
## 以太坊默克尔压缩前缀树
在以太坊中,一种经过改良的默克尔树非常关键,是以太坊数据安全与效率的保障,此树在以太坊中称之为 MPT(默克尔压缩前缀树)。 MPT 全称是 Merkle Patricia Trie 也叫 Merkle Patricia Tree,是 Merkle Tree 和 Patricia Tree 的混合物。 Merkle Tree(默克尔树) 用于保证数据安全,Patricia Tree(基数树,也叫基数特里树或压缩前缀树) 用于提升树的读写效率。
### 简述
以太坊不同于比特币的 UXTO 模型,在账户存在多个属性(余额、代码、存储信息),属性(状态)需要经常更新。因此需要一种数据结构来满足几点要求:
* ①在执行插入、修改或者删除操作后能快速计算新的树根,而无需重新计算整个树。
* ②即使攻击者故意构造非常深的树,它的深度也是有限的。否则,攻击者可以通过特意构建足够深的树使得每次树更新变得极慢,从而执行拒绝服务攻击。
* ③树的根值仅取决于数据,而不取决于更新的顺序。以不同的顺序更新,甚至是从头重新计算树都不会改变树的根值。
要求①是默克尔树特性,但要求②③则非默克尔树的优势。 对于要求②,可将数据 Key 进行一次哈希计算,得到确定长度的哈希值参与树的构建。而要求③则是引入位置确定的压缩前缀树并加以改进。
### 压缩前缀树 Patricia Tree
在[压缩前缀树(基数树)中,键值是通过树到达相应值的实际路径值。 也就是说,从树的根节点开始,键中的每个字符会告诉您要遵循哪个子节点以获取相应的值,其中值存储在叶节点中,叶节点终止了穿过树的每个路径。假设键是包含 N 个字符的字母,则树中的每个节点最多可以有 N 个子级,并且树的最大深度是键的最大长度。
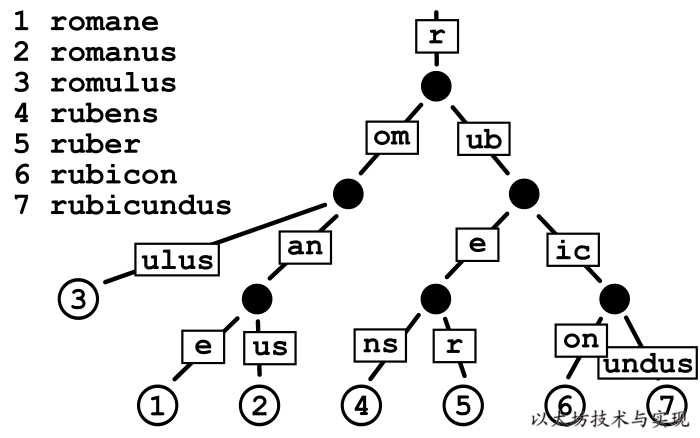
虽然基数树使得以相同字符序列开头的键的值在树中靠得更近,但是它们可能效率很低。 例如,当你有一个超长键且没有其他键与之共享前缀时,即使路径上没有其他值,但你必须在树中移动(并存储)大量节点才能获得该值。 这种低效在以太坊中会更加明显,因为参与树构建的 Key 是一个哈希值有 64 长(32 字节),则树的最长深度是 64。树中每个节点必须存储 32 字节,一个 Key 就需要至少 2KB 来存储,其中包含大量空白内容。 因此,在经常需要更新的以太坊状态树中,优化改进基数树,以提高效率、降低树的深度和减少 IO 次数,是必要的。
### 以太坊压缩前缀树(MPT)
为了解决基数树的效率问题,以太坊对基数树的最大改动是丰富了节点类型,围绕不同节点类型的不同操作来解决效率。
