
在 JDK 1.5 之前共享对象的协调机制只有 synchronized 和 volatile,在 JDK 1.5 中增加了新的机制 ReentrantLock,该机制的诞生并不是为了替代 synchronized,而是在 synchronized 不适用的情况下,提供一种可以选择的高级功能。
我们本课时的面试题是,synchronized 和 ReentrantLock 是如何实现的?它们有什么区别?
#### 典型回答
synchronized 属于独占式悲观锁,是通过 JVM 隐式实现的,synchronized 只允许同一时刻只有一个线程操作资源。
在 Java 中每个对象都隐式包含一个 monitor(监视器)对象,加锁的过程其实就是竞争 monitor 的过程,当线程进入字节码 monitorenter 指令之后,线程将持有 monitor 对象,执行 monitorexit 时释放 monitor 对象,当其他线程没有拿到 monitor 对象时,则需要阻塞等待获取该对象。
ReentrantLock 是 Lock 的默认实现方式之一,它是基于 AQS(Abstract Queued Synchronizer,队列同步器)实现的,它默认是通过非公平锁实现的,在它的内部有一个 state 的状态字段用于表示锁是否被占用,如果是 0 则表示锁未被占用,此时线程就可以把 state 改为 1,并成功获得锁,而其他未获得锁的线程只能去排队等待获取锁资源。
synchronized 和 ReentrantLock 都提供了锁的功能,具备互斥性和不可见性。在 JDK 1.5 中 synchronized 的性能远远低于 ReentrantLock,但在 JDK 1.6 之后 synchronized 的性能略低于 ReentrantLock,它的区别如下:
* synchronized 是 JVM 隐式实现的,而 ReentrantLock 是 Java 语言提供的 API;
* ReentrantLock 可设置为公平锁,而 synchronized 却不行;
* ReentrantLock 只能修饰代码块,而 synchronized 可以用于修饰方法、修饰代码块等;
* ReentrantLock 需要手动加锁和释放锁,如果忘记释放锁,则会造成资源被永久占用,而 synchronized 无需手动释放锁;
* ReentrantLock 可以知道是否成功获得了锁,而 synchronized 却不行。
#### 考点分析
synchronized 和 ReentrantLock 是比线程池还要高频的面试问题,因为它包含了更多的知识点,且涉及到的知识点更加深入,对面试者的要求也更高,前面我们简要地介绍了 synchronized 和 ReentrantLock 的概念及执行原理,但很多大厂会更加深入的追问更多关于它们的实现细节,比如:
* ReentrantLock 的具体实现细节是什么?
* JDK 1.6 时锁做了哪些优化?
#### 知识扩展
* [ ] ReentrantLock 源码分析
本课时从源码出发来解密 ReentrantLock 的具体实现细节,首先来看 ReentrantLock 的两个构造函数:
```
public ReentrantLock() {
sync = new NonfairSync(); // 非公平锁
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
```
无参的构造函数创建了一个非公平锁,用户也可以根据第二个构造函数,设置一个 boolean 类型的值,来决定是否使用公平锁来实现线程的调度。
* [ ] 公平锁 VS 非公平锁
公平锁的含义是线程需要按照请求的顺序来获得锁;而非公平锁则允许“插队”的情况存在,所谓的“插队”指的是,线程在发送请求的同时该锁的状态恰好变成了可用,那么此线程就可以跳过队列中所有排队的线程直接拥有该锁。
而公平锁由于有挂起和恢复所以存在一定的开销,因此性能不如非公平锁,所以 ReentrantLock 和 synchronized 默认都是非公平锁的实现方式。
ReentrantLock 是通过 lock() 来获取锁,并通过 unlock() 释放锁,使用代码如下:
```
Lock lock = new ReentrantLock();
try {
// 加锁
lock.lock();
//......业务处理
} finally {
// 释放锁
lock.unlock();
}
```
ReentrantLock 中的 lock() 是通过 sync.lock() 实现的,但 Sync 类中的 lock() 是一个抽象方法,需要子类 NonfairSync 或 FairSync 去实现,NonfairSync 中的 lock() 源码如下:
```
final void lock() {
if (compareAndSetState(0, 1))
// 将当前线程设置为此锁的持有者
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
