Lisp 实际上是两种语言:一种能写出快速执行的程序,一种则能让你快速的写出程序。 在程序开发的早期阶段,你可以为了开发上的便捷舍弃程序的执行速度。一旦程序的结构开始固化,你就可以精炼其中的关键部分以使得它们执行的更快。
由于各个 Common Lisp 实现间的差异,很难针对优化给出通用的建议。在一个实现上使程序变快的修改也许在另一个实现上会使得程序变慢。这是难免的事儿。越强大的语言,离机器底层就越远,离机器底层越远,语言的不同实现沿着不同路径趋向它的可能性就越大。因此,即便有一些技巧几乎一定能够让程序运行的更快,本章的目的也只是建议而不是规定。
[TOC]
## 13.1 瓶颈规则 (The Bottleneck Rule)[](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#the-bottleneck-rule "Permalink to this headline")
不管是什么实现,关于优化都可以整理出三点规则:它应该关注瓶颈,它不应该开始的太早,它应该始于算法。
也许关于优化最重要的事情就是要意识到,程序中的大部分执行时间都是被少数瓶颈所消耗掉的。 正如[高德纳](http://en.wikipedia.org/wiki/Donald_Knuth)所说,“在一个与 I/O 无关 (Non-I/O bound) 的程序中,大部分的运行时间集中在大概 3% 的源代码中。” [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-213) 优化程序的这一部分将会使得它的运行速度明显的提升;相反,优化程序的其他部分则是在浪费时间。
因此,优化程序时关键的第一步就是找到瓶颈。许多 Lisp 实现都提供性能分析器 (profiler) 来监视程序的运行并报告每一部分所花费的时间量。 为了写出最为高效的代码,性能分析器非常重要,甚至是必不可少的。 如果你所使用的 Lisp 实现带有性能分析器,那么请在进行优化时使用它。另一方面,如果实现没有提供性能分析器的话,那么你就不得不通过猜测来寻找瓶颈,而且这种猜测往往都是错的!
瓶颈规则的一个推论是,不应该在程序的初期花费太多的精力在优化上。[高德纳](http://en.wikipedia.org/wiki/Donald_Knuth)对此深信不疑:“过早的优化是一切 (至少是大多数) 问题的源头。” [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-214) 在刚开始写程序的时候,通常很难看清真正的瓶颈在哪,如果这个时候进行优化,你很可能是在浪费时间。优化也会使程序的修改变得更加困难,边写程序边优化就像是在用风干非常快的颜料来画画一样。
在适当的时候做适当的事情,可以让你写出更优秀的程序。 Lisp 的一个优点就是能让你用两种不同的工作方式来进行开发:很快地写出运行较慢的代码,或者,放慢写程序的速度,精雕细琢,从而得出运行得较快的代码。
在程序开发的初期阶段,工作通常在第一种模式下进行,只有当性能成为问题的时候,才切换到第二种模式。 对于非常底层的语言,比如汇编,你必须优化程序的每一行。但这么做会浪费你大部分的精力,因为瓶颈仅仅是其中很小的那部分代码。一个更加抽象的语言能够让你把主要精力集中在瓶颈上, 达到事半功倍的效果。
当真正开始优化的时候,还必须从最顶端入手。 在使用各种低层次的编码技巧 (low-level coding tricks) 之前,请先确保你已经使用了最为高效的算法。 这么做的潜在好处相当大 ── 甚至可能大到你都不再需要玩那些奇淫技巧。 当然本规则还是要和前一个规则保持平衡。 有些时候,关于算法的决策必须尽早进行。
## 13.2 编译 (Compilation)[](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#compilation "Permalink to this headline")
有五个参数可以控制代码的编译方式: *speed* (速度)代表编译器产生代码的速度; *compilation-speed* (编译速度)代表程序被编译的速度; *safety* (安全) 代表要对目标代码进行错误检查的数量; *space* (空间)代表目标代码的大小和内存需求量;最后, *debug* (调试)代表为了调试而保留的信息量。
交互与解释 (INTERACTIVE VS. INTERPRETED)
Lisp 是一种交互式语言 (Interactive Language),但是交互式的语言不必都是解释型的。早期的 Lisp 都通过解释器实现,因此认为 Lisp 的特质都依赖于它是被解释的想法就这么产生了。但这种想法是错误的:Common Lisp 既是编译型语言,又是解释型语言。
至少有两种 Common Lisp 实现甚至都不包含解释器。在这些实现中,输入到顶层的表达式在求值前会被编译。因此,把顶层叫做解释器的这种说法,不仅是落伍的,甚至还是错误的。
编译参数不是真正的变量。它们在声明中被分配从 `0` (最不重要) 到 `3` (最重要) 的权值。如果一个主要的瓶颈发生在某个函数的内层循环中,我们或许可以添加如下的声明:
~~~
(defun bottleneck (...)
