1.这里用的是 **scrapy** 这个网页爬虫框架,首先要安装好**scrapy**,这个安装过程比较曲折,可以去看看网上的其他教程。
2.安装好了之后,创建第一个**scrapy**项目,这里我们需要一个命令行创建就可以了,
`scrapy startproject demo`
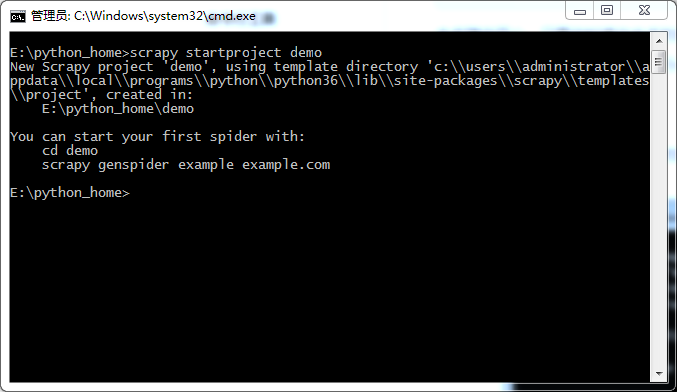
这里,我们的项目就创建成功了。然后就可以看到我们创建的项目了。
3.项目的目录结构是这样子的,
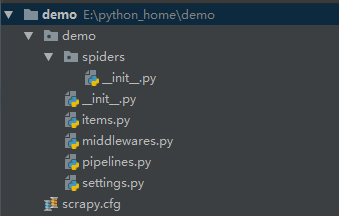
先介绍下目录结构:
(1) demo/: 该项目的python模块。
(2) scrapy.cfg: 项目的配置文件
(3) demo/items.py: 项目中的item文件。
(4) demo/pipelines.py: 项目中的pipelines文件。
(5) demo/settings.py: 项目的设置文件
(6) demo/spiders/: 放置spider代码的目录
(7) demo/middlewares.py:中间件。
具体的功能之后再介绍。
4.接下来,在**spiders**目录下新建个python文件。名字可以自定义。代码如下
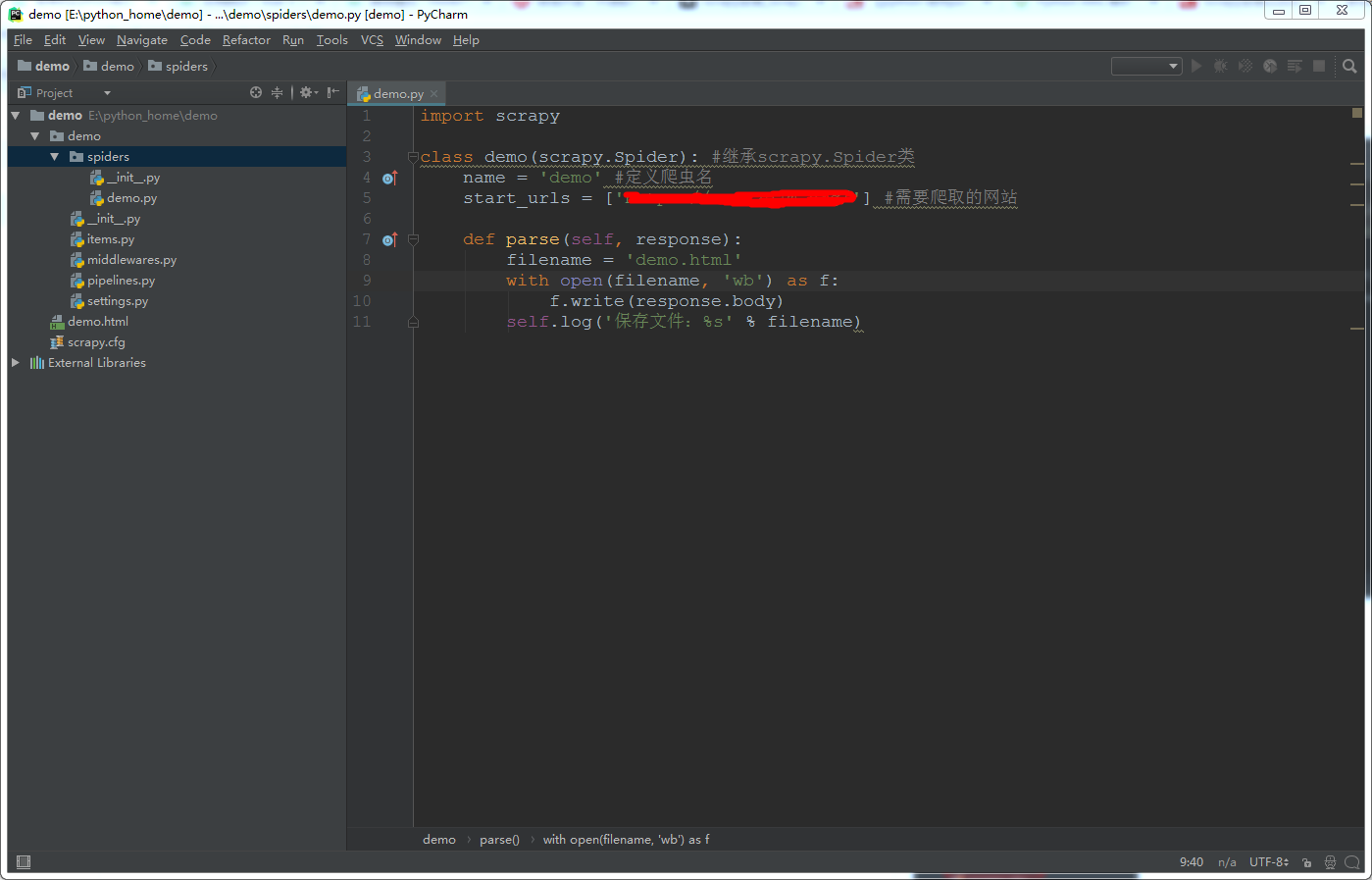
运行命令`scrapy crawl demo`成功之后,我们就可以看到我们爬取的数据了
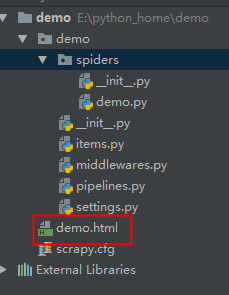
后面,我们再介绍如何爬取关键的数据
爬取过程中,如果爬取不成功,出现 [DEBUG: Forbidden by robots.txt:错误],那就关闭scrapy自带的ROBOTSTXT_OBEY 功能,修改配置文件 settings.py, 将 ROBOTSTXT_OBEY 设置为False。
填入header信息,伪装成浏览器
`DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36',
}
~~~`
重新运行就可以了~
