# 使用OQL分析虚拟机内存
本章作为书第一章的补充,较为详细说明了如何进行内存分析以解决因为内存使用过多导致的性能降低以及内存溢出现象。有些非内存故障问题,页可以通过OQL来分析对象在内存中使用情况,查看对象运行时刻的属性值。
## 获取内存镜像文件
当应用系统性能不佳的时候,我们在第一章介通过 jvisualvm的抽样器定位性能瓶颈外,系统性能不佳还可能是虚拟机频繁的全局垃圾回收导致。
导入本节附带工程OQL后,可以直接运行OutMemoryCase1方法,该方法会不断的向Map里添加User实例,直到内存用满为止
~~~java
public class OutMemoryCase1 {
static Map<Long,User> map = new HashMap<>();
static long idBase = 0;
static Config config = new Config();
static public void test() {
config.setMax(1000);
config.setSleep(100);
for(int i=0;i<config.getMax();i++){
User user = new User();
user.setId((long)idBase);
user.setName("user"+idBase);
user.setDepartId((long)idBase);
map.put(user.getId(),user);
idBase++;
}
}
public static void main(String[] ags) throws InterruptedException {
while(true){
test();
Thread.sleep(config.getSleep());
System.out.println(config.getMessage()+idBase);
}
}
}
~~~
test方法会循环运行1万次,像类变量map添加User实例,main方法则不断循环运行test,每循环一次,会打印idBase变量。
User对象是一个POJO,包含了id,departId,和name属性,定义如下
~~~java
public class User {
private Long id ;
private Long departId ;
private String name;
//忽略getter和setter
}
~~~
Config对象如下定义,包含了循环,休眠等配置信息
~~~java
public class Config {
private int max =100;
private int sleep = 10;
private String message = ">";
//忽略getter和setter
}
~~~
运行OutMemoryCase1方法后,我们可以使用jdk命令jps 获取进程编号
~~~
>jps -ml
914 com.ibeetl.code.OutMemoryCase1
957 sun.tools.jps.Jps -ml
~~~
然后我们使用jdk的jstat命令观察内存使用情况
~~~
jstat -gcutil -h 20 914 2000 0
~~~
- -gcutil 表示输出内存使用汇总信息。
- -h 表示没输出20行,再打印一次表头