(do (...)
(...)
(do (...)
(...)
(declare (optimize (speed 3) (safety 0)))
...)))
~~~
一般情况下,应该在代码写完并且经过完善测试之后,才考虑加上那么一句声明。
要让代码在任何情况下都尽可能地快,可以使用如下声明:
~~~
(declaim (optimize (speed 3)
(compilation-speed 0)
(safety 0)
(debug 0)))
~~~
考虑到前面提到的瓶颈规则 [[1]](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#id9) ,这种苛刻的做法可能并没有什么必要。
另一类特别重要的优化就是由 Lisp 编译器完成的尾递归优化。当 *speed* (速度)的权值最大时,所有支持尾递归优化的编译器都将保证对代码进行这种优化。
如果在一个调用返回时调用者中没有残余的计算,该调用就被称为尾递归。下面的代码返回列表的长度:
~~~
(defun length/r (lst)
(if (null lst)
0
(1+ (length/r (cdr lst)))))
~~~
这个递归调用不是尾递归,因为当它返回以后,它的值必须传给 `1+` 。相反,这是一个尾递归的版本,
~~~
(defun length/rt (lst)
(labels ((len (lst acc)
(if (null lst)
acc
(len (cdr lst) (1+ acc)))))
(len lst 0)))
~~~
更准确地说,局部函数 `len` 是尾递归调用,因为当它返回时,调用函数已经没什么事情可做了。 和 `length/r` 不同的是,它不是在递归回溯的时候构建返回值,而是在递归调用的过程中积累返回值。 在函数的最后一次递归调用结束之后, `acc` 参数就可以作为函数的结果值被返回。
出色的编译器能够将一个尾递归编译成一个跳转 (goto),因此也能将一个尾递归函数编译成一个循环。在典型的机器语言代码中,当第一次执行到表示 `len` 的指令片段时,栈上会有信息指示在返回时要做些什么。由于在递归调用后没有残余的计算,该信息对第二层调用仍然有效:第二层调用返回后我们要做的仅仅就是从第一层调用返回。 因此,当进行第二层调用时,我们只需给参数设置新的值,然后跳转到函数的起始处继续执行就可以了,没有必要进行真正的函数调用。
另一个利用函数调用抽象,却没有开销的方法是使函数内联编译。对于那些调用开销比函数体的执行代价还高的小型函数来说,这种技术非常有价值。例如,以下代码用于判断列表是否仅有一个元素:
~~~
(declaim (inline single?))
(defun single? (lst)
(and (consp lst) (null (cdr lst))))
~~~
因为这个函数是在全局被声明为内联的,引用了 `single?` 的函数在编译后将不需要真正的函数调用。 [[2]](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#id10) 如果我们定义一个调用它的函数,
~~~
(defun foo (x)
(single? (bar x)))
~~~
当 `foo` 被编译后, `single?` 函数体中的代码将会被编译进 `foo` 的函数体,就好像我们直接写以下代码一样:
~~~
(defun foo (x)
(let ((lst (bar x)))
(and (consp lst) (null (cdr lst)))))
~~~
内联编译有两个限制: 首先,递归函数不能内联。 其次,如果一个内联函数被重新定义,我们就必须重新编译调用它的任何函数,否则调用仍然使用原来的定义。
在一些早期的 Lisp 方言中,有时候会使用宏( 10.2 节)来避免函数调用。这种做法在 Common Lisp 中通常是没有必要的。
不同 Lisp 编译器的优化方式千差万别。 如果你想了解你的编译器为某个函数生成的代码,试着调用 `disassemble` 函数:它接受一个函数或者函数名,并显示该函数编译后的形式。 即便你看到的东西是完全无法理解的,你仍然可以使用 `disassemble` 来判断声明是否起效果:编译函数的两个版本,一个使用优化声明,另一个不使用优化声明,然后观察由 `disassemble` 显示的两组代码之间是否有差异。 同样的技巧也可以用于检验函数是否被内联编译。 不论情况如何,都请优先考虑使用编译参数,而不是手动调优的方式来优化代码。
## 13.3 类型声明 (Type Declarations)[](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#type-declarations "Permalink to this headline")
如果 Lisp 不是你所学的第一门编程语言,那么你也许会感到困惑,为什么这本书还没说到类型声明这件事来?毕竟,在很多流行的编程语言中,类型声明是必须要做的。
