[TOC]
# 一、EFK
使用的技术:
* Elasticsearch:日志存储和搜索
* Fluentd:日志收集、过滤、转换、写入到Elasticsearch中
* Kibana:前端展示
# 二、采集原理
Dokcer 默认的日志驱动是`json-file`,该驱动将来自容器的`stdout`和`stderr`日志都统一以 json 的形式存储到 Node 节点的`/var/lib/docker/containers/<container-id>/<container-id>-json.log`目录结构内。
而 Kubernetes kubelet 会将`/var/lib/docker/containers/`目录内的日志文件重新软链接至`/var/log/containers`目录和`/var/log/pods`目录下。这种统一的日志存储规则,为我们收集容器的日志提供了基础和便利。
也就是说,我们只需采集集群节点的`/var/log/containers`目录的日志,就相当于采集了该节点所有容器输出`stdout`的日志。
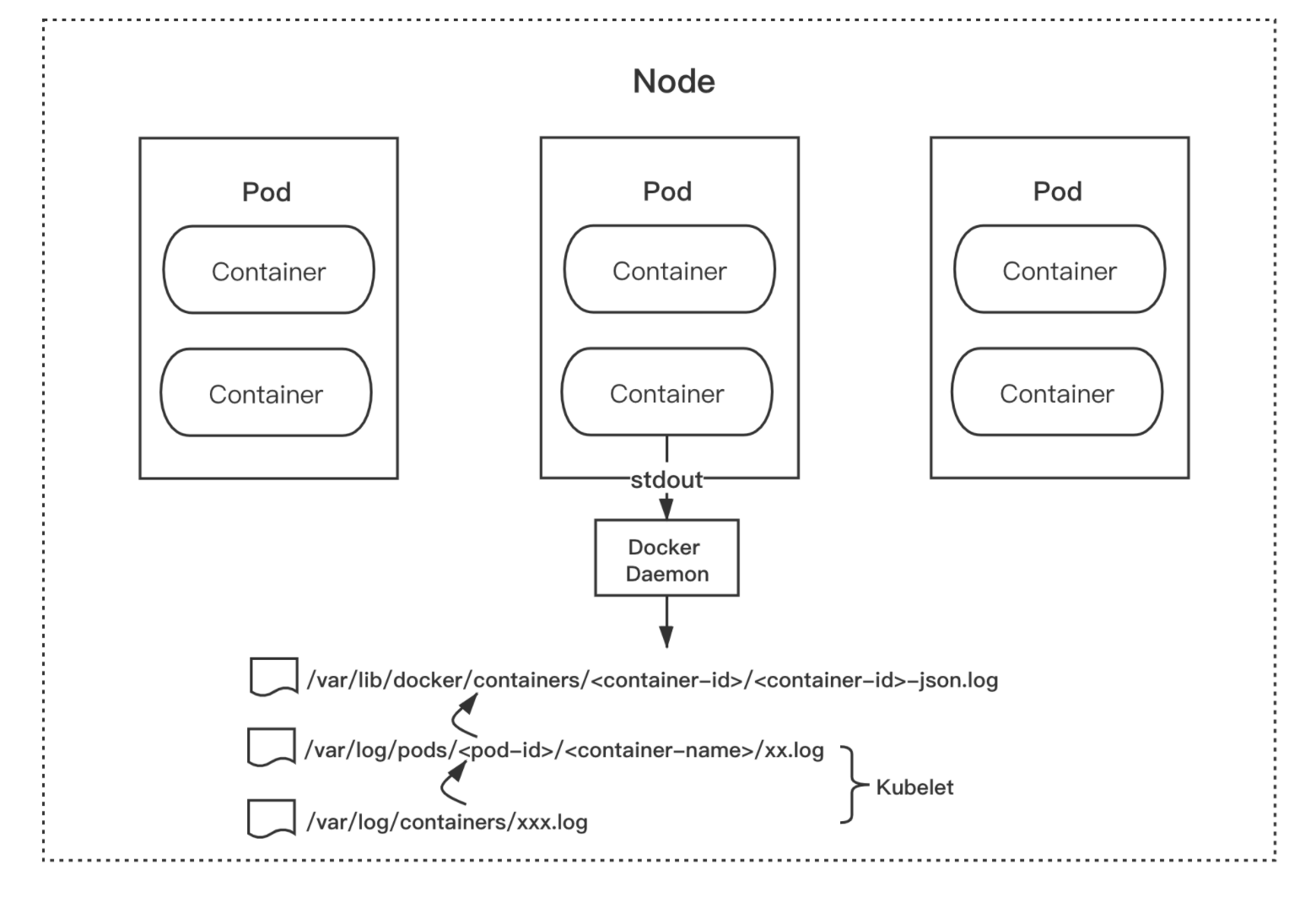
图片来自网络
基于集群的日志采集原理,我们配置了一下目录:
* `/var/log`
* `/var/lib/docker/containers`
* `/run/log/journal`
具体配置见`kubernetes/efk`目录
# 三、在k8s集群部署EFK
运行如下脚本:
```
$ ./kubernetes/scripts/deploy-prod-efk.bash
```
该脚本自动创建命名空间`logging`,部署`elasticsearch`、`kibana`、`fluentd`