- 914是我们需要监控的虚拟机进程ID,使用需要用实际进程id代替
- 2000表示每2000毫秒输出一行信息
- 最后一个参数 0 表示一直输出,如果填写其他数字n,则最多输出n行
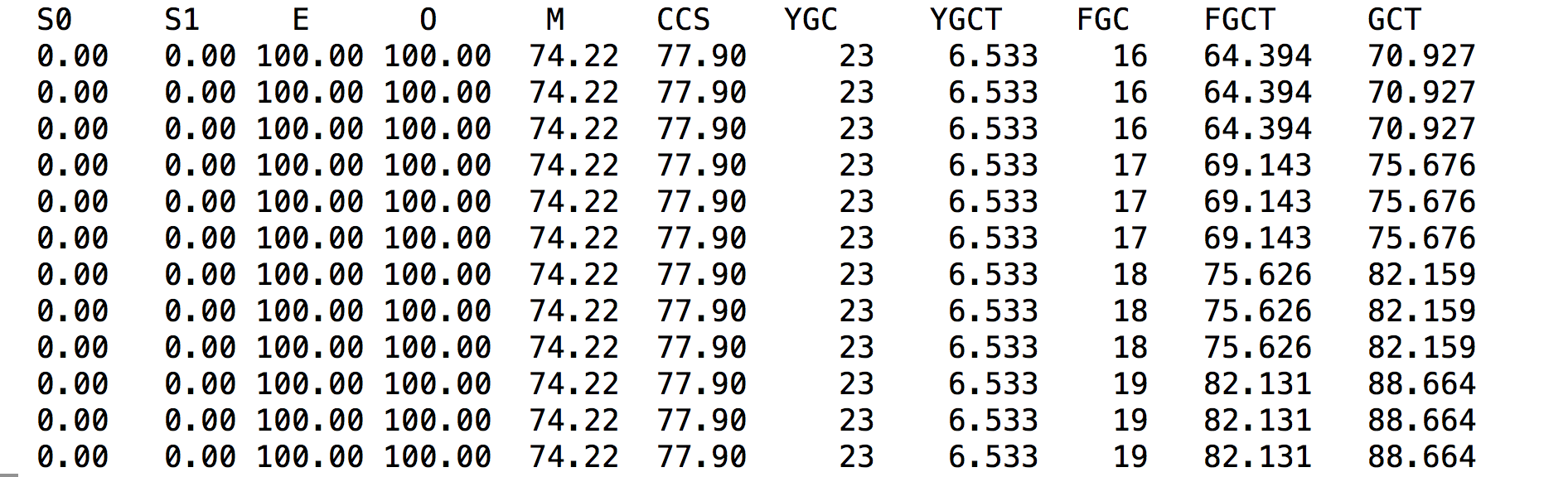
上图显示了虚拟机各个代的使用情况,描述了堆内存的各个占比和垃圾回收次数以及占用时间
* S0,第一个幸存区使用比率
* S1,第二个幸存区的使用率
* E,伊甸园区的使用比率
* O 老年代
* M 方法区,元空间使用率
* CCS,压缩使用比率
* YGC 年轻代垃圾回收次数
* YGCT 年纪带垃圾回收占用时间
* FGC 全局垃圾回收次数,这对性能影响至关重要
* FGCT 全局垃圾回收的消耗时间
* GCT 总得垃圾回收时间
关于虚拟机的内部结构和垃圾回收机制,超出了本书的范畴,这里做一些简要描述,我们只需要关注一些异常情况。
Java虚拟机中,对象的生命周期有长有短,大部分对象的生命周期很短,只有少部分的对象才会在内存中存留较长时间,因此可以依据对象生命周期的长短将它们放在不同的区域。在采用分代收集算法的Java虚拟机堆中,一般分为三个区域,用来分别储存这三类对象:
新生代 - 刚创建的对象,在代码运行时一般都会持续不断地创建新的对象,这些新创建的对象有很多是局部变量,很快就会变成垃圾对象。这些对象被放在一块称为新生代的内存区域。新生代的特点是垃圾对象多,存活对象少。
在新生代区域中,按照8:1:1的比例分为了Eden、SurvivorA、SurvivorB三个区域。其中Eden意为伊甸园,形容有很多新生对象在里面创建;Survivor区则为幸存者,即经历GC后仍然存活下来的对象。
Eden区对外提供堆内存。当Eden区快要满了,则进行Minor GC(新生代GC),把存活对象放入SurvivorA区,清空Eden区;
Eden区被清空后,继续对外提供堆内存;
当Eden区再次被填满,此时对Eden区和SurvivorA区同时进行Minor GC(新生代GC),把存活对象放入SurvivorB区,此时同时清空Eden区和SurvivorA区;
Eden区继续对外提供堆内存,并重复上述过程,即在 Eden 区填满后,把Eden区和某个Survivor区的存活对象放到另一个Survivor区;
当某个Survivor区被填满,且仍有对象未被复制完毕时,或者某些对象在反复Survive 15次左右时,则把这部分剩余对象放到老年代区域;当老年区也被填满时,进行Major GC(老年代GC),对老年代区域进行垃圾回收。
老年代 - 一些对象很早被创建了,经历了多次GC也没有被回收,而是一直存活下来。这些对象被放在一块称为老年代的区域。老年代的特点是存活对象多,垃圾对象少。
永久代 - 一些伴随虚拟机生命周期永久存在的对象,比如一些静态对象,常量等。这些对象被放在一块称为永久代的区域。永久代的特点是这些对象一般不需要垃圾回收,会在虚拟机运行过程中一直存活。(在Java1.7之前,方法区中存储的是永久代对象,Java1.7方法区的永久代对象移到了堆中,而在Java1.8永久代已经从堆中移除了,这块内存给了元空间。
从jstat的输出可以看到,老年代已经使用了99.9%,FGC一直在不停的增长,说明内存几乎已经占满,正常情况应该很难观察到一次FGC发生。从控制台的打印输出来看
~~~
.......
