
## 智能合约的存储
将智能合约数据按照编码规则映射成 MPT,然后将 MPT 的所有节点的 Key 和 Value 构建一个 RLP List 编码作为数据库存储的 Value 值,将该 Value 值进行 Sha3 计算 hash 值作为数据库存储的 Key 值进行存储。
## 智能合约存储布局
以太坊合约是经过 EVM 执行后,将从 KV 数据库中读写。这和常见的编程语言的内存数据模型差异很大。 这是因为合约在创建或执行后必须方便存储到KV 数据库,也需要能拥有引用指针访问数据能力。 在主流编程语言中,数据的访问都可以通过指针访问,在以太坊中,访问数据是需要从 KV 数据中实时读取,因此在访问前必须知道某个数据确切的存储位置。 如何读写数据是由合约编译器决定,和 EVM 无关。这里我们讨论以太坊**Solidity**智能合约编程语言所设计的数据存储模型。
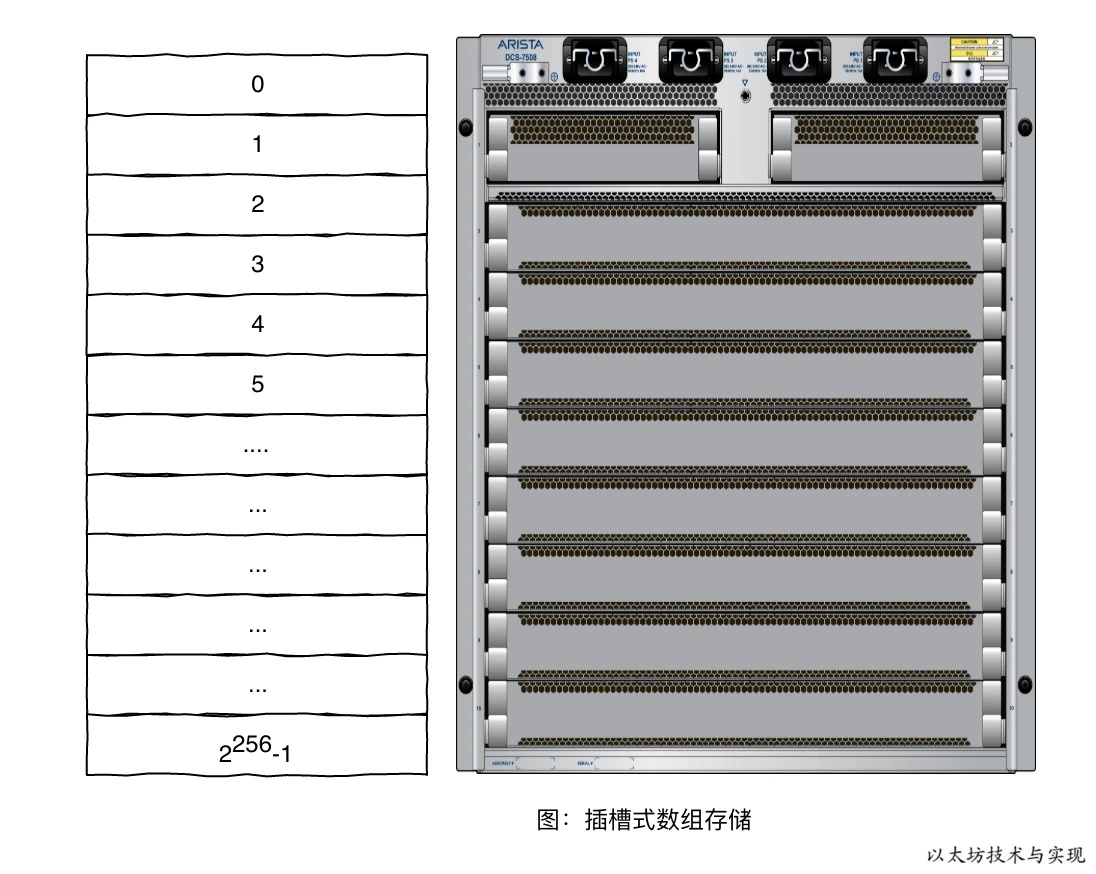
Solidity 合约数据存储采用的是为合约每项数据指定一个可计算的存储位置,数据存在容量为2256超级数组中,数组中每项数据的初始值为 0。 你不用担心存储会占用太多空间,实际上存储是稀疏的。在存储到 KV 数据库中时只有非零(空值)数据才会被写入。
每个插槽可存储 32 字节(256位)数据:
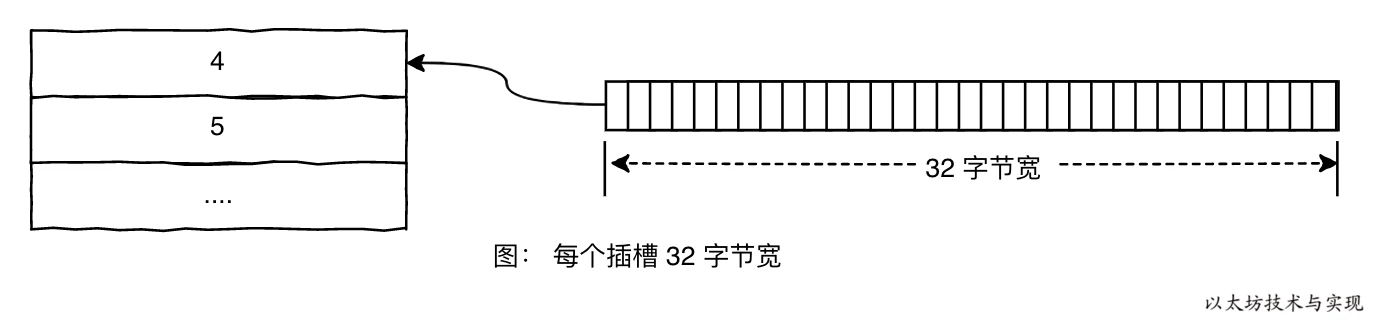
当某项数据超过 32 字节,则需要占用多个连续插槽(data.length/32)。 因此,当数据长度是已知时,则存储位置将在编译时指定存储位置,而对于长度不确定的类型(如 动态数组、字典)则按一定规则计算存储位置。
2256是一个超级大的数字,足够容量合约需要任意大小的存储。
```
2256是一个超级大的数字,等于232* 8,而 232约等于40 亿。 如果你无法直观理解的的话,可以做一个比较:地球上的沙子总数量大约为“7.5 * 1015”, 而2256等于1.158*1077,相当于五倍多的全地区沙子总量。
```
## 定长数据结构的存储
在 Solidity 语言中,一部分的值类型所需要占用的存储是确定的。 比如布尔类型,只需要占用一字节,uint16 只需要占用 2 字节。 Solidity 编译器在编译合约时,将严格的根据定义顺序,依次给他们设定存储位置。
~~~solidity
pragma solidity >0.5.0;
contract StorageExample {
uint8 public a = 11;
uint256 b=12;
uint[2] c= [13,14];
struct Entry {
uint id;
uint value;
}
Entry d;
}
~~~
上面合约中,有定义 a、b、c、d 四个存储字段。a、b 分配在 0,1位置。 而字段 c 是定长 2 且元素类型是 uint,需要用 32 字节存储一个元素,一共需要占用两个插槽 2和 3。 字段 d 是一个结构类型数据,其中 Entry 的数据长度也是确定的 64 字节,因此字段 d 也占用两个插槽 4 和 5。