1. 空白节点 NULL
2. 分支节点 branch Node [0,1,…,16,value]
3. 叶子节点 leaf Node : [key,value]
4. 扩展节点 extension Node: [key,value]
多种节点类型的不同操作方式,虽然提升了效率,但复杂度被加大。而在 geth 中,为了适应实现,节点类型的设计稍有不同:
~~~go
//trie/node.go:35
type (
fullNode struct { //分支节点
Children [17]node
flags nodeFlag
}
shortNode struct { //短节点:叶子节点、扩展节点
Key []byte
Val node
flags nodeFlag
}
hashNode []byte //哈希节点
valueNode []byte //数据节点,但他的值就是实际的数据值
)
var nilValueNode = valueNode(nil) //空白节点
~~~
* fullNode: 分支节点,fullNode\[16\]的类型是 valueNode。前 16 个元素对应键中可能存在的一个十六进制字符。如果键\[key,value\]在对应的分支处结束,则在列表末尾存储 value 。
* shortNode: 叶子节点或者扩展节点,当 shortNode.Key的末尾字节是终止符`16`时表示为叶子节点。当 shortNode 是叶子节点是,Val 是 valueNode。
* hashNode: 应该取名为 collapsedNode 折叠节点更合适些,但因为其值是一个哈希值当做指针使用,所以取名 hashNode。使用这个哈希值可以从数据库读取节点数据展开节点。
* valueNode: 数据节点,实际的业务数据值,严格来说他不属于树中的节点,它只存在于 fullNode.Children 或者 shortNode.Val 中。
### 各类key
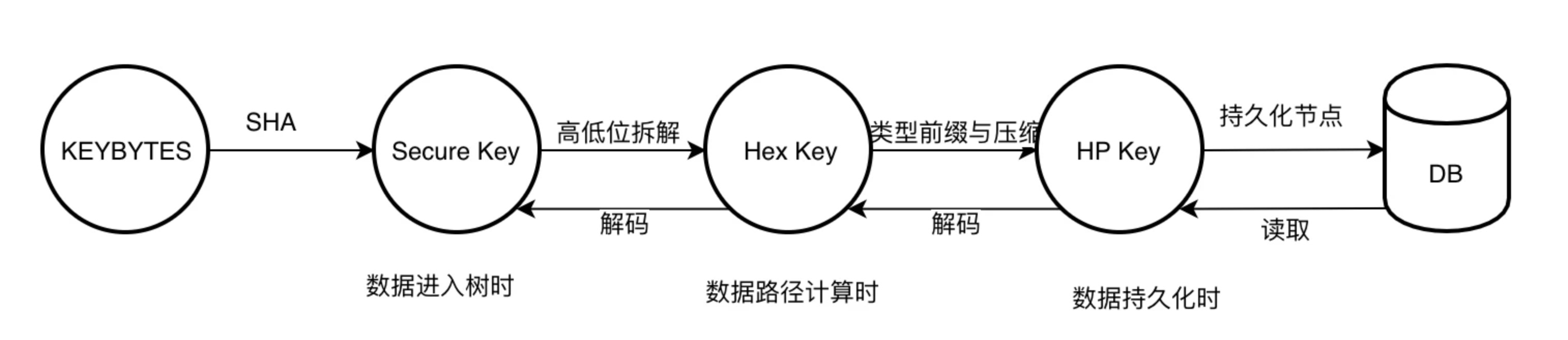
在改进过程中,为适应不同场景应用,以太坊定义了几种不同类型的 key 。
1. keybytes :数据的原始 key
2. Secure Key: 是 Keccak256(keybytes) 结果,用于规避 key 深度攻击,长度固定为 32 字节。
3. Hex Key: 将 Key 进行半字节拆解后的 key ,用于 MPT 的树路径中和降低子节点水平宽度。
4. HP Key: Hex 前缀编码(hex prefix encoding),在节点存持久化时,将对节点 key 进行压缩编码,并加入节点类型标签,以便从存储读取节点数据后可分辨节点类型。