9320000
9330000
9340000
~~~
系统输出已经停滞在9340000值(在此是作者本人机器上运行结果,实际结果不一定是这个值),这代表此时系统执行已经非常缓慢了,这就是因为虚拟机频繁的全局垃圾回收导致的。
如果你不了解oql工程,没有看过代码OutMemoryCase1 如何诊断此时系统是哪一处代码出问题了呢,思路实获取内存的dump文件,然后通过OQL,一种类似SQL的分析语句分析内存dump文件,定位问题代码。
有多种方式获取到内存dump文件:
通过jmap 命令主动获取到
~~~
jmap -dump:format=b,file=filename.hprof pid
~~~
实际系统会有2G到8G内存,此命令会导致虚拟机暂停1-3秒时间,并生成指定filename的dump文件
还有一种是被动获取方式,当虚拟机出现内存溢出的时候,会主动dump内存文件。添加虚拟机启动参数
~~~
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof
~~~
会有如下输出
~~~
>9454000
>9455000
java.lang.OutOfMemoryError: Java heap space
Dumping heap to heapdump.hprof ...
~~~
通过打开jvisualvm也可以获取到堆dump文件,在左侧进程列表里找到该进程,右键,点击选项“堆 dump”,保存内存镜像文件
无论那种方式,我们都会获取到内存dump文件,我们下一节,将使用jvisualvm分析,主要使用OQL功能分析内存使用情况,定位系统问题
## OQL 查询语言
打开jvisualvm工具,选择菜单File,点击装入,选择我们保存过的dump文件,这时候jvisualvm面板会打开内存镜像文件。打开较大的内存镜像文件需要较长的时间,需要耐心等候
有一个“类按钮”可以进入类实例使用汇总页面,一个OQL控制台会进入OQL功能,我们点击OQL直接进入OQL控制台
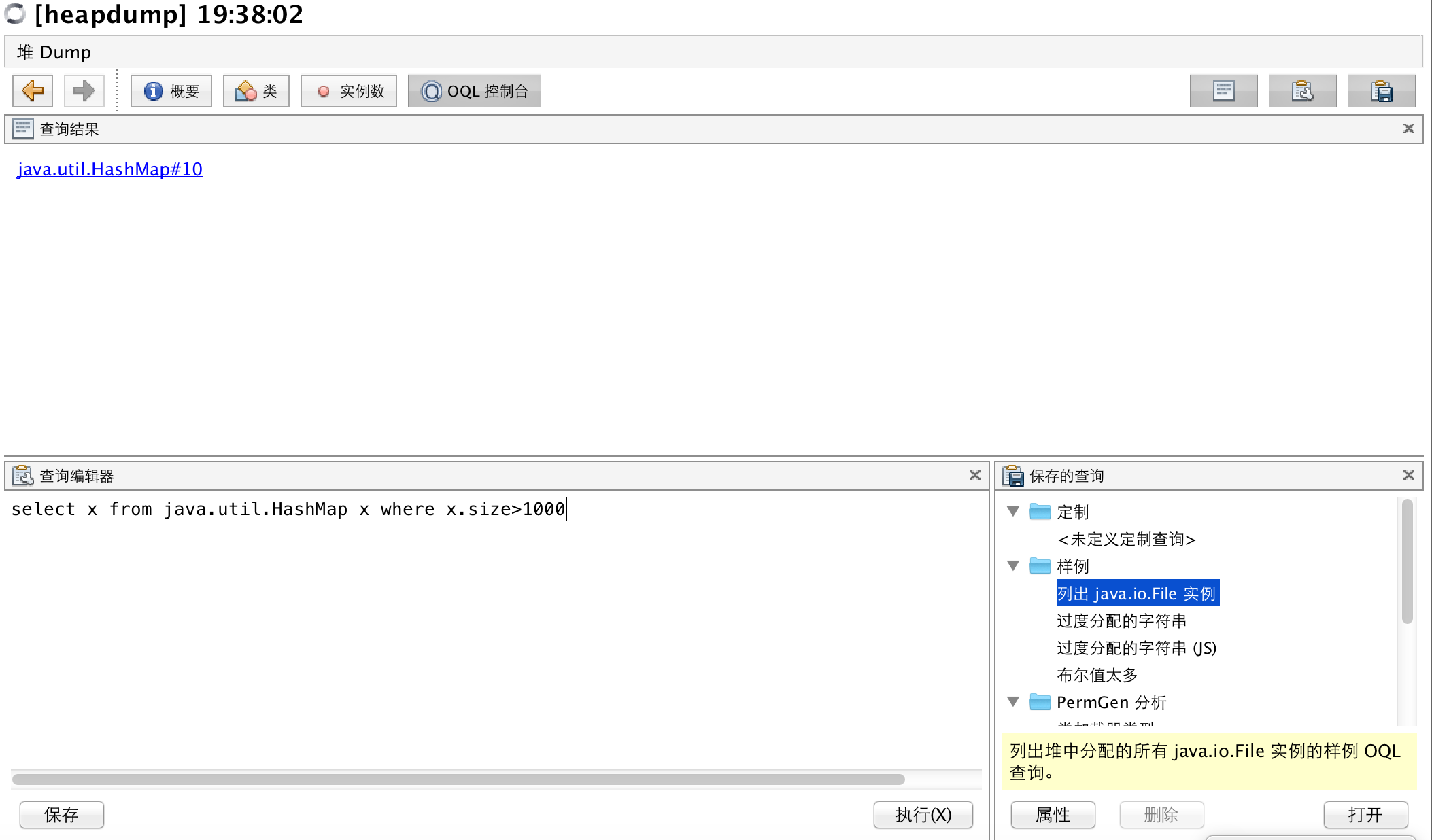
如面板所示,左下角的查询编辑器可以输入OQL语句,从内存中查询,我们输入
~~~
select x from java.util.HashMap x where x.size>1000
~~~
这个OQL语句查询出所有HashMap实例,且其属性size大于1000的,查询结果显示在面板上方。可以点击每个实例进入详情面板,如下图
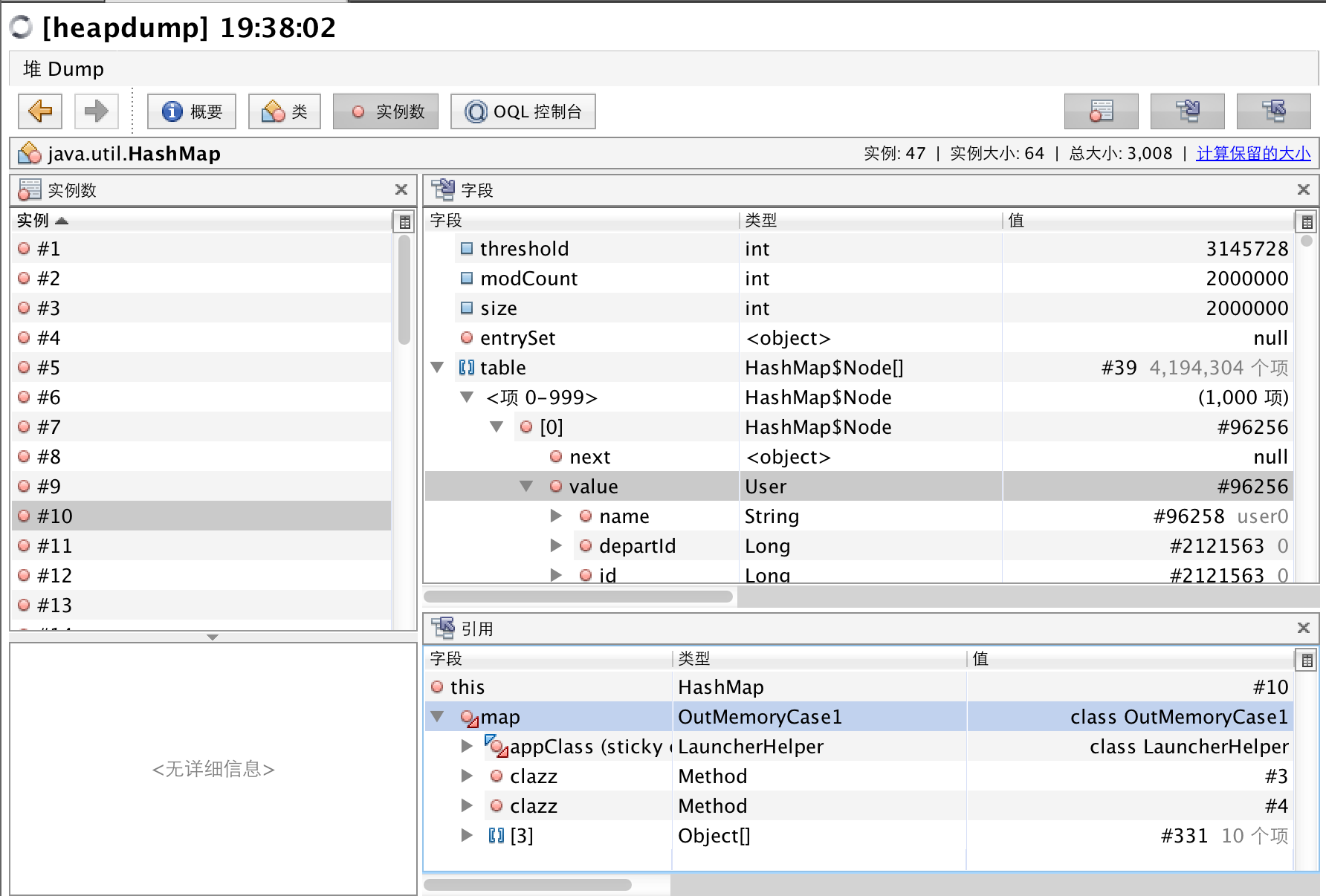
