
# Apache HBase 运营管理
本章将介绍运行 Apache HBase 集群所需的操作工具和实践。操作主题与[故障排除和调试 Apache HBase](#trouble) , [Apache HBase 性能调优](#performance)和 [Apache HBase 配置](#configuration)的主题相关,但本身就是一个独特的主题。
## 150\. HBase 工具和实用程序
HBase 为集群的管理,分析和调试提供了多种工具。大多数这些工具的入口点是 _bin / hbase_ 命令,尽管 _dev-support /_ 目录中提供了一些工具。
要查看 _bin / hbase_ 命令的使用说明,请运行它,不带参数或使用`-h`参数。这些是 HBase 0.98.x 的使用说明。某些命令(例如`version`,`pe`,`ltt`,`clean`)在以前的版本中不可用。
```
$ bin/hbase
Usage: hbase [<options>] <command> [<args>]
Options:
--config DIR Configuration direction to use. Default: ./conf
--hosts HOSTS Override the list in 'regionservers' file
--auth-as-server Authenticate to ZooKeeper using servers configuration
Commands:
Some commands take arguments. Pass no args or -h for usage.
shell Run the HBase shell
hbck Run the HBase 'fsck' tool. Defaults read-only hbck1.
Pass '-j /path/to/HBCK2.jar' to run hbase-2.x HBCK2.
snapshot Tool for managing snapshots
wal Write-ahead-log analyzer
hfile Store file analyzer
zkcli Run the ZooKeeper shell
master Run an HBase HMaster node
regionserver Run an HBase HRegionServer node
zookeeper Run a ZooKeeper server
rest Run an HBase REST server
thrift Run the HBase Thrift server
thrift2 Run the HBase Thrift2 server
clean Run the HBase clean up script
classpath Dump hbase CLASSPATH
mapredcp Dump CLASSPATH entries required by mapreduce
pe Run PerformanceEvaluation
ltt Run LoadTestTool
canary Run the Canary tool
version Print the version
backup Backup tables for recovery
restore Restore tables from existing backup image
regionsplitter Run RegionSplitter tool
rowcounter Run RowCounter tool
cellcounter Run CellCounter tool
CLASSNAME Run the class named CLASSNAME
```
下面的一些工具和实用程序是 Java 类,它们直接传递给 _bin / hbase_ 命令,如使用说明的最后一行所述。其他如`hbase shell`( [Apache HBase Shell](#shell) ),`hbase upgrade`([升级](#upgrading))和`hbase thrift`( [Thrift API 和过滤语言](#thrift)) ,在本指南的其他地方记录。
### 150.1。加纳利
Canary 工具可以帮助用户“测试”HBase 集群状态。默认的“区域模式”从每个区域的每个列族中获取一行。在“regionserver 模式”中,Canary 工具将从每个集群的 RegionServers 上的随机区域中获取一行。在“zookeeper 模式”中,Canary 将读取 zookeeper 集合的每个成员上的根 znode。
要查看用法,请传递`-help`参数(如果未传递参数,则 Canary 工具将在默认区域“mode”中开始执行,从群集中的每个区域获取一行)。
```
2018-10-16 13:11:27,037 INFO [main] tool.Canary: Execution thread count=16
Usage: canary [OPTIONS] [<TABLE1> [<TABLE2]...] | [<REGIONSERVER1> [<REGIONSERVER2]..]
Where [OPTIONS] are:
-h,-help show this help and exit.
-regionserver set 'regionserver mode'; gets row from random region on server
-allRegions get from ALL regions when 'regionserver mode', not just random one.
-zookeeper set 'zookeeper mode'; grab zookeeper.znode.parent on each ensemble member
-daemon continuous check at defined intervals.
-interval <N> interval between checks in seconds
-e consider table/regionserver argument as regular expression
-f <B> exit on first error; default=true
-failureAsError treat read/write failure as error
-t <N> timeout for canary-test run; default=600000ms
-writeSniffing enable write sniffing
-writeTable the table used for write sniffing; default=hbase:canary
-writeTableTimeout <N> timeout for writeTable; default=600000ms
-readTableTimeouts <tableName>=<read timeout>,<tableName>=<read timeout>,...
comma-separated list of table read timeouts (no spaces);
logs 'ERROR' if takes longer. default=600000ms
-permittedZookeeperFailures <N> Ignore first N failures attempting to
connect to individual zookeeper nodes in ensemble
-D<configProperty>=<value> to assign or override configuration params
-Dhbase.canary.read.raw.enabled=<true/false> Set to enable/disable raw scan; default=false
Canary runs in one of three modes: region (default), regionserver, or zookeeper.
