## **Mysql关于Sql语句分析是否走索引问题讨论**
## <blockquote class="danger"><p>答案: 使用EXPLAIN + SQL语句,分析查询结果集
如图所示
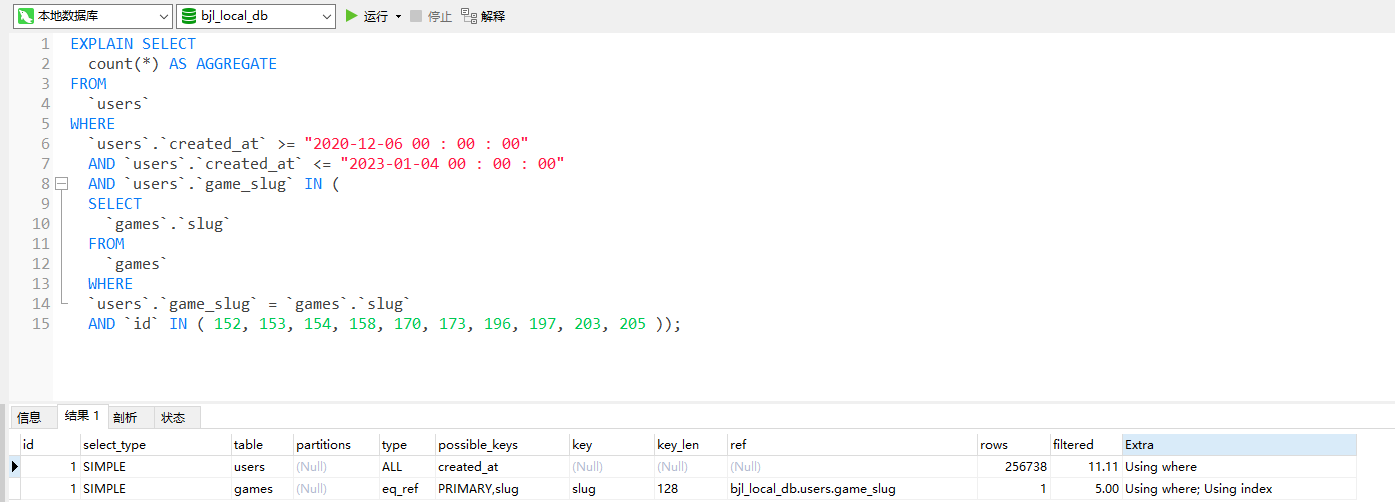
我们把比较重要的参数提取出来进行详细讲解一下:
* [ ] **id**
选择标识符
* [ ] **select_type**
查询中每个select子句的类型
1. SIMPLE:简单select语句,不实用union或子查询等
2. PRIMARY:查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY
3. UNION:UNION中的第二个或后面的SELECT语句
4. UNION RESULT:UNION的结果
5. SUBQUERY:子查询中的第一个SELECT
* [ ] **table**
查询的表名
* [ ] **partitions**
匹配的分区
* [ ] **type**
表示连接类型,类型有ALL、index、range、 ref、eq_ref、const、system、NULL,这几种类型从左到右,性能越来越高。一般一个好的sql语句至少要达到range级别。all级别应当杜绝
* [ ] **possible_keys**
表示查询时,可能使用的索引
* [ ] **key**
显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL
* [ ] **key_len**
显示的值为索引字段的最大可能长度,并非实际使用长度
* [ ] **ref**
连接匹配条件,即哪些列或常量被用于查找索引列上的值
* [ ] **rows**
显示MySQL认为它执行查询时必须检查的行数。
* [ ] **filtered**
按表条件过滤的行百分比
* [ ] **extra**
表示详细说明,注意该值包含十分重要的信息。一般该列存在下列值,常见的不太友好的值有:Using filesort(排序时无法使用到索引), Using temporary(表示使用了临时表存储中间结果)