下图是 key 有特定的使用场景,基本支持逆向编码,在下面的讲解中 Key 在不同语义下特指的类型有所不同。
### 分支节点
分支节点是以太坊引入,将其子节点直接包含在自身的数据插槽中,这样可缩减树深度和减少IO次数,特别是当插槽中均有子节点存在时,改进效果越明显。
分支节点没有key,可能value也为空。分支节点存储多个子节点的hash。
数据 Key 在进入 MPT 前已转换 Secure Key。 因此,key 长度为 32 字节,每个字节的值范围是[0 - 255]。 如果在分支节点中使用 256 个插槽,空间开销非常高,造成浪费,毕竟空插槽在持久化时也需要占用空间。同时超大容量的插槽,也会可能使得持久化数据过大,可能会造成读取持久化数据时占用过多内存。 如果将 Key 进行Hex 编码,每个字节值范围被缩小到 [0-15] 内(4bits)。这样,分支节点只需要 16 个插槽来存放子节点:

1. MPT 是一颗逻辑树,并不一一对应物理树(存储)。
2. 在 MPT 中必将在叶子节点处存放在 Key 对应的数据节点(ValueNode),数据节点必然是在树的子叶节点中。
3. 在 MPT 中,到达节点的树路径 Path 和节点中记录的 Key 一起构成了节点的完整 Key。
4. 分支节点的插槽 Index 就是树路径的一部分。
### 计算树的Root
们以 romane、romanus、romulus 为示例数据,来讲解是何如计算出 MPT 树的一个树根 Root 值的。
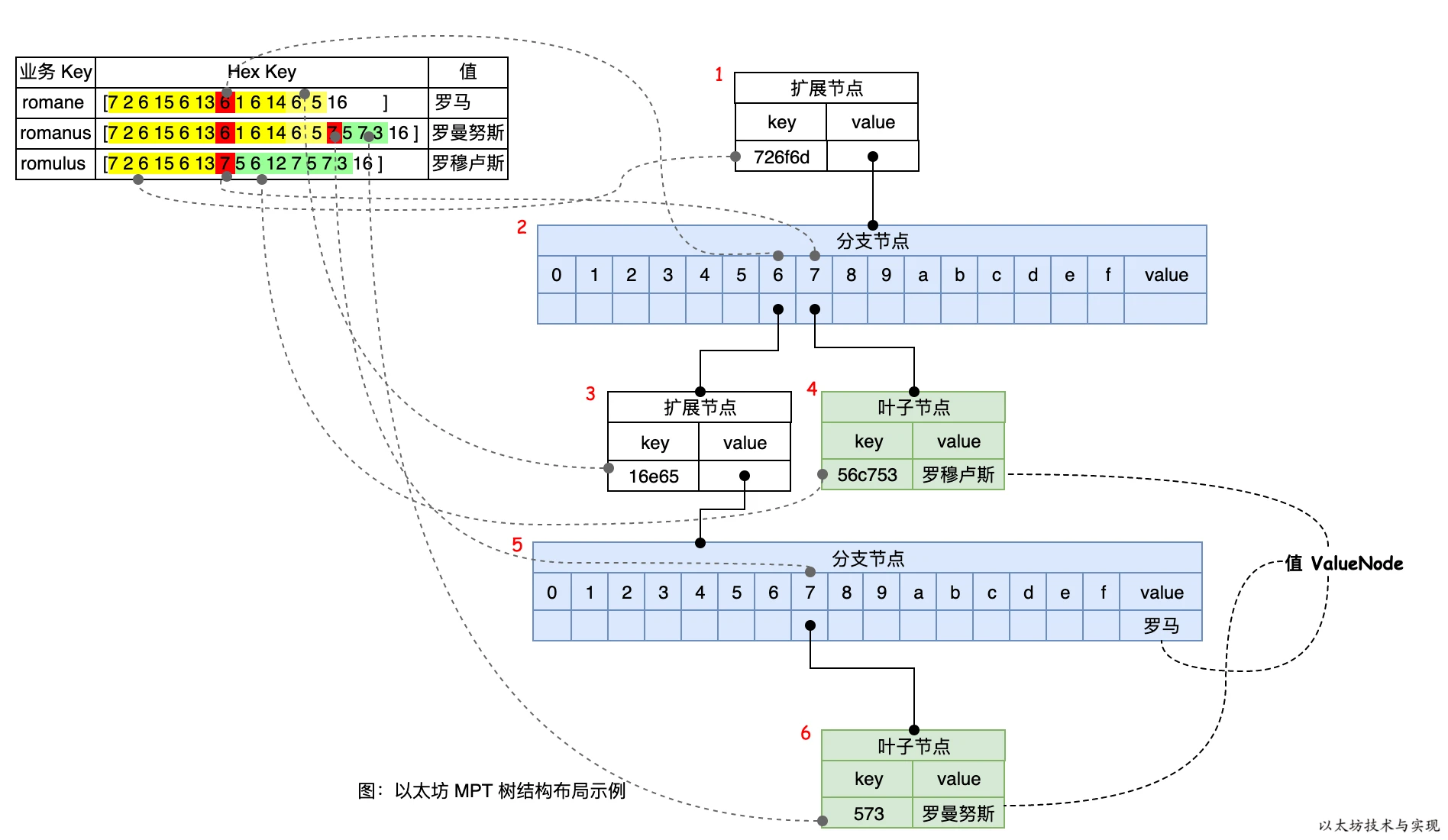
上图是三项数据的业务 Key 经过 HP 编码后,写入 MPT 树后所形成的 MPT 树结构布局。HP表和树的虚线连接表示树路径的生成依据,这是根据前面所描述的 MPT 生成规则而形成的树结构。在树中,一共有6 个节点,其中节点 1 和 3 为扩展节点,节点 2 和 5 为分支节点,节点 4 和 6 为叶子节点。可以看到在分支节点 5 中的 value 位置存放着业务 key “romane” 所对应的值“罗马”,但业务 key “romanus”和“romulus” 则存放在独立的叶子节点中。
当我们执行 trie.Commit 时将获得一个 Hash 值,称之为 树的 Root 值,这个 Root 值是如何得到的呢? Root 值算法源自默克尔树(Merkle Tree),在默克尔树中,树根值是由从子叶开始不断进行哈希计算得到最终能代表这棵树数据的哈希值。