To sniff/probe all regions, pass no arguments.
To sniff/probe all regions of a table, pass tablename.
To sniff/probe regionservers, pass -regionserver, etc.
See http://hbase.apache.org/book.html#_canary for Canary documentation.
```
> `Sink`类使用`hbase.canary.sink.class`配置属性进行实例化。
此工具将向用户返回非零错误代码,以便与其他监视工具(如 Nagios)协作。错误代码定义是:
```
private static final int USAGE_EXIT_CODE = 1;
private static final int INIT_ERROR_EXIT_CODE = 2;
private static final int TIMEOUT_ERROR_EXIT_CODE = 3;
private static final int ERROR_EXIT_CODE = 4;
private static final int FAILURE_EXIT_CODE = 5;
```
以下是基于以下给定情况的一些示例:给定两个名为 test-01 和 test-02 的 Table 对象,每个对象分别具有两个列族 cf1 和 cf2,部署在 3 个 RegionServers 上。请参见下表。
| RegionServer 的 | 测试 01 | 测试 02 |
| --- | --- | --- |
| RS1 | R1 | R2 |
| RS2 | r2 | |
| RS3 | r2 | r1 |
以下是基于先前给定案例的一些示例输出。
#### 150.1.1。 Canary 测试每个表的每个区域的每个列族(商店)
```
$ ${HBASE_HOME}/bin/hbase canary
3/12/09 03:26:32 INFO tool.Canary: read from region test-01,,1386230156732.0e3c7d77ffb6361ea1b996ac1042ca9a. column family cf1 in 2ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-01,,1386230156732.0e3c7d77ffb6361ea1b996ac1042ca9a. column family cf2 in 2ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-01,0004883,1386230156732.87b55e03dfeade00f441125159f8ca87\. column family cf1 in 4ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-01,0004883,1386230156732.87b55e03dfeade00f441125159f8ca87\. column family cf2 in 1ms
...
13/12/09 03:26:32 INFO tool.Canary: read from region test-02,,1386559511167.aa2951a86289281beee480f107bb36ee. column family cf1 in 5ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-02,,1386559511167.aa2951a86289281beee480f107bb36ee. column family cf2 in 3ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-02,0004883,1386559511167.cbda32d5e2e276520712d84eaaa29d84\. column family cf1 in 31ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-02,0004883,1386559511167.cbda32d5e2e276520712d84eaaa29d84\. column family cf2 in 8ms
```
所以你可以看到,table test-01 有两个区域和两个列族,因此默认的“区域模式”中的 Canary 工具将从 4 个(2 个区域* 2 个商店)不同的商店中挑选 4 个小块数据。这是默认行为。
#### 150.1.2。对特定表格的每个区域的每个列族(商店)进行 Canary 测试
您还可以通过传递表名来测试一个或多个特定表。
```
$ ${HBASE_HOME}/bin/hbase canary test-01 test-02
```
#### 150.1.3。使用 RegionServer 粒度进行 Canary 测试
在“regionserver 模式”中,Canary 工具将从每个 RegionServer 中选取一小段数据(在“regionserver 模式”下,您还可以将一个或多个 RegionServer 名称作为参数传递给 canary-test)。
```
$ ${HBASE_HOME}/bin/hbase canary -regionserver
13/12/09 06:05:17 INFO tool.Canary: Read from table:test-01 on region server:rs2 in 72ms
13/12/09 06:05:17 INFO tool.Canary: Read from table:test-02 on region server:rs3 in 34ms
13/12/09 06:05:17 INFO tool.Canary: Read from table:test-01 on region server:rs1 in 56ms
```
#### 150.1.4。金丝雀测试与正则表达式模式
在“区域模式”下,您可以为表名传递正则表达式,在“regionserver 模式”下,可以为服务器名传递正则表达式。下面将测试 table test-01 和 test-02。
```
$ ${HBASE_HOME}/bin/hbase canary -e test-0[1-2]
```
#### 150.1.5。运行金丝雀测试作为“守护进程”
通过选项`-interval`定义的间隔重复运行(默认值为 60 秒)。如果发生任何错误,此守护程序将自行停止并返回非零错误代码。要让守护程序继续运行错误,请传递-f 标志,并将其值设置为 false(请参阅上面的用法)。
```
$ ${HBASE_HOME}/bin/hbase canary -daemon
```
要以 5 秒的间隔重复运行而不是因错误而停止,请执行以下操作。
```
$ ${HBASE_HOME}/bin/hbase canary -daemon -interval 5 -f false
```
#### 150.1.6。如果金丝雀测试卡住,则强制超时
在某些情况下,请求被卡住,并且没有响应被发送回客户端。这可能发生在主服务器尚未注意到的死区域服务器上。因此,我们提供了一个超时选项来终止金丝雀测试并返回非零错误代码。以下设置超时值为 60 秒(默认值为 600 秒)。
```
$ ${HBASE_HOME}/bin/hbase canary -t 60000
```
#### 150.1.7。在金丝雀中启用写嗅探
默认情况下,canary 工具仅检查读取操作。要启用写入嗅探,可以在设置了`-writeSniffing`选项的情况下运行 canary。启用写入嗅探时,金丝雀工具将创建一个 hbase 表,并确保将表的区域分发到所有区域服务器。在每个嗅探期间,金丝雀将尝试将数据放入这些区域以检查每个区域服务器的写入可用性。
```
$ ${HBASE_HOME}/bin/hbase canary -writeSniffing
```
默认写表为`hbase:canary`,可以使用选项`-writeTable`指定。
```
$ ${HBASE_HOME}/bin/hbase canary -writeSniffing -writeTable ns:canary
```
每个 put 的默认值大小为 10 个字节。您可以通过配置键设置它:`hbase.canary.write.value.size`。
#### 150.1.8。将读/写失败视为错误
默认情况下,金丝雀工具仅记录读取失败 - 由于例如 RetriesExhaustedException 等 - 并将返回'正常'退出代码。要将读/写失败视为错误,可以使用`-treatFailureAsError`选项运行 canary。启用时,读/写失败将导致错误退出代码。
```
$ ${HBASE_HOME}/bin/hbase canary -treatFailureAsError
```
#### 150.1.9。在启用 Kerberos 的群集中运行 Canary
要在启用 Kerberos 的群集中运行 Canary,请在 _hbase-site.xml_ 中配置以下两个属性:
* `hbase.client.keytab.file`
* `hbase.client.kerberos.principal`
当 Canary 以守护进程模式运行时,Kerberos 凭据每 30 秒刷新一次。
要为客户端配置 DNS 接口,请在 _hbase-site.xml_ 中配置以下可选属性。
* `hbase.client.dns.interface`
* `hbase.client.dns.nameserver`
示例 40.启用 Kerberos 的群集中的 Canary
此示例显示具有有效值的每个属性。
```
<property>
<name>hbase.client.kerberos.principal</name>
<value>hbase/_HOST@YOUR-REALM.COM</value>
</property>
<property>
<name>hbase.client.keytab.file</name>
<value>/etc/hbase/conf/keytab.krb5</value>
</property>
<!-- optional params -->
<property>
<name>hbase.client.dns.interface</name>
<value>default</value>
</property>
<property>
<name>hbase.client.dns.nameserver</name>
<value>default</value>
</property>
```
### 150.2。 RegionSplitter
```
usage: bin/hbase regionsplitter <TABLE> <SPLITALGORITHM>
SPLITALGORITHM is the java class name of a class implementing
SplitAlgorithm, or one of the special strings
HexStringSplit or DecimalStringSplit or
UniformSplit, which are built-in split algorithms.
HexStringSplit treats keys as hexadecimal ASCII, and
DecimalStringSplit treats keys as decimal ASCII, and
UniformSplit treats keys as arbitrary bytes.
-c <region count> Create a new table with a pre-split number of
regions
-D <property=value> Override HBase Configuration Settings
-f <family:family:...> Column Families to create with new table.
Required with -c
--firstrow <arg> First Row in Table for Split Algorithm
-h Print this usage help
--lastrow <arg> Last Row in Table for Split Algorithm
-o <count> Max outstanding splits that have unfinished
major compactions
-r Perform a rolling split of an existing region
--risky Skip verification steps to complete
quickly. STRONGLY DISCOURAGED for production
systems.
```
有关其他详细信息,请参见[手动区域分割](#manual_region_splitting_decisions)。
### 150.3。健康检查员
您可以将 HBase 配置为定期运行脚本,如果它失败了 N 次(可配置),请让服务器退出。有关配置和详细信息,请参阅 _HBASE-7351 定期运行状况检查脚本 _。
### 150.4。司机
几个经常访问的实用程序作为`Driver`类提供,并由 _bin / hbase_ 命令执行。这些实用程序代表在群集上运行的 MapReduce 作业。它们以下列方式运行,将 _UtilityName_ 替换为您要运行的实用程序。此命令假定您已将环境变量`HBASE_HOME`设置为服务器上解压缩 HBase 的目录。
```
${HBASE_HOME}/bin/hbase org.apache.hadoop.hbase.mapreduce.UtilityName
```
可以使用以下实用程序:
`LoadIncrementalHFiles`
完成批量数据加载。
`CopyTable`
将表从本地群集导出到对等群集。
`Export`
将表数据写入 HDFS。
`Import`
导入先前`Export`操作写入的数据。
`ImportTsv`
以 TSV 格式导入数据。
`RowCounter`
计算 HBase 表中的行数。
`CellCounter`
计算 HBase 表中的单元格。
`replication.VerifyReplication`
比较两个不同集群中表的数据。警告:自时间戳更改以来,它不适用于 incrementColumnValues 的单元格。请注意,此命令与其他命令位于不同的程序包中。
除`RowCounter`和`CellCounter`之外的每个命令都接受单个`--help`参数来打印使用说明。
### 150.5。 HBase `hbck`
hbase-1.x 附带的`hbck`工具已在 hbase-2.x 中设置为只读。由于 hbase 内部组件已更改,因此无法修复 hbase-2.x 群集。其只读模式的评估也不应该受到信任,因为它不了解 hbase-2.x 操作。
下一节中描述的新工具 [HBase `HBCK2`](#HBCK2) 取代`hbck`。
### 150.6。 HBase `HBCK2`
`HBCK2`是 [HBase `hbck`](#hbck) 的后继者,hbase-1.x 修复工具(A.K.A `hbck1`)。使用它代替`hbck1`进行 hbase-2.x 安装修复。
`HBCK2`不作为 hbase 的一部分发货。它可以作为 [Apache HBase HBCK2 工具](https://github.com/apache/hbase-operator-tools/tree/master/hbase-hbck2)的伴随 [hbase-operator-tools](https://github.com/apache/hbase-operator-tools) 存储库的子项目找到。 `HBCK2`被移出 hbase,因此除了 hbase 核心之外,它还能以节奏发展。
有关`HBCK2`与`hbck1`的区别,请参阅 [](HBCK2) [https://github.com/apache/hbase-operator-tools/tree/master/hbase-hbck2](https://github.com/apache/hbase-operator-tools/tree/master/hbase-hbck2) 主页,以及如何构建和使用它。
构建完成后,您可以按如下方式运行`HBCK2`:
```
$ hbase hbck -j /path/to/HBCK2.jar
```
这将生成描述命令和选项的`HBCK2`用法。
### 150.7。 HFile 工具
参见 [HFile 工具](#hfile_tool)。
### 150.8。 WAL 工具
#### 150.8.1。 FSHLog 工具
`FSHLog`上的主要方法提供手动拆分和转储设施。传递它 WALs 或分裂的产物, _recover.edits_ 的内容。目录。
您可以通过执行以下操作获取 WAL 文件内容的文本转储:
```
$ ./bin/hbase org.apache.hadoop.hbase.regionserver.wal.FSHLog --dump hdfs://example.org:8020/hbase/WALs/example.org,60020,1283516293161/10.10.21.10%3A60020.1283973724012
```
如果文件有任何问题,返回代码将为非零,因此您可以通过将`STDOUT`重定向到`/dev/null`并测试程序返回来测试文件的健康性。
类似地,您可以通过执行以下操作强制拆分日志文件目录:
```
$ ./bin/hbase org.apache.hadoop.hbase.regionserver.wal.FSHLog --split hdfs://example.org:8020/hbase/WALs/example.org,60020,1283516293161/
```
##### WALPrettyPrinter
`WALPrettyPrinter`是一个带有可配置选项的工具,用于打印 WAL 的内容。您可以使用'wal'命令通过 HBase cli 调用它。
```
$ ./bin/hbase wal hdfs://example.org:8020/hbase/WALs/example.org,60020,1283516293161/10.10.21.10%3A60020.1283973724012
```
> WAL 打印旧版本的 HBase
>
> 在版本 2.0 之前,`WALPrettyPrinter`在 HBase 的预写日志的内部名称之后被称为`HLogPrettyPrinter`。在这些版本中,您可以使用与上面相同的配置打印 WAL 的内容,但使用'hlog'命令。
>
> ```
> $ ./bin/hbase hlog hdfs://example.org:8020/hbase/.logs/example.org,60020,1283516293161/10.10.21.10%3A60020.1283973724012
> ```
### 150.9。压缩工具
见 [compression.test](#compression.test) 。
### 150.10。 CopyTable
CopyTable 是一个实用程序,可以将部分或全部表复制到同一个集群或另一个集群。目标表必须首先存在。用法如下:
```
$ ./bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --help
/bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --help
Usage: CopyTable [general options] [--starttime=X] [--endtime=Y] [--new.name=NEW] [--peer.adr=ADR] <tablename>
Options:
rs.class hbase.regionserver.class of the peer cluster,
specify if different from current cluster
rs.impl hbase.regionserver.impl of the peer cluster,
startrow the start row
stoprow the stop row
starttime beginning of the time range (unixtime in millis)
without endtime means from starttime to forever
endtime end of the time range. Ignored if no starttime specified.
