
[TOC]
## 1. stream特点
`Stream` 流分为**顺序流**和**并行流**,所谓顺序流就是按照顺序对集合中的元素进行处理,而并行流则是使用多线程同时对集合中多个元素进行处理,所以在使用并行流的时候就要注意线程安全的问题了。
1. stream不是一种数据结构,不保存数据,只是在原数据上封装了一组操作
2. 这些操作是惰性的,即每当访问到流中的一个元素,才会在此元素上执行这一系列操作。
3. Stream不保存数据,故每个Stream流只能使用一次。
4. 提供并行化流,不用开发人员自己写多线程
## 2. stream操作分类
可以分成两种:**Intermediate(中间操作)** 和**Terminal(终止操作)**。
1. 中间操作的返回结果都是Stream,故可以多个中间操作叠加;
2. 终止操作用于返回我们最终需要的数据,只能有一个终止操作。
## 3. 流的产生方法
1. Collection接口的stream()或parallelStream()方法
2. 静态的Stream.of()、Stream.empty()方法
3. Arrays.stream(array, from, to)
4. 静态的Stream.generate()方法生成无限流,接受一个不包含引元的函数
5. 静态的Stream.iterate()方法生成无限流,接受一个种子值以及一个迭代函数
6. Pattern接口的splitAsStream(input)方法
7. 静态的Files.lines(path)、Files.lines(path, charSet)方法
8. 静态的Stream.concat()方法将两个流连接起来
## 4. 流的Intermediate方法(中间操作)
集合可以直接调用
1. filter(Predicate)
将结果为false的元素过滤掉
2. map(fun)
转换元素的值,可以用方法引元或者lambda表达式
3. flatMap(fun)
若元素是流,将流摊平为正常元素,再进行元素转换
4. limit(n)
保留前n个元素
5. skip(n)
跳过前n个元素
6. distinct()
剔除重复元素
7. sorted()
将Comparable元素的流排序
8. sorted(Comparator)
将流元素按Comparator排序
9. peek(fun)
流不变,但会把每个元素传入fun执行,可以用作调试
## 5. 流的Terminal方法(终结操作)
### 5.1 约简统计操作
1. max(Comparator)
2. min(Comparator)
3. count()
4. findFirst()
返回第一个元素
5. findAny()
返回任意元素
6. anyMatch(Predicate)
任意元素匹配时返回true
7. allMatch(Predicate)
所有元素匹配时返回true
8. noneMatch(Predicate)
没有元素匹配时返回true
9. reduce(fun)
从流中计算某个值,接受一个二元函数作为累积器,从前两个元素开始持续应用它,累积器的中间结果作为第一个参数,流元素作为第二个参数
10. reduce(a, fun)
a为幺元值,作为累积器的起点
11. reduce(a, fun1, fun2)
与二元变形类似,并发操作中,当累积器的第一个参数与第二个参数都为流元素类型时,可以对各个中间结果也应用累积器进行合并,但是当累积器的第一个参数不是流元素类型而是类型T的时候,各个中间结果也为类型T,需要fun2来将各个中间结果进行合并
### 5.2 收集操作
1. iterator()
2. forEach(fun)
3. forEachOrdered(fun)
可以应用在并行流上以保持元素顺序
4. toArray()
5. toArray(T[] :: new)
返回正确的元素类型
**6. collect(Collector),Collector是收集器,用于将流数据收集成Java集合对象**
7. collect(fun1, fun2, fun3)
fun1转换流元素;fun2为累积器,将fun1的转换结果累积起来;fun3为组合器,将并行处理过程中累积器的各个结果组合起来
### 5.3 实例
```
public static void streamImpl(List<Student> students) {
List<Student> filterStudent = students.stream()
.filter(one -> one.getScore() < 60).collect(Collectors.toList());
System.out.println(filterStudent);
}
```
#### flatMap()
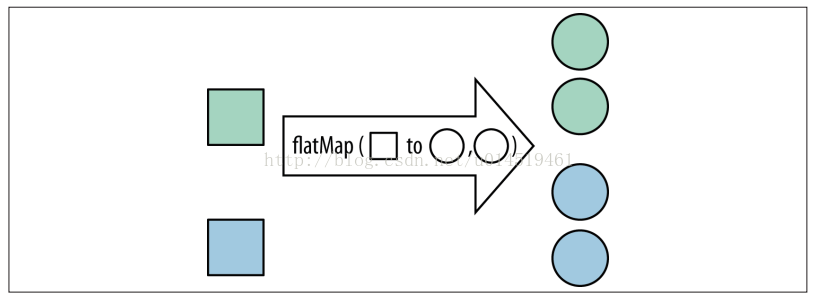
`flatMap()`操作能把原始流中的元素进行一对多的转换,并且将新生成的元素全都合并到它返回的流里面。假如现每个班的学生都学了不同的课程,现在需要统计班里所有学生所学的课程列表,该如何实现呢?