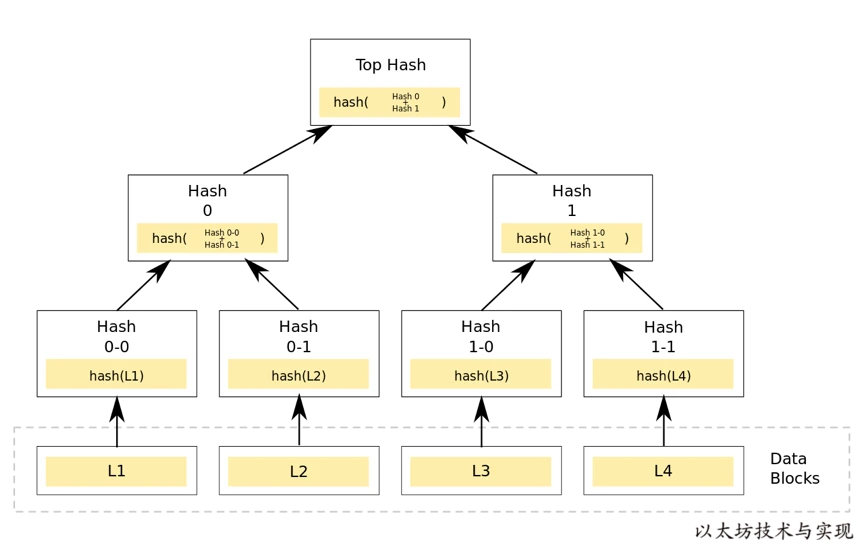
同样在计算 MPT 树的 Root 值是也是如此,在 MPT 中一个节点的哈希值,是节点内容经 RLP 编码后的 Keccak256 哈希值。当对一个节点进行哈希计算遵循如下规则:
1. Hash(扩展节点)= Hash( HP(node.Key),Hash(node.Value) ), 节点 key 需 HP 编码后参与哈希计算。当 node.Value 是表示业务数据时(valueNode),将为 Hash( HP(node.Key),node.Value)。
2. Hash(叶子节点) 无,叶子节点只存在于分支节点中。
3. Hash(分支节点)= Hash( hash(node.Children[1\),…,hash(node.Children[i]),node.Value),需要先将每个子节点存储中的节点进行哈希。如果子节点为 null,则使用空字节表示。
根据上面的规则,我们可以得到上面 MPT 树进行哈希计算时的节点分布:
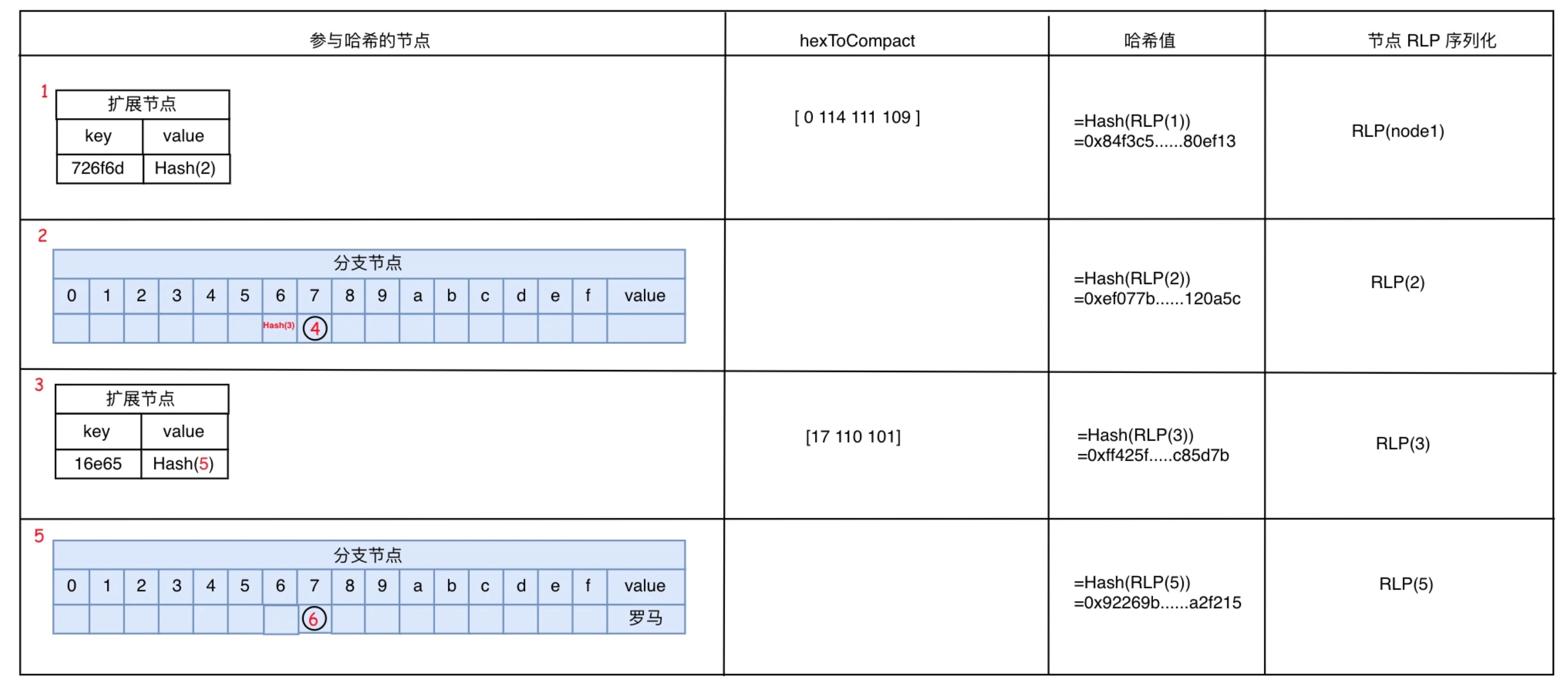
图中,可哈希的节点只有 4 个,而叶子节点 4 和 6 则直接属于分支节点的一部分参与哈希计算。MPT 的 Root 值是 MPT 树根节点的哈希值。在本示例中,Root 节点为 节点 1,Hash(节点 1)=`0x84f3c5......80ef13`即为 MPT 的 Root 值。扩展节点 1 和 3 的 key 在哈希计算时有进行 HP 编码。需要编码的原因是为了区分扩展节点的 value 是叶子节点还是分支节点的区别。
### 持久化
当需要将 MPT Commit 到 DB 时,这颗树的数据是如何完整存储到数据库的呢?以太坊的持久层是 KV 数据库,一个 Key 对应一份存储内容。 当上面在计算 Root 值时,实际上已完成了哈希值和节点内容的处理过程。不同于在内存中计算 Root 值,在持久化时是持久化和 Hash 计算同步进行。
从Root的计算规则可知,HASH 计算是递归的,从树的叶子节点向上计算。每次计算出一个节点哈希时,将使用此哈希值作为数据库的 Key,存放节点的 RLP 持久化内容到数据库中。 因为节点哈希值以及被包含在父节点中,直至树根。因此,我们只需要知道一颗树的 Root 值,便可以依次从 DB 中读取节点数据,并在内存中构建完整的 MPT 树。
### 编码规则
#### 1、Secure编码
这并非 MPT 树的必要部分,是为了解决路径深度攻击而将数据进入 MPT 前进行一次安全清洗,使用 Keccak256(key) 得到的key 的哈希值替换原数据 key。