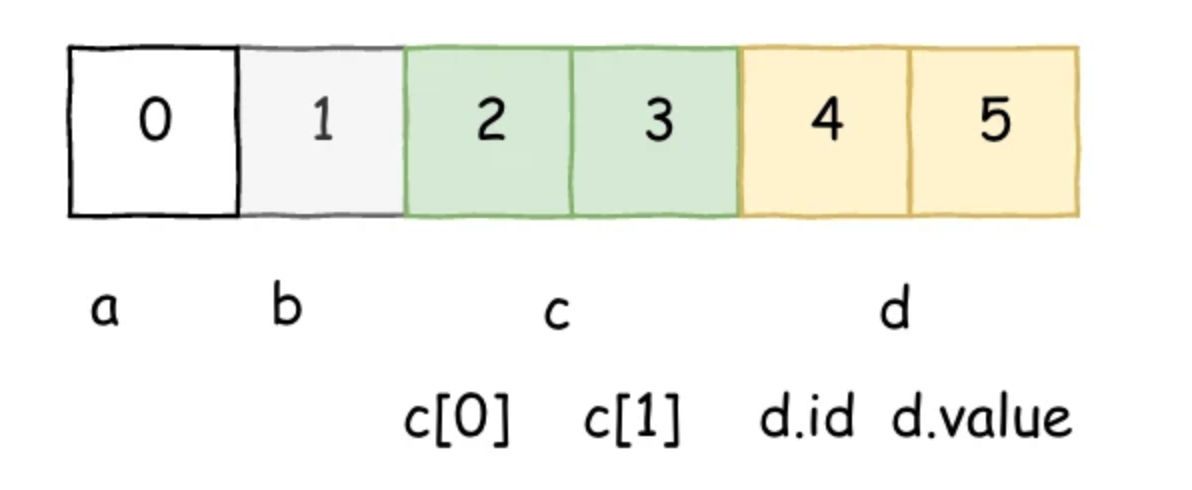
当数据类型是值类型(固定大小的值)时,编译时将严格根据字段排序顺序,给每个要存储的值类型数据预分配存储位置。 相当于已提前指定了固定不变的数据指针。
部署上面合约,根据合约地址可以直接通过`eth_getStorageAt(contractAddress,slot)`API 获取存储数据。
~~~js
var contractAddr="0xe700184a875390d7c98371769315E9A2504Ad556"; # 我部署上方合约的合约地址。
for(i=0;i<6;i++){
console.log(web3.eth.getStorageAt(contractAddr,i))
}
// 输出
0x000000000000000000000000000000000000000000000000000000000000000b
0x000000000000000000000000000000000000000000000000000000000000000c
0x000000000000000000000000000000000000000000000000000000000000000d
0x000000000000000000000000000000000000000000000000000000000000000e
0x0000000000000000000000000000000000000000000000000000000000000000
0x0000000000000000000000000000000000000000000000000000000000000000
~~~
上面是根据存储位置遍历合约的所有存储, 存储到 DB 的数据是十六进制,我们可以直接使用工具类函数转换数据。
~~~
web3.toBigNumber(web3.eth.getStorageAt(contractAddr,0))
// 输出: 11
~~~
```
注意:本文脚本运行在 geth 控制台中,和 NodeJs 运行有所差异。geth 控制台中有修改 web3 方法定义。
```
## 动态大小数据结构存储
当数据大小是不可预知时,无法在编译期直接确定其存储位置。因此 Solidity 在编译动态数字、字典数据时采用的是特定算法。
### 字符串存储
字符串 string 和 bytes 实际是一个特殊的 array ,编译器对这类数据有进行优化。如果`string`和`bytes`的数据很短。那么它们的长度也会和数据一起存储到同一个插槽。 具体为:
1. 如果数据长度小于等于 31 字节, 则它存储在高位字节(左对齐),最低位字节存储 length * 2。
2. 如果数据长度超出 31 字节,则在主插槽存储 length * 2 + 1, 数据照常存储在 keccak256(slot) 中。
~~~solidity