在不少编程语言里,你必须为每个变量声明类型,并且变量也只可以持有与该类型相一致的值。 这种语言被称为*强类型*(*strongly typed*) 语言。 除了给程序员们徒增了许多负担外,这种方式还限制了你能做的事情。 使用这种语言,很难写出那些需要多种类型的参数一起工作的函数,也很难定义出可以包含不同种类元素的数据结构。 当然,这种方式也有它的优势,比如无论何时当编译器碰到一个加法运算,它都能够事先知道这是一个什么类型的加法运算。如果两个参数都是整数类型,编译器可以直接在目标代码中生成一个固定 (hard-wire) 的整数加法运算。
正如 2.15 节所讲,Common Lisp 使用一种更加灵活的方式:显式类型 (manifest typing) [[3]](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#id11) 。有类型的是值而不是变量。变量可以用于任何类型的对象。
当然,这种灵活性需要付出一定的速度作为代价。 由于 `+` 可以接受好几种不同类型的数,它不得不在运行时查看每个参数的类型来决定采用哪种加法运算。
在某些时候,如果我们要执行的全都是整数的加法,那么每次查看参数类型的这种做法就说不上高效了。 Common Lisp 处理这种问题的方法是:让程序员尽可能地提示编译器。 比如说,如果我们提前就能知道某个加法运算的两个参数是定长数 (fixnums) ,那么就可以对此进行声明,这样编译器就会像 C 语言的那样为我们生成一个固定的整数加法运算。
因为显式类型也可以通过声明类型来生成高效的代码,所以强类型和显式类型两种方式之间的差别并不在于运行速度。 真正的区别是,在强类型语言中,类型声明是强制性的,而显式类型则不强加这样的要求。 在 Common Lisp 中,类型声明完全是可选的。它们可以让程序运行的更快,但(除非错误)不会改变程序的行为。
全局声明以 `declaim` 伴随一个或多个声明的形式来实现。一个类型声明是一个列表,包含了符号 `type` ,后跟一个类型名,以及一个或多个变量组成。举个例子,要为一个全局变量声明类型,可以这么写:
~~~
(declaim (type fixnum *count*))
~~~
在 ANSI Common Lisp 中,可以省略 `type` 符号,将声明简写为:
~~~
(declaim (fixnum *count*))
~~~
局部声明通过 `declare` 完成,它接受的参数和 `declaim` 的一样。 声明可以放在那些创建变量的代码体之前:如 `defun` 、 `lambda` 、`let` 、 `do` ,诸如此类。 比如说,要把一个函数的参数声明为定长数,可以这么写:
~~~
(defun poly (a b x)
(declare (fixnum a b x))
(+ (* a (expt x 2)) (* b x)))
~~~
在类型声明中的变量名指的就是该声明所在的上下文中的那个变量 ── 那个通过赋值可以改变它的值的变量。
你也可以通过 `the` 为某个表达式的值声明类型。 如果我们提前就知道 `a` 、 `b` 和 `x` 是足够小的定长数,并且它们的和也是定长数的话,那么可以进行以下声明:
~~~
(defun poly (a b x)
(declare (fixnum a b x))
(the fixnum (+ (the fixnum (* a (the fixnum (expt x 2))))
(the fixnum (* b x)))))
~~~
看起来是不是很笨拙啊?幸运的是有两个原因让你很少会这样使用 `the` 把你的数值运算代码变得散乱不堪。其一是很容易通过宏,来帮你插入这些声明。其二是某些实现使用了特殊的技巧,即便没有类型声明的定长数运算也能足够快。
Common Lisp 中有相当多的类型 ── 恐怕有无数种类型那么多,如果考虑到你可以自己定义新的类型的话。 类型声明只在少数情况下至关重要,可以遵照以下两条规则来进行:
1. 当函数可以接受若干不同类型的参数(但不是所有类型)时,可以对参数的类型进行声明。如果你知道一个对 `+` 的调用总是接受定长数类型的参数,或者一个对 `aref` 的调用第一个参数总是某种特定种类的数组,那么进行类型声明是值得的。
2. 通常来说,只有对类型层级中接近底层的类型进行声明,才是值得的:将某个东西的类型声明为 `fixnum` 或者 `simple-array` 也许有用,但将某个东西的类型声明为 `integer` 或者 `sequence` 或许就没用了。
类型声明对内容复杂的对象特别重要,这包括数组、结构和对象实例。这些声明可以在两个方面提升效率:除了可以让编译器来决定函数参数的类型以外,它们也使得这些对象可以在内存中更高效地表示。
如果对数组元素的类型一无所知的话,这些元素在内存中就不得不用一块指针来表示。但假如预先就知道数组包含的元素仅仅是 ── 比方说 ── 双精度浮点数 (double-floats),那么这个数组就可以用一组实际的双精度浮点数来表示。这样数组将占用更少的空间,因为我们不再需要额外的指针指向每一个双精度浮点数;同时,对数组元素的访问也将更快,因为我们不必沿着指针去读取和写元素。
