
[TOC]
## **什么是Spark?**
Spark是**用于大规模数据处理的,基于内存计算的统一分析引擎**。Spark借鉴MapReduce发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度,并提供丰富的API提高了开发速度。Spark可以计算:**结构化、半结构化、非结构化等各种类型的数据结构**,支持使用Python、Java、Scala、R以及SQL语言去开发数据计算程序。
- Spark是Apache基金会旗下的顶级开源项目,用于对海量数据进行大规模分布式计算。
## **什么是PySpark**
Spark安装目录里面的bin/pyspark 程序,提供一个Python解释器执行环境来运行Spark任务。我们现在说的PySpark, 是Spark官方提供的一个Python类库,内置了完全的Spark API, 可以通过PySpark类库来编写Spark应用程序,并将其提交到Spark集群中运行
- PySpark是Spark的Python实现,是Spark为Python开发者提供的编程入口,用于以Python代码完成Spark任务的开发
- PySpark不仅可以作为Python第三方库使用,也可以将程序提交的Spark集群环境中,调度大规模集群进行执行。
## **PySpark安装**
~~~
pip install pyspark
~~~
## **PySpark使用**
~~~python
# 导包
from pyspark import SparkConf, SparkContext
# 创建SparkConf对象
conf = SparkConf().setMaster("local[*]").setAppName("demo2")
# 基于SparkConf对象创建SparkContext对象
sc = SparkContext(conf=conf)
# 执行逻辑代码
# 停止SparkContext对象运行(停止PySpark程序)
sc.stop()
~~~
:-: 
:-: 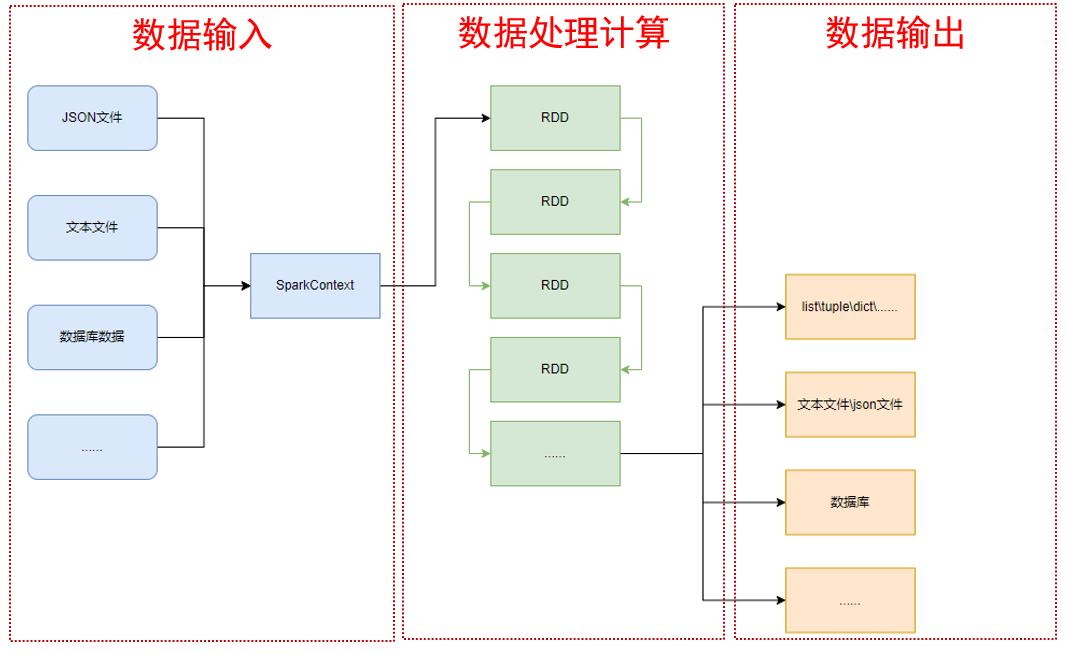
- 通过SparkContext对象,完成数据输入
- 输入数据后得到RDD对象,对RDD对象进行迭代计算
- 最终通过RDD对象的成员方法,完成数据输出工作
### **RDD对象**
**RDD全称**:弹性分布式数据集(Resilient Distributed Datasets)
通过 SparkContext 对象的 `parallelize `成员方法,将`list`、`tuple`、`set`、`dict`、`str`转换为PySpark的RDD对象
~~~python
from pyspark import SparkConf, SparkContext
# 创建SparkConf对象
conf = SparkConf().setMaster("local[*]").setSparkHome("test_spark")
# 基于SparkConf类对象创建SparkContext对象
sc = SparkContext(conf=conf)
# 通过parallelize方法将python对象加载到spark内,成为RDD对象
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize((1, 2, 3, 4, 5))
rdd3 = sc.parallelize("方式腐恶哦吼")
rdd4 = sc.parallelize({1, 2, 3, 4, 5})
rdd5 = sc.parallelize({"key1": "value1", "key2": "value2", })
# # 查看RDD中的内容
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
~~~
## **算子**
### **数据计算类**
#### **Map**
- 功能:map算子,是将RDD的数据一条条处理 处理的逻辑基于map算子中接收的处理函数 ),返回新的RDD
- 语法:

- 代码:
~~~
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = rdd.map(lambda x: x * 10).map(lambda x: x + 5)
print(rdd2.collect())
# 结果:
# [15, 25, 35, 45, 55]
~~~
#### **flatMap**
- 功能:对rdd执行map操作,然后进行**解除嵌套**操作

- 代码
~~~
rdd = sc.parallelize(["fsfes gsg 45", "56 f omo", "65 dsfmles 5", "dsads 56 dd"])
rdd2 = rdd.flatMap(lambda x: x.split(" "))
print(rdd2.collect())
# 结果:
# ['fsfes', 'gsg', '45', '56', 'f', 'omo', '65', 'dsfmles', '5', 'dsads', '56', 'dd']
~~~
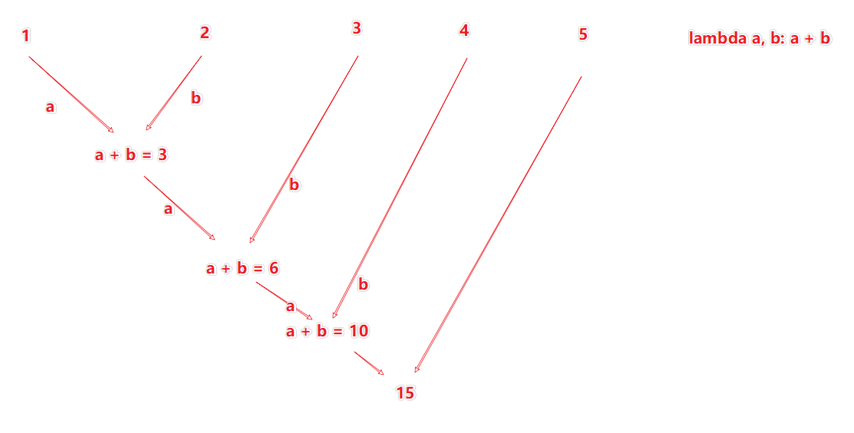
#### **reducrByKey**
- 功能:针对key-value型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成**组内数据(value)**的聚合操作。
- 用法:

- 代码:
~~~
rdd = sc.parallelize([('男', 6), ('女', 98), ('男', 87), ('男', 99), ('女', 78), ('女', 66)])
rdd2 = rdd.reduceByKey(lambda a, b: a + b)
print(rdd2.collect())
# 结果:
# [('男', 192), ('女', 242)]
~~~
#### **Filter**
- 功能:过滤想要的数据进行保留
- 用法:
~~~
rdd.filter(func)
# func:(T) -> bool 传入一个随机类型的参数,返回值必须是 True 或 False
~~~
- 用法:
~~~
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7])
rdd2 = rdd.filter(lambda num: num % 2 == 0)
print(rdd2.collect())
# 结果:
# [2, 4, 6]
~~~
#### **Distinct**
- 功能:对RDD数据去重
- 代码:
~~~
rdd = sc.parallelize([1, 2, 3, 2, 3, 4, 4, 5, 6, 7])
rdd2 = rdd.distinct()
print(rdd2.collect())
# 结果:
# [1, 2, 3, 4, 5, 6, 7]
~~~

#### **sortBy**
- 功能:对RDD数据排序
- 用法:
~~~
rdd.sortBy(func, ascending = False, numPartitions = 1)
# func: (T) -> U:告知安装RDD的哪个数据进行排序,例如:lambda x: x[1] 表示按照rdd的第二个元素进行排序
# ascending:True 升序、False 降序。默认 True
# numPartitions:用多少分区排序
~~~
- 代码:
~~~
rdd = sc.parallelize([2, 5, 5, 54, 25, 85, 32])
rdd2 = rdd.sortBy(lambda x: x)
print(rdd2.collect())
# 结果:
# [2, 5, 5, 25, 32, 54, 85]
~~~
### **数据输出类**
#### **Collect**
- 功能:将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象
- 用法:
~~~
rdd.collect()
~~~
#### **Reduce**
- 功能:对RDD数据集按照传入的逻辑进行聚合
- 代码:
~~~
rdd = sc.parallelize([2, 5, 5, 54, 25, 85, 32])
rdd2 = rdd.reduce(lambda a, b: a + b)
print(rdd2)
# 结果
# 208
~~~
#### **Take**
- 功能:去RDD数据集中的前N个元素,组合成List返回
- 代码:
~~~
rdd = sc.parallelize([2, 5, 5, 54, 25, 85, 32])
rdd2 = rdd.take(3)
print(rdd2)