contract StorageExample3 {
string a = "我比较短";
string b = "我特别特别长,已经超过了一个插槽存储量";
}
~~~
合约有两个字段 a 和 b,他们所需要占用的存储各不相同。根据规则一,a 的内容和长度一起存储在插槽 0 中。
```
data=web3.eth.getStorageAt('0x24aA059A03bC2f1EdC8412f673b6Bd3319A2c5CB',0) //输出:`0xe68891e6af94e8be83e79fad0000000000000000000000000000000000000018`
```
a 占用存储 12 (0x18/2) 字节,根据长度可解码 a 的值:
~~~js
web3.toUtf8( data.substr(2,12*2))
~~~
而字段 b 需要占用57 字节 (=web3.fromUtf8(‘我特别特别长,已经超过了一个插槽存储量’).length/2 -1),已超过 31 字节。 那么将在插槽 1 中存储值 115(= 57 * 2 + 1): “0x0000000000000000000000000000000000000000000000000000000000000073”。 而 b 值起始存储在 keccak256(0x1) 中,需要使用连续两个插槽存储。
调用 SlotHelp 函数`dataSolot(1)`,得到 b 字符串的起始存储位置:start=0xb10e2d527612073b26eecdfd717e6a320cf44b4afac2b0732d9fcbe2b7fa0cf6。 而 b 字符串需要两个插槽存储,下一个存储位置是 start +1 。
~~~js
b1 = web3.eth.getStorageAt('0x0a4Efc37f85023Fae282DE0c885669DaEF02E02A',"0xb10e2d527612073b26eecdfd717e6a320cf44b4afac2b0732d9fcbe2b7fa0cf6")
//0xe68891e789b9e588abe789b9e588abe995bfefbc8ce5b7b2e7bb8fe8b685e8bf
b2 = web3.eth.getStorageAt('0x0a4Efc37f85023Fae282DE0c885669DaEF02E02A',"0xb10e2d527612073b26eecdfd717e6a320cf44b4afac2b0732d9fcbe2b7fa0cf7")
//0x87e4ba86e4b880e4b8aae68f92e6a7bde5ad98e582a8e9878f00000000000000
str = web3.toUtf8(b1+b2.substr(2))
~~~
```
keccak256 是 Solidity 中合约中使用的 sha3 函数,不等同于 web3.sha 。 为了计算方便,我定义了一个 Solot 的帮助类来计算存储位置,见文档底部。
