[toc]
# 一、collection概述
collection是一个接口类,其有两个主要的子接口List和Set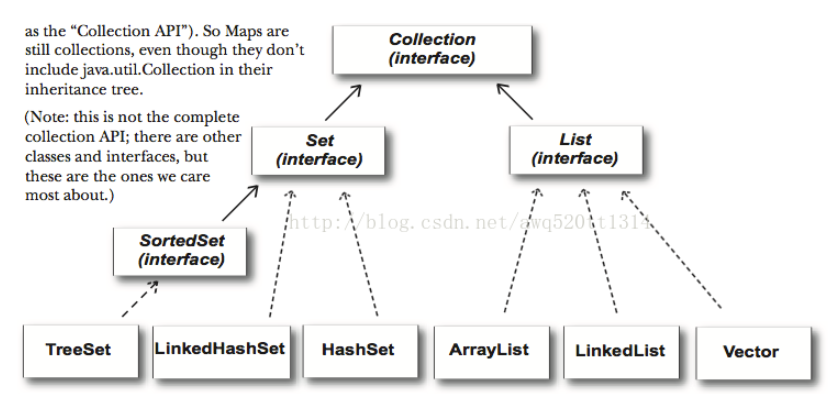
List(interface):List可以通过index知道元素的位置,它是<b>有序的</b>,并且允许元素<b>重复</b>
Set(interface):<b>无序的,不允许元素重复</b>
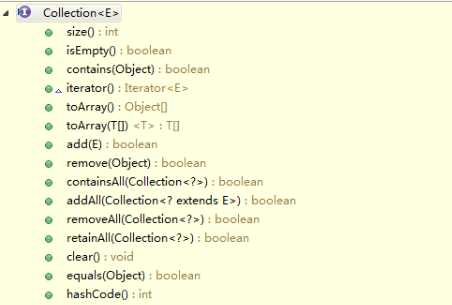
## collection的方法
# 二、List
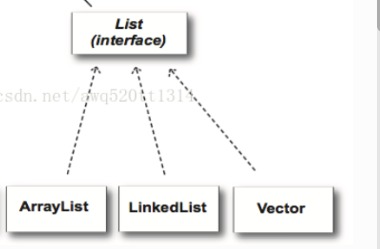
有三个比较常用的继承List接口的类,分别是ArrayList、LinkedList和Vector
List接口:有序的,此接口可以对列表中元素的插入位置精确控制,允许多个null值,元素可重复
ArrayList:ArrayList是个动态数组,擅长随机访问,非同步的
LinkedList:LinkedList是个双向链表,不能随机访问,非同步
Vector:Vctor是同步 的,其他同ArrayList类似,是线程安全的动态数组。
## 2-1.ArrayList
ArrayList就是一个<b>动态数组</b>,按照添加对象的顺序存储对象,<b>随机访问</b>速度极快。缺点是不适合于在线性表中间需要频繁进行插入和删除操作。因为每次插入和删除都需要移动数组中的元素。
~~~
//E是泛型,代表一种类型,让ArrayList里存的是同一种类型的数据
List<E> list = new ArrayList<>();
~~~
### ArrayList常用API
set(int index,E element)

remove(int index)

indexOf(Object o)