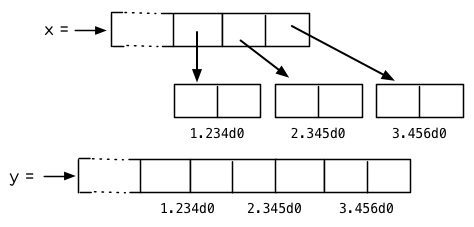
**图 13.1:指定元素类型的效果**
你可以通过 `make-array` 的 `:element-type` 参数指定数组包含值的种类。这样的数组被称为*特化数组*(specialized array)。 图 13.1 为我们展示了如下代码在多数实现上求值后发生的事情:
~~~
(setf x (vector 1.234d0 2.345d0 3.456d0)
y (make-array 3 :element-type 'double-float)
(aref y 0) 1.234d0
(aref y 1) 2.345d0
(aref y 2)3.456d0))
~~~
图 13.1 中的每一个矩形方格代表内存中的一个字 (a word of memory)。这两个数组都由未特别指明长度的头部 (header) 以及后续 三个元素的某种表示构成。对于 `x` 来说,每个元素都由一个指针表示。此时每个指针碰巧都指向双精度浮点数,但实际上我们可以存储任何类型的对象到这个向量中。对 `y` 来说,每个元素实际上都是双精度浮点数。 `y` 更快而且占用更少空间,但意味着它的元素只能是双精度浮点数。
注意我们使用 `aref` 来引用 `y` 的元素。一个特化的向量不再是一个简单向量,因此我们不再能够通过 `svref` 来引用它的元素。
除了在创建数组时指定元素的类型,你还应该在使用数组的代码中声明数组的维度以及它的元素类型。一个完整的向量声明如下:
~~~
(declare (type (vector fixnum 20) v))
~~~
以上代码声明了一个仅含有定长数,并且长度固定为 `20` 的向量。
~~~
(setf a (make-array '(1000 1000)
:element-type 'single-float
:initial-element 1.0s0))
(defun sum-elts (a)
(declare (type (simple-array single-float (1000 1000))
a))
(let ((sum 0.0s0))
(declare (type single-float sum))
(dotimes (r 1000)
(dotimes (c 1000)
(incf sum (aref a r c))))
sum))
~~~
**图 13.2 对数组元素求和**
最为通用的数组声明形式由数组类型以及紧接其后的元素类型和一个维度列表构成:
~~~
(declare (type (simple-array fixnum (4 4)) ar))
~~~
图 13.2 展示了如何创建一个 1000×1000 的单精度浮点数数组,以及如何编写一个将该数组元素相加的函数。数组以行主序 (row-major order)存储,遍历时也应尽可能按此顺序进行。
我们将用 `time` 来比较 `sum-elts` 在有声明和无声明两种情况下的性能。 `time` 宏显示表达式求值所花费时间的某种度量(取决于实现)。对被编译的函数求取时间才是有意义的。在某个实现中,如果我们以获取最快速代码的编译参数编译 `sum-elts` ,它将在不到半秒的时间内返回:
~~~
> (time (sum-elts a))
User Run Time = 0.43 seconds
1000000.0
~~~
如果我们把 *sum-elts* 中的类型声明去掉并重新编译它,同样的计算将花费超过5秒的时间:
~~~
> (time (sum-elts a))
User Run Time = 5.17 seconds
1000000.0
~~~
类型声明的重要性 ── 特别是对数组和数来说 ── 怎么强调都不过分。上面的例子中,仅仅两行代码就可以让 `sum-elts` 变快 12 倍。
## 13.4 避免垃圾 (Garbage Avoidance)[](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#garbage-avoidance "Permalink to this headline")
Lisp 除了可以让你推迟考虑变量的类型以外,它还允许你推迟对内存分配的考虑。 在程序的早期阶段,暂时忽略内存分配和臭虫等问题,将有助于解放你的想象力。 等到程序基本固定下来以后,就可以开始考虑怎么减少动态分配,从而让程序运行得更快。
但是,并不是构造(consing)用得少的程序就一定快。 多数 Lisp 实现一直使用着差劲的垃圾回收器,在这些实现中,过多的内存分配容易让程序运行变得缓慢。 因此,『高效的程序应该尽可能地减少 `cons` 的使用』这种观点,逐渐成为了一种传统。 最近这种传统开始有所改变,因为一些实现已经用上了相当先进(sophisticated)的垃圾回收器,它们实行一种更为高效的策略:创建新的对象,用完之后抛弃而不是进行回收。
本节介绍了几种方法,用于减少程序中的构造。 但构造数量的减少是否有利于加快程序的运行,这一点最终还是取决于实现。 最好的办法就是自己去试一试。