在实现上,只需要在原 MPT 树进行依次封装即可获得一颗 Secure MPT 树。
#### 2、Hex编码
用于树路径中,是将数据 key 进行半字节拆解而成。即依次将 key\[0\],key\[1\],…,key\[n\] 分别进行半字节拆分成两个数,再依次存放在长度为 len(key)+1 的数组中。 并在数组末尾写入终止符`16`。算法如下:
> 半字节,在计算机中,通常将8位二进制数称为字节,而把4位二进制数称为半字节。 高四位和低四位,这里的“位”是针对二进制来说的。比如数字 250 的二进制数为 11111010,则高四位是左边的 1111,低四位是右边的 1010。
~~~go
// trie/encoding.go:65
func keybytesToHex(str []byte) []byte {
l := len(str)*2 + 1
var nibbles = make([]byte, l)
for i, b := range str {
nibbles[i*2] = b / 16
nibbles[i*2+1] = b % 16
}
nibbles[l-1] = 16
return nibbles
}
~~~
例如:字符串 “romane” 的 bytes 是`[114 111 109 97 110 101]`,在 HEX 编码时将其依次处理:
| i | key\[i\] | key\[i\]二进制 | nibbles\[i\*2\]=高四位 | nibbles\[i\*2+1\]=低四位 |
| --- | --- | --- | --- | --- |
| 0 | 114 | 011100102 | 01112\= 7 | 00102\= 2 |
| 1 | 111 | 011011112 | 01102\=6 | 11112\=15 |
| 2 | 109 | 011011012 | 01102\=6 | 11012\=13 |
| 3 | 97 | 011000012 | 01102\=6 | 00012\=1 |
| 4 | 110 | 011011102 | 01102\=6 | 11102\=14 |
| 5 | 101 | 011001012 | 01102\=6 | 01012\=5 |
最终得到 Hex(“romane”) =`[7 2 6 15 6 13 6 1 6 14 6 5 16]`
