
[TOC]
## 1 定义
Java 内存模型(JSR-133)的主要目的是定义程序中各种变量(Variables)的访问规则
- Variables 包括实例字段(instance field),静态字段(static field)和构成数组的元素(array element),不包括局部变量(local variable)与方法参数(method params),因为后者是线程私有的
- 所有的 Variables 都存储在虚拟机中的主内存(Main Memory);每条线程有自己的工作内存(Working Memory),保存了 Variables 的主内存副本
- 线程对 Variables 的所有操作,都必须在 Working Memory 中完成,不同线程间不能相互访问彼此的 Variables
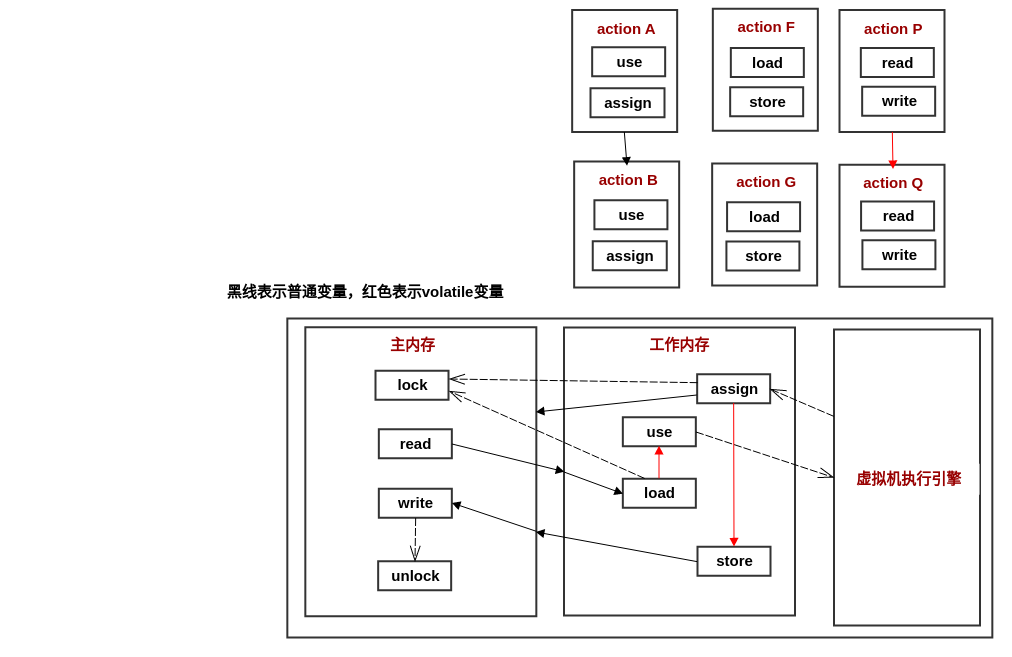
## 2 八种原子的内存间交互操作
Java 虚拟机实现时必须保证下面的每一种操作都是原子的:
名称 | 简称 | 作用位置 | 功能
---- | ---- | ---- | ----
lock | 锁定 | 主内存的变量 | 把一个变量标识为一条线程独占的状态
unlock | 解锁 | 主内存的变量 | 把一个处于锁定状态的变量释放 (释放后的变量才可被锁定)
read | 读取 | 主内存的变量 | 将变量值从主内存传输到线程的工作内存中 (以便 load )
load | 载入 | 工作内存的变量 | 把 read 操作从主内存中得到的变量值放入工作内存的变量副本中
use | 使用 | 工作内存的变量 | 把工作内存中一个变量的值传递给执行引擎
assign | 赋值 | 工作内存的变量 | 把一个从执行引擎接收的值赋给工作内存的变量
store | 存储 | 工作内存的变量 | 把变量值从传输到主内存 (以便 write)
write | 写入 | 主内存的变量 | 把 store 操作从工作内存中得到的变量值放入主内存的变量中
Java 内存模型规定了在执行上述 8 种操作时必须满足以下规则:
- (read 与 load) 或者 (store 与 write) 操作必须成对出现 (不允许主内存 read 后,工作内存不 load,或者工作内存 store 后,主内存不 write)
- 不允许一个线程丢弃它最近的 assign 操作 (变量在工作内存中改变了之后,必须同步回主内存)
- 不允许一个线程无原因地(没有发生过任何 assign 操作)把数据从线程的工作内存同步回主内存
- 在对变量实施 use 、store 操作之前,必须先执行 load 和 assign操作 (新变量只能在主内存中创建,不允许工作内存使用未被初始化的变量)
- 一个变量在同一时刻只允许一条线程对其进行 lock ,但 lock 操作可以被同一条线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock ,变量才会被解锁
- 如果一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行 load 或 assign 操作以初始化变量的值
- 一个线程不允许 unlock 一个未被 lock 或者被其他线程 lock 的变量
- 对一个变量执行 unlock 操作前,必须把此变量同步回主内存中(执行 store、write 操作)
## 3 volatile 变量
对 volatile 变量的 read、load、use、assign、store 和 write 操作,规定以下**规则**:
- 一个线程对 volatile 变量的 load、use 操作必须是连续的
- 一个线程对 volatile 变量的 assign、store、write 操作必须是连续的
- volatile 变量不会被指令重排序优化
当一个变量被 volatile 修饰后,将具备以下**特性**:
- 保证此变量对所有线程的可见性 (当一条线程修改了这个变量的值,新值对于其他线程来说是可以立即得知的)
- 当不符合以下两条规则的运算场景中,仍然要通过加锁保证 volatile 变量的线程安全:
- 运算结果并不依赖变量的当前值,或者能够确保只有单一线程修改变量的值
- 变量不需要与其他状态变量共同参与不变约束
- bad case 1,volatile修饰的变量i,在10个线程中进行(i++)操作后,i不一定会增加10
- bad case 2,32位机器中long和double类型的操作非原子性,使用时需要保证原子性
- 禁止指令重排序优化
- 64位long与double变量读写的原子性
> 以下示例中,假设 loaded 未使用 volatile 修饰,则指令重排序后可能出现在 loadCofig() 逻辑前,导致线程 2 使用了未加载的配置
```java
volatile loaded = false;