减少构造的办法有很多种。 有些办法对程序的修改非常少。 例如,最简单的方法就是使用破坏性函数。 下表罗列了一些常用的函数,以及这些函数对应的破坏性版本。
| 安全 | 破坏性 |
| --- | --- |
| append | nconc |
| reverse | nreverse |
| remove | delete |
| remove-if | delete-if |
| remove-duplicates | delete-duplicates |
| subst | nsubst |
| subst-if | nsubst-if |
| union | nunion |
| intersection | nintersection |
| set-difference | nset-difference |
当确认修改列表是安全的时候,可以使用 `delete` 替换 `remove` ,用 `nreverse` 替换 `reverse` ,诸如此类。
即便你想完全摆脱构造,你也不必放弃在运行中 (on the fly)创建对象的可能性。 你需要做的是避免在运行中为它们分配空间和通过垃圾回收收回空间。通用方案是你自己预先分配内存块 (block of memory),以及明确回收用过的块。*预先*可能意味着在编译期或者某些初始化例程中。具体情况还应具体分析。
例如,当情况允许我们利用一个有限大小的堆栈时,我们可以让堆栈在一个已经分配了空间的向量中增长或缩减,而不是构造它。Common Lisp 内置支持把向量作为堆栈使用。如果我们传给 `make-array` 可选的 `fill-pointer` 参数,我们将得到一个看起来可扩展的向量。 `make-array` 的第一个参数指定了分配给向量的存储量,而 `fill-pointer` 指定了初始有效长度:
~~~
> (setf *print-array* t)
T
> (setf vec (make-array 10 :fill-pointer 2
:initial-element nil))
#(NIL NIL)
~~~
我们刚刚制造的向量对于操作序列的函数来说,仍好像只含有两个元素,
~~~
> (length vec)
2
~~~
但它能够增长直到十个元素。因为 `vec` 有一个填充指针,我们可以使用 `vector-push` 和 `vector-pop` 函数推入和弹出元素,就像它是一个列表一样:
~~~
> (vector-push 'a vec)
2
> vec
#(NIL NIL A)
> (vector-pop vec)
A
> vec
#(NIL NIL)
~~~
当我们调用 `vector-push` 时,它增加填充指针并返回它过去的值。只要填充指针小于 `make-array` 的第一个参数,我们就可以向这个向量中推入新元素;当空间用尽时, `vector-push` 返回 `nil` 。目前我们还可以向 `vec` 中推入八个元素。
使用带有填充指针的向量有一个缺点,就是它们不再是简单向量了。我们不得不使用 `aref` 来代替 `svref` 引用元素。代价需要和潜在的收益保持平衡。
~~~
(defconstant dict (make-array 25000 :fill-pointer 0))
(defun read-words (from)
(setf (fill-pointer dict) 0)
(with-open-file (in from :direction :input)
(do ((w (read-line in nil :eof)
(read-line in nil :eof)))
((eql w :eof))
(vector-push w dict))))
(defun xform (fn seq) (map-into seq fn seq))
(defun write-words (to)
(with-open-file (out to :direction :output
:if-exists :supersede)
(map nil #'(lambda (x)
(fresh-line out)
(princ x out))
(xform #'nreverse
(sort (xform #'nreverse dict)
#'string<)))))
~~~
**图 13.3 生成同韵字辞典**
当应用涉及很长的序列时,你可以用 `map-into` 代替 `map` 。 `map-into` 的第一个参数不是一个序列类型,而是用来存储结果的,实际的序列。这个序列可以是该函数接受的其他序列参数中的任何一个。所以,打个比方,如果你想为一个向量的每个元素加 1,你可以这么写:
~~~
(setf v (map-into v #'1+ v))
~~~
图 13.3 展示了一个使用大向量应用的例子:一个生成简单的同韵字辞典 (或者更确切的说,一个不完全韵辞典)的程序。函数 `read-line` 从一个每行仅含有一个单词的文件中读取单词,而函数 `write-words` 将它们按照字母的逆序打印出来。比如,输出的起始可能是
~~~
a amoeba alba samba marimba...