#### 3、HP(Hex-Prefix) 编码
Hex-Prefix 编码是一种任意量的半字节转换为数组的有效方式,还可以在存入一个标识符来区分不同节点类型。 因此 HP 编码是在由一个标识符前缀和半字节转换为数组的两部分组成。存入到数据库中存在节点 Key 的只有扩展节点和叶子节点,因此 HP 只用于区分扩展节点和叶子节点,不涉及无节点 key 的分支节点。

前缀标识符由两部分组成:节点类型和奇偶标识,并存储在编码后字节的第一个半字节中。 0 表示扩展节点类型,1 表示叶子节点,偶为 0,奇为 1。最终可以得到唯一标识的前缀标识:
* 0:偶长度的扩展节点
* 1:奇长度的扩展节点
* 2:偶长度的叶子节点
* 3:奇长度的叶子节点
当偶长度时,第一个字节的低四位用`0`填充,当是奇长度时,则将 key\[0\] 存放在第一个字节的低四位中,这样 HP 编码结果始终是偶长度。 这里为什么要区分节点 key 长度的奇偶呢?这是因为,半字节`1`和`01`在转换为 bytes 格式时都成为`<01>`,无法区分两者。
例如,上图 “以太坊 MPT 树的哈希计算”中的控制节点1的key 为`[ 7 2 6 f 6 d]`,因为是偶长度,则 HP[0]= (00000000)2\=0,H[1:]= 解码半字节(key)。 而节点 3 的 key 为`[1 6 e 6 5]`,为奇长度,则 HP[0]= (0001 0001)2\=17。
下面是 HP 编码算法的 Go 语言实现:
~~~go
// trie/encoding.go:37
func hexToCompact(hex []byte) []byte {
terminator := byte(0)
if hasTerm(hex) {
terminator = 1
hex = hex[:len(hex)-1]
}
buf := make([]byte, len(hex)/2+1)
buf[0] = terminator << 5 // the flag byte
if len(hex)&1 == 1 {
buf[0] |= 1 << 4 // odd flag
buf[0] |= hex[0] // first nibble is contained in the first byte
hex = hex[1:]
}
decodeNibbles(hex, buf[1:])
return buf
}
func decodeNibbles(nibbles []byte, bytes []byte) {
for bi, ni := 0, 0; ni < len(nibbles); bi, ni = bi+1, ni+2 {
bytes[bi] = nibbles[ni]<<4 | nibbles[ni+1]