自动转发5601端口,可以通过`localhost:5601`访问`kibana`
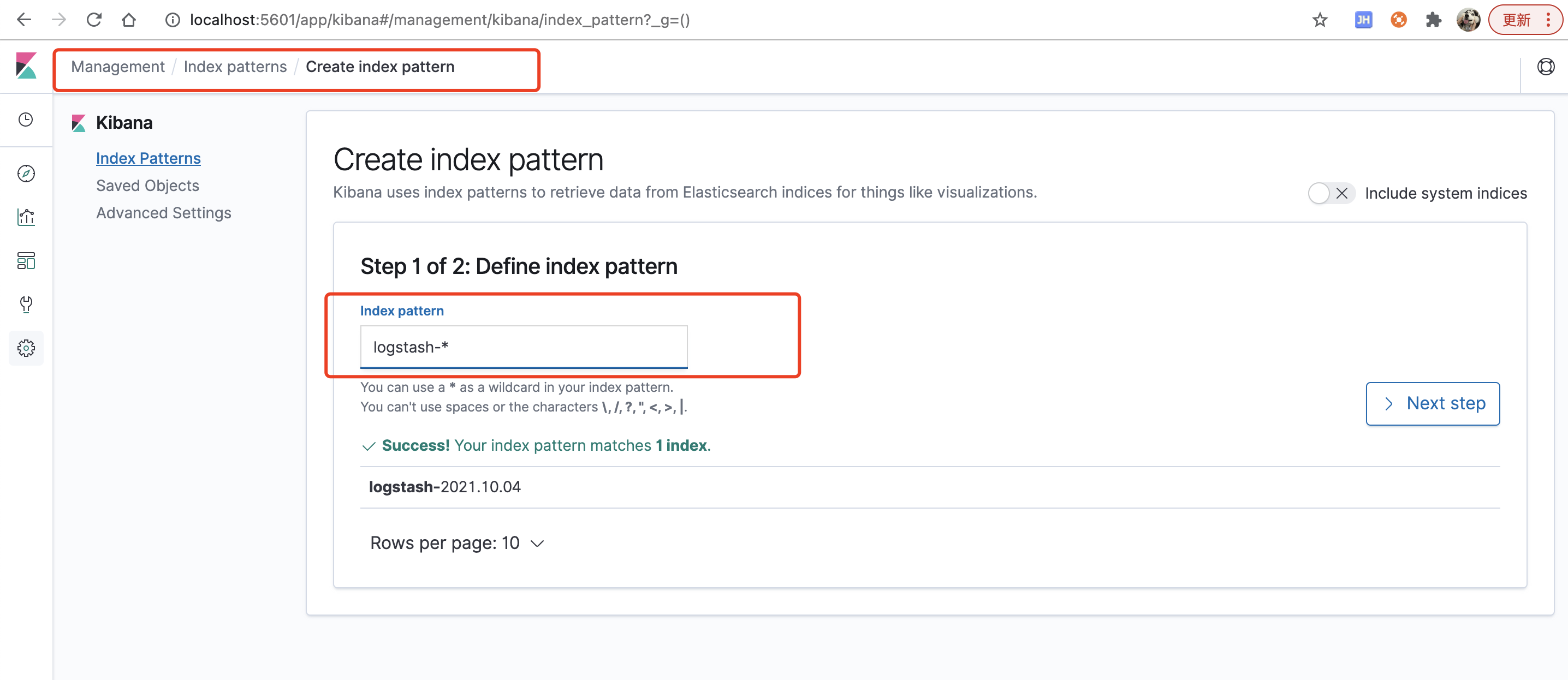
初次部署`kibana`属于创建index pattern,输入`logstash-*`,如下图:
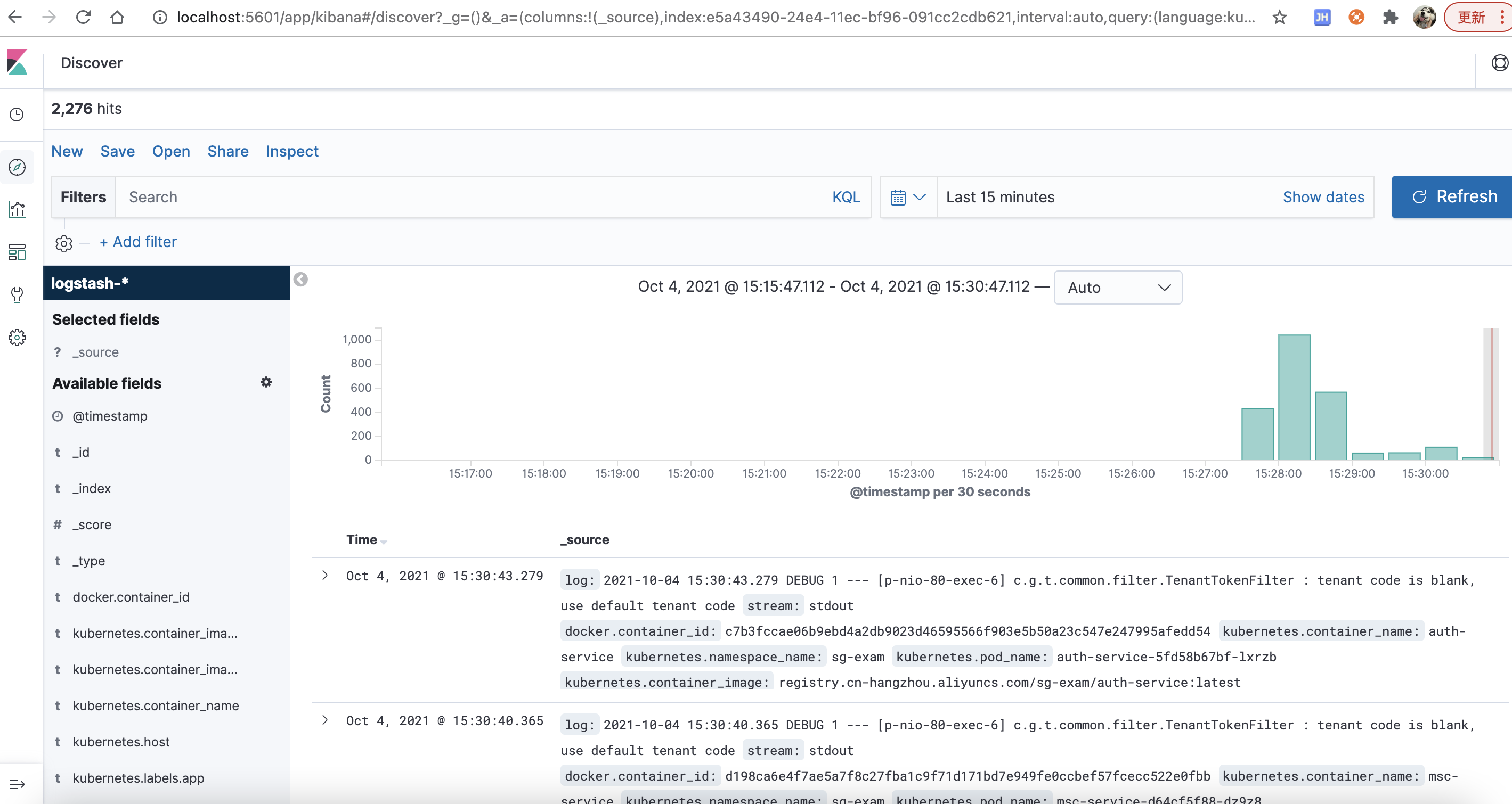
next step选择@timestamp
最终效果
# 参考资料
* [Fluentd官网](https://www.fluentd.org)
* [使用 Fluentd 进行日志收集](https://istio.io/latest/zh/docs/tasks/observability/logs/fluentd/)
* [EFK](https://www.servicemesher.com/istio-handbook/practice/efk.html)
