# xpath选择器
表达式 描述
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
/text() 获取标签内的文字
/img/@src 获取img标签的src属性
/a[1] 获取选中的第一个a标签
div[@class='main_pic'] 通过class选择div,同样id也行
# 示例
* 抓取class为`logo-image`a标签下的img标签的图片地址
```
<a class="logo-image">
<img src="https://fanyi-cdn.cdn.bcebos.com/static/translation/img/header/logo_e835568.png">
</a>
```
```
print(response.xpath("//a[@class='logo-image']/img/@src").extract_first())
```
* 抓取class为`copyright`div下所有a连接文字
```
<div class="copyright">
<ul>
<li>
<a href="https://www.baidu.com/duty/" target="_blank">使用百度前必读</a>
<span class="split-line">|</span>
</li>
<li>
<a href="https://www.baidu.com/duty/" target="_blank">使用百度前必读</a>
<span class="split-line">|</span>
</li>
</ul>
</div>
```
```
list = response.xpath("//div[@class='copyright']/ul/li/a")
for i in list:
print(i.xpath('text()').extract())
```
# 实践
实践网址`http://m.soxs.cc/shuku/`
我们可以看到这个页面有许多列表,我们要做的是利用xpath选择器获取到所有的列表信息<br/>
* html 样例
```
<ul class="list">
<li>
<a href="/book/JingLingShouFu.html">
<img src="//img.soxs.cc/310272/1451007.jpg" alt="精灵收服">
</a>
<p class="bookname">
<a href="/JingLingShouFu/">精灵收服</a>
</p>
<p class="data">
<a href="/author/多肉的多/" class="layui-btn layui-btn-xs layui-bg-cyan">多肉的多</a>
<span class="layui-btn layui-btn-xs layui-btn-radius">玄幻奇幻</span>
<span class="layui-btn layui-btn-xs layui-btn-radius layui-btn-normal">连载</span>
</p>
<p class="intro">冯宇熙生活在精灵世界,这里有各种神奇的精灵,等你来收服</p>
<p class="data">最新:
<a href="/JingLingShouFu/2412122.html">第105章围剿邪灵</a>
</p>
</li>
</ul>
```
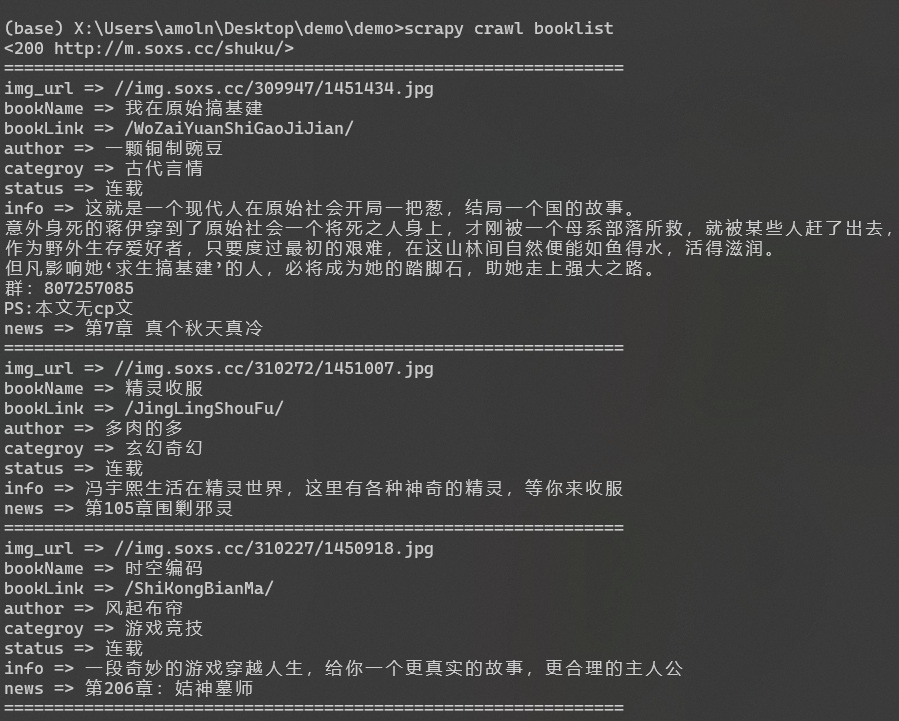
* 我们新建一个`booklist.py`文件
```
import scrapy
class booklistSpider(scrapy.Spider):
name = 'booklist'
allowed_domains = ['m.soxs.cc'] # 定义只爬取变量内的网站
start_urls = ["http://m.soxs.cc/shuku/"]
# 定义爬取的url,
def parse(self, response): # 爬虫启动后进入parse方法
print(response) # 输出爬取状态 200为成功获取内容
list = response.xpath("//ul[@class='list']/li")
for i in list:
img_url = i.xpath("a[1]/img/@src").extract_first()
bookName = i.xpath("p[1]/a/text()")[0].extract()
bookLink = i.xpath("p[1]/a/@href").extract_first()
author = i.xpath("p[2]/a/text()")[0].extract()
categroy = i.xpath("p[2]/span[1]/text()")[0].extract()
status = i.xpath("p[2]/span[2]/text()")[0].extract()
info = i.xpath("p[3]/text()")[0].extract()
news = i.xpath("p[4]/a/text()")[0].extract()
print("==============================================================")
print("img_url => "+img_url)
print("bookName => " + bookName)
print("bookLink => " + bookLink)
print("author => " + author)
print("categroy => " + categroy)
print("status => " + status)
print("info => " + info)
print("news => " + news)
```
* 执行代码:
`scrapy crawl booklist`