// 线程 1
loadConfig(); // 加载配置文件
loaded = true; // 设置加载状态
// 线程 2
while (!loaded) {
sleep(); // 判断是否加载配置完成
}
useConfig(); // 跳出循环后使用线程 1 的配置
```
> **双重检测锁定形式的延迟初始化存在的问题**
>
> 设 new A() 分为:
> 1. 分配内存
> 2. 初始化对象
> 3. sInstance 指向内存地址
>
> 重排序后可能变为`1、3、2`的顺序,导致虽然第一次的 `if (sInstance == null)` 返回了 false,但是对象并未被初始化,改为 `private static volatile A sInstance;` 禁止指令重排序即可。
```java
public class A {
private static A sInstance;
public static A getInstance() {
if (sInstance == null) {
synchronized (A.class) {
if (sInstance == null) {
sInstance = new A();
}
}
}
return sInstance;
}
}
```
## 4 final 域
对于 final 域,编译器和处理器要遵守两个重排序规则:
- 在构造方法内对一个 final 域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这个两个操作之间不能重排序。
- 初次读一个包含 final 域的对象的引用,与随后初次读这个 final 域,这两个操作之间不能重排序。
## 5 原子性、可见性和有序性
**原子性**
- Java内存模型中保证原子性的操作包括:read、load、assign、use、write、store、write,如果需要更大范围的,可以使用 lock 和 unlock
- lock 和 unlock 体现在字节码层面是 monitorenter 和 monitorexit 指令,反映到代码中就是 synchronized 或 Unsafe#monitorEnter 和 Unsafe#monitorExit 方法
**可见性**
- 一个线程对变量的 load、use 操作必须是连续的
- 一个线程对变量的 assign、store、write 操作必须是连续的
- synchronized、 volatile 、final 都可以保证可见性
**有序性**
- 在单个线程中观察,所有操作都是有序的;在一个线程观察另一个线程,所有操作都是无序的
- synchronized、volatile 可以保证有序性
## 6 先行发生原则
先行发生原则(Happens-Before)是判断数据是否竞争,线程是否安全的重要手段。
> 先行发生原则示例:假设 A 线程的操作先行发生于 B 线程的操作,则 j 等于 1;假设无法保证 B 线程和 C 线程的先行发生关系,则 j 的值可能为 1,也可能为 2
```java
// A 线程执行
i = 1;
// B 线程执行
j = i;
// C 线程执行
i = 2
```
假设两个操作,不满足以下关系之一的,虚拟机可以对其随意重排序(有且只有以下关系):
- **程序次序规则(Program Order Rule)**:在一个线程内,按照控制流顺序,书写在前的操作先行发生于书写在后面的操作
- **管程锁定规则(Monitor Lock Rule)**:一个 unlock 操作先行发生于后面(时间上)对同一个锁的 lock 操作
- **volatile 变量规则(Volatile Variable Rule)**:对一个 volatile 变量的写操作先行发生于后面(时间上)对这个变量的读操作
- **线程启动规则(Thread Start Rule)**:Thread 对象的start()方法先行发生于此线程的每一个动作
- **线程终止规则(Thread Stop Rule)**:线程中的所有操作都先行发生于对此线程的终止检测,所以可以用 Thread#join Thread#isAlive 来检测线程线程是否已经终止
- **线程中断规则(Thread Interruption Rule)**:对线程 interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,所以可以用 Thread#interrupted 方法检测是否有中断发生
- **对象终结规则(Finalizer Rule)**:一个对象的构造方法结束,先行发生于它的finalize()方法的开始
- **传递性规则(Transitivity)**:如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,则操作 A 先行发生于操作 C
