
[TOC]
> 本部分,我们来解读一下Canal的源码,看从中能汲取到多少营养呢。
## Canal简介
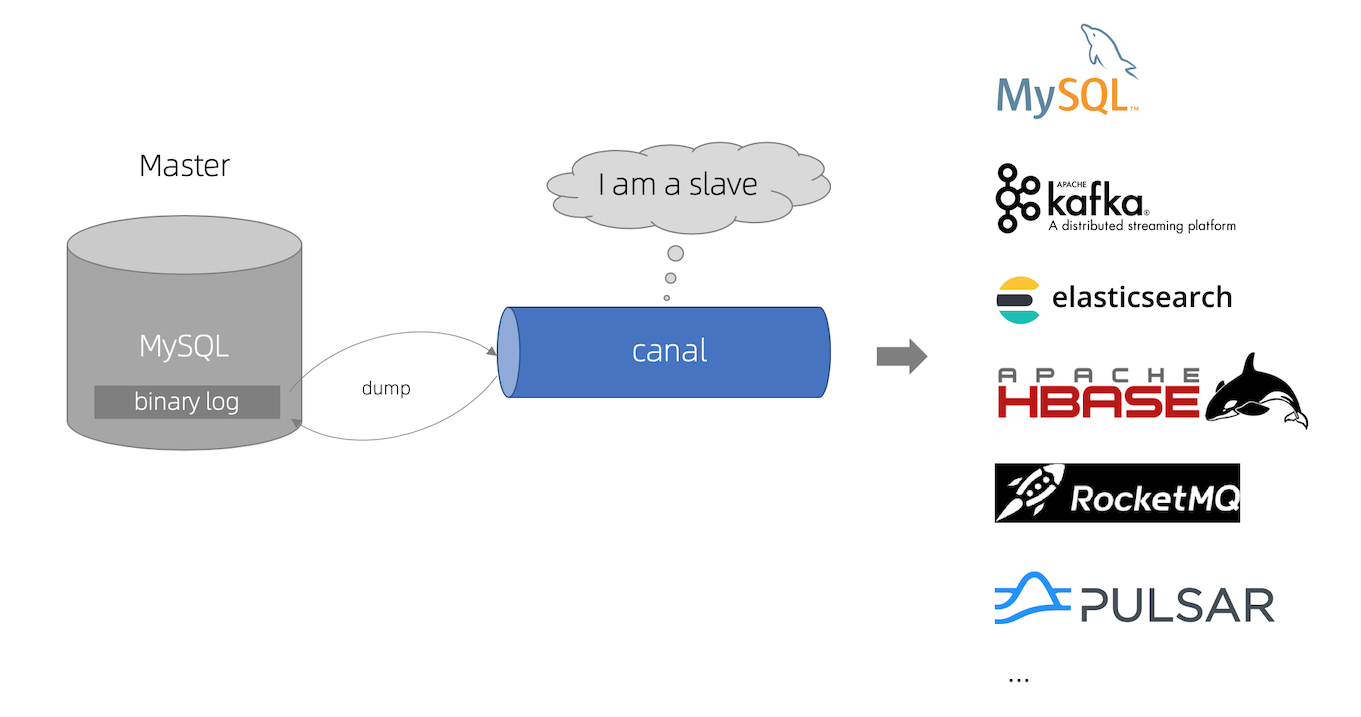
## Canal模块介绍
下面先通过一张图来说明各个模块之间的依赖关系:
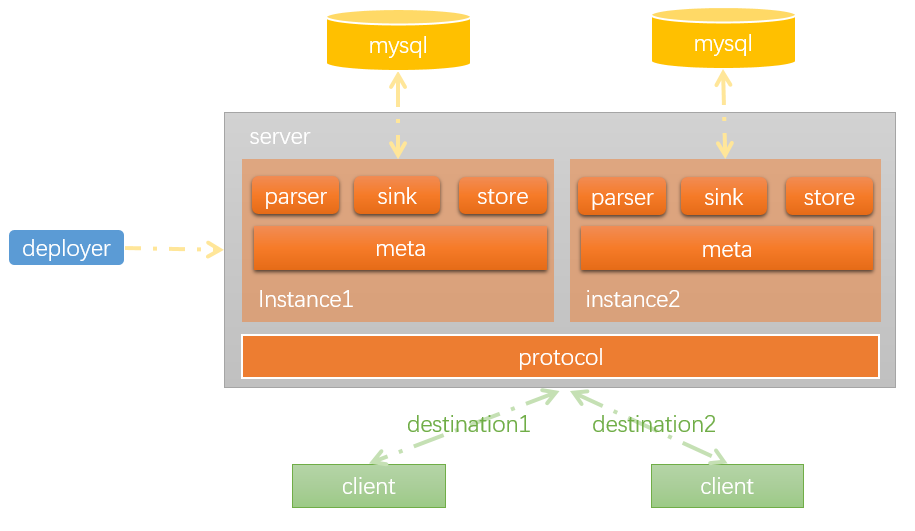
通过deployer模块,启动一个canal-server,一个cannal-server内部包含多个instance,每个instance都会伪装成一个mysql实例的slave。client与server之间的通信协议由protocol模块定义。client在订阅binlog信息时,需要传递一个destination参数,server会根据这个destination确定由哪一个instance为其提供服务。
### 模块说明
模块虽多,但是每个模块的代码都很少。各个模块的作用如下所示:
| 模块名称 | 说明 |
| --- | --- |
|common模块|主要是提供了一些公共的工具类和接口。|
|client模块|canal的客户端诵慕涌谖狢analConnector|
|example模块|提供client模块使用案例。|
|protocol模块|client和server模块之间的通信协议|
|deployer|部署模块。通过该模块提供的CanalLauncher来启动canal server|
|server模块|canal服务器端诵慕涌谖狢analServer|
|instance模块|一个server有多个instance。每个instance都会模拟成一个mysql实例的slave。instance模块有四个核心组成部分,parser模块、sink模块、store模块,meta模块|
|parser模块|数据源接入,模拟slave协议和master进行交互,协议解析。parser模块依赖于dbsync、driver模块。|
