
# **第 2 章 便利的对象**
在第 1 章里,我们介绍了 Ruby 的基本数据对象“字符串”以及“数值”。当然,Ruby 能使用的数据对象不可能只有这两种。一般 Ruby 程序里数据对象的结构都比它们复杂得多。
假设现在我们用 Ruby 做一个通讯录,通讯录一般有以下项目:
-
**名字**
-
**拼音**
-
**邮政编码**
-
**都道府县**1
-
**地址**
-
**电话号码**
-
**邮箱地址**
-
**SNS 的 URL**
-
**登记日期**
1日本的行政区域单位——译者注
在这些项目里,邮政编码用 7 位的数字表示,除此以外的项目都是用字符串表示(一般来说,登记日期这个项目应该用 `Date` 对象来表示。关于 `Date` 对象我们将会在第 20 章介绍)。
这样一来,一组的项目集合起来后就可以表示一个人的基本信息(图 2.1),再把亲朋好友的基本信息都收集后就成为一本通讯录。

**图 2.1 收集、汇总各项目**
不同数据间的组合无法用字符串或数值这样简单的对象来表示,因此我们需要一个可以用以表示数据集合的数据结构。
本章我们将介绍数组和散列这两 种新的数据结构。另外,我们还会介绍处理字符串时常用的工具——正则表达式。
> **备注** 像数组、散列这样保存对象的对象,我们称为容器(container)。
数组、散列、正则表达式的应用十分广泛,关于它们的详细用法我们会在后面的章节介绍,在这里我们只会简略地说明一下,让大家对它们有个初步印象。
### **2.1 数组**
数组(array)是一个按顺序保存多个对象的对象,它是基本的容器之一。我们一般称为数组对象或者 Array 对象。
### **2.1.1 数组的创建**
要创建数组,我们需要把各数组的元素用逗号隔开,然后再用 `[]` 把它们括起来即可。首先,让我们创建一个简单的数组。
~~~
names = [" 小林 ", " 林 ", " 高野 ", " 森冈 "]
~~~
在这个例子里,我们创建了一个叫 `names` 的数组对象,分别保存了 4 个数组元素:小林、林、高野、森冈。如图 2.2 所示。

**图 2.2 数组对象**
### **2.1.2 数组对象**
在数组元素对象还未确定的情况下,我们可以用 `[]` 表示一个空数组对象。
~~~
names = []
~~~
除此以外,还有其他方法创建数组,我们将会在第 13 章再详细说明。
### **2.1.3 从数组中抽取对象**
保存在数组里的每个对象,都各自有一个表示其位置的编号,我们称之为索引(index)。利用索引,我们可以进行把对象保存到数组、从数组中抽取对象等操作。
要从数组中抽取元素(对象),我们可以使用以下方法。
**数组名 [ 索引 ]**
如下所示,有一个名为 `names` 的数组对象。
~~~
names = [" 小林 ", " 林 ", " 高野 ", " 森冈 "]
~~~
把 `names` 数组里第一个元素拿出来,我们可以这么做
~~~
names[0]
~~~
因此,若执行以下代码,
~~~
print "第一个名字为:", names[0], "。\n"
~~~
得到的结果为,
~~~
第一个名字为小林。
~~~
同样地,`names[1]` 表示林,`names[2]` 表示高野。
> **执行示例**
~~~
> irb --simple-prompt
=> names = ["小林", "林", "高野", "森冈"]
=> ["小林", "林", "高野", "森冈"]
>> names[0]
=> "小林"
>> names[1]
=> "林"
>> names[2]
=> "高野"
>> names[3]
=> "森冈"
~~~
> **备注** 数组的索引值是从 0 开始,并非 1。因此,`a[1]`返回的并不是数组第一个元素,而是第二个元素。刚接触编程时,大家比较容易弄错(即便是熟悉以后也有可能会犯这样的错误)。大家在使用数组时,务必注意索引值这个特点。
> **注** 在 Windows 命令行中,用 Alt + Shift 键切换中英文输入法模式。
### **2.1.4 将对象保存到数组中**
我们可以将新的对象保存到已经创建的数组中。
将数组里的某个元素置换为其他对象,我们可以这样做:
**数组名 [ 索引 ] = 希望保存的对象**
我们试着置换一下刚才的 `names` 数组的内容,将 " 野尻 " 放在数组首位。
~~~
names [0] = "野尻"