----
> 一个非线程安全的例子:假设有两个线程,A线程(时间上)先调用了setValue(100),然后B线程调用了同一个对象的getValue(),则B线程收到的返回值可能为0也可能为100
```java
private int value = 0;
public void setValue(int value) {
this.value = value;
}
public int getValue() {
return value;
}
```
以上例子,根据先行发生原则进行分析:
- 不在一个线程中,不符合**程序次序规则**
- 没有同步块,不符合**管程锁定规则**
- value 字段没有被 volatile 修饰,不符合**volatile 变量规则**
- 和 **线程启动规则**、**线程终止规则**、**线程中断规则**、**对象终结规则** 没关系
- 没有先行发生原则 ,因此不符合**传递性规则**
保证线程安全的方案:
- 将 setValue 方法与 getValue 方法用 synchronized 修饰
- 或者将 value 字段使用 volatile 修饰
> 判断并发安全问题的时候,不要受时间顺序干扰,一切必须以**先行发生原则**为准
----
## 7 附录 - volatile 变量的实现原理
volatile的两条实现规则为:
- lock前缀指令会引起处理器缓存写回到内存
- 一个处理器的缓存回写到内存会导致其他处理器的缓存无效
如果对volatile变量执行写操作,JVM会向处理器发送一条lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存;并且在多处理器间实现缓存一致性协议,当处理器感知缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态
<pre>
instance = new Singletion(); // instance 是 volatile 变量
// 转为汇编代码
0x01a3de1d: movb $0×0,0×1104800(%esi);0x01a3de24: <b>lock</b> addl $0×0,(%esp);
</pre>
> CPU 的术语定义
术语 | 英文 | 描述
---- | ---- | ----
内存屏障 | memory barriers | 一组处理器**指令**,用于实现对内存操作的**顺序限制**
缓冲行 | cache line | 缓存中可以分配的最小存储单位。处理器填写缓冲线时会加载整个缓存线,需要使用多个主内存读周期
原子操作 | atomic operations | 不可中断的一个或一系列操作
缓存行填充 | cache line fill | 当处理器识别到从内存中读取操作数是可缓存的,处理器读取整个缓存行到适当的缓存(L1, L2, L3或所有)
缓存命中 | cache hit | 如果进行告诉缓存行填充操作的内存位置仍然是下次处理器访问的地址时,处理器从**缓存**中读取操作数,而不是从内存读取
写命中 | write hit | 当处理器将操作数写回到一个内存缓存的区域时,它首先会检查这个缓存的内存地址是否在缓存行中。如果存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是写回到内存,这个操作称为写命中
写缺失 | write miss the cache | 一个有效的缓存行被写入到不存在的内存区域
----
**volatile与缓存行填充优化**:
- JDK 7 的LinkedTransferQueue在使用volatile变量时,通过追加15个变量将(加上private volatile V value)对象的占用变为64字节(JDK 8 可以使用`@sun.misc.Contended`来填充缓存行),以提高并发编程效率
> 因为英特尔酷睿i7、酷睿、Atom和NetBurst,以及Core Solo和Pentium M处理器的L1、L2或L3缓存的高速缓存行是64个字节宽,不支持部分填充缓存行;如果LinkedTransferQueue的头结点和尾结点都不足64字节,处理器会将它们读到同一个高速缓存行;假如一个处理器试图修改头结点,则会将整个缓存行锁定,导致其他处理器不能访问自己高速缓存中的尾结点,严重影响LinkedTransferQueue的出队和入队操作
- 以下两种场景不应该使用缓存行填充:**缓存行非64字节宽的处理器;共享变量不会被频繁地写**
----
** `volatile + CAS` 构成了 [Java并发包](http://wiki.baidu.com/pages/viewpage.action?pageId=1654188471) 的基石**
- 底层:volatile变量的读/写 + CAS(Unsafe类)