versions number of cell versions to copy
new.name new table's name
peer.adr Address of the peer cluster given in the format
hbase.zookeeer.quorum:hbase.zookeeper.client.port:zookeeper.znode.parent
families comma-separated list of families to copy
To copy from cf1 to cf2, give sourceCfName:destCfName.
To keep the same name, just give "cfName"
all.cells also copy delete markers and deleted cells
Args:
tablename Name of the table to copy
Examples:
To copy 'TestTable' to a cluster that uses replication for a 1 hour window:
$ bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=1265875194289 --endtime=1265878794289 --peer.adr=server1,server2,server3:2181:/hbase --families=myOldCf:myNewCf,cf2,cf3 TestTable
For performance consider the following general options:
It is recommended that you set the following to >=100\. A higher value uses more memory but
decreases the round trip time to the server and may increase performance.
-Dhbase.client.scanner.caching=100
The following should always be set to false, to prevent writing data twice, which may produce
inaccurate results.
-Dmapred.map.tasks.speculative.execution=false
```
> 扫描仪缓存
>
> 输入的缓存扫描通过作业配置中的`hbase.client.scanner.caching`进行配置。
>
> 版
>
> 默认情况下,CopyTable 实用程序仅复制最新版本的行单元格,除非在命令中明确指定了`--versions=n`。
有关`CopyTable`的更多信息,请参阅 Jonathan Hsieh 的[在线 HBase 备份和 CopyTable](https://blog.cloudera.com/blog/2012/06/online-hbase-backups-with-copytable-2/) 博客文章。
### 150.11。哈希表/ SyncTable
HashTable / SyncTable 是一个用于同步表数据的两步工具,其中每个步骤都实现为 MapReduce 作业。与 CopyTable 类似,它可用于在相同或远程群集下进行部分或整个表数据同步。但是,它以比 CopyTable 更有效的方式执行同步。 HashTable(第一步)不是复制指定行键/时间段范围内的所有单元格,而是为源表上的批处理单元格创建散列索引,并将其作为结果输出。在下一个阶段,SyncTable 扫描源表,现在计算表格单元格的哈希索引,将这些哈希值与 HashTable 的输出进行比较,然后只扫描(并比较)单元格以获得不同的哈希值,只更新不匹配的单元格。这样可以减少网络流量/数据传输,这可能会在同步远程群集上的大型表时产生影响。
#### 150.11.1。第 1 步,HashTable
首先,在源表集群上运行 HashTable(这是将其状态复制到其对应表的表)。
用法:
```
$ ./bin/hbase org.apache.hadoop.hbase.mapreduce.HashTable --help
Usage: HashTable [options] <tablename> <outputpath>
Options:
batchsize the target amount of bytes to hash in each batch
rows are added to the batch until this size is reached
(defaults to 8000 bytes)
numhashfiles the number of hash files to create
if set to fewer than number of regions then
the job will create this number of reducers
(defaults to 1/100 of regions -- at least 1)
startrow the start row
stoprow the stop row
starttime beginning of the time range (unixtime in millis)
without endtime means from starttime to forever
endtime end of the time range. Ignored if no starttime specified.