~~~
结束是
~~~
...megahertz gigahertz jazz buzz fuzz
~~~
利用填充指针和 `map-into` ,我们可以把程序写的既简单又高效。
在数值应用中要当心大数 (bignums)。大数运算需要构造,因此也就会比较慢。 即使程序的最后结果为大数,但是,通过调整计算,将中间结果保存在定长数中,这种优化也是有可能的。
另一个避免垃圾回收的方法是,鼓励编译器在栈上分配对象而不是在堆上。 如果你知道只是临时需要某个东西,你可以通过将它声明为 `dynamic extent` 来避免在堆上分配空间。
通过一个动态范围 (dynamic extent)变量声明,你告诉编译器,变量的值应该和变量保持相同的生命期。 什么时候值的生命期比变量长呢?这里有个例子:
~~~
(defun our-reverse (lst)
(let ((rev nil))
(dolist (x lst)
(push x rev))
rev))
~~~
在 `our-reverse` 中,作为参数传入的列表以逆序被收集到 `rev` 中。当函数返回时,变量 `rev` 将不复存在。 然而,它的值 ── 一个逆序的列表 ── 将继续存活:它被送回调用函数,一个知道它的命运何去何从的地方。
相比之下,考虑如下 `adjoin` 实现:
~~~
(defun our-adjoin (obj lst &rest args)
(if (apply #'member obj lst args)
lst
(cons obj lst)))
~~~
在这个例子里,我们可以从函数的定义看出, `args` 参数中的值 (列表) 哪儿也没去。它不必比存储它的变量活的更久。在这种情形下把它声明为动态范围的就比较有意义。如果我们加上这样的声明:
~~~
(defun our-adjoin (obj lst &rest args)
(declare (dynamic-extent args))
(if (apply #'member obj lst args)
lst
(cons obj lst)))
~~~
那么编译器就可以 (但不是必须)在栈上为 `args` 分配空间,在 `our-adjoin` 返回后,它将自动被释放。
## 13.5 示例: 存储池 (Example: Pools)[](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#example-pools "Permalink to this headline")
对于涉及数据结构的应用,你可以通过在一个存储池 (pool)中预先分配一定数量的结构来避免动态分配。当你需要一个结构时,你从池中取得一份,当你用完后,再把它送回池中。为了演示存储池的使用,我们将快速的编写一段记录港口中船舶数量的程序原型 (prototype of a program),然后用存储池的方式重写它。
~~~
(defparameter *harbor* nil)
(defstruct ship
name flag tons)
(defun enter (n f d)
(push (make-ship :name n :flag f :tons d)
*harbor*))
(defun find-ship (n)
(find n *harbor* :key #'ship-name))
(defun leave (n)
(setf *harbor*
(delete (find-ship n) *harbor*)))
~~~
**图 13.4 港口**
图 13.4 中展示的是第一个版本。 全局变量 `harbor` 是一个船只的列表, 每一艘船只由一个 `ship` 结构表示。 函数 `enter` 在船只进入港口时被调用; `find-ship` 根据给定名字 (如果有的话) 来寻找对应的船只;最后, `leave` 在船只离开港口时被调用。
一个程序的初始版本这么写简直是棒呆了,但它会产生许多的垃圾。当这个程序运行时,它会在两个方面构造:当船只进入港口时,新的结构将会被分配;而 `harbor` 的每一次增大都需要使用构造。
我们可以通过在编译期分配空间来消除这两种构造的源头 (sources of consing)。图 13.5 展示了程序的第二个版本,它根本不会构造。
~~~
(defconstant pool (make-array 1000 :fill-pointer t))
(dotimes (i 1000)
(setf (aref pool i) (make-ship)))
(defconstant harbor (make-hash-table :size 1100
:test #'eq))
(defun enter (n f d)
(let ((s (if (plusp (length pool))
(vector-pop pool)
(make-ship))))
(setf (ship-name s) n
(ship-flag s) f
(ship-tons s) d
(gethash n harbor) s)))
(defun find-ship (n) (gethash n harbor))