~~~
执行下面的程序,我们可以知道 " 野尻 " 的确已经被置换为首位的数组元素。
> **执行示例**
~~~
> irb --simple-prompt
>> names = ["小林", "林", "高野", "森冈"]
=> ["小林", "林", "高野", "森冈"]
>> names[0] = "野尻"
=> "野尻"
>> names
=> ["野尻", "林", "高野", "森冈"]
~~~
在保存对象时,如果指定了数组中不存在的索引值时,则数组的大小会随之而改变。Ruby 数组的大小是按实际情况自动调整的 2。
2即动态数组。——译者注
> **执行示例**
~~~
> irb --simple-prompt
>> names = ["小林", "林", "高野", "森冈"]
=> ["小林", "林", "高野", "森冈"]
>> names[4] = "野尻"
=> "野尻"
>> names
=> ["小林", "林", "高野", "森冈", "野尻"]
~~~
### **2.1.5 数组的元素**
任何对象都可以作为数组元素保存到数组中。例如,我们除了可以创建字符数组,还可以创建数值数组。
~~~
num = [3, 1, 4, 1, 5, 9, 2, 6, 5]
~~~
Ruby 数组还支持多种不同对象的混合保存。
~~~
mixed = [1, " 歌 ", 2, " 风 ", 3]
~~~
这里,我们不再举其他例子了,像时间、文件等对象也都可以作为数组元素。
### **2.1.6 数组的大小**
我们可以用 `size` 方法获知数组的大小。例如,若想获知数组 `array` 的大小,程序可以这么写:
~~~
array.size
~~~
我们现在就用 `size` 方法,查看一下刚才的 `names` 数组的大小。
> **执行示例**
~~~
> irb --simple-prompt
>> names = ["小林", "林", "高野", "森冈"]
=> ["小林", "林", "高野", "森冈"]
>> names.size
=> 4
~~~
size 方法的返回值就是数组的大小。
### **2.1.7 数组的循环**
有时,我们希望输出所有数组元素,或者对在数组中符合某条件的元素执行 xx 方法,不符合条件的执行 yy 方法。为实现这些目的,我们需要一种方法遍历所有数组元素。
为此,Ruby 提供了 `each` 方法。我们在第 1 章介绍迭代器时,已经稍微接触了一下 `each` 方法。
`each` 方法的语法如下:
**数组 .`each do` | 变量 |
希望循环的处理
`end`**
`each` 后面在 `do ~ end` 之间的部分称为块(block)3。因此,`each` 这样的方法也可以称为带块的方法。我们可以把多个需要处理的内容合并后写到块里面。
3也称为代码块。——译者注
块的开始部分为 | 变量 |。`each` 方法会把数组元素逐个拿出来,赋值给指定的 | 变量 |,那么块里面的方法就可以通过访问该变量,实现循环遍历数组的操作。
接下来,我们实际操作一下,按顺序输出数组 `names` 的元素。
> **执行示例**

每循环一次,就会把当前的数组元素赋值给变量 `|n|`(图 2.3)。

**图 2.3 循环时 n 的变化**
除了 `each` 方法外,数组还提供了许多带块的方法,我们在实际的数组操作中会经常使用到,详细的内容会在 13.6 节介绍。
### **2.2 散列**
散列(hash)也是一个程序里常用到的容器。散列是键值对(key-value pair)的一种数据结构。在 Ruby 中,一般是以字符串或者符号(Symbol)作为键,来保存对应的对象(图 2.4)。
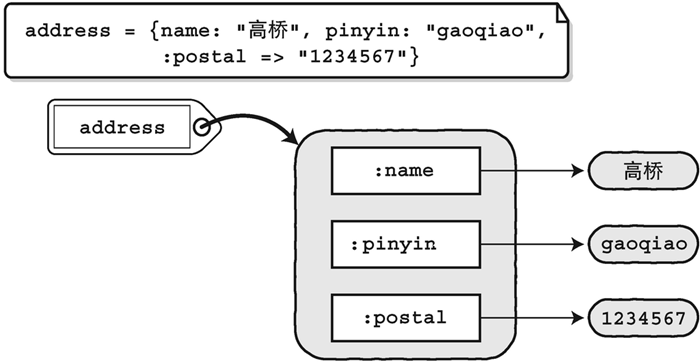
**图 2.4 散列**
### **2.2.1 什么是符号**
在 Ruby 中,符号(symbol)与字符串对象很相似 4,符号也是对象,一般作为名称标签来使用,用来表示方法等的对象的名称。
4可以将符号简单理解为轻量级的字符串。——译者注
创建符号,只需在标识符的开头加上`:` 就可以了。
~~~
sym = :foo # 表示符号“:foo”
sym2 = :"foo" # 意思同上
~~~
符号能实现的功能,大部分字符串也能实现。但像散列键这样只是单纯判断“是否相等”的处理中,使用符号会比字符串比较更加有效率,因此在实际编程中我们也会时常用到符号。