}
}
~~~
在 Go 语言中因为叶子节点的末尾字节必然是 16(Hex 编码的终止符),依据此可以区分扩展节点还是叶子节点。
- 重要更新说明
- linechain发布
- linechain新版设计
- 引言一
- 引言二
- 引言三
- vs-code设置及开发环境设置
- BoltDB数据库应用
- 关于Go语言、VS-code的一些Tips
- 区块链的架构
- 网络通信与区块链
- 单元测试
- 比特币脚本语言
- 关于区块链的一些概念
- 区块链组件
- 区块链第一版:基本原型
- 区块链第二版:增加工作量证明
- 区块链第三版:持久化
- 区块链第四版:交易
- 区块链第五版:实现钱包
- 区块链第六版:实现UTXO集
- 区块链第七版:网络
- 阶段小结
- 区块链第八版:P2P
- P2P网络架构
- 区块链网络层
- P2P区块链最简体验
- libp2p建立P2P网络的关键概念
- 区块链结构层设计与实现
- 用户交互层设计与实现
- 网络层设计与实现
- 建立节点发现机制
- 向区块链网络请求区块信息
- 向区块链网络发布消息
- 运行区块链
- LineChain
- 系统运行流程
- Multihash
- 区块链网络的节点发现机制深入探讨
- DHT
- Bootstrap
- 连接到所有引导节点
- Advertise
- 搜索其它peers
- 连接到搜到的其它peers
- 区块链网络的消息订发布-订阅机制深入探讨
- LineChain:适用于智能合约编程的脚本语言支持
- LineChain:解决分叉问题
- LineChain:多重签名
- libp2p升级到v0.22版本
- 以太坊基础
- 重温以太坊的树结构
- 世界状态树
- (智能合约)账户存储树
- 交易树
- 交易收据树
- 小结
- 以太坊的存储结构
- 以太坊状态数据库
- MPT
- 以太坊POW共识算法
- 智能合约存储
- Polygon Edge
- block结构
- transaction数据结构
- 数据结构小结
- 关于本区块链的一些说明
- UML工具-PlantUML
- libp2p介绍
- JSON-RPC
- docker制作:启动多个应用系统
- Dockerfile
- docker-entrypoint.sh
- supervisord.conf
- docker run
- nginx.conf
- docker基础操作整理
- jupyter计算交互环境
- git技巧一
- git技巧二
- 使用github项目的最佳实践
- windows下package管理工具