(defun leave (n)
(let ((s (gethash n harbor)))
(remhash n harbor)
(vector-push s pool)))
~~~
**图 13.5 港口(第二版)**
严格说来,新的版本仍然会构造,只是不在运行期。在第二个版本中, `harbor` 从列表变成了哈希表,所以它所有的空间都在编译期分配了。 一千个 `ship` 结构体也会在编译期被创建出来,并被保存在向量池(vector pool) 中。(如果 `:fill-pointer` 参数为 `t` ,填充指针将指向向量的末尾。) 此时,当 `enter` 需要一个新的结构时,它只需从池中取来一个便是,无须再调用 `make-ship` 。 而且当`leave` 从 `harbor` 中移除一艘 `ship` 时,它把它送回池中,而不是抛弃它。
我们使用存储池的行为实际上是肩负起内存管理的工作。这是否会让我们的程序更快仍取决于我们的 Lisp 实现怎样管理内存。总的说来,只有在那些仍使用着原始垃圾回收器的实现中,或者在那些对 GC 的不可预见性比较敏感的实时应用中才值得一试。
## 13.6 快速操作符 (Fast Operators)[](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#fast-operators "Permalink to this headline")
本章一开始就宣称 Lisp 是两种不同的语言。就某种意义来讲这确实是正确的。如果你仔细看过 Common Lisp 的设计,你会发现某些特性主要是为了速度,而另外一些主要为了便捷性。
例如,你可以通过三个不同的函数取得向量给定位置上的元素: `elt` 、 `aref` 、 `svref` 。如此的多样性允许你把一个程序的性能提升到极致。 所以如果你可以使用 `svref` ,完事儿! 相反,如果对某段程序来说速度很重要的话,或许不应该调用 `elt` ,它既可以用于数组也可以用于列表。
对于列表来说,你应该调用 `nth` ,而不是 `elt` 。然而只有单一的一个函数 ── `length` ── 用于计算任何一个序列的长度。为什么 Common Lisp 不单独为列表提供一个特定的版本呢?因为如果你的程序正在计算一个列表的长度,它在速度上已经输了。在这个 例子中,就像许多其他的例子一样,语言的设计暗示了哪些会是快速的而哪些不是。
另一对相似的函数是 `eql` 和 `eq` 。前者是验证同一性 (identity) 的默认判断式,但如果你知道参数不会是字符或者数字时,使用后者其实更快。两个对象 *eq* 只有当它们处在相同的内存位置上时才成立。数字和字符可能不会与任何特定的内存位置相关,因此 `eq` 不适用于它们 (即便多数实现中它仍然能用于定长数)。对于其他任何种类的参数, `eq` 和 `eql` 将返回相同的值。
使用 `eq` 来比较对象总是最快的,因为 Lisp 所需要比较的仅仅是指向对象的指针。因此 `eq` 哈希表 (如图 13.5 所示) 应该会提供最快的访问。 在一个 `eq` 哈希表中, `gethash` 可以只根据指针查找,甚至不需要查看它们指向的是什么。然而,访问不是唯一要考虑的因素; *eq* 和 *eql* 哈希表在拷贝型垃圾回收算法 (copying garbage collection algorithm)中会引起额外的开销,因为垃圾回收后需要对一些哈希值重新进行计算 (rehashing)。如果这变成了一个问题,最好的解决方案是使用一个把定长数作为键值的 `eql` 哈希表。
当被调函数有一个余留参数时,调用 `reduce` 可能是比 `apply` 更高效的一种方式。例如,相比
~~~
(apply #'+ '(1 2 3))
~~~
写成如下可以更高效:
~~~
(reduce #'+ '(1 2 3))
~~~
它不仅有助于调用正确的函数,还有助于按照正确的方式调用它们。余留、可选和关键字参数 是昂贵的。只使用普通参数,函数调用中的参量会被调用者简单的留在被调者能够找到的地方。但其他种类的参数涉及运行时的处理。关键字参数是最差的。针对内置函数,优秀的编译器采用特殊的办法把使用关键字参量的调用编译成快速代码 (fast code)。但对于你自己编写的函数,避免在程序中对速度敏感的部分使用它们只有好处没有坏处。另外,不把大量的参量都放到余留参数中也是明智的举措,如果这可以避免的话。
不同的编译器有时也会有一些它们独到优化。例如,有些编译器可以针对键值是一个狭小范围中的整数的 `case` 语句进行优化。查看你的用户手册来了解那些实现特有的优化的建议吧。
## 13.7 二阶段开发 (Two-Phase Development)[](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#two-phase-development "Permalink to this headline")
在以速度至上的应用中,你也许想要使用诸如 C 或者汇编这样的低级语言来重写一个 Lisp 程序的某部分。你可以对用任何语言编写的程序使用这一技巧 ── C 程序的关键部分经常用汇编重写 ── 但语言越抽象,用两阶段(two phases)开发程序的好处就越明显。