scanbatch scanner batch size to support intra row scans
versions number of cell versions to include
families comma-separated list of families to include
Args:
tablename Name of the table to hash
outputpath Filesystem path to put the output data
Examples:
To hash 'TestTable' in 32kB batches for a 1 hour window into 50 files:
$ bin/hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=50 --starttime=1265875194289 --endtime=1265878794289 --families=cf2,cf3 TestTable /hashes/testTable
```
**batchsize** 属性定义在单个散列值中将给定区域的单元数据散列在一起的程度。正确调整大小会对同步效率产生直接影响,因为它可能会导致 SyncTable 的映射器任务执行的扫描次数减少(该过程的下一步)。经验法则是,不同步的单元数量越少(找到差异的概率越低),可以确定更大的批量大小值。
#### 150.11.2。第 2 步,SyncTable
在源群集上完成 HashTable 后,可以在目标群集上运行 SyncTable。就像复制和其他同步作业一样,它要求源集群上的所有 RegionServers / DataNode 都可以由目标集群上的 NodeManagers 访问(其中将运行 SyncTable 作业任务)。
Usage:
```
$ ./bin/hbase org.apache.hadoop.hbase.mapreduce.SyncTable --help
Usage: SyncTable [options] <sourcehashdir> <sourcetable> <targettable>
Options:
sourcezkcluster ZK cluster key of the source table
(defaults to cluster in classpath's config)
targetzkcluster ZK cluster key of the target table
(defaults to cluster in classpath's config)
dryrun if true, output counters but no writes
(defaults to false)
doDeletes if false, does not perform deletes
(defaults to true)
doPuts if false, does not perform puts
(defaults to true)
Args:
sourcehashdir path to HashTable output dir for source table
(see org.apache.hadoop.hbase.mapreduce.HashTable)
sourcetable Name of the source table to sync from
targettable Name of the target table to sync to
Examples:
For a dry run SyncTable of tableA from a remote source cluster
to a local target cluster:
$ bin/hbase org.apache.hadoop.hbase.mapreduce.SyncTable --dryrun=true --sourcezkcluster=zk1.example.com,zk2.example.com,zk3.example.com:2181:/hbase hdfs://nn:9000/hashes/tableA tableA tableA
```
当需要只读,差异报告时, **dryrun** 选项很有用,因为它只会产生指示差异的 COUNTERS,但不会执行任何实际更改。它可以用作 VerifyReplication 工具的替代方案。
默认情况下,SyncTable 将使目标表成为源表的精确副本(至少,对于指定的 startrow / stoprow 或/和 starttime / endtime)。
将 doDeletes 设置为 false 会修改默认行为,以便不删除源上缺少的目标单元格。同样,将 doPuts 设置为 false 会修改默认行为,以便不在目标上添加缺少的单元格。将 doDeletes 和 doPuts 都设置为 false 会产生与将 dryrun 设置为 true 相同的效果。
> 在双向复制方案中将 doDeletes 设置为 false
>
> 在双向复制或源集群和目标集群都可以获取数据的其他情况下,建议始终将 doDeletes 选项设置为 false,因为在 SyncTable 目标集群上插入但尚未复制到源的任何其他单元格将被删除,并且可能永远失去了。
>
> 将 sourcezkcluster 设置为实际源群集 ZK quoru
>
> 虽然不是必需的,但如果未设置 sourcezkcluster,则 SyncTable 将连接到源和目标的本地 HBase 集群,这不会产生任何有意义的结果。
>
> 不同 Kerberos 领域的远程集群
>
> 目前,无法为不同 Kerberos 领域上的远程群集运行 SyncTable。有一些工作要在 [HBASE-20586](https://jira.apache.org/jira/browse/HBASE-20586) 上解决这个问题
### 150.12。出口
Export 是一个实用程序,它将表的内容转储到序列文件中的 HDFS。可以通过协处理器端点或 MapReduce 运行导出。通过以下方式调用
**基于 mapreduce 的出口**
```
$ bin/hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir> [<versions> [<starttime> [<endtime>]]]
```
**基于端点的导出**
> 通过将`org.apache.hadoop.hbase.coprocessor.Export`添加到`hbase.coprocessor.region.classes`,确保启用了导出协处理器。
```
$ bin/hbase org.apache.hadoop.hbase.coprocessor.Export <tablename> <outputdir> [<versions> [<starttime> [<endtime>]]]
```
outputdir 是导出前不存在的 HDFS 目录。完成后,导出的文件将由调用导出命令的用户拥有。
**基于端点的导出和基于 Mapreduce 的导出的比较**
| | 基于端点的导出 | 基于 Mapreduce 的导出 |
| --- | --- | --- |
| HBase 版本要求 | 2.0+ | 0.2.1+ |
| Maven 依赖 | HBase 的端点 | hbase-mapreduce(2.0 +),hbase-server(2.0 之前) |
| 转储前的要求 | 在目标表上挂载 endpoint.Export | 部署 MapReduce 框架 |
| 读延迟 | 低,直接从区域读取数据 | 传统的 RPC 扫描 |
| 读可伸缩性 | 取决于地区的数量 | 取决于映射器的数量(请参阅 TableInputFormatBase #getSplits) |
