## 案例网站`http://m.soxs.cc/shuku/`
## 逻辑:
1. 我们需要定义一个入口将url放进启动程序
2. 我们写一个获取url方法,用之前的xpath选择器进行获取筛选,
3. 在主程序中我们调用上面的方法,如果有连接则在利用 `scrapy.Request` 进行访问
4. yield scrapy.Request("url",callback = self.回调方法名)
5. 请求写法固定
```
import scrapy
class booklist2Spider(scrapy.Spider):
name = 'booklist2'
allowed_domains = ['m.soxs.cc'] # 定义只爬取变量内的网站
start_urls = ["http://m.soxs.cc/"]# 定义爬取的url,
# 程序入口
def parse(self, response): # 爬虫启动后进入parse方法
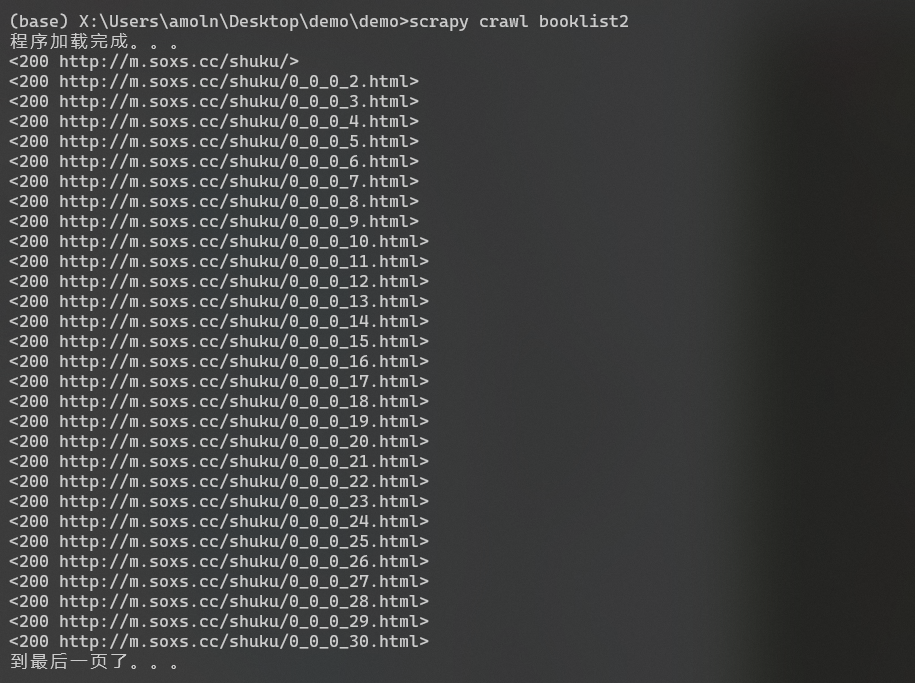
print("程序加载完成。。。")
yield scrapy.Request("http://m.soxs.cc/shuku/",callback = self.next)
# 固定写法 nextLink是url ,getrepones是请求成功调用方法
# 这里是主程序用来处理每页数据
def next(self, response):
print(response) # 输出爬取状态 200为成功获取内容
nextLink = self.getnextlink(response)
if nextLink == False:
print("到最后一页了。。。")
return
yield scrapy.Request(nextLink,callback = self.next)
# 获取下一页链接方法
def getnextlink(self, response):
list = response.xpath("//div[@class='pagelist']/a")
is_last = 1
for i in list:
if i.xpath("text()")[0].extract() == "下一页":
url = "http://"+self.allowed_domains[0]+i.xpath("@href").extract_first()
return url
return False
```
执行结果: