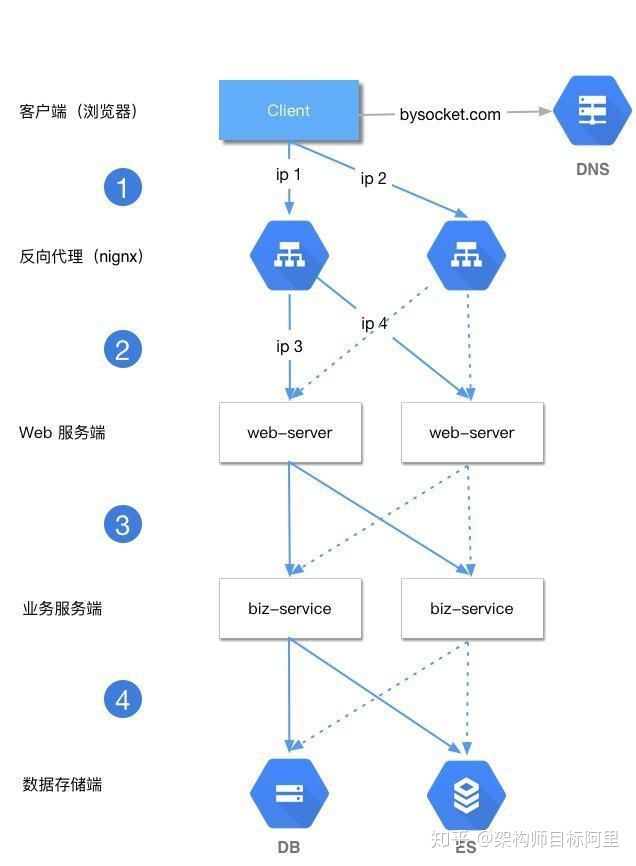
常见的互联网分布式系统架构分为几层,一般如下:
* 客户端层:比如用户浏览器、APP 端
* 反向代理层:技术选型 Nignx 或者 F5 等
* Web 层:前后端分离场景下, Web 端可以用 NodeJS 、 RN 、Vue
* 业务服务层:用 Java 、Go,一般互联网公司,技术方案选型就是 SC 或者 Spring Boot + Dubbo 服务化
* 数据存储层:DB 选型 MySQL ,Cache 选型 Redis ,搜索选型 ES 等
一个请求从第 1 层到第 4 层,层层访问都需要负载均衡。即每个上游调用下游多个业务方的时候,需要均匀调用。这样整体系统来看,就比较负载均衡
**第 1 层:客户端层 -> 反向代理层 的负载均衡**
客户端层 -> 反向代理层的负载均衡如何实现呢?
答案是:DNS 的轮询。 DNS 可以通过 A (Address,返回域名指向的 IP 地址)设置多个 IP 地址。比如这里访问[http://bysocket.com](https://link.zhihu.com/?target=http%3A//bysocket.com)的 DNS 配置了 ip1 和 ip2 。为了反向代理层的高可用,至少会有两条 A 记录。这样冗余的两个 ip 对应的 nginx 服务实例,防止单点故障。
每次请求[http://bysocket.com](https://link.zhihu.com/?target=http%3A//bysocket.com)域名的时候,通过 DNS 轮询,返回对应的 ip 地址,每个 ip 对应的反向代理层的服务实例,也就是 nginx 的外网ip。这样可以做到每一个反向代理层实例得到的请求分配是均衡的。
**第 2 层:反向代理层 -> Web 层 的负载均衡**
反向代理层 -> Web 层 的负载均衡如何实现呢?
是通过反向代理层的负载均衡模块处理。比如 nginx 有多种均衡方法:
1. 请求轮询。请求按时间顺序,逐一分配到 web 层服务,然后周而复始。如果 web 层服务 down 掉,自动剔除
~~~text
upstream web-server {
server ip3;
server ip4;
}
~~~
ip 哈希。按照 ip 的哈希值,确定路由到对应的 web 层。只要是用户的 ip 是均匀的,那么请求到 Web 层也是均匀的。
1. 还有个好处就是同一个 ip 的请求会分发到相同的 web 层服务。这样每个用户固定访问一个 web 层服务,可以解决 session 的问题。
~~~text
upstream web-server {
ip_hash;
server ip3;
server ip4;
}
~~~
1. weight 权重 、 fair、url\_hash 等
**第 3 层:Web 层 -> 业务服务层 的负载均衡**
Web 层 -> 业务服务层 的负载均衡如何实现呢?
比如 Dubbo 是一个服务治理方案,包括服务注册、服务降级、访问控制、动态配置路由规则、权重调节、负载均衡。其中一个特性就是智能负载均衡:内置多种负载均衡策略,智能感知下游节点健康状况,显著减少调用延迟,提高系统吞吐量。
为了避免避免单点故障和支持服务的横向扩容,一个服务通常会部署多个实例,即 Dubbo 集群部署。会将多个服务实例成为一个服务提供方,然后根据配置的随机负载均衡策略,在20个 Provider 中随机选择了一个来调用,假设随机到了第7个 Provider。LoadBalance 组件从提供者地址列表中,使用均衡策略,选择选一个提供者进行调用,如果调用失败,再选另一台调用。
Dubbo内置了4种负载均衡策略:
* RandomLoadBalance:随机负载均衡。随机的选择一个。是Dubbo的默认负载均衡策略。
* RoundRobinLoadBalance:轮询负载均衡。轮询选择一个。
* LeastActiveLoadBalance:最少活跃调用数,相同活跃数的随机。活跃数指调用前后计数差。使慢的 Provider 收到更少请求,因为越慢的 Provider 的调用前后计数差会越大。
* ConsistentHashLoadBalance:一致性哈希负载均衡。相同参数的请求总是落在同一台机器上。
同样,因为业务的需要,也可以实现自己的负载均衡策略
**第 4 层:业务服务层 -> 数据存储层 的负载均衡**
数据存储层的负载均衡,一般通过 DBProxy 实现。比如 MySQL 分库分表。
当单库或者单表访问太大,数据量太大的情况下,需要进行垂直拆分和水平拆分两个维度。比如水平切分规则:
* Range 、 时间
* hash 取模,订单根据店铺ID 等
但伴随着这块的负载会出现下面的问题,需要解决:
* 分布式事务
* 跨库 join 等
现状分库分表的产品方案很多:当当 sharding-jdbc、阿里的 Cobar 等
## **五、小结**
对外看来,负载均衡是一个系统或软件的整体。对内看来,层层上下游调用。只要存在调用,就需要考虑负载均衡这个因素。所以负载均衡(Load Balance)是分布式系统架构设计中必须考虑的因素之一。考虑主要是如何让下游接收到的请求是均匀分布的:
* 第 1 层:客户端层 -> 反向代理层 的负载均衡。通过 DNS 轮询
* 第 2 层:反向代理层 -> Web 层 的负载均衡。通过 Nginx 的负载均衡模块
* 第 3 层:Web 层 -> 业务服务层 的负载均衡。通过服务治理框架的负载均衡模块
* 第 4 层:业务服务层 -> 数据存储层 的负载均衡。通过数据的水平分布,数据均匀了,理论上请求也会均匀。比如通过买家ID分片类似
