
本文对应视频:https://www.bilibili.com/video/BV1Da411Y76u/
前面两小节白话完之后,举一个专业点的例子。说明一下消息队列在实际开发中的一个典型的应用场景。
### 用户订单处理
先看下面的这个模型,用户通过浏览器浏览商品并进行下单的动作。用户下单之后,应用程序通常会做如下的一些操作:
1. 订单管理:为用户生成订单
2. 库存管理:商品库存减1
3. 积分管理:为用户增加积分
**请求同步处理模型:**

如果按照上图的操作,用户下单之后,依次同步进行订单、库存、积分管理操作。这样做的缺点是用户等待的时间会较长,特别是在系统用户量大、并发度高的情况下,可能会出现用户下单之后页面超长等待的现象。"哎呀,怎么这么慢,是不是没成功啊,再点几下,欸欸,电脑怎么卡死了。"
**请求异步处理模型:**
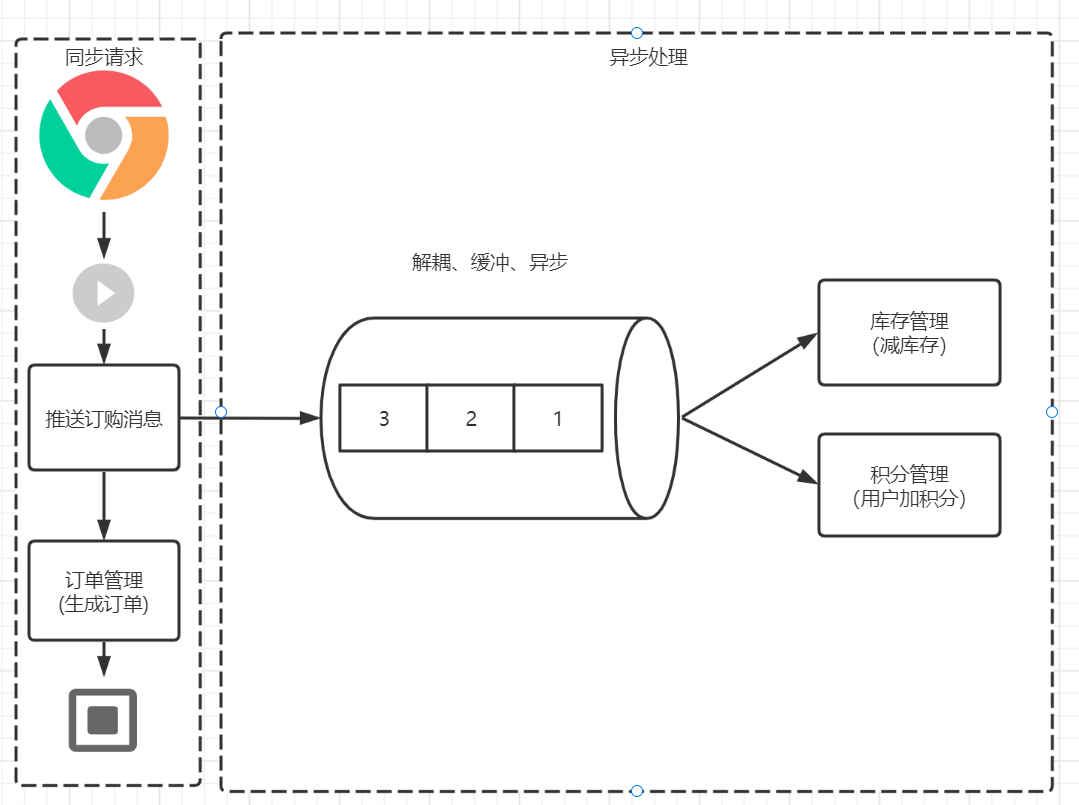
为了有效地提升用户的体验,可以在用户下单之后,**将订购消息发送至消息队列(kafka的延时可以做到毫秒级)**,之后生成订单,返回给用户一个订购成功的消息。用户直接跳转到订单支付页面。大家看到这里的就涉及到同步和异步。
* 同步:推送消息和订单管理是同步进行的,为什么?因为订单的生成是不允许延时操作的,必须先有订单用户才能进行支付操作。
* 异步:库存管理和积分管理是异步操作?因为用户下单之后并不会关心商品库存是不是减少了;对于自己购买商品的积分,用户通常也不会特别关注时效性。所以采用异步处理方式。
因此通过异步操作,我们**减少了同步操作的步骤,缩短用户浏览等待时间,提升了用户体验**。除此之外,消息队列可以有效地进行系统功能解耦,采用异步处理模型,能够有效的进行服务解耦。
**单体应用与服务解耦**
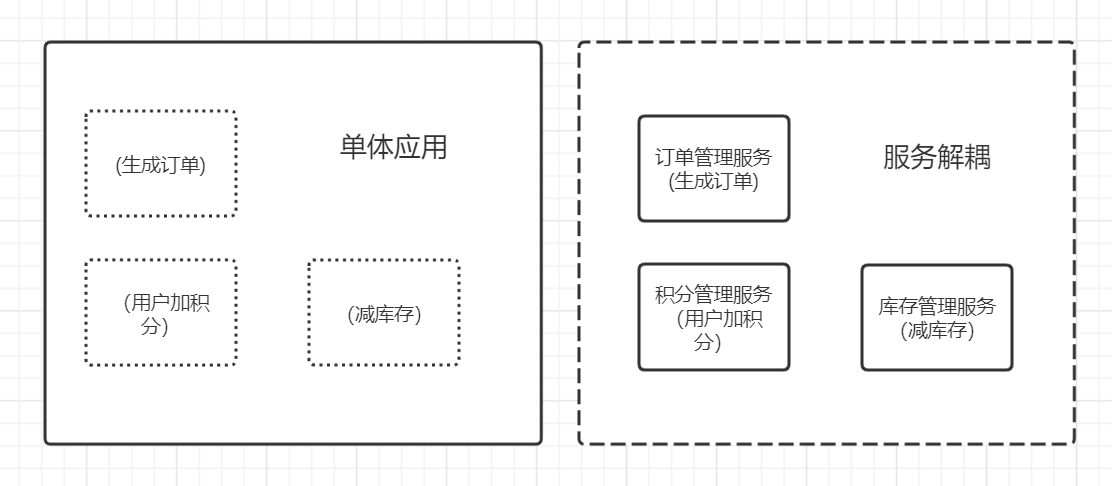
* 在同步处理模型下,将生成订单、用户加积分、减库存操作写在一个单体应用中。修改订单可能影响用户积分,修改用户积分代码可能影响减库存。修改应用程序中的任何一部分代码,都需要将应用整体打包重新部署。这比较适合小团队、用户量小项目的开发模型。
* 在异步的处理模型下,可以将订单管理、积分管理、库存管理都单独拆分为一个服务独立运行、独立代码、独立部署,彼此之间通过消息队列或RPC进行交互。便于小团队知识聚合、专业度增强,代码质量的提升,单个服务测试难度的下降。当服务耦合度下降的时候,也意味着扩展能力的增强,面对更复杂的业务需求也更有的放矢。
一般来说小团队、用户量较小的项目很少会将“程序解耦”作为优先的选项。如果阿里巴巴从工作第一天就想把架构做成今天的样子,它也一定不会成为今天的阿里巴巴。应用服务的解耦一定是配合着业务量的增长,团队规模及知识储备的提升。应用服务的解耦有很多方式,使用消息队列就是核心选项之一。
**数据缓冲**
当我们使用到消息队列,一定意味着“单体应用”的方式已经无法满足我们的用户并发度需求,无法满足高速增长的业务量。对于高并发的处理,通常有两种方式来缓解
1. 集群部署,增加应用实例部署规模,比如一个应用实例处理不过来的请求,通过部署多个实例来完成,配合有效的负载均衡处理高并发需求。也就是:“一个好汉三个帮”,自己干不过来就找人来一起干。