| 超时 | 操作超时。由 hbase.client.operation.timeout 配置 | 扫描超时。由 hbase.client.scanner.timeout.period 配置 |
| 许可要求 | 阅读,执行 | 读 |
| 容错 | 没有 | 取决于 MapReduce |
> 要查看使用说明,请运行不带任何选项的命令。可用选项包括指定列族和导出期间应用过滤器。
默认情况下,`Export`工具仅导出给定单元格的最新版本,而不管存储的版本数量。要导出多个版本,请用所需的版本数替换。
注意:输入扫描的缓存是通过作业配置中的`hbase.client.scanner.caching`配置的。
### 150.13。进口
Import 是一个实用程序,它将加载已导出回 HBase 的数据。通过以下方式调用
```
$ bin/hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>
```
> 要查看使用说明,请运行不带任何选项的命令。
要在 0.96 群集中或之后导入 0.94 导出的文件,您需要在运行导入命令时设置系统属性“hbase.import.version”,如下所示:
```
$ bin/hbase -Dhbase.import.version=0.94 org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>
```
### 150.14。 ImportTsv
ImportTsv 是一个实用程序,它将 TSV 格式的数据加载到 HBase 中。它有两个不同的用法:通过 Puts 将数据从 HDFS 中的 TSV 格式加载到 HBase 中,并准备通过`completebulkload`加载 StoreFiles。
通过 Puts 加载数据(即非批量加载):
```
$ bin/hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns=a,b,c <tablename> <hdfs-inputdir>
```
要生成 StoreFiles 以进行批量加载:
```
$ bin/hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns=a,b,c -Dimporttsv.bulk.output=hdfs://storefile-outputdir <tablename> <hdfs-data-inputdir>
```
这些生成的 StoreFiles 可以通过 [completebulkload](#completebulkload) 加载到 HBase 中。
#### 150.14.1。 ImportTsv 选项
不带参数运行`ImportTsv`会打印简要的用法信息:
```
Usage: importtsv -Dimporttsv.columns=a,b,c <tablename> <inputdir>
Imports the given input directory of TSV data into the specified table.
The column names of the TSV data must be specified using the -Dimporttsv.columns
option. This option takes the form of comma-separated column names, where each
column name is either a simple column family, or a columnfamily:qualifier. The special
column name HBASE_ROW_KEY is used to designate that this column should be used
as the row key for each imported record. You must specify exactly one column
to be the row key, and you must specify a column name for every column that exists in the
input data.
By default importtsv will load data directly into HBase. To instead generate
HFiles of data to prepare for a bulk data load, pass the option:
-Dimporttsv.bulk.output=/path/for/output
Note: the target table will be created with default column family descriptors if it does not already exist.
Other options that may be specified with -D include:
-Dimporttsv.skip.bad.lines=false - fail if encountering an invalid line
'-Dimporttsv.separator=|' - eg separate on pipes instead of tabs
-Dimporttsv.timestamp=currentTimeAsLong - use the specified timestamp for the import
-Dimporttsv.mapper.class=my.Mapper - A user-defined Mapper to use instead of org.apache.hadoop.hbase.mapreduce.TsvImporterMapper
```
#### 150.14.2。 ImportTsv 示例
例如,假设我们将数据加载到名为'datatsv'的表中,其中 ColumnFamily 称为'd',其中包含两列“c1”和“c2”。
假设输入文件存在如下:
```
row1 c1 c2
row2 c1 c2
row3 c1 c2
row4 c1 c2
row5 c1 c2
row6 c1 c2
row7 c1 c2
row8 c1 c2
row9 c1 c2
row10 c1 c2
```
要使 ImportTsv 使用此输入文件,命令行需要如下所示:
```
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/hbase-mapreduce-VERSION.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,d:c1,d:c2 -Dimporttsv.bulk.output=hdfs://storefileoutput datatsv hdfs://inputfile
```
...在本例中,第一列是 rowkey,这就是使用 HBASE_ROW_KEY 的原因。文件中的第二列和第三列将分别导入为“d:c1”和“d:c2”。
#### 150.14.3。 ImportTsv 警告
如果您准备了大量数据以进行批量加载,请确保对目标 HBase 表进行适当的预分割。
#### 150.14.4。也可以看看
有关将 HFiles 批量加载到 HBase 中的更多信息,请参见 [arch.bulk.load](#arch.bulk.load)
### 150.15。 CompleteBulkLoad
`completebulkload`实用程序会将生成的 StoreFiles 移动到 HBase 表中。该实用程序通常与 [importtsv](#importtsv) 的输出结合使用。
有两种方法可以通过显式类名和驱动程序调用此实用程序:
显式类名
```