- 中层:AQS + 非阻塞数据结构 + 原子变量类
- 上层:Lock + 同步器 + 阻塞队列 + Executor + 并发容器
## 8 附录 - synchronized 域
**synchronized 的用法**
Java 中的每一个对象都可以作为锁 —— 这是 synchronized 实现同步的基础,具体表现为:
```java
static class A {
synchronized void m1(String key, Object value) { // 对于普通方法,锁是 A.this
}
static synchronized void put(Map<String, Object> map, String key, Object value) { // 对于静态方法,锁是 A.class
}
static void get(Map<String, Object> map, String key) {
synchronized (map) { // 对于同步方法块,锁是 map
}
}
}
```
-----
**synchronized 的实现**
JVM 基于进入和退出Monitor对象来实现方法同步和代码块同步
- 代码块是使用monitorenter和monitorexit指令实现(monitorenter指令在编译后插入到同步块的开始位置,monitorexit插入到方法结束处和异常处)
- 方法同步也以使用monitorenter和monitorexit指令实现,但是JVM规范里没有详细说明
任何对象都有一个monitor,当一个monitor被持有后,将处于锁定状态;以下是对象头的结构(数组类型使用3字宽(Word),非数组使用2字宽,32位虚拟机中,1字宽等于32bit)
- `Mark Word` 占1字宽,存储对象的hashCode和锁信息
- `Class Metadata Address` 占1字宽,存储对象类型数据的指针
- `Array Length` 占1字宽(仅数组类型),存储数组的长度
> Mark Word 的存储结构
<pre style="font-family: 'Courier New','MONACO'">
锁状态 | 23bit | 2bit | 4bit | 1bit是否为偏向锁 | 2bit 锁标志位
--------------------------------------------------------------------------------------------------------------------------
无锁状态 | 对象的hashCode (25bit) | 对象的分代年龄 (4bit) | 0 (1bit) | 01 (2bit)
偏向锁 | 线程ID (23bit) | Epoch (2bit) | 对象分代年龄 (4bit) | 1 (1bit) | 01 (2bit)
轻量级锁 | 指向栈中锁记录的指针 (30bit) | 00 (2bit)
重量级锁 | 执行互斥量(重量级锁)的指针 (30bit) | 10 (2bit)
GC 标记 | 空 | 11 (2bit)
</pre>
-----
Java SE 1.6 为了减少获得锁和释放锁带来的性能损耗,引入了`偏向锁` 和 `轻量级锁`,锁的4种状态会锁着竞争情况而不断升级(不能降级):无锁、偏向锁、轻量级锁、重量级锁
> 4种锁状态的优缺点对比
锁状态 | 优点 | 缺点 | 适用场景
---- | ---- | ---- | ----
偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法相比仅存在纳秒级的差距 | 如果线程间存在锁竞争,会带来额外的**锁撤销**的消耗 | 适用于只有一个线程访问同步块的场景
轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度 | 如果始终得不到锁竞争的线程,使用**自旋**会消耗 CPU | 追求响应时间,同步块执行速度非常块
重量级锁 | 线程竞争不使用自旋,不会消耗CPU | 线程阻塞,响应时间缓慢 | 追求吞吐量,同步块执行时间较长
## 9 附录 - 原子操作的实现原理
原子操作(atomic operation)表示不可中断的一个或一系列操作
**处理器实现原子操作**
> CPU 术语定义
处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性
- 总线锁定:使用处理器提供的一个`lock#`信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,此时该处理器可以独占共享内存