Common Lisp 没有规定如何集成其他语言所编写的代码。这部分留给了实现决定,而几乎所有的实现都提供了某种方式来实现它。
使用一种语言编写程序然后用另一种语言重写它其中部分看起来可能是一种浪费。事实上,经验显示这是一种好的开发软件的方式。先针对功能、然后是速度比试着同时达成两者来的简单。
如果编程完全是一个机械的过程 ── 简单的把规格说明翻译为代码 ── 在一步中把所有的事情都搞定也许是合理的。但编程永远不是如此。不论规格说明多么精确, 编程总是涉及一定量的探索 ── 通常比任何人能预期到的还多的多。
一份好的规格说明,也许会让编程看起来像是简单的把它们翻译成代码的过程。这是一个普遍的误区。编程必定涉及探索,因为规格说明必定含糊不清。如果它们不含糊的话,它们就都算不上规格说明。
在其他领域,尽可能精准的规格说明也许是可取的。如果你要求一块金属被切割成某种形状,最好准确的说出你想要的。但这个规则不适用于软件,因为程序和规格说明由相同的东西构成:文本。你不可能编写出完全合意的规格说明。如果规格说明有那么精确的话,它们就变成程序了。 [λ](http://acl.readthedocs.org/en/latest/zhCN/notes-cn.html#notes-229)
对于存在着可观数量的探索的应用 (再一次,比任何人承认的还要多,将实现分成两个阶段是值得的。而且在第一阶段中你所使用的手段 (medium) 不必就是最后的那个。例如,制作铜像的标准方法是先从粘土开始。你先用粘土做一个塑像出来,然后用它做一个模子,在这个模子中铸造铜像。在最后的塑像中是没有丁点粘土的,但你可以从铜像的形状中认识到它发挥的作用。试想下从一开始就只用一块儿铜和一个凿子来制造这么个一模一样的塑像要多难啊!出于相同的原因,首先用 Lisp 来编写程序,然后用 C 改写它,要比从头开始就用 C 编写这个程序要好。
## Chapter 13 总结 (Summary)[](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#chapter-13-summary "Permalink to this headline")
1. 不应过早开始优化,应该关注瓶颈,而且应该从算法开始。
2. 有五个不同的参数控制编译。它们可以在本地声明也可以在全局声明。
3. 优秀的编译器能够优化尾递归,将一个尾递归的函数转换为一个循环。内联编译是另一种避免函数调用的方法。
4. 类型声明并不是必须的,但它们可以让一个程序更高效。类型声明对于处理数值和数组的代码特别重要。
5. 少的构造可以让程序更快,特别是在使用着原始的垃圾回收器的实现中。解决方案是使用破坏性函数、预先分配空间块、以及在栈上分配。
6. 某些情况下,从预先分配的存储池中提取对象可能是有价值的。
7. Common Lisp 的某些部分是为了速度而设计的,另一些则为了灵活性。
8. 编程必定存在探索的过程。探索和优化应该被分开 ── 有时甚至需要使用不同的语言。
## Chapter 13 练习 (Exercises)[](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#chapter-13-exercises "Permalink to this headline")
1. 检验你的编译器是否支持 (observe)内敛声明。
2. 将下述函数重写为尾递归形式。它被编译后能快多少?
~~~
(defun foo (x)
(if (zerop x)
0
(1+ (foo (1- x)))))
注意:你需要增加额外的参数。
~~~
1. 为下述程序增加声明。你能让它们变快多少?
~~~
(a) 在 5.7 节中的日期运算代码。
(b) 在 9.8 节中的光线跟踪器 (ray-tracer)。
~~~
1. 重写 3.15 节中的广度优先搜索的代码让它尽可能减少使用构造。
2. 使用存储池修改 4.7 节中的二叉搜索的代码。
脚注
[[1]](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#id4) | 较早的实现或许不提供 `declaim` ;需要使用 `proclaim` 并且引用这些参量 (quote the argument)。
[[2]](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#id5) | 为了让内联声明 (inline declaration) 有效,你同时必须设置编译参数,告诉它你想获得最快的代码。
[[3]](http://acl.readthedocs.org/en/latest/zhCN/ch13-cn.html#id6) | 有两种方法可以描述 Lisp 声明类型 (typing) 的方式:从类型信息被存放的位置或者从它被使用的时间。显示类型 (manifest typing) 的意思是类型信息与数据对象 (data objects) 绑定,而运行时类型(run-time typing) 的意思是类型信息在运行时被使用。实际上,两者是一回事儿。