另外,符号与字符串可以互相任意转换。对符号使用 `to_s` 方法,则可以得到对应的字符串。反之,对字符串使用 `to_sym` 方法,则可以得到对应的符号。
> **执行示例**
~~~
> irb --simple-prompt
>> sym = :foo
=> :foo
>> sym.to_s # 将符号转换为字符串
=> "foo"
>> "foo".to_sym # 将字符串转换为符号
=> :foo
~~~
### **2.2.2 散列的创建**
创建散列的方法与创建数组的差不多,不同的是,不使用 `[]`,而是使用 `{}` 把创建的内容括起来。散列用`=>`来定义获取对象时所需的键(key),以及键相对应的对象(value)。
~~~
address = {:name => "高桥", :pinyin => "gaoqiao", :postal => "1234567"}
~~~
将符号当作键来使用时,程序还可以像下面这么写:
~~~
address = {name: "高桥", pinyin: "gaoqiao", postal: "1234567"}
~~~
### **2.2.3 散列的使用**
从散列取出对象、将对象保存到散列的使用方法也都和数组非常相似。我们使用以下方法从散列里取出对象。
**散列名 [ 键 ]**
保存对象时使用以下方法。
**散列名[ 键 ] = 希望保存的对象**
> **执行示例**
~~~
> irb --simple-prompt
>> address = {name: "高桥", pinyin: "gaoqiao"}
=> {:name=>"高桥", :pinyin=>"gaoqiao"}
>> address[:name]
=> "高桥"
>> address[:pinyin]
=> "gaoqiao"
>> address[:tel] = "000-1234-5678"
=> "000-1234-5678"
>> address
=> {:name=>"高桥", :pinyin=>"gaoqiao", :tel=>"000-1234-5678"}
~~~
### **2.2.4 散列的循环**
使用 `each` 方法,我们可以遍历散列里的所有元素,逐个取出其元素的键和对应的值。循环数组时是按索引顺序遍历元素,循环散列时按照键值组合遍历元素。
散列的 `each` 语法如下。
**散列 .`each do` | 键变量 , 值变量 |
希望循环的处理
`end`**
事不宜迟,我们马上来看看怎么用。
> **执行示例**
~~~
> irb --simple-prompt
>> address = {name: "高桥", pinyin: "gaoqiao"}
=> {:name=>"高桥", :pinyin=>"gaoqiao"}
>> address.each do |key, value|
?> puts "#{key}: #{value}"
>> end
name: 高桥
pinyin: gaoqiao
=> {:name=>"高桥", :pinyin=>"gaoqiao"}
~~~
显而易见,程序循环执行了输出散列 `address` 的键和值的 `puts` 方法 5。
5原文是 print 方法。——译者注
### **2.3 正则表达式**
在 Ruby 中处理字符串时,我们常常会用到正则表达式(regular expression)。使用正则表达式,可以非常简单地实现以下功能:
-
**将字符串与模式(pattern)相匹配**
-
**使用模式分割字符串**
Ruby 的前辈——Perl、Python 等脚本语言至今还在使用正则表达式。Ruby 继承了这一点,把正则表达式的使用嵌入到语法中,大大简化了正则表达式的调用方式。正是在正则表达式的帮助下,字符串处理变成了一个 Ruby 非常擅长的领域。
### **模式与匹配**
我们有时会有按照特定模式进行字符串处理的需求,比如“找出包含○○字符串的行”或者“抽取○○和 ×× 之间的字符串”。判断字符串是否适用于某模式的过程称为匹配,如果字符串适用于该模式则称为匹配成功(图 2.5)。

**图 2.5 匹配的例子**
像这样的字符串模式就是所谓的正则表达式。
乍一看,“正则表达式”这个词可能会给人一种深奥、难理解的印象。的确,正则表达式非常复杂,但如果只是使用单纯的匹配功能,也并不怎么难。所以大家也无需感到如临大敌,我们暂时只需要知道有个工具叫“正则表达式”就足够了。