右上面板是字段面板,包含了选中实例的的所有属性,可以看到,size属性为2百万,是个非常大的数,这代表此时HashMap包含了2百万个对象,如果熟悉HashMap代码,我们知道table属性保存了所有的元素,我们可以点击table属性,向下钻取,可以看到存放的正是User对象。
右下面板是引用面板,根节点为this,表示了我们查询出来的这个HashMap实例,该面板节点每个子节点表示了所属关系,我们可以看到这个HashMap实例的名字是map,属于OutMemoryCase1类。
截至到目前为止,我们已经使用一条OQL语句找到了内存的溢出的原因,且定位到代码位置为OutMemoryCase1。我们下面学习更多的OQL语法,这有助于帮助我们分析内存
OQL语法类似SQL和Javascript结合体,javascript用于表达式和方法调用,格式如下
~~~
select <JavaScript expression to select>
[ from [instanceof] <class name> <identifier>
[ where <JavaScript boolean expression to filter> ] ]
~~~
* class name是java类的完全限定名,如:java.lang.String, java.util.ArrayList, [C是char数组, [Ljava.io.File是java.io.File[],依此类推,insatnceof 关键字用上,表示将查询其子类
* from和where子句都是可选的
* 可以使用identifier.fieldName语法访问Java字段,并且可以使用array [index]语法形式访问数组元素。
* OQL使用的是JS表达式,因此使用&&和||,不要使用and or
比如查找超长的字符串,这里的10000是一个任意指定的值,如下OQL语句查找字符串长度超过1万的。
~~~java
select s from java.lang.String s where s.value.length >= 10000
~~~
这里s表示String,查看java.lang.String有个名字为value的char[] 类型的数组,因此filter是s.value.length >= 10000
针对OutMemoryCase1,比如我们要查找user对象中departId为15的User对象,并输出其name属性
~~~java
select u.name from com.ibeetl.code.User u where u.departId.value==15
~~~
