# namespace 与 rootfs
## namespace
这段小程序的作用是,在创建子进程时开启指定的 Namespace。
在 main 函数里,我们通过 clone() 系统调用创建了一个新的子进程 container_main,并且声明要为它启用 Mount Namespace(即:CLONE_NEWNS 标志)。而这个子进程执行的,是一个“/bin/bash”程序,也就是一个 shell。所以这个 shell 就运行在了 Mount Namespace 的隔离环境中。
## ns.c
```
#define _GNU_SOURCE
#include <sys/mount.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
// One
// int container_main(void* arg)
// {
// printf("Container - inside the container!\n");
// execv(container_args[0], container_args);
// printf("Something's wrong!\n");
// return 1;
// }
int container_main(void* arg)
{
printf("Container - inside the container!\n");
mount("none", "/tmp", "tmpfs", 0, "");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
printf("Parent - start a container!\n");
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWNS | SIGCHLD , NULL);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
```
## 编译测试
```
$ gcc -o ns ns.c
$ ./ns
Parent - start a container!
Container - inside the container!
```
```
root@ubuntu-xenial:~/mkdocker# df -Th | grep tmpfs
none tmpfs 496M 0 496M 0% /tmp
```
> Mount Namespace 跟其他 Namespace 的使用略有不同的地方对容器进程视图的改变,一定是伴随着挂载操作(mount)才能生效。
假设,我们现在有一个 目录,想要把它作为一个 /bin/bash 进程的根目录。
首先,创建几个 lib 文件夹:
```
$ mkdir -p $HOME/{bin,lib64,lib/x86_64-linux-gnu}
$ cd $HOME
```
然后,把 bash 命令拷贝到 test 目录对应的 bin 路径下:
```
$ cp -v /bin/{bash,ls} $HOME/bin
```
接下来,把 bash 命令需要的所有 so 文件,也拷贝到 test 目录对应的 lib 路径下。找到 so 文件可以用 ldd 命令:
```
$ list="$(ldd /bin/ls | egrep -o '/lib.*\.[0-9]')"
$ for i in $list; do cp -v "$i" "${home}${i}"; done
$ list="$(ldd /bin/bash | egrep -o '/lib.*\.[0-9]')"
$ for i in $list; do cp -v "$i" "${home}${i}"; done
```
最后,执行 chroot 命令,告诉操作系统,我们将使用 $HOME/ 目录作为 /bin/bash 进程的根目录:
```
$ chroot $HOME /bin/bash
```
这时,你如果执行 "ls /",就会看到,它返回的都是 `$HOME/ `目录下面的内容,而不是宿主机的内容。更重要的是,对于被 chroot 的进程来说,它并不会感受到自己的根目录已经被“修改”成$HOME 了。这种视图被修改的原理,和 Linux Namespace 很类似,实际上,Mount Namespace 正是基于对 chroot 的不断改良才被发明出来的,它也是 Linux操作系统里的第一个 Namespace。当然,为了能够让容器的这个根目录看起来更“真实”,我们一般会在这个容器的根目录下挂载一个完整操作系统的文件系统,比如 Ubuntu16.04 的 ISO。
## rootfs
而这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
所以,一个最常见的 rootfs,或者说容器镜像,会包括如下所示的一些目录和文件,比如/bin,/etc,/proc 等等。
对 Docker 项目来说,它最核心的原理实际上有以下三点:
* 启用 Linux Namespace 配置;
* 设置指定的 Cgroups 参数;
* 切换进程的根目录(Change Root)
这样,一个完整的容器就诞生了。不过,Docker 项目在最后一步的切换上会优先使用 pivot_root 系统调用,如果系统不支持,才会使用 chroot。
另外,需要明确的是,rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。
Docker 公司在实现 Docker 镜像时并没有沿用以前制作 rootfs 的标准流程,而是做了一个小小的创新:
当然,这个想法不是凭空臆造出来的,而是用到了一种叫作联合文件系统(Union FileSystem)的能力。
Union File System 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union
mount)到同一个目录下。比如,我现在有两个目录 A 和 B,它们分别有两个文件:
```
$ tree
.
