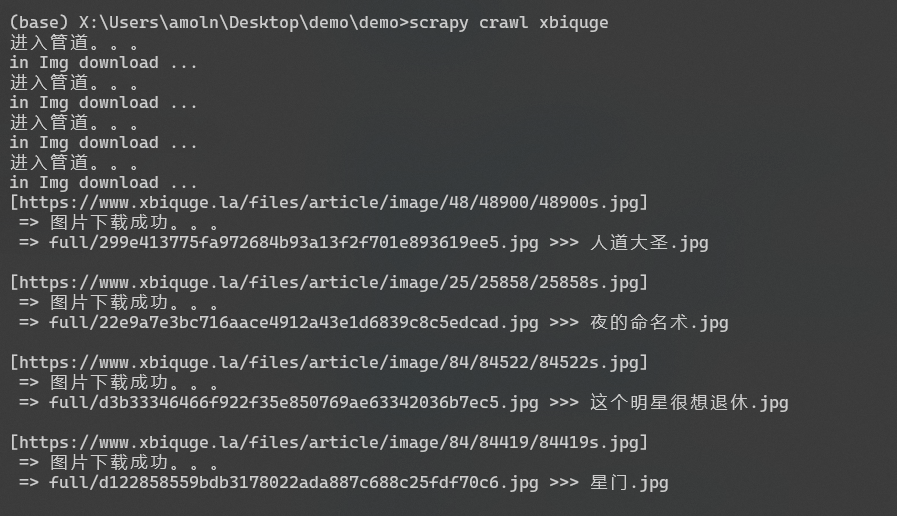
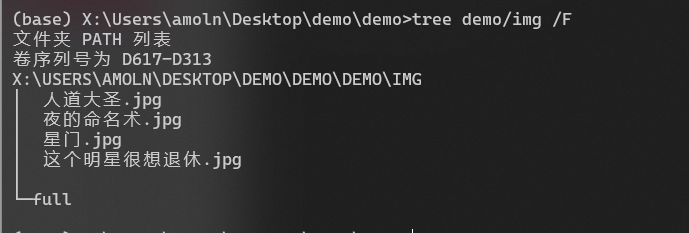
## soxs的网站图片都是无效的我们这次拿笔趣阁来试
* **书写一个item用于给文件下载管道传输参数**
这个主要两个参数一个图片url一个文件名
`items.py`文件
```
import scrapy
class ImgItem(scrapy.Item):
src = scrapy.Field()
fileName = scrapy.Field()
```
* **获取url链接和书名**
这个很简单就不细说了
`spiders/xbiquge.py`
```
import scrapy
import re
from ..items import ImgItem
class xbiqugeSpider(scrapy.Spider):
name = 'xbiquge'
allowed_domains = ['www.xbiquge.la'] # 定义只爬取变量内的网站
start_urls = ["https://www.xbiquge.la/"]# 定义爬取的url,
def parse(self, response): # 爬虫启动后进入parse方法
list = response.xpath("//div[@id='hotcontent']/div/div")
for i in list:
url = i.xpath('div/a/img/@src').extract_first()
name = i.xpath('div/a/img/@alt').extract_first()
fileName = name+"."+re.search(".([a-z|A-Z]*?)$",url).group(1)
item = ImgItem() #实例化item
item['src'] = url
item['fileName'] = fileName
print("进入管道。。。")
yield item # 通过管道保存
```
* **开启管道**
在`setting.py`中添加如下配置
这里demo是项目名,ImgImagesPipeline是类名,根据自己实际情况改
```
ITEM_PIPELINES = {
'demo.pipelines.ImgImagesPipeline': 300,
}
```
* **书写管道**
文件的写法是可以固定的,如果想研究原理可以细看,不想的话直接复制就能用
这个类是我自己写的,可能会有bug
【文件名不可重复,否则报错,没做细节】
```
import scrapy
from scrapy.exceptions import DropItem
import json
import os
from scrapy.pipelines.images import ImagesPipeline
IMGFILEPATH = os.path.dirname(os.path.abspath(__file__))+ "/img/"
# 图片下载管道
class ImgImagesPipeline(ImagesPipeline):
# 返回 图片链接对象
def get_media_requests(self, item, info):
print("in Img download ...")
image_url = item['src']
yield scrapy.Request(url=image_url)
# 下载完成处理文件
def item_completed(self, results, item, info):
global IMGFILEPATH
if results[0][0] == True:
url = results[0][1]['url']
strurl = "["+url+"]"
print(strurl + " \n => 图片下载成功。。。")
print(" => " + results[0][1]['path'] + " >>> " + item['fileName']+" \n")
# 判断文件是否存在
if os.path.isfile(IMGFILEPATH + results[0][1]['path']):
# 重命名
os.rename(IMGFILEPATH + results[0][1]['path'] , IMGFILEPATH + item['fileName'])
# 在这里可以自定义代码,用于处理数据。
# 比如向数据库保存文件名下载状态等
return results
print( "["+item['src']+"] \n => 文件url无法访问 404 ... \n")
return results
```