# 结果
# [2, 5, 5]
~~~
#### **Count**
- 功能:统计RDD共有多少条数据,返回值一个数字
- 代码:
~~~
rdd = sc.parallelize([2, 5, 5, 54, 25, 85, 32])
rdd2 = rdd.count()
print(rdd2)
# 结果
# 7
~~~
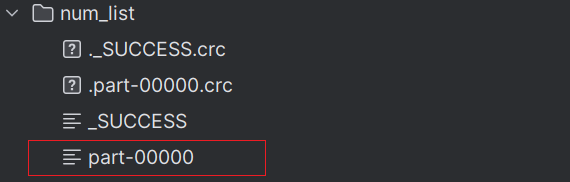
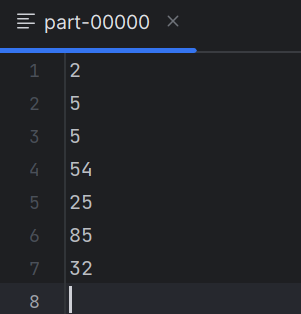
#### **saveAsTextFile**
- 功能:将RDD数据写入**文本文件**中
- 代码:
~~~
rdd = sc.parallelize([2, 5, 5, 54, 25, 85, 32], numSlices=1) # 设置使用的分区为1()
rdd.saveAsTextFile("num_list")
~~~
结果:
> **注意**:
> 调用保存文件的算子,需要配置**Hadoop**依赖
> - 下载Hadoop安装包
> http://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
> - 解压到电脑任意位置
> - 在Python代码中使用os模块配置:os.environ[‘HADOOP_HOME’] = ‘HADOOP解压文件夹路径’
> - 下载winutils.exe,并放入Hadoop解压文件夹的bin目录内
> https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/winutils.exe
> - 下载hadoop.dll,并放入:C:/Windows/System32 文件夹内
> https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/hadoop.dll
- PHP
- PHP 核心架构
- PHP 生命周期
- PHP-FPM 详解
- PHP-FPM 配置优化
- PHP 命名空间和自动加载
- PHP 运行模式
- PHP 的 Buffer(缓冲区)
- php.ini 配置文件参数优化
- 常见面试题
- 常用函数
- 几种排序算法
- PHP - 框架
- Laravel
- Laravel 生命周期
- ThinkPHP
- MySQL
- 常见问题
- MySQL 索引
- 事务
- 锁机制
- Explain 使用分析
- MySQL 高性能优化规范
- UNION 与 UNION ALL
- MySQL报错:sql_mode=only_full_group_by
- MySQL 默认的 sql_mode 详解
- 正则表达式
- Redis
- Redis 知识
- 持久化
- 主从复制、哨兵、集群
- Redis 缓存击穿、穿透、雪崩
- Redis 分布式锁
- RedisBloom
- 网络
- 计算机网络模型
- TCP
- UDP
- HTTP
- HTTPS
- WebSocket
- 常见几种网络攻击方式
- Nginx
- 状态码
- 配置文件
- Nginx 代理+负载均衡
- Nginx 缓存
- Nginx 优化
- Nginx 配置 SSL 证书
- Linux
- 常用命令
- Vim 常用操作命令
- Supervisor 进程管理
- CentOS与Ubuntu系统区别
- Java
- 消息队列
- 运维
- RAID 磁盘阵列
- 逻辑分区管理 LVM
- 业务
- 标准通信接口设计
- 业务逻辑开发套路的三板斧
- 微信小程序登录流程
- 7种Web实时消息推送方案
- 用户签到
- 用户注册-短信验证码
- SQLServer 删除同一天用户重复签到
- 软件研发完整流程
- 前端
- Redux
- 其他
- 百度云盘大文件下载
- 日常报错记录
- GIT
- SSL certificate problem: unable to get local issuer certificate
- NPM
- reason: connect ECONNREFUSED 127.0.0.1:31181
- SVN
- SVN客户端无法连接SVN服务器,主机积极拒绝
- Python
- 基础
- pyecharts图表
- 对象
- 数据库
- PySpark
- 多线程
- 正则
- Hadoop
- 概述
- HDFS