├──A
│ ├── a
│ └── x
└── B
├── b
└── x
```
然后,我使用联合挂载的方式,将这两个目录挂载到一个公共的目录 C 上:
Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
AuFS 的全称是 Another UnionFS,后改名为 Alternative UnionFS,再后来干脆改名叫作Advance UnionFS,从这些名字中你应该能看出这样两个事实:
对于 AuFS 来说,它最关键的目录结构在 /var/lib/docker 路径下的 diff 目录:
```
/var/lib/docker/aufs/diff/<layer_id>
```
而这个目录的作用,我们不妨通过一个具体例子来看一下。现在,我们启动一个容器,比如:
```
$ docker run -d ubuntu:latest sleep 3600
$ docker image inspect ubuntu:latest
```
这个所谓的“镜像”,实际上就是一个 Ubuntu 操作系统的 rootfs,它的内容是 Ubuntu 操作系统的所有文件和目录。不过,与之前我们讲述的 rootfs 稍微不同的是,Docker 镜像使用的
rootfs,往往由多个“层”组成:
```
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:f49017d4d5ce9c0f544c...",
"sha256:8f2b771487e9d6354080...",
"sha256:ccd4d61916aaa2159429...",
"sha256:c01d74f99de40e097c73...",
"sha256:268a067217b5fe78e000..."
]
}
```
可以看到,这个 Ubuntu 镜像,实际上由五个层组成。这五个层就是五个增量 rootfs,每一层都是 Ubuntu 操作系统文件与目录的一部分;而在使用镜像时,Docker 会把这些增量联合挂载
在一个统一的挂载点上(等价于前面例子里的“/C”目录)。这个挂载点就是 /var/lib/docker/aufs/mnt/,比如:
这个目录里面正是一个完整的 Ubuntu 操作系统:那么,前面提到的五个镜像层,又是如何被联合挂载成这样一个完整的 Ubuntu 文件系统的呢?
这个信息记录在 AuFS 的系统目录 /sys/fs/aufs 下面。
```
$ ls /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce645b3
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
```
```
$ cat /proc/mounts| grep aufs
none /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fc... aufs rw,relatime,si=972c6d361e6b32ba
```
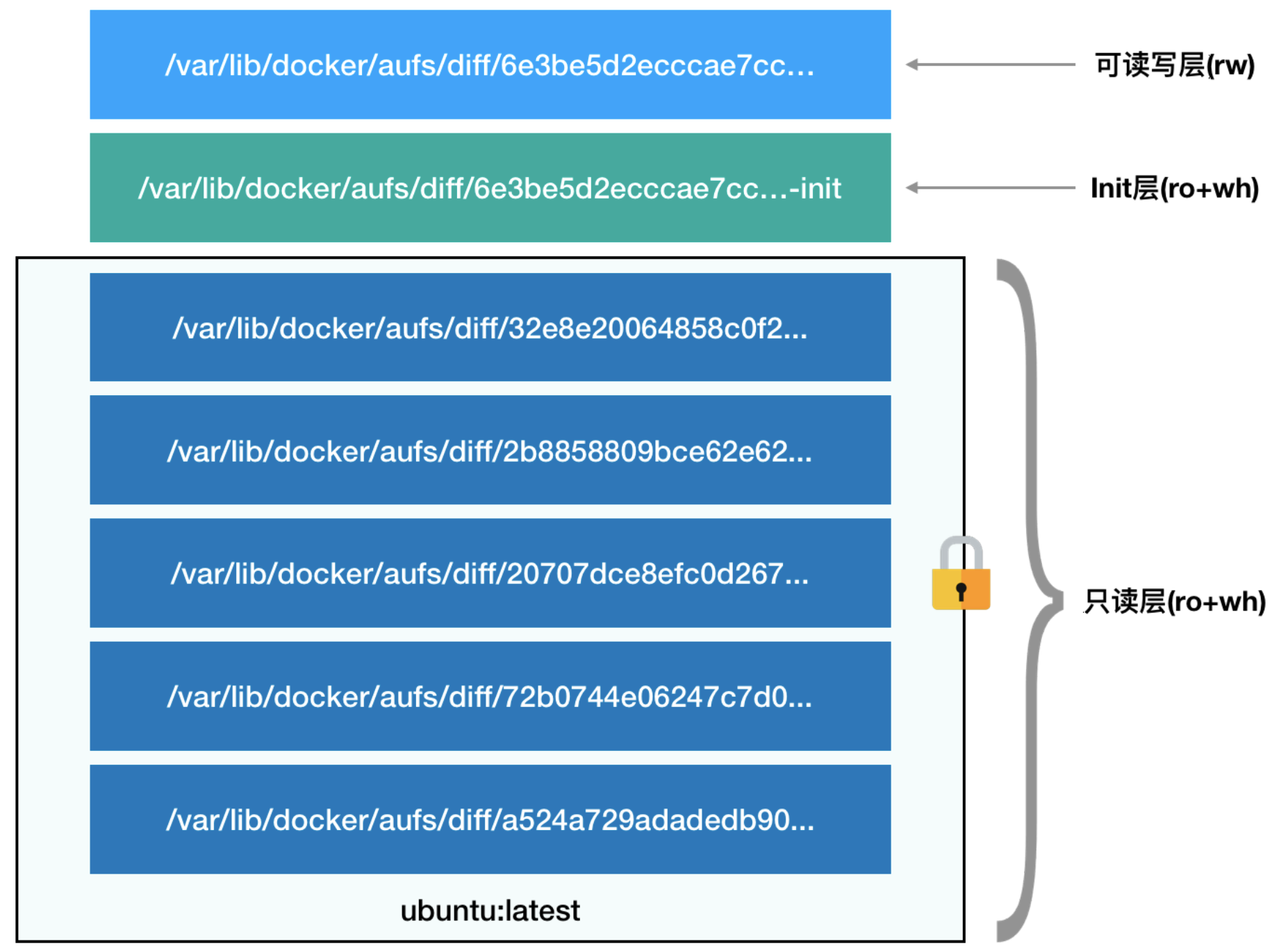
