
## **索引有哪些数据结构,优缺点**
> 在创建索引时,通常采用的数据结构有:Hash、二叉搜索树、红黑树、B树以及B+树。这里主要介绍这些数据结构的设计思想,不做底层实现研究。
1. Hash结构:通过一定的算法计算数据的Hash值,然后得到数据的存放位置,例如JAVA中的HashMap采用就是这种数据索引结构。
* 优点:检索时间快,平均检索时间为O(1)。
* 缺点:
* 因为Hash值是通过算法计算出来的,存在Hash碰撞的几率,比如HashMap对于Hash值相同的数据,会在Hash值所在桶创建一个链表,用于存放相同Hash值的数据。
* 在数据量很大的情况下,内存无法加载全部的数据索引。
2. 二叉搜索树:定义规则为“左边节点值比根节点小,右边节点值比根节点大,并且左右子节点都是排序树”。
* 优点:可以解决大量数据索引无法一次加载进内存中的问题,二叉搜索树可以批量加载数据进内存。
* 缺点:
* 检索时间与树的高度有关,树的高度越高,检索次数及时间相对就会越久。
* 极端情况下,如果数据本身就是有序的,二叉搜索树会退化成链表,性能会急剧降低。
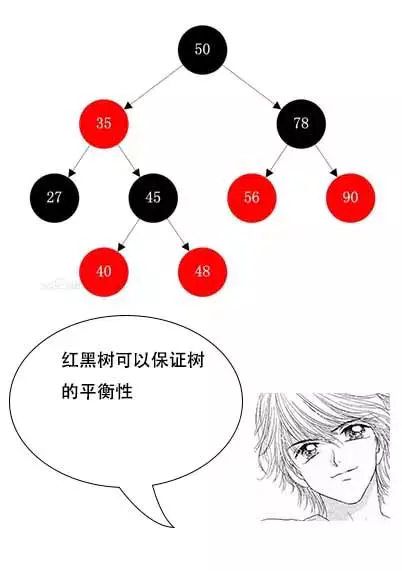
3. 红黑树:红黑树是一种自平衡二叉树,主要解决二叉搜索树在极端情况下退化成链表的情况,在数据插入的时候同时调整整个树,使其节点尽量均匀分布,保证平衡性,目的在于降低树的高度,提高查询效率。
* 优点:解决二叉搜索树的极端情况的退化问题。
* 缺点:检索时间依旧与树的高度有关,当数据量很大时,树的高度就会很高,检索的次数就会比较多,检索的时间会比较久,效率低。
:-: 
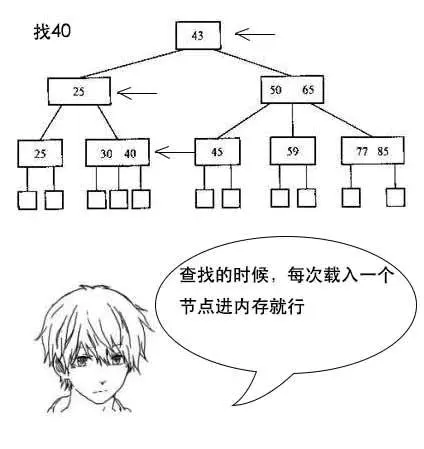
4. B树:B树是一种多路搜索树,每个子节点可以拥有多于2个子节点,M路的B树最多可拥有M个子节点。设计成多路,其目的是为了降低树的高度,降低查询次数,提高查询效率。
* 虽然多路可以降低树的高度,但是如果设计成无限多路,就会退化成有序数组,一般B树的使用场景是用于文件的索引,这些索引会存放于硬盘中,有时内存是无法一次性加载完,此时就无法进行查找。
* 如果全部在内存中,红黑树的查找效率要高于B树,但是涉及到磁盘操作,B树要优于红黑树,所以在JDK1.8版本的HashMap中,如果单个桶的链表长度多于8或全部桶的链表总长度多余64,会将链表转换成红黑树。
:-: 
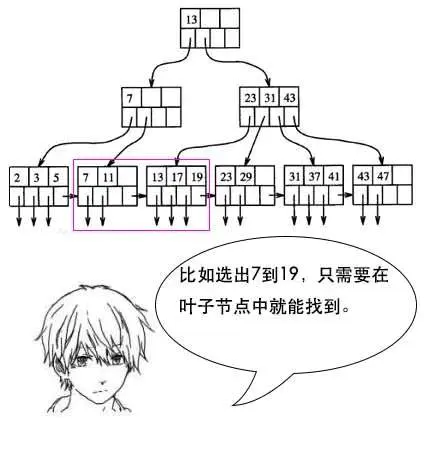
5. B+树:B+树是对于B树进行优化的多路搜索树,主要设计是将数据全部存放于叶子节点,并将叶子节点用指针进行链表链接。
* 主要使用场景:常用于数据库的索引。
* 数据库的索引一般数据量不小,同时又存放于磁盘中,采用多路搜索树,可以降低树的高度,同时在大数据量下可以分批载入内存,提高查询效率。
* 不同于B树的使用场景,数据库的查询中,我们一般查询的数量不会是单条数据,例如列表常用查询中的分页查询--查询第1页的10条数据,此时如果采用B树,需要进行树的中序遍历,可能需要跨层访问。
* 而B+树的所有数据全部存放于叶子节点上,且叶子节点之间采用指针进行链表链接,一次查询多条时,确定首尾位置,便可以方便的确定多条数据位置。
:-: 
- PHP篇
- 函数传值和传引用的区别
- 简述PHP的垃圾回收机制
- 简述CGI、FAST-CGI、PHP-FPM的关系
- 常见正则表达式
- 多进程写文件,如何保证都写成功
- php支持回调函数的数组函数
- MySQL篇
- MySQL的两种存储引擎区别
- 事务的四大特性
- 数据库事务隔离级别
- 什么是索引
- 索引有哪些数据结构,优缺点
- 索引的一些潜规则
- SQL的优化方案
- 简述MySQL的锁机制
- 死锁是怎么产生的?怎么解决?
- 简述MySQL的主从复制过程,延迟问题怎么解决
- 分布式事务的解决方案
- 数据库中间件MyCat
- Linux篇
- Linux常用命令
- 对日志文件的IP出现的次数进行统计,并显示次数最多的前5名
- WEB篇
- 跨域是怎么产生的,如何解决跨域
- Redis篇
- redis介绍
- redis和memcached区别
- redis的持久化方案
- 缓存穿透、击穿、雪崩、预热、更新、降级
- 网络篇
- 计算机网络体系结构
- 简述TCP的三次握手、四次挥手过程
- UDP、TCP 区别,适用场景
- HTTP常见状态码含义
- 设计模式篇
- 单例模式
- 简单工厂模式
- 抽象工厂模式
- 观察者模式
- 策略模式
- 注册模式
- 适配器模式
- 安全篇
- 跨站脚本攻击(XSS)
- 跨站点请求伪造(CSRF)
- SQL 注入
- 应用层拒绝服务攻击
- PHP安全
- 运维篇
- docker面试题
- 消息队列篇
- 架构篇
- 数据结构与算法篇