```
FairSync 中的 lock() 源码如下:
```
final void lock() {
acquire(1);
}
```
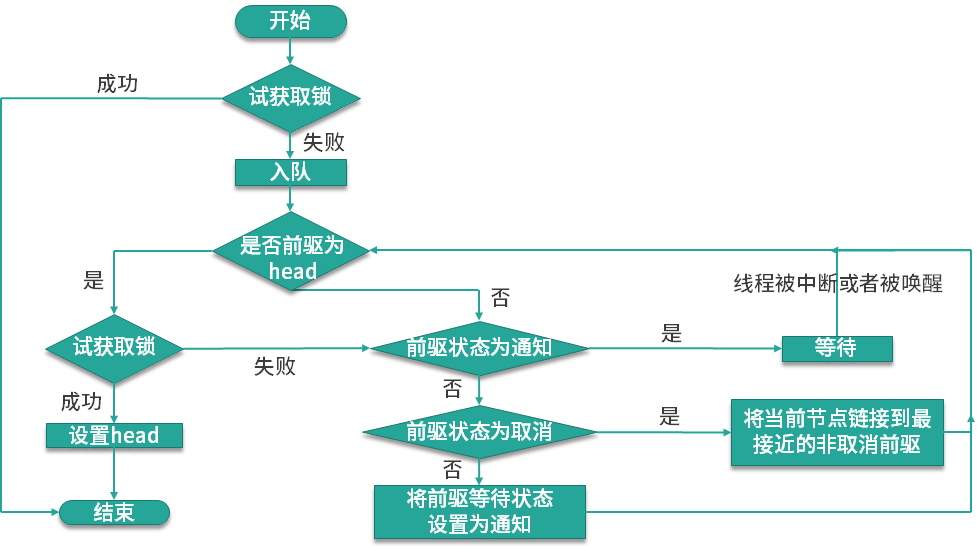
可以看出非公平锁比公平锁只是多了一行 compareAndSetState 方法,该方法是尝试将 state 值由 0 置换为 1,如果设置成功的话,则说明当前没有其他线程持有该锁,不用再去排队了,可直接占用该锁,否则,则需要通过 acquire 方法去排队。
acquire 源码如下:
```
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
```
tryAcquire 方法尝试获取锁,如果获取锁失败,则把它加入到阻塞队列中,来看 tryAcquire 的源码:
```
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
// 公平锁比非公平锁多了一行代码 !hasQueuedPredecessors()
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) { //尝试获取锁
setExclusiveOwnerThread(current); // 获取成功,标记被抢占
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc); // set state=state+1
return true;
}
return false;
}
```
对于此方法来说,公平锁比非公平锁只多一行代码 !hasQueuedPredecessors(),它用来查看队列中是否有比它等待时间更久的线程,如果没有,就尝试一下是否能获取到锁,如果获取成功,则标记为已经被占用。
如果获取锁失败,则调用 addWaiter 方法把线程包装成 Node 对象,同时放入到队列中,但 addWaiter 方法并不会尝试获取锁,acquireQueued 方法才会尝试获取锁,如果获取失败,则此节点会被挂起,源码如下:
```
/**
* 队列中的线程尝试获取锁,失败则会被挂起
*/
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true; // 获取锁是否成功的状态标识
try {
boolean interrupted = false; // 线程是否被中断
for (;;) {
// 获取前一个节点(前驱节点)
final Node p = node.predecessor();
// 当前节点为头节点的下一个节点时,有权尝试获取锁
if (p == head && tryAcquire(arg)) {
setHead(node); // 获取成功,将当前节点设置为 head 节点
p.next = null; // 原 head 节点出队,等待被 GC
failed = false; // 获取成功
return interrupted;
}
// 判断获取锁失败后是否可以挂起
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
// 线程若被中断,返回 true
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
```
该方法会使用 for(;;) 无限循环的方式来尝试获取锁,若获取失败,则调用 shouldParkAfterFailedAcquire 方法,尝试挂起当前线程,源码如下:
```
/**
* 判断线程是否可以被挂起
*/
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获得前驱节点的状态
int ws = pred.waitStatus;
// 前驱节点的状态为 SIGNAL,当前线程可以被挂起(阻塞)
if (ws == Node.SIGNAL)
return true;
if (ws > 0) {
do {
// 若前驱节点状态为 CANCELLED,那就一直往前找,直到找到一个正常等待的状态为止
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
// 并将当前节点排在它后边
pred.next = node;
} else {
// 把前驱节点的状态修改为 SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
```
线程入列被挂起的前提条件是,前驱节点的状态为 SIGNAL,SIGNAL 状态的含义是后继节点处于等待状态,当前节点释放锁后将会唤醒后继节点。所以在上面这段代码中,会先判断前驱节点的状态,如果为 SIGNAL,则当前线程可以被挂起并返回 true;如果前驱节点的状态 >0,则表示前驱节点取消了,这时候需要一直往前找,直到找到最近一个正常等待的前驱节点,然后把它作为自己的前驱节点;如果前驱节点正常(未取消),则修改前驱节点状态为 SIGNAL。
