集合
`EnumSet<E> of(E e1, E e2)`:构造包含2个元素的集合
`EnumSet<E> of(E e1, E e2, E e3)`:构造包含3个元素的集合
`EnumSet<E> of(E e1, E e2, E e3, E e4)`:构造包含4个元素的集合
`EnumSet<E> of(E e1, E e2, E e3, E e4, E e5)`:构造包含5个元素的集合
`EnumSet<E> of(E first, E... rest)`:构造包含多个元素的集合(使用可变参数)
`EnumSet<E> copyOf(EnumSet<E> s)`:构造包含参数中所有元素的集合
`EnumSet<E> copyOf(Collection<E> c)`:构造包含参数中所有元素的集合
#### 3.7.2.EnumSet作为集合类基本操作方法实现原理(位运算):
**说明**:
- 从EnumSet的`noneOf`可以看出,当枚举类中的枚举项`少于64`时,返回的是`RegularEnumSet类`(`EnumSet的实现类`)对象,大于64,返回的是JumboEnumSet类对象,为了方便分析,后面同一使用RegularEnumSet类解释原理
```
// EnumSet#noneOf
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) {
Enum<?>[] universe = getUniverse(elementType);
if (universe == null)
throw new ClassCastException(elementType + " not an enum");
if (universe.length <= 64)
return new RegularEnumSet<>(elementType, universe);
else
return new JumboEnumSet<>(elementType, universe);
}
```
- 测试用的枚举类
```
enum Color{
RED("RED"),
BLUE("BLUE"),
YELLOW("YELLOW"),
BLACK("BLACK");
String name;
Color(String name){
this.name = name;
}
@Override
public String toString(){
return this.name;
}
}
```
#### 3.7.3. add方法</h6>
public boolean add(E e) {
typeCheck(e);
long oldElements = elements;
elements |= (1L << ((Enum<?>)e).ordinal());
return elements != oldElements;
}
`ordinal()`为每个枚举项的序号,从`0开始`,按声明顺序排列,如`[RED,BLUE,YELLOW,BLACK]`对应`[0,1,2,3]`;`1L << ((Enum<?>)e).ordinal()`(为了方便,这里称之为`枚举值`)则表示`1*2^(e.ordinal())`,Color.RED的`ordianl()`为`0`,对应`枚举值`为`1*2^0=1`,其实就是第`ordinal()+1`位(从右往左数,个位为第1位)为1其它位为0的十进制数,对应十进制数为`00000001`(这里假设是8bit,实际是long型32bit);
则每个枚举项表示如下:
枚举项|序号|`1L << ((Enum<?>)e).ordinal()`|枚举值
:-:|:-:|:-:|:-:
Color.RED|0|`00000001`|1
Color.BLUE|1|`00000010`|2
Color.YELLOW|2|`00000100`|4
Color.BLACK|3|`00001000`|8
`elements |=`就是对添加的不同元素的枚举值进行求和,`相同`元素`相或`时`保持不变`
#### 3.7.4. remove方法
public boolean remove(Object e) {
if (e == null)
return false;
Class<?> eClass = e.getClass();
if (eClass != elementType && eClass.getSuperclass() != elementType)
return false;
long oldElements = elements;
elements &= ~(1L << ((Enum<?>)e).ordinal());
return elements != oldElements;
}
按照之前的`枚举值相加`的想法,remove就是从`总枚举值`中减去`待删除元素的枚举值`,因为是`位运算`,没有直接相减,使用位操作`elements &= ~(1L << ((Enum<?>)e).ordinal());`
完成相减操作
#### 3.7.5. contains方法</h6>
public boolean contains(Object e) {
if (e == null)
return false;
Class<?> eClass = e.getClass();
if (eClass != elementType && eClass.getSuperclass() != elementType)
return false;
return (elements & (1L << ((Enum<?>)e).ordinal())) != 0;
}
contains方法就更好理解,每个枚举项的枚举值的值都`不一样`,且`相互之间`进行`相与`操作为`0`,使用`总枚举值`与`要查询的枚举项的枚举值`进行`相与`操作,如果为`0`,说明`不存在`该枚举项,否则`存在`
- JavaCook
- Java专题零:类的继承
- Java专题一:数据类型
- Java专题二:相等与比较
- Java专题三:集合
- Java专题四:异常
- Java专题五:遍历与迭代
- Java专题六:运算符
- Java专题七:正则表达式
- Java专题八:泛型
- Java专题九:反射
- Java专题九(1):反射
- Java专题九(2):动态代理
- Java专题十:日期与时间
- Java专题十一:IO与NIO
- Java专题十一(1):IO
- Java专题十一(2):NIO
- Java专题十二:网络
- Java专题十三:并发编程
- Java专题十三(1):线程与线程池
- Java专题十三(2):线程安全与同步
- Java专题十三(3):内存模型、volatile、ThreadLocal
- Java专题十四:JDBC
- Java专题十五:日志
- Java专题十六:定时任务
- Java专题十七:JavaMail
- Java专题十八:注解
- Java专题十九:浅拷贝与深拷贝
- Java专题二十:设计模式
- Java专题二十一:序列化与反序列化
- 附加专题一:MySQL
- MySQL专题零:简介
- MySQL专题一:安装与连接
- MySQL专题二:DDL与DML语法
- MySQL专题三:工作原理
- MySQL专题四:InnoDB存储引擎
- MySQL专题五:sql优化
- MySQL专题六:数据类型
- 附加专题二:Mybatis
- Mybatis专题零:简介
- Mybatis专题一:配置文件
- Mybatis专题二:映射文件
- Mybatis专题三:动态SQL
- Mybatis专题四:源码解析
- 附加专题三:Web编程
- Web专题零:HTTP协议
- Web专题一:Servlet
- Web专题二:Cookie与Session
- 附加专题四:Redis
- Redis专题一:数据类型
- Redis专题二:事务
- Redis专题三:key的过期
- Redis专题四:消息队列
- Redis专题五:持久化