需要注意的事,User对象的departId类型Long,并非原始类型,因此需要使用Long对象的value属性来比较。另外在OQL里任意实例的都有属性id,是在OQL分配的对象唯一标识,因此,如下OQL语句在jvisualvm执行得不到期望的结果
~~~
//错误的OQL语句,id属性是内存分配的唯一id,并非用户的id属性
select u.name from com.ibeetl.code.User u where u.id.value==15
~~~
如下查询包含key为"abc"的Map,value为"edf",注意需要使用toString才能比较字符串
```sql
select m from java.util.Map$Entry m where m.key.toString()='abc'&&m.value.toString()='edf'
```
通过size函数获取实例本身占用的空间,rsize函数获取实例占用的shallow空间,实际使用空间
~~~
select sizeof(x) from java.util.HashMap x where x.size>1000
select rsizeof(x) from java.util.HashMap x where x.size>1000
~~~
rsizeof 会计算对象下每一个对象占用空间,因此执行该语句需要较长时间,sizeof仅仅计算此对象属性占用空间。查询出来的对象可以通过objectid函数得到一个16进制编号,可以记住这个唯一编号,在用函数heap.findObject直接定位到该实例
~~~sql
select objectid(x) from com.ibeetl.code.Config
//查询返回"31150212072",可以记住下次再分析的时候直接查询该Config对象
select heap.findObject(31150212072)
~~~
OQL提供了一系列的heap方法,用于查找实例,由于附录并非专门讲解OQL,因此列出重要的方法并还是以OutMemoryCase1为例子,说明如何使用
* heap.forEachClass - 为每个Java类调用一个回调函数
~~~
heap.forEachClass(callback);
~~~
* heap.forEachObject - 为每个Java对象调用回调函数
~~~
heap.forEachObject(callback, clazz, includeSubtypes);
~~~
如果clazz未指定,则是默认的java.lang.Object,includeSubtypes表示查找子类,如果未指定,默认是true,callback是一个类似JS的回掉函数.