```
### 动态数组
动态数组`T[]`由两部分组成,数组长度和元素值。在 Solidity 中定义动态数组后,将在定义的插槽位置存储数组元素数量, 元素数据存储的起始位置是:keccak256(slot),每个元素需要根据下标和元素大小来读取数据。
~~~solidity
contract StorageExample4 {
uint16[] public a = [401,402,403,405,406];
uint256[] public b = [401,402,403,405,406];
}
~~~
上面有定义两个数组 a 和 b,都有 5 个相同初始值。 a 和 b 在插槽 0 和 1 上分别存储他们的长度值 5,而数组元素值存储有所不同(紧缩存储)。 因为数组 a 元素宽度(width)是 2 字节,因此一个插槽可以存储 16 个元素,而数组 b 则只能是一个插槽存储一个元素(uint256 需要用 32 字节存储)。
上面有定义两个数组 a 和 b,都有 5 个相同初始值。 a 和 b 在插槽 0 和 1 上分别存储他们的长度值 5,而数组元素值存储有所不同(紧缩存储)。 因为数组 a 元素宽度(width)是 2 字节,因此一个插槽可以存储 16 个元素,而数组 b 则只能是一个插槽存储一个元素(uint256 需要用 32 字节存储)。
已知:
* keccak256(0)=0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563
* keccak256(1)=0xb10e2d527612073b26eecdfd717e6a320cf44b4afac2b0732d9fcbe2b7fa0cf6
如果要获取 a[3] 值,首先确认 a[3]的存储位置:
`keccak256(0)+ index* width / 32`= 0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563
可得到插槽中存储的数据:
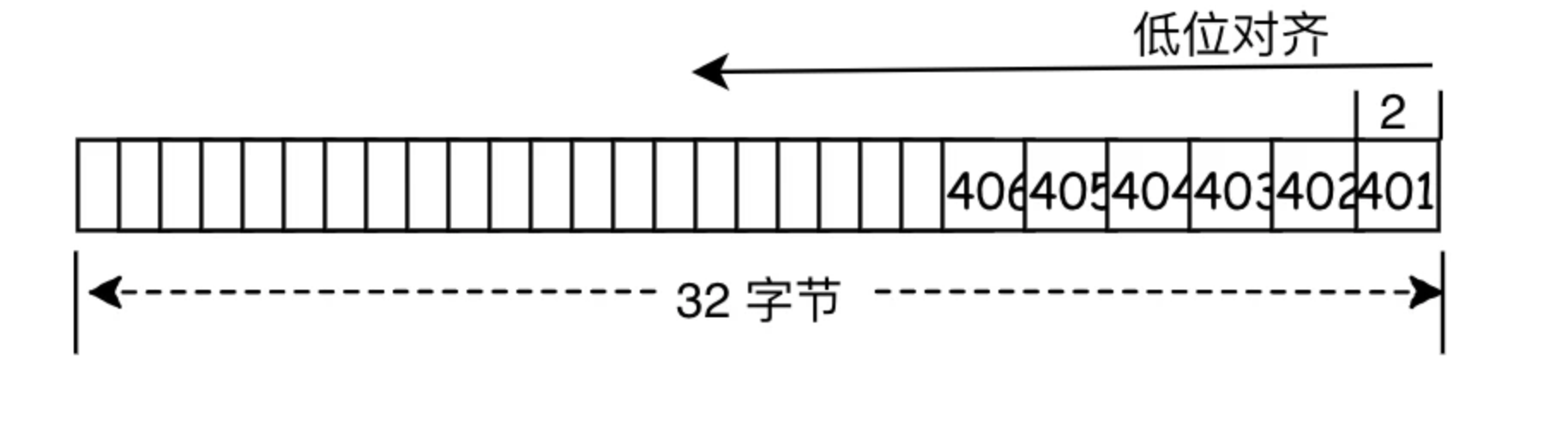
data=0x0000000000000000000000000000000000000000000001960195019301920191
根据第一项以低位对齐(右对齐)的存储方式,可以知道 a[3] 需要向左偏移`index*width`= 6 个字节,值为`data.substr(32*2+2-3*2*2,2*2)`
### 字典存储
字典的存储布局是直接存储 Key 对应的 value,每个 Key 对应一份存储。一个 Key 的对应存储位置是`keccak256(key.slot)`,其中`.`是拼接符合,实际上编码时进行拼接`abi.encodePacked(key,slot)`; 可直接获得 map[key] 的存储位置。
~~~solidity
contract StorageExample5 {