|driver模块和dbsync模块|从这两个模块的artifactId(canal.parse.driver、canal.parse.dbsync),就可以看出来,这两个模块实际上是parser模块的组件。事实上parser 是通过driver模块与mysql建立连接,从而获取到binlog。由于原始的binlog都是二进制流,需要解析成对应的binlog事件,这些binlog事件对象都定义在dbsync模块中,dbsync 模块来自于淘宝的tddl。|
|sink模块|parser和store链接器,进行数据过滤,加工,分发的工作诵慕涌谖狢analEventSink|
|store模块|数据存储。核心接口为CanalEventStore|
|meta模块|增量订阅&消费信息管理器,核心接口为`CanalMetaManager`,主要用于记录canal消费到的mysql binlog的位置。|
## Canal和Otter什么关系?
借鉴网友的一张图:
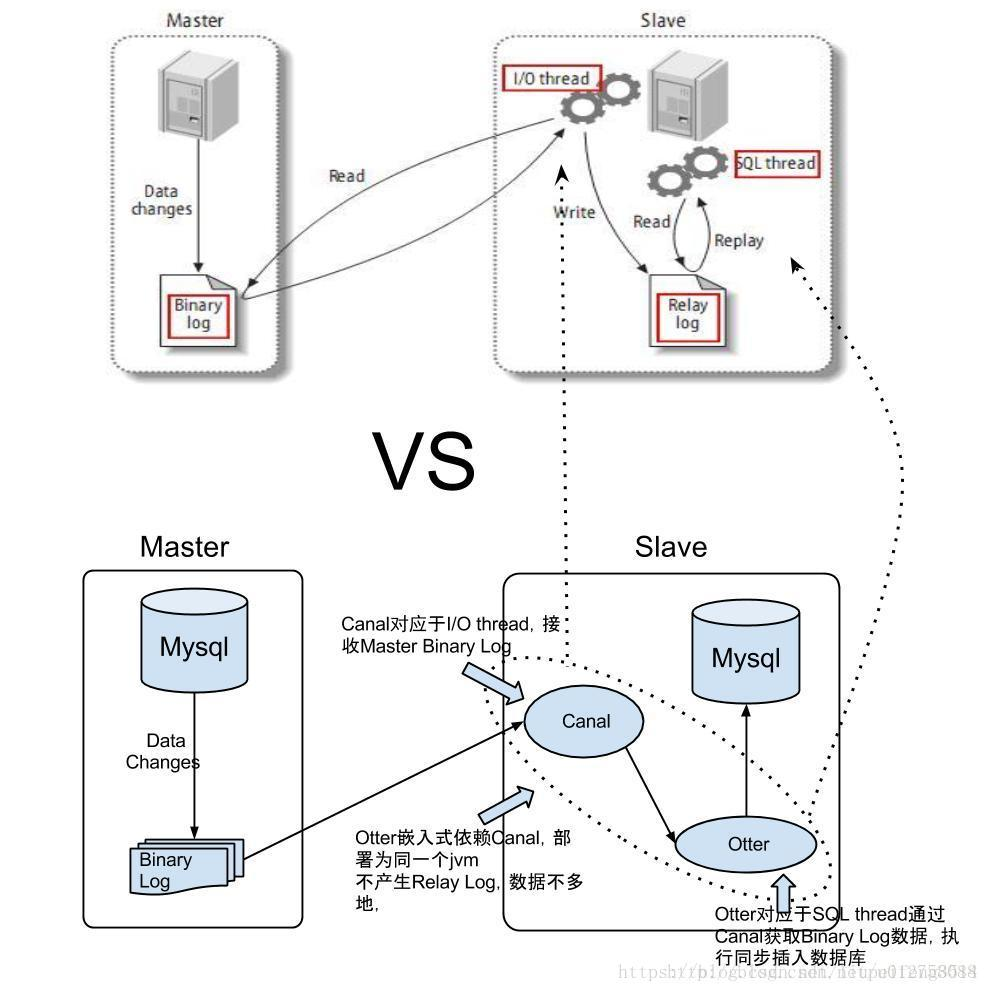
mysql的自带复制技术可分成三步:
1. master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
2. slave将master的binary log events拷贝到它的中继日志(relay log),这里是I/O thread线程;
3. slave重做中继日志中的事件,将改变反映它自己的数据,这里是SQL thread线程。
基于canal&otter的复制技术和mysql复制类似,具有类比性:
1. Canal对应于I/O thread,接收Master Binary Log;
2. Otter对应于SQL thread,通过Canal获取Binary Log数据,执行同步插入数据库;
### 提问与分析:
从两张图中,我们可以注意到一个细节不同:图一Slave获取Binlog是一个`pull模式`;图二的描述却是`push模式`。