* heap.findClass - 查找给定名称的Java类
* heap.findObject 根据对象标识查询对象
* heap.objects 返回Java对象的枚举
~~~
heap.objects(clazz, [includeSubtypes], [filter])
~~~
比如,我们需要查找某个User对象,其name属性的值是“user1“结尾,我们可以使用js正则表达式查询
~~~
heap.objects("com.ibeetl.code.User", false, "/user1$/.test(it.name)")
//或者
heap.objects ("com.ibeetl.code.User",false,"it.name.toString()=='user1'")
~~~
* heap.livepaths 返回给定对象存活的路径数组。此方法接受可选的第二个参数,它是一个布尔标志。此标志指示是否包含弱引用的路径。默认情况下,不包括具有弱引用的路径。
~~~
select heap.livepaths(config) from com.ibeetl.code.Config config
~~~
会有如下输出,我们可以看到Config对象被OutMemoryCase1引用
~~~
com.ibeetl.code.Config#1->com.ibeetl.code.OutMemoryCase1->sun.launcher.LauncherHelper
~~~
OQL提供了一些对集合操作的方法,允许查询出来的结果集,进行过滤和加工,一些常用的函数如下
* filter
filter函数返回一个数组/枚举,其中包含满足给定布尔表达式的输入数组/枚举的元素。布尔表达式代码可以引用以下内置变量。it - >目前访问过的元,index - >当前元素的索,array - >正在迭代的数组/枚举,result - > result array / enumeration
如查询User对象,name属性为“user1”
~~~
select filter(heap.objects ("com.ibeetl.code.User"), "it.name.toString()=='user1'")
~~~
或者使用回调函数
~~~javascript
select filter(heap.objects ("com.ibeetl.code.User"), function(it){
if(it.name.toString()=='user1'){
return true;
}else{
return false;
}
})
~~~
* map
通过评估每个元素上的给定代码来转换给定的数组/枚举。评估的代码可以引用以下内置变量。it - >目前访问过的元,index - >当前元素的索,array - >正在迭代的数组/枚举,result - > result array / enumeration
map函数返回通过在输入数组/枚举的每个元素上重复调用代码而创建的值的数组/枚举。
~~~javascript
select map(heap.objects('com.ibeetl.code.User'),
function (it) {
var res = objectid(it);
res+=">"+toHtml(it);
return res ;
})
~~~
此例子通过heap.objects查询所有的User实例,返回数组,并传入map方法,map将每个User实例 转化为一个字符串,包含了User实例的唯一编号,toHtml方法是OQL自带的一个方法,接受一个对象实例,输出带有类名和顺序号的字符串。运行语句,有如下输出
~~~
31138521288>com.ibeetl.code.User#1
31138521456>com.ibeetl.code.User#2
31138521624>com.ibeetl.code.User#3
........