到这里整个加锁的流程就已经走完了,最后的情况是,没有拿到锁的线程会在队列中被挂起,直到拥有锁的线程释放锁之后,才会去唤醒其他的线程去获取锁资源,整个运行流程如下图所示:
unlock 相比于 lock 来说就简单很多了,源码如下:
```
public void unlock() {
sync.release(1);
}
public final boolean release(int arg) {
// 尝试释放锁
if (tryRelease(arg)) {
// 释放成功
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
```
锁的释放流程为,先调用 tryRelease 方法尝试释放锁,如果释放成功,则查看头结点的状态是否为 SIGNAL,如果是,则唤醒头结点的下个节点关联的线程;如果释放锁失败,则返回 false。
tryRelease 源码如下:
```
/**
* 尝试释放当前线程占有的锁
*/
protected final boolean tryRelease(int releases) {
int c = getState() - releases; // 释放锁后的状态,0 表示释放锁成功
// 如果拥有锁的线程不是当前线程的话抛出异常
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) { // 锁被成功释放
free = true;
setExclusiveOwnerThread(null); // 清空独占线程
}
setState(c); // 更新 state 值,0 表示为释放锁成功
return free;
}
```
在 tryRelease 方法中,会先判断当前的线程是不是占用锁的线程,如果不是的话,则会抛出异常;如果是的话,则先计算锁的状态值 getState() - releases 是否为 0,如果为 0,则表示可以正常的释放锁,然后清空独占的线程,最后会更新锁的状态并返回执行结果。
#### JDK 1.6 锁优化
* [ ] 自适应自旋锁
JDK 1.5 在升级为 JDK 1.6 时,HotSpot 虚拟机团队在锁的优化上下了很大功夫,比如实现了自适应式自旋锁、锁升级等。
JDK 1.6 引入了自适应式自旋锁意味着自旋的时间不再是固定的时间了,比如在同一个锁对象上,如果通过自旋等待成功获取了锁,那么虚拟机就会认为,它下一次很有可能也会成功 (通过自旋获取到锁),因此允许自旋等待的时间会相对的比较长,而当某个锁通过自旋很少成功获得过锁,那么以后在获取该锁时,可能会直接忽略掉自旋的过程,以避免浪费 CPU 的资源,这就是自适应自旋锁的功能。
* [ ] 锁升级
锁升级其实就是从偏向锁到轻量级锁再到重量级锁升级的过程,这是 JDK 1.6 提供的优化功能,也称之为锁膨胀。
偏向锁是指在无竞争的情况下设置的一种锁状态。偏向锁的意思是它会偏向于第一个获取它的线程,当锁对象第一次被获取到之后,会在此对象头中设置标示为“01”,表示偏向锁的模式,并且在对象头中记录此线程的 ID,这种情况下,如果是持有偏向锁的线程每次在进入的话,不再进行任何同步操作,如 Locking、Unlocking 等,直到另一个线程尝试获取此锁的时候,偏向锁模式才会结束,偏向锁可以提高带有同步但无竞争的程序性能。但如果在多数锁总会被不同的线程访问时,偏向锁模式就比较多余了,此时可以通过 -XX:-UseBiasedLocking 来禁用偏向锁以提高性能。
轻量锁是相对于重量锁而言的,在 JDK 1.6 之前,synchronized 是通过操作系统的互斥量(mutex lock)来实现的,这种实现方式需要在用户态和核心态之间做转换,有很大的性能消耗,这种传统实现锁的方式被称之为重量锁。
而轻量锁是通过比较并交换(CAS,Compare and Swap)来实现的,它对比的是线程和对象的 Mark Word(对象头中的一个区域),如果更新成功则表示当前线程成功拥有此锁;如果失败,虚拟机会先检查对象的 Mark Word 是否指向当前线程的栈帧,如果是,则说明当前线程已经拥有此锁,否则,则说明此锁已经被其他线程占用了。当两个以上的线程争抢此锁时,轻量级锁就膨胀为重量级锁,这就是锁升级的过程,也是 JDK 1.6 锁优化的内容。
#### 小结
本课时首先讲了 synchronized 和 ReentrantLock 的实现过程,然后讲了 synchronized 和 ReentrantLock 的区别,最后通过源码的方式讲了 ReentrantLock 加锁和解锁的执行流程。接着又讲了 JDK 1.6 中的锁优化,包括自适应式自旋锁的实现过程,以及 synchronized 的三种锁状态和锁升级的执行流程。
synchronized 刚开始为偏向锁,随着锁竞争越来越激烈,会升级为轻量级锁和重量级锁。如果大多数锁被不同的线程所争抢就不建议使用偏向锁了。
#### 课后问答
* 1、在自适应自旋锁中,“而当某个锁通过自旋很少成功获得过锁”有点理解不了。请问磊哥 锁获得锁是什么情况?