### 第一部分,只读层
它是这个容器的 rootfs 最下面的五层,对应的正是 ubuntu:latest 镜像的五层。可以看到,它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout)。这时,我们可以分别查看一下这些层的内容。可以看到,这些层,都以增量的方式分别包含了 Ubuntu 操作系统的一部分。
```
$ ls /var/lib/docker/aufs/diff/72b0744e06247c7d0...
etc sbin usr var
$ ls /var/lib/docker/aufs/diff/32e8e20064858c0f2...
run
$ ls /var/lib/docker/aufs/diff/a524a729adadedb900...
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
```
### 第二部分,可读写层
它是这个容器的 rootfs 最上面的一层(6e3be5d2ecccae7cc),它的挂载方式为:rw,即read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。可是,你有没有想到这样一个问题:如果我现在要做的,是删除只读层里的一个文件呢?为了实现这样的删除操作,AuFS 会在可读写层创建一个 whiteout 文件,把只读层里的文件“遮挡”起来。
比如,你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件“遮挡”起来,“消失”了。这个功能,就是“ro+wh”的挂载方式,即只读 +whiteout 的含义。我喜欢把 whiteout 形象地翻译为:“白障”。
所以,最上面这个可读写层的作用,就是专门用来存放你修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里。而当我们使用完了这个被修改过的容器之后,还可以使用 docker commit 和 push 指令,保存这个被修改过的可读写层,并上传到 Docker Hub 上,供其他人使用;而与此同时,原先的只读层里的内容则不会有任何变化。这,就是增量 rootfs 的好处。、
### 第三部分,Init 层
它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 `/etc/hosts、/etc/resolv.conf `等信息。需要这样一层的原因是,这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息连同可读写层一起提交掉。
所以,Docker 做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行 docker commit 只会提交可读写层,所以是不包含这些内容的。
最终,这 7 个层都被联合挂载到 /var/lib/docker/aufs/mnt 目录下,表现为一个完整的Ubuntu 操作系统供容器使用。