~~~
* max函数,返回给定数组/枚举的最大元素。接受表达式以比较数组的元素。默认情况下使用数字比较。比较表达式可以使用以下内置变量:lhs - >左侧元素进行比较,rhs - >右侧元素进行比较
如查询容量最大的Map,这有可能是内存溢出发生的地方。
~~~
select max(map(heap.objects('java.util.HashMap'), 'it.size'))
// 或者
select max(heap.objects('java.util.HashMap'), 'lhs.size> rhs.size')
~~~
* min函数,同max,返回给定数组/枚举的最小元素
* sort函数,给出数组/枚举的排序。(可选)接受代码表达式以比较数组的元素。默认情况下使用数字比较。比较表达式可以使用以下内置变量:lhs 代表左侧元素,rhs - >代表右侧元素
~~~
select sort(heap.objects('[C'), 'sizeof(lhs) - sizeof(rhs)')
~~~
查询所有字符串数组,并按照大小升序排序。
附录A介绍了JDK自带的OQL,许多商业的内存分析器提供了更多的内置的分析功能以及OQL功能扩展,如果有条件,建议使用这些商业内存分析器和参考他们的OQL使用文档介绍。在我的内存故障解决里,基本上使用自带的OQL就能找到问题所在了,需要耐心的分析和查找问题。
- 内容介绍
- 第一章 Java系统优化
- 1.1 可优化的代码
- 1.2 性能监控
- 1.3 JMH
- 1.3.1 使用JMH
- 1.3.2 JMH常用设置
- 1.3.3 注意事项
- 1.3.4 单元测试
- 第二章 字符串和数字
- 2 字符串和数字操作
- 2.1 构造字符串
- 2.2 字符串拼接
- 2.3 字符串格式化
- 2.4 字符串查找
- 2.6 intern方法
- 2.7 UUID
- 2.8 StringUtils类
- 2.9 前缀树过滤
- 2.10 数字装箱
- 2.11 BigDecimal
- 第三章 并发和异步编程
- 3.1 不安全的代码
- 3.2 Java并发编程
- 3.2.1 volatile
- 3.2.2 synchronized
- 3.2.3 Lock
- 3.2.4 Condition
- 3.2.5 读写锁
- 3.2.6 semaphore
- 3.2.7 栅栏
- 3.3 Java并发工具
- 3.3.1 原子变量
- 3.3.2 Queue
- 3.3.3 Future
- 3.4 Java线程池
- 3.5 异步编程
- 3.5.1 创建异步任务
- 3.5.2 完成时回调
- 3.5.3 串行执行
- 3.5.4 并行执行
- 3.5.5 接收任务处理结果
- 第四章 代码性能优化
- 4.1 int 转 String
- 4.2 使用Native 方法
- 4.3 日期格式化
- 4.4 switch 优化
- 4.5 优先用局部变量
- 4.6 预处理
- 4.7 预分配
- 4.8 预编译
- 4.9 预先编码
- 4.10 谨慎使用Exception
- 4.11 批处理
- 4.12 展开循环
- 4.13 静态方法调用
- 4.14 高速Map存取
- 4.15 位运算
- 4.16 反射
- 4.17 压缩
- 4.18 可变数组
- 4.19 System.nanoTime()
- 4.20 ThreadLocalRandom
- 4.21 Base64
- 4.22 辨别重量级对象
- 4.23 池化技术
- 4.24 实现hashCode
- 4.25 错误优化策略
- 4.25.1 final无法帮助内联
- 4.25.2 subString 内存泄露
- 4.25.3 循环优化
- 4.25.4 循环中捕捉异常
- 4.25.5 StringBuffer性能不如StringBuilder高
- 第五章 高性能工具
- 5.1 高速缓存 caffeine
- 5.1.1 安装
- 5.1.2 caffeine 基本使用
- 5.1.3 淘汰策略
- 5.1.4 statistics 功能
- 5.1.5 caffeine高命中率
- 5.1.6 卓越性能
- 5.2 selma映射工具
- 5.3 Json工具 Jackson
- 5.3.1 Jackson三种使用方式
- 5.3.3 对象绑定
- 5.3.2 Jackson 树遍历
- 5.3.4 流式操作
- 5.3.6 自定义 JsonSerializer
- 5.3.7 集合的反序列化
- 5.3.8 性能提升和优化
- 5.4 HikariCP
- 5.4.1 HikariCP安装
- 5.4.3 HikariCP 性能测试
- 5.4.4 性能优化说明
- 5.5 文本处理Beetl
- 5.5.1 安装和配置
- 5.5.2 脚本引擎
- 5.5.3 特点
- 5.5.4 性能优化
- 5.6 MessagePack
- 5.7 ReflectASM
- 第六章 Java注释
- 6.1 JavaDoc
- 6.2 Tag
- 6.2.1 {@link}
- 6.2.2 @deprecated
- 6.2.3 {@literal}
- 6.2.4 {@code}
- 6.2.5 {@value}
- 6.2.6 @author
- 6.2.7 @param 和 @return
- 6.2.8 @throws
- 6.2.9 @see
- 6.2.10 自动拷贝
- 6.3 Package-Info
- 6.4 HTML生成
- 6.5 Markdown-doclet
- 第七章 可读性代码
- 7.1 精简注释
- 7.2 变量
- 7.2.1 变量命名
- 7.2.2 变量的位置
- 7.2.3 中间变量
- 7.3 方法
- 7.3 .1 方法签名
- 7.3.2 小方法
- 7.3.3 单一职责
- 7.3.3 小类
- 7.4 分支
- 7.4.1 if else
- 7.4.2 switch case
- 7.5 发现对象
- 7.3.1 不要用String
- 7.3.2 不要用数组,Map
- 7.6 checked异常
- 7.7 其他
- 7.7.1 避免自动格式化
- 7.7.2 关于Null
- 第八章 JIT优化
- 8.1 解释和编译
- 8.2 C1和C2
- 8.3 代码缓存
- 8.4 JITWatch
- 8.5 内联
- 8.6 虚方法调用
- 第九章 代码审查
- 9.1 ConcurrentHashMap陷阱
- 9.2 字符串搜索
- 9.3 IO输出
- 9.4 字符串拼接
- 9.5 方法的入参和出参
- 9.6 RPC调用定义的返回值
- 9.7 Integer使用
- 9.8 排序
- 9.9 判断特殊的ID
- 9.10 优化if结构
- 9.11 文件COPY
- 9.12 siwtch优化
- 9.13 Encoder
- 9.14一个JMH例子
- 9.15 注释
- 9.16 完善注释
- 9.17 方法抽取
- 9.18 遍历Map
- 9.19 日期格式化
- 9.20 日志框架设计的问题
- 9.21 持久化到数据库
- 9.22 某个RPC框架
- 9.23 循环调用
- 9.24 Lock使用
- 9.25 字符集
- 9.26 处理枚举值
- 9.27 任务执行
- 9.28 开关判断
- 9.29 JDBC操作
- 9.30 Controller代码
- 9.31 停止任务
- 9.32 log框架
- 9.33 缩短UUID
- 9.34 Dubbo ThreadPool设置
- 9.35 压缩设备信息
- 第十章 ASM运行时增强
- 10.1 Java字节码
- 10.1.1 基础知识
- 10.1.2 class文件格式
- 10.2 Java方法的执行
- 10.2.1 方法在内存的表示
- 10.2.3 方法在class文件中的表示
- 10.2.3 指令的分类
- 10.2.4 操作数栈的变化分析
- 10.3 Bytecode Outline插件
- 10.4 ASM入门
- 10.4.1 生成类名及构造函数
- 10.4.2 生成main方法
- 10.4.3 调用生成的代码
- 10.5 ASM增强代码
- 10.5.1 使用反射实现
- 10.5.2 使用ASM生成辅助类
- 10.5.3 switch语句的分类
- 10.5.4 获取bean中的property
- 10.5.5 switch语句的实现
- 10.5.6 性能对比
- 第十一章 JSR269编译时增强
- 11.1 Java编译的过程
- 11.2 注解处理器入门
- 11.3 相关概念介绍
- 11.3.1 AbstractProcessor
- 11.3.2 Element与TypeMirror
- 11.4 注解处理器进阶
- 11.4.1 JsonWriter注解
- 11.4.2 处理器与生成辅助类
- 11.4.3 使用生成的Mapper类
- 11.4.4 注解处理器的使用
- 11.5 调试注解处理器
- 11.5.1 Eclipse中调试注解处理器
- 11.5.2 Idea中调试注解处理
- 附录A OQL分析JVM内存(免费)
- 附录B 7行代码的9种性能优化方法(免费)
- 附录 C CPUCacheTest更多讨论(免费)