- 缓存锁定:内存区域如果被缓存在处理器的缓存行中,并且在lock操作期间被锁定,那么当它执行锁操作写回到内存时,处理器不在总线上声明`lock#`信号,而是修改内部的内存地址,使缓存行无效
- 当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行时,处理器会使用总线锁定
- 当处理器不支持缓存锁定时,会调用总线锁定
**Java 实现原子操作**
在 Java 中通过锁或循环CAS来实现原子操作。CAS 存在三大问题
- ABA 问题(通过版本号解决)
- 循环时间长开销大
- 只能保证一个共享变量的原子操作(通过将多种状态用各个bit位表示来解决)
- 空白目录
- 精简版Spring的实现
- 0 前言
- 1 注册和获取bean
- 2 抽象工厂实例化bean
- 3 注入bean属性
- 4 通过XML配置beanFactory
- 5 将bean注入到bean
- 6 加入应用程序上下文
- 7 JDK动态代理实现的方法拦截器
- 8 加入切入点和aspectj
- 9 自动创建AOP代理
- Redis原理
- 1 Redis简介与构建
- 1.1 什么是Redis
- 1.2 构建Redis
- 1.3 源码结构
- 2 Redis数据结构与对象
- 2.1 简单动态字符串
- 2.1.1 sds的结构
- 2.1.2 sds与C字符串的区别
- 2.1.3 sds主要操作的API
- 2.2 双向链表
- 2.2.1 adlist的结构
- 2.2.2 adlist和listNode的API
- 2.3 字典
- 2.3.1 字典的结构
- 2.3.2 哈希算法
- 2.3.3 解决键冲突
- 2.3.4 rehash
- 2.3.5 字典的API
- 2.4 跳跃表
- 2.4.1 跳跃表的结构
- 2.4.2 跳跃表的API
- 2.5 整数集合
- 2.5.1 整数集合的结构
- 2.5.2 整数集合的API
- 2.6 压缩列表
- 2.6.1 压缩列表的结构
- 2.6.2 压缩列表结点的结构
- 2.6.3 连锁更新
- 2.6.4 压缩列表API
- 2.7 对象
- 2.7.1 类型
- 2.7.2 编码和底层实现
- 2.7.3 字符串对象
- 2.7.4 列表对象
- 2.7.5 哈希对象
- 2.7.6 集合对象
- 2.7.7 有序集合对象
- 2.7.8 类型检查与命令多态
- 2.7.9 内存回收
- 2.7.10 对象共享
- 2.7.11 对象空转时长
- 3 单机数据库的实现
- 3.1 数据库
- 3.1.1 服务端中的数据库
- 3.1.2 切换数据库
- 3.1.3 数据库键空间
- 3.1.4 过期键的处理
- 3.1.5 数据库通知
- 3.2 RDB持久化
- 操作系统
- 2021-01-08 Linux I/O 操作
- 2021-03-01 Linux 进程控制
- 2021-03-01 Linux 进程通信
- 2021-06-11 Linux 性能优化
- 2021-06-18 性能指标
- 2022-05-05 Android 系统源码阅读笔记
- Java基础
- 2020-07-18 Java 前端编译与优化
- 2020-07-28 Java 虚拟机类加载机制
- 2020-09-11 Java 语法规则
- 2020-09-28 Java 虚拟机字节码执行引擎
- 2020-11-09 class 文件结构
- 2020-12-08 Java 内存模型
- 2021-09-06 Java 并发包
- 代码性能
- 2020-12-03 Java 字符串代码性能
- 2021-01-02 ASM 运行时增强技术
- 理解Unsafe
- Java 8
- 1 行为参数化
- 1.1 行为参数化的实现原理
- 1.2 Java 8中的行为参数化
- 1.3 行为参数化 - 排序
- 1.4 行为参数化 - 线程
- 1.5 泛型实现的行为参数化
- 1.6 小结
- 2 Lambda表达式
- 2.1 Lambda表达式的组成
- 2.2 函数式接口
- 2.2.1 Predicate
- 2.2.2 Consumer
- 2.2.3 Function
- 2.2.4 函数式接口列表
- 2.3 方法引用
- 2.3.1 方法引用的类别
- 2.3.2 构造函数引用
- 2.4 复合方法
- 2.4.1 Comparator复合
- 2.4.2 Predicate复合
- 2.4.3 Function复合
- 3 流处理
- 3.1 流简介
- 3.1.1 流的定义
- 3.1.2 流的特点
- 3.2 流操作
- 3.2.1 中间操作
- 3.2.2 终端操作
- 3.3.3 构建流
- 3.3 流API
- 3.3.1 flatMap的用法
- 3.3.2 reduce的用法
- 3.4 collect操作
- 3.4.1 collect示例
- 3.4.2 Collector接口