mappping(uint256 => string) a;
constructor()public {
a["u1"]=18;
a["u2"]=19;
}
}
~~~
如上面示例中,字段 a 定义在 0 插槽,初始化合约时有添加两个key u1 和 u2。那么 u1的存储位置就是:`keccak256("u1",0)`,u2 存储在`keccak256("u2",0)`中。调用`SlotHelp.mappingValueSlotString(0,"u1")`可计算出存储位置,分别是:
1. keccak256(“u1”,0) = 0x666a0898319983ee51fdb14dca8cb63a131f53ef02192cda872152628bb15fd7
2. keccak256(“u2”,0) = 0xb8f3bac818d08a6d5c3fc2cecdc63de9db8e456c49b3877ea67282ec9d7ef62c
取值为:
~~~js
addr="0xB793D15FF1e9F652D66a58E7C963c4c6766DA193" #部署后的合约地址
web3.eth.getStorageAt(addr,'0x666a0898319983ee51fdb14dca8cb63a131f53ef02192cda872152628bb15fd7')
// Result
// "0x0000000000000000000000000000000000000000000000000000000000000012"
web3.eth.getStorageAt(addr,'0xb8f3bac818d08a6d5c3fc2cecdc63de9db8e456c49b3877ea67282ec9d7ef62c')
// Result
// "0x0000000000000000000000000000000000000000000000000000000000000013"
~~~
### 组合型数据
当前数据类型不是基础类型时,是进行内部递归处理,遵守上述规则来存储数据的。
### slot遵循紧凑存储原则
区块链存储很昂贵,遵循紧凑存储原则:
一大部分值类型实际上不需要用到 32 字节,如布尔型、uint1 到 uint256。 为了节约存储量,编译器在发现所用存储不超过 32 字节时,将会将其和后面字段尽可能的存储在一个存储中。
~~~solidity
pragma solidity >0.5.0;
contract StorageExample2 {
uint256 a = 11; // 插槽 0
uint8 b = 12; // 插槽1,1 字节
uint128 c = 13; // 插槽1,16 字节
bool d = true; // 插槽1,1 字节
uint128 e = 14;//插槽2
}
~~~
上面合约总共使用 3 个插槽存储数据。
* 字段 a 需要 32 字节占用 1 个插槽,存于插槽 0 中。
* b 只需要 1 字节,存于插槽 1 中。