### ArrayList四个注意点
a.如果在初试化ArrayList的时候没有指定初始长度的话,默认长度为10
~~~
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
~~~
b.ArrayList在增加新元素的时候如果超过了原始的容量的话,ArrayList扩容ensureCapacity的方案为<b>“原始容量*1.5+1”</b>
~~~
public void ensureCapacity(int minCapacity) {
modCount++;
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3)/2 + 1;
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
~~~
c.ArrayList是线程不安全的,在多线程的情况下不要使用。多线程用Vector。
d.ArrayList实现遍历的几种方法。
~~~
public class Test{
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("Hello");
list.add("World");
list.add("HAHAHAHA");
//第一种遍历方法使用foreach遍历List
for (String str : list) { //也可以改写for(int i=0;i<list.size();i++)这种形式
System.out.println(str);
}
//第二种遍历,把链表变为数组相关的内容进行遍历
String[] strArray=new String[list.size()];
list.toArray(strArray);
for(int i=0;i<strArray.length;i++) //这里也可以改写为foreach(String str:strArray)这种形式
{
System.out.println(strArray[i]);
}
//第三种遍历 使用迭代器进行相关遍历
Iterator<String> ite=list.iterator();
while(ite.hasNext())
{
System.out.println(ite.next());
}
}
}
~~~
## 2-2.LinkedList
LinkedList是一个<b>双向链表</b>,优点在于适合于在链表中间需要频繁进行<b>插入和删除</b>操作,缺点是随机访问速度较慢,查找每个元素都需要从头开始一个个找。
遍历LinkedList
~~~
List<String> list=new LinkedList<String>();
list.add("Hello");
list.add("World");
list.add("HAHAHAHA");
for(String str:list){
System.out.println(str);
}
~~~
## 2-3.Vector
vector和arraylist基本一致,区别在于vector中的绝大部分方法都使用了<b>synchronized</b>锁,使得vector多线程的情况下是安全的。vector是允许设置默认的增长长度,vector的默认扩容方式为原来的2倍。
# 三、Set
set接口也是collection的一个常用子接口。set接口区别于list接口的特点在于:
set中的元素不能重复,并且是无序的,最多允许一个null值。
注意:虽然set中元素没有顺序,但是元素在set中的位置是由该元素的hashcode决定的,其具体位置其实是<b>固定的</b>。
## 1.HashSet
~~~
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
~~~
由hashset的部分源码可知,hashset的底层就是<b>基于hashmap</b>来实现的。
hashset使用和理解中容易出现的误区:
a.hashset中存储元素的位置是固定的
hashset中存储元素是<b>无序的</b>,由于hashset底层是基于hash算法实现的,使用了hashcode,所以hashset中相应的元素的位置是固定的
b.遍历hashset的几种方法
~~~
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("hello");
set.add("world");
set.add("hello");
//1.使用foreach循环遍历
for(String str:set){
System.out.println(str);
}
//2.使用迭代器遍历
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
~~~
## 2.LinkedHashSet
~~~
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
private static final long serialVersionUID = -2851667679971038690L;
/**
* Constructs a new, empty linked hash set with the specified initial
* capacity and load factor.
*/
~~~
由linkedhashset的源码可知,linkedhashset不仅是set的子接口,还是上面<b>hashset的子类</b>。
通过查看底层源码发现,其底层是基于linkedhashmap。
### linkedhashset和hashset异同点
1.**hashset和linkedhashset都出于速度原因使用了散列,故都没排序,而linkedset使用了链表维护了元素的插入顺序**
2.hashset是linkedhashset的父类
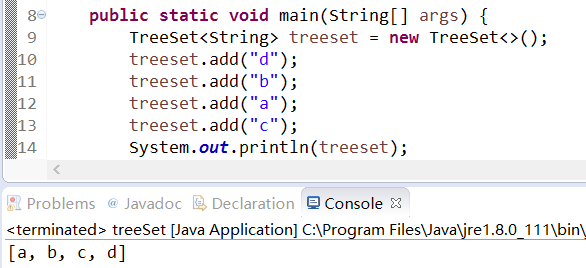
## 3.TreeSet
treeset是一种<b>排序二叉树</b>。存入set集合中的值,会按照值的大小进行相关的排序操作,底层算法是<b>基于红黑树</b>来实现的。
### treeset和hashset的区别和联系
1.hashset是通过hashmap实现的,treeset是通过treemap实现的,只是用了map的key值。
2.map的key和set都有一个共同的特性就是集合的唯一性。treemap更是多了一个排序的功能。
3. hashCode和equal()是HashMap用的, 因为无需排序所以只需要关注定位和唯一性即可.
a. hashCode是用来计算hash值的,hash值是用来确定hash表索引的.
b. hash表中的一个索引处存放的是一张链表, 所以还要通过equal方法循环比较链上的每一个对象
才可以真正定位到键值对应的Entry.
c. put时,如果hash表中没定位到,就在链表前加一个Entry,如果定位到了,则更换Entry中的value,并返回旧value
4. 由于TreeMap需要排序,所以需要一个Comparator为键值进行大小比较.当然也是用Comparator定位的.
a. Comparator可以在创建TreeMap时指定
b. 如果创建时没有确定,那么就会使用key.compareTo()方法,这就要求key必须实现Comparable接口.
c. TreeMap是使用Tree数据结构实现的,所以使用compare接口就可以完成定位了.