2. 增加集群应用实例规模的方式固然有效,但是要考虑的一件事是:服务器资源是有限的,那么怎么在有限的生产力条件下,既能满足用户需求,又能合理的安排生产,这是“架构师”需要思考的事情。所以架构师将消息处理按照时效性分成两类:
* 对于高时效性的消息数据进行实时同步处理,如:生成订单。
* 对于低时效性、并发度又很高的数据,先缓冲起来。消息队列就是缓冲队列,缓冲的目的是降低后端服务处理瓶颈,根据消息队列后端消费服务的处理能力来拉取数据进行处理,而不是一下子把所有的数据全交给后端消费服务,把后端消费服务压死。如:增加积分、减少库存。
**提升数据处理性能**
既然消息队列已经缓冲了数据,就为我们进行消息的批处理创造了条件。数据批量接收、批量处理、批量入库的操作,一定是比我们一条一条数据的处理操作性能更高的。
- 文档概要
- 如何提问
- 一、kafka基础入门
- 1.1.白话消息队列
- 1.2.消息传递模型
- 1.3.典型应用场景一
- 1.4.典型应用场景二
- 1.5.kafka简单介绍
- 1.6.kafka核心概念解析
- 1.7.搭建kafka单机版
- 1.8.kafka3中zk替代方案
- 二、生产级集群安装
- 2.1.linux安装JDK
- 2.2.linux主机与ip解析
- 2.3.linux新建用户
- 2.4.linux开放防火墙端口
- 2.5.最大打开文件句柄数
- 2.6.集群主机之间免密登录
- 2.7.zookeeper集群安装(脚本)
- 2.8.kafka集群安装部署(脚本)
- 2.9.kafka3无需zk的集群安装
- 2.10.集群可用性验证及配置
- 2.11.kafka集群可靠性配置
- 2.12内外网络映射问题
- 三、生产者客户端
- 3.1.本章阅读说明
- 3.2.图解kafka生产者
- 3.3.数据生产可靠性
- 3.4.保证消息顺序性
- 3.5.生产者Java实现
- 3.6.自定义拦截器
- 3.7.自定义序列化器
- 3.8.自定义分区器
- 3.9.幂等与事务处理
- 四、消费者客户端
- 4.1.消费者组与数据积压
- 4.2.消费者Java实现
- 4.3.消费偏移与可靠性
- 4.4.分区再均衡
- 4.5.线程池与消费者组
- 4.6.消费者拦截器
- 4.7.自定义反序列化器
- 五、SpringBoot集成kafka
- 5.1.整合集成kafka客户端
- 5.2.生产者同步异步分区拦截
- 5.3.生产者事务处理
- 5.4.KafkaListener详解
- 5.5.Header及sendTo
- 5.5.监听器模式及偏移量提交
- 5.3.消费监听器的异常处理
- 5.6.JSON序列化日期问题处理
- 六、kafka安全认证
- 6.1.用户名密码PLAIN认证
- 6.2.SCRAM认证
- 6.3.Kerberos认证(撰写中)
- 七、kafka运维配置管理
- 7.1.topic管理命令
- 7.2.KafkaTool带界面管理工具
- 7.3.LogiKM企业级监控管理(撰写中)
- 附录
- linux虚拟机集群的搭建
- 笔者其他作品推荐
- vue深入浅出系列
- 手摸手教你Spring Boot2.0
- Spring Security-JWT-OAuth2一本通
- 实战前后端分离RBAC权限管理系统
- 实战SpringCloud微服务从青铜到王者
- 送书活动