* 因为 插槽 1 还剩余 31 字节可用,而 c 只需要 16 字节,因此 c 也可以存储在插槽 1 中。
* 此时,插槽 1 剩余 15 字节,可以继续存放 d 的一字节。
* 插槽 1 还剩余 14 字节,但是 e 需要 16 字节存储,插槽 1 已不能容纳 e。需将 e 存放到下一个插槽 2 中。
[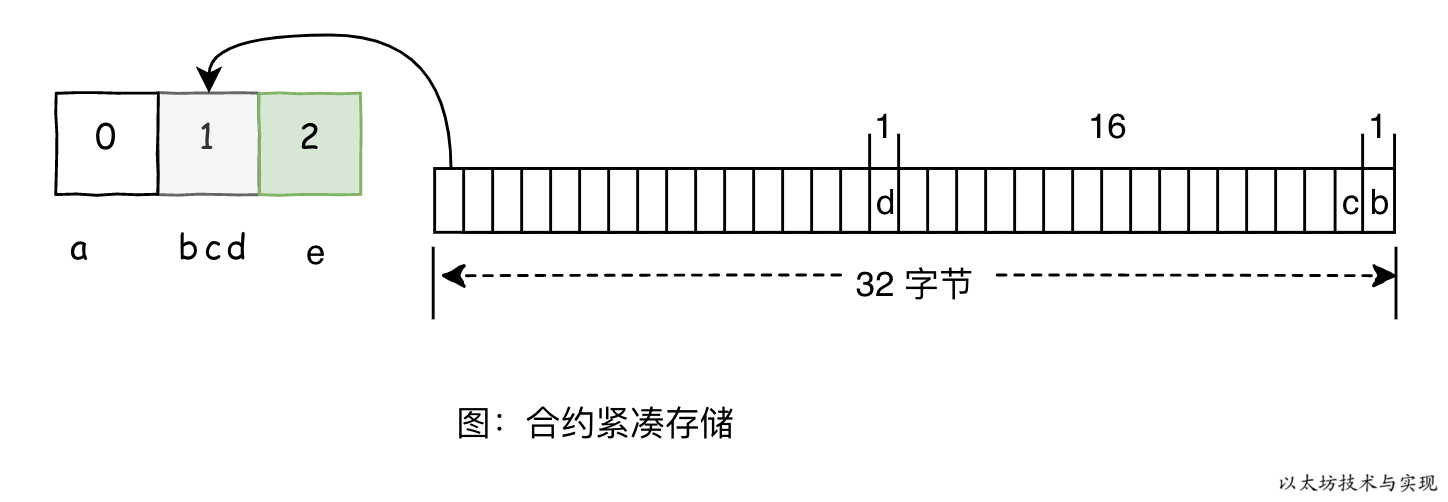](https://img.learnblockchain.cn/book_geth/2019-11-6-21-56-39.png!de?width=600px)
上图是合约的存储布局,被紧凑地存放在插槽 1 中的 b、c、d 他们将依次从右往左存储于插槽 1 中。读取插槽 1 中的数据得到 data 为:
0x0000000000000000000000000000010000000000000000000000000000000d0c
如果希望得到b、c、d 的值,则需要进行分割读取。data 是一串 Hex 字符串,两个字符代表一个字节。
~~~js
data = web3.eth.getStorageAt(contractAddr,1);
b = parseInt(data.substr(66-1*2,1*2),16);
c = parseInt(data.substr(66-1*2-16*2,16*2),16);
d = parseInt(data.substr(66-1*2-16*2-1*2,1*2),16);
~~~
鉴于这种紧凑存储原则,有效降低了存储占用。而因以太坊存储是昂贵的,因此为了降低存储占用, 你在编写合约时,记得注意字段的**定义顺序**。
比如在合约中的结构类型字段,依次是 uint256、uint8和 uint8,占用两个插槽。如果你定义成: age、id、sex 顺序,则将占用 3 个插槽。
~~~solidity
contract StorageExample3 {
struct User {
uint256 id;
uint8 age;
uint8 sex
}
}
~~~
但这种机制也引发了**另一个问题**。因为以太坊虚拟机每次读取数据都是 32 字节,当你的数据小于 32 字节时需要更多的指令操作才能将所需值取出。 如上面实例中,当你取 c 值时,首先要读取插槽 1 的 32 字节数据外,还需要截取 32 字节的中间一小部分。 在使得相比取 32 字节值的数据,需要花费更多的 gas 来获取小于 32 字节的数据。 当然这种开销,相对于更多的存储占用要便宜得多。
### SlotHelp
~~~solidity
pragma solidity >0.5.0;
contract SlotHelp {
// 获取字符串的存储起始位置
function dataSolot(uint256 slot) public pure returns (bytes32) {
bytes memory slotEncoded = abi.encodePacked(slot);