既然是伪装,数据同步的方式应该是一致的才是,所以上图可能存在一定的错误。
### 两者的区别在于:
otter目前嵌入式依赖canal,部署为同一个jvm,目前设计为不产生Relay Log,数据不落地;
otter目前允许自定义同步逻辑,解决各类需求;
a. ETL转化. 比如Slave上目标表的表名,字段名,字段类型不同,字段个数不同等.
b. 异构数据库. 比如Slave可以是oracle或者其他类型的存储,nosql等.
c. M-M部署,解决数据一致性问题
d. 基于manager部署,方便监控同步状态和管理同步任务.
## 参考资料:
[canal和otter的关系?](https://blog.csdn.net/liupeifeng3514/article/details/79687130)
- 写在前面
- 如何阅读源码
- 第一部分 开源框架
- Netty
- 启动过程
- SpringSecurityOauth2
- Quartz
- quartz启动原理
- quartz定时调度任务触发流程
- 第二部分 优质中间件源码分析
- Canal
- Canal是如何伪装为mysql的slave的?
- canal源码调试
- Sentinel
- 核心概念梳理
- 滑动窗口实现原理
- jvm-sandbox
- jvm-sandbox-repeater
- Windows环境安装
- 结果比对
- 第三部分 优质行业项目源码分析
- 第一章 分库分表实践
- sharding-jdbc
- 第二章 DDD领域驱动
- 享同科技DDD开源框架
- J-IM
- 功能测试
- 悟空CRM
- 项目搭建
- 默认密码
- dataX-web
- 项目搭建
- 部署报错
- dolphinscheduler
- awescnb
- geek
- chrome插件-funds
- 优质开源项目备忘