讲师回复: 可以理解为通过不停的循环获得了(CPU的)执行权
* 2、而公平锁由于有挂起和恢复所以存在一定的开销,因此性能不如非公平锁。非公平锁也有挂起和恢复吧。
讲师回复: 可以看下第六课时哈,有相应的答案。
* 3、老师,请问自旋锁的自旋是什么意思?发现好多专有名词
讲师回复: 就是自己循环获取锁的意思
* 4、synchronized没有结合markword分析加锁的过程!如何进行锁的升级的?
讲师回复: 内容有限,源码没贴,但升级的过程有文字描述,可以自行对照源码看一下。
* 5、意思是如果偏向锁被禁用,那后边的竞争机制是轻量级锁吗?
编辑回复: 对,偏向到轻量到重量这个过程
* 9、为什么两个以上线程竞争锁的时候会升级为重量级锁?java中哪些是重量级锁,我理解的是CAS是类似自旋的,多个就耗费CPU了,重量级会进休眠状态?
讲师回复: 文中有写,JDK 1.6 以后引入自适应自旋了
- 前言
- 开篇词
- 开篇词:大厂技术面试“潜规则”
- 模块一:Java 基础
- 第01讲:String 的特点是什么?它有哪些重要的方法?
- 第02讲:HashMap 底层实现原理是什么?JDK8 做了哪些优化?
- 第03讲:线程的状态有哪些?它是如何工作的?
- 第04讲:详解 ThreadPoolExecutor 的参数含义及源码执行流程?
- 第05讲:synchronized 和 ReentrantLock 的实现原理是什么?它们有什么区别?
- 第06讲:谈谈你对锁的理解?如何手动模拟一个死锁?
- 第07讲:深克隆和浅克隆有什么区别?它的实现方式有哪些?
- 第08讲:动态代理是如何实现的?JDK Proxy 和 CGLib 有什么区别?
- 第09讲:如何实现本地缓存和分布式缓存?
- 第10讲:如何手写一个消息队列和延迟消息队列?
- 模块二:热门框架
- 第11讲:底层源码分析 Spring 的核心功能和执行流程?(上)
- 第12讲:底层源码分析 Spring 的核心功能和执行流程?(下)
- 第13讲:MyBatis 使用了哪些设计模式?在源码中是如何体现的?
- 第14讲:SpringBoot 有哪些优点?它和 Spring 有什么区别?
- 第15讲:MQ 有什么作用?你都用过哪些 MQ 中间件?
- 模块三:数据库相关
- 第16讲:MySQL 的运行机制是什么?它有哪些引擎?
- 第17讲:MySQL 的优化方案有哪些?
- 第18讲:关系型数据和文档型数据库有什么区别?
- 第19讲:Redis 的过期策略和内存淘汰机制有什么区别?
- 第20讲:Redis 怎样实现的分布式锁?
- 第21讲:Redis 中如何实现的消息队列?实现的方式有几种?
- 第22讲:Redis 是如何实现高可用的?
- 模块四:Java 进阶
- 第23讲:说一下 JVM 的内存布局和运行原理?
- 第24讲:垃圾回收算法有哪些?
- 第25讲:你用过哪些垃圾回收器?它们有什么区别?
- 第26讲:生产环境如何排除和优化 JVM?
- 第27讲:单例的实现方式有几种?它们有什么优缺点?
- 第28讲:你知道哪些设计模式?分别对应的应用场景有哪些?
- 第29讲:红黑树和平衡二叉树有什么区别?
- 第30讲:你知道哪些算法?讲一下它的内部实现过程?
- 模块五:加分项
- 第31讲:如何保证接口的幂等性?常见的实现方案有哪些?
- 第32讲:TCP 为什么需要三次握手?
- 第33讲:Nginx 的负载均衡模式有哪些?它的实现原理是什么?
- 第34讲:Docker 有什么优点?使用时需要注意什么问题?
- 彩蛋
- 彩蛋:如何提高面试成功率?