return keccak256(slotEncoded);
}
// 获取字符串 Key 的字典值存储位置
function mappingValueSlotString(uint256 slot,string memory key ) public pure returns (bytes32) {
bytes memory slotEncoded = abi.encodePacked(key,slot);
return keccak256(slotEncoded);
}
}
~~~
- 重要更新说明
- linechain发布
- linechain新版设计
- 引言一
- 引言二
- 引言三
- vs-code设置及开发环境设置
- BoltDB数据库应用
- 关于Go语言、VS-code的一些Tips
- 区块链的架构
- 网络通信与区块链
- 单元测试
- 比特币脚本语言
- 关于区块链的一些概念
- 区块链组件
- 区块链第一版:基本原型
- 区块链第二版:增加工作量证明
- 区块链第三版:持久化
- 区块链第四版:交易
- 区块链第五版:实现钱包
- 区块链第六版:实现UTXO集
- 区块链第七版:网络
- 阶段小结
- 区块链第八版:P2P
- P2P网络架构
- 区块链网络层
- P2P区块链最简体验
- libp2p建立P2P网络的关键概念
- 区块链结构层设计与实现
- 用户交互层设计与实现
- 网络层设计与实现
- 建立节点发现机制
- 向区块链网络请求区块信息
- 向区块链网络发布消息
- 运行区块链
- LineChain
- 系统运行流程
- Multihash
- 区块链网络的节点发现机制深入探讨
- DHT
- Bootstrap
- 连接到所有引导节点
- Advertise
- 搜索其它peers
- 连接到搜到的其它peers
- 区块链网络的消息订发布-订阅机制深入探讨
- LineChain:适用于智能合约编程的脚本语言支持
- LineChain:解决分叉问题
- LineChain:多重签名
- libp2p升级到v0.22版本
- 以太坊基础
- 重温以太坊的树结构
- 世界状态树
- (智能合约)账户存储树
- 交易树
- 交易收据树
- 小结
- 以太坊的存储结构
- 以太坊状态数据库
- MPT
- 以太坊POW共识算法
- 智能合约存储
- Polygon Edge
- block结构
- transaction数据结构
- 数据结构小结
- 关于本区块链的一些说明
- UML工具-PlantUML
- libp2p介绍
- JSON-RPC
- docker制作:启动多个应用系统
- Dockerfile
- docker-entrypoint.sh
- supervisord.conf
- docker run
- nginx.conf
- docker基础操作整理
- jupyter计算交互环境
- git技巧一
- git技巧二
- 使用github项目的最佳实践
- windows下package管理工具