##### 清单 12. `flatMap ()` 方法的使用示例
```
`public static void useFlatMap() {`
`List<``Student``> students = initData();`
`List<``String``> course = students.stream().flatMap(one -> one.getCourse().stream()).distinct()`
`.collect(Collectors.toList());`
`System.out.println(course);`
`}`
```
# 实例
## 1. reduce实例
Reduce,顾名思义为减少的意思,就是根据指定的计算模型将Stream中的值计算**得到一个最终结果**。首先来看一下Reduce三种形式:

1. 第一种,无初始值,依次累加
```
public static void reduceFirstSign() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6);
ptional<Integer> count = list.stream().reduce((a, b) -> (a + b));
System.out.println(count.get()); // 21
}
```
2. 第二种,有初始值依次计算
```
public static void reduceSecondSign() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6);
Integer count = list.stream().reduce(2, (a, b) -> (a * b));
System.out.println(count); // 1440
}
```
(((((2 x 1) x 2) x 3 )x 4) x 5) x 6 )
3. 第三种,并行化计算统计
```
public static void main(String[] args) {
List<Integer> list = Arrays.asList(2,2);
Integer result = list.stream().parallel().reduce(2, (a, b) -> (a + b), (a, b) -> (a + b));
System.out.println(result);
}
```
上面的代码实际上是先使用累加器把 Stream 流中的两个元素都加 `2` 后,然后再使用合并器将两部分的结果相加。最终得到的结果也就是 `8`。
## 2. 收集器实例
#### list转map
利用收集器 Collectors.toMap
```
public static void list2Map() {
List<Student> students = initData();
Map<String, Double> collect = students.stream()
.collect(Collectors.toMap(one -> one.getName(),
one -> one.getScore()));
System.out.println(collect);
}
```
## 6. 流类型转换
### 6.1 对象流转基本流
对象流转换为基本类型流:mapToInt()、mapToLong()、mapToDouble()
### 6.2 基本流转对象流
基本类型流转换为对象流:
boxed() :类似于包装类
mapToObj(func):用函数构造对象
- 计算机网络
- 基础_01
- tcp/ip
- http转https
- Let's Encrypt免费ssl证书(基于haproxy负载)
- what's the http?
- 网关
- 网络IO
- http
- 工具
- Git
- 初始本地仓库并上传
- git保存密码
- Gitflow
- maven
- 1.生命周期命令
- 聚合与继承
- 插件管理
- assembly
- 资源管理插件
- 依赖范围
- 分环境打包
- dependencyManagement
- 版本分类
- 找不到主类
- 无法加载主类
- 私服
- svn
- gradle
- 手动引入第三方jar包
- 打包exe文件
- Windows
- java
- 设计模式
- 七大原则
- 1.开闭原则
- 2. 里式替换原则
- 3. 依赖倒置原则
- 4. 单一职责原则
- 单例模式
- 工厂模式
- 简单工厂
- 工厂方法模式
- 抽象工厂模式
- 观察者模式
- 适配器模式
- 建造者模式
- 代理模式
- 适配器模式
- 命令模式
- json
- jackson
- poi
- excel
- easy-poi
- 规则
- 模板
- 合并单元格
- word
- 读取
- java基础
- 类路径与jar
- 访问控制权限
- 类加载
- 注解
- 异常处理
- String不可变
- 跨域
- transient关键字
- 二进制编码
- 泛型1
- 与或非
- final详解
- Java -jar
- 正则
- 读取jar
- map
- map计算
- hashcode计算原理
- 枚举
- 序列化
- URLClassLoader
- 环境变量和系统变量
- java高级
- java8
- 1.Lambda表达式和函数式接口
- 2.接口的默认方法和静态方法
- 3.方法引用
- 4.重复注解
- 5.类型推断
- 6.拓宽注解的应用场景
- java7-自动关闭资源机制
- 泛型
- stream
- 时区的正确理解
- StringJoiner字符串拼接
- 注解
- @RequestParam和@RequestBody的区别
- 多线程
- 概念
- 线程实现方法
- 守护线程
- 线程阻塞
- 笔试题
- 类加载
- FutureTask和Future
- 线程池
- 同步与异步
- 高效简洁的代码
- IO
- ThreadLocal
- IO
- NIO
- 图片操作
- KeyTool生成证书
- 压缩图片
- restful
- 分布式session
- app保持session
- ClassLoader.getResources 能搜索到的资源路径
- java开发规范
- jvm
- 高并发
- netty
- 多线程与多路复用
- 异步与事件驱动
- 五种IO模型
- copy on write
- code style
- 布隆过滤器
- 笔试
- 数据库
- mybatis
- mybatis与springboot整合配置
- pagehelper
- 分页数据重复问题
- Java与数据库之间映射
- 拦截器
- 拦截器应用
- jvm
- 堆内存测试
- 线程栈
- 直接内存
- 内存结构
- 内存模型
- 垃圾回收
- 调优
- 符号引用
- 运行参数
- 方法区
- 分带回收理论
- 快捷开发
- idea插件
- 注释模板
- git
- pull冲突
- push冲突
- Excel处理
- 图片处理
- 合并单元格
- easypoi
- 模板处理
- 响应式编程
- reactor
- reactor基础
- jingyan
- 规范
- 数据库