创建正则表达式对象的语法如下所示。
**/ 模式 /**
例如,我们希望匹配 `Ruby` 字符串的正则表达式为:
~~~
/Ruby/
~~~
把希望匹配的内容直接写出来,就这么简单。匹配字母、数字时,模式按字符串原样写就可以了。6
6汉字也可以通过同样的方法做匹配。——译者注
我们用运算符`=~` 来匹配正则表达式和字符串。它与判断是否为同一个对象时用到的 `==` 有点像。
匹配正则表达式与字符串的方法是:
**/ 模式 / =~ 希望匹配的字符串**
若匹配成功则返回匹配部分的位置。字符的位置和数组的索引一样,是从 0 开始计数的。也就是说,字符串的首个字符位置为 0。反之,若匹配失败,则返回 `nil`。
> **执行示例**
~~~
> irb --simple-prompt
>> /Ruby/ =~ "Ruby"
=> 0
>> /Ruby/ =~ "Diamond"
=> nil
~~~
之前曾提到过,使用单纯的字母、数字、汉字模式时,如果字符串里存在该模式则匹配成功,否则匹配失败。
> **执行示例**
~~~
> irb --simple-prompt
>> /Ruby/ =~ "Yet Another Ruby Hacker,"
=> 12
>> /Yet Another Ruby Hacker,/ =~ "Ruby"
=> nil
~~~
正则表达式右边的 / 后面加上 i 表示不区分大小写匹配。
> **执行示例**
~~~
> irb --simple-prompt
>> /Ruby/ =~ "ruby"
=> nil
>> /Ruby/ =~ "RUBY"
=> nil
>> /Ruby/i =~ "ruby"
=> 0
>> /Ruby/i =~ "RUBY"
=> 0
>> /Ruby/i =~ "rUbY"
=> 0
~~~
除此以外,正则表达式还有很多写法和用法,更详细内容将会在第 16 章介绍。
> **专栏**
> **nil 是什么**
> `nil` 是一个特殊的值,表示对象不存在。像在正则表达式中表示无法匹配成功一样,方法不能返回有意义的值时就会返回 `nil`。另外,从数组或者散列里获取对象时,若指定不存在的索引或者键,则得到的返回值也是 `nil`。
> > **执行示例**
~~~
> irb --simple-prompt
>> hash = {"a"=>1, "b"=>2}
=> {"a"=>1, "b"=>2}
>> hash["c"]
=> nil
~~~
> `if` 语句和 `while` 语句在判断条件时,如果碰到 `false` 和 `nil`,则会认为是“假”,除此以外的都认为是“真”。因此,除了可以使用返回 `true` 或者 `false` 的方法,也可以使用“返回某个值”或者返回“`nil`”的方法作为判断条件表达式。
> **代码清单 print_hayasi.rb**
~~~
names = ["小林", "林", "高野", "森冈"]
["小林", "林", "高野", "森冈"]
names.each do |name|
if / 林/ =~ name
puts name
end
end
~~~
> > **执行示例**
~~~
> ruby print_hayasi.rb
小林
林
~~~
- 推荐序
- 译者序
- 前言
- 本书的读者对象
- 第 1 部分 Ruby 初体验
- 第 1 章 Ruby 初探
- 第 2 章 便利的对象
- 第 3 章 创建命令
- 第 2 部分 Ruby 的基础
- 第 4 章 对象、变量和常量
- 第 5 章 条件判断
- 第 6 章 循环
- 第 7 章 方法
- 第 8 章 类和模块
- 第 9 章 运算符
- 第 10 章 错误处理与异常
- 第 11 章 块
- 第 3 部分 Ruby 的类
- 第 12 章 数值类
- 第 13 章 数组类
- 第 14 章 字符串类
- 第 15 章 散列类
- 第 16 章 正则表达式类
- 第 17 章 IO 类
- 第 18 章 File 类与 Dir 类
- 第 19 章 Encoding 类
- 第 20 章 Time 类与 Date 类
- 第 21 章 Proc 类
- 第 4 部分 动手制作工具
- 第 22 章 文本处理
- 第 23 章 检索邮政编码
- 附录
- 附录 A Ruby 运行环境的构建
- 附录 B Ruby 参考集
- 后记
- 谢辞