
语法形式:
```
group by 字段1, 字段2, .... ;
```
含义:
表示对所取得的数据,以所给定的字段来进行分组。
最后的结果就是将数据分成了若干组,每组作为一个“整体”成为一行数据。
特别注意:
分组之后,只有“组信息”——一行就是一组
示例:
对于如下原始数据:
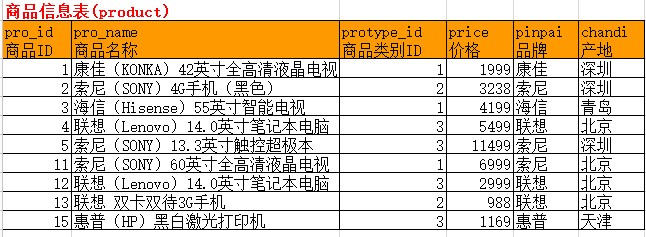
对其按“品牌”进行分组:

结果为:
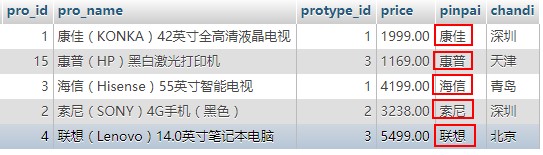
### 特别注意:
分组查询的结果,要理解为,将“若干行原始数据”,分成了若干组,结果是每组为一行数据。
即:一行数据就代表“一组”这个集合概念,而不再是单个概念。
因此:一行中出现的信息,应该是“组的信息”,而不是“个体信息”。
于是,对于分组查询(group by),select中出现的信息,通常就只有两种情况的信息了:
1,分组本身的字段信息;
2,一组的综合统计信息,主要包括:
(1) 计数值: count(字段), 表示求出一组中原始数据的行数;
(2) 最大值: max(字段),表示求出一组中该字段的最大值;
(3) 最小值: min(字段),表示求出一组中该字段的最小值;
(4) 平均值: avg(字段),表示求出一组中该字段的平均值;
(5) 总和值: sum(字段),表示求出一组中该字段的累加和;
以上5个函数,也称为“聚合函数”!
示例:
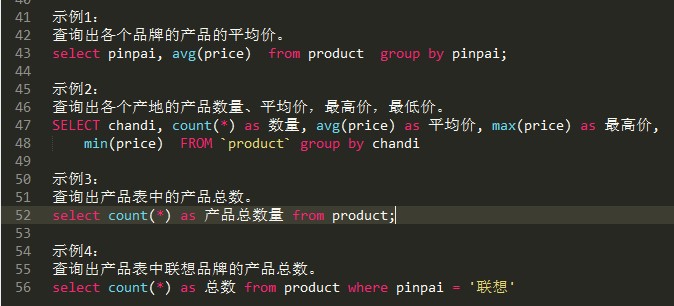
多条件分组:
将product表中的所有商品以品牌和产地进行分组,并求出每一组的数量
```
select pinpai, chandi, count(*) as 数量 from product group by pinpai, chandi;
```
- 1、数据库介绍
- 1.1.主流数据库
- 1.2.MySQL数据库概览
- 1.3.关系数据库
- 2、访问mysql数据库服务器
- 2.1.开启/关闭数据库服务
- 2.2.客户端连接数据库服务器
- 3、数据库操作
- 3.1.查看所有数据库
- 3.2.创建新数据库
- 3.3.查看数据库创建信息
- 3.4.删除现有数据库
- 3.5.修改现有数据库
- 3.6.选择(使用)某个数据库
- 4、数据表操作
- 4.1.创建数据表初步
- 4.2.查看所有数据表
- 4.3.查看数据表结构
- 4.4.查看数据表的创建语句
- 4.5.删除数据表
- 4.6.修改数据表
- 5、数据操作初步
- 5.1.插入数据
- 5.2.查询数据
- 5.3.删除数据
- 5.4.修改数据
- 6、MySQL数据类型
- 6.1.数据类型(列类型)总览
- 6.2.整型
- 6.3.小数型
- 6.4.日期时间型
- 6.5.字符串型
- 7、列属性
- 8、实体与实体的关系
- 8.1.基本概念
- 8.2.一对一关系
- 8.3.一对多关系
- 8.4.多对多关系
- 9、高级查询
- 9.1.高级查询语法概述
- 9.2.查询结果数据及select选项
- 9.3.where子句
- 9.4.mysql运算符
- 9.5.group by子句
- 9.6.having子句
- 9.7.order by子句
- 9.8.limit 子句
- 10、高级插入
- 10.1.同时插入多行记录
- 10.2.插入查询的结果数据
- 10.3.set语法插入数据
- 10.4.蠕虫复制
- 10.5.插入时主键冲突的解决办法
- 11、高级删除
- 11.1.按指定顺序删除指定数量的数据
- 11.2.truncate清空
- 12、高级更新
- 13、联合(union)查询
- 13.1.联合查询概念
- 13.2.联合查询语法
- 14、连接(join)查询
- 14.1.连接查询概述
- 14.2.交叉连接(cross join)
- 14.3.内连接(inner join)
- 14.4.外连接
- 14.5.自连接
- 15、子查询(subquery)
- 15.1.子查询的概念
- 15.2.标量子查询
- 15.3.列子查询
- 15.4.行子查询
- 15.5.表子查询
- 15.6.有关子查询的特定关键字
- 15.7.exists子查询
- 16、数据管理
- 16.1.数据备份
- 16.2.数据还原(数据恢复)
- 17、用户管理:
- 17.1.查看用户
- 17.2.创建用户
- 17.3.删除用户
- 17.4.修改/设置用户密码
- 17.5.授予用户权限
- 17.6.取消用户授权