$ bin/hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles <hdfs://storefileoutput> <tablename>
```
司机
```
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/hbase-server-VERSION.jar completebulkload <hdfs://storefileoutput> <tablename>
```
#### 150.15.1。 CompleteBulkLoad 警告
通过 MapReduce 生成的数据通常使用与正在运行的 HBase 进程不兼容的文件权限创建。假设您在启用权限的情况下运行 HDFS,则需要在运行 CompleteBulkLoad 之前更新这些权限。
有关将 HFile 批量加载到 HBase 中的更多信息,请参见 [arch.bulk.load](#arch.bulk.load) 。
### 150.16。 WALPlayer
WALPlayer 是一个将 WAL 文件重放到 HBase 中的实用程序。
可以为一组表或所有表重放 WAL,并且可以提供时间范围(以毫秒为单位)。 WAL 被过滤到这组表。输出可以选择性地映射到另一组表。
WALPlayer 还可以生成 HFile 以供以后批量导入,在这种情况下,只能指定一个表,并且不能指定映射。
通过以下方式调用
```
$ bin/hbase org.apache.hadoop.hbase.mapreduce.WALPlayer [options] <wal inputdir> <tables> [<tableMappings>]>
```
例如:
```
$ bin/hbase org.apache.hadoop.hbase.mapreduce.WALPlayer /backuplogdir oldTable1,oldTable2 newTable1,newTable2
```
默认情况下,WALPlayer 作为 mapreduce 作业运行。若要不将 WALPlayer 作为集群上的 mapreduce 作业运行,请通过在命令行上添加标志`-Dmapreduce.jobtracker.address=local`来强制它在本地进程中运行。
#### 150.16.1。 WALPlayer 选项
不带参数运行`WALPlayer`会打印简要的用法信息:
```
Usage: WALPlayer [options] <wal inputdir> <tables> [<tableMappings>]
Replay all WAL files into HBase.
<tables> is a comma separated list of tables.
If no tables ("") are specified, all tables are imported.
(Be careful, hbase:meta entries will be imported in this case.)
WAL entries can be mapped to new set of tables via <tableMappings>.
<tableMappings> is a comma separated list of target tables.
If specified, each table in <tables> must have a mapping.
By default WALPlayer will load data directly into HBase.
To generate HFiles for a bulk data load instead, pass the following option:
-Dwal.bulk.output=/path/for/output
(Only one table can be specified, and no mapping is allowed!)
Time range options:
-Dwal.start.time=[date|ms]
-Dwal.end.time=[date|ms]
(The start and the end date of timerange. The dates can be expressed
in milliseconds since epoch or in yyyy-MM-dd'T'HH:mm:ss.SS format.
E.g. 1234567890120 or 2009-02-13T23:32:30.12)
Other options:
-Dmapreduce.job.name=jobName
Use the specified mapreduce job name for the wal player
For performance also consider the following options:
-Dmapreduce.map.speculative=false
-Dmapreduce.reduce.speculative=false
```
### 150.17。 RowCounter
[RowCounter](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/mapreduce/RowCounter.html) 是一个 mapreduce 作业,用于计算表的所有行。这是一个很好的实用程序,可用作健全性检查,以确保如果存在元数据不一致的问题,HBase 可以读取表的所有块。它将在一个进程中运行 mapreduce,但如果你有一个 MapReduce 集群可以利用它,它将运行得更快。可以使用`--starttime=[starttime]`和`--endtime=[endtime]`标志限制要扫描的数据的时间范围。可以使用`--range=[startKey],[endKey][;[startKey],[endKey]…]`选项基于键限制扫描数据。
```
$ bin/hbase rowcounter [options] <tablename> [--starttime=<start> --endtime=<end>] [--range=[startKey],[endKey][;[startKey],[endKey]...]] [ ...]
```
RowCounter 每个单元只计算一个版本。
性能考虑使用`-Dhbase.client.scanner.caching=100`和`-Dmapreduce.map.speculative=false`选项。
### 150.18。 CellCounter
HBase 发布了另一个叫做 [CellCounter](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/mapreduce/CellCounter.html) 的诊断 mapreduce 工作。与 RowCounter 一样,它收集有关您的表的更细粒度的统计信息。 CellCounter 收集的统计数据更精细,包括:
* 表中的总行数。
* 所有行中的 CF 总数。
* 所有行的总限定符。
* 每个 CF 的总发生次数。
* 每个限定符的总出现次数。
* 每个限定符的版本总数。
该程序允许您限制运行的范围。提供行正则表达式或前缀以限制要分析的行。使用`--starttime=<starttime>`和`--endtime=<endtime>`标志指定扫描表的时间范围。
使用`hbase.mapreduce.scan.column.family`指定扫描单列族。
```
$ bin/hbase cellcounter <tablename> <outputDir> [reportSeparator] [regex or prefix] [--starttime=<starttime> --endtime=<endtime>]
```
注意:就像 RowCounter 一样,输入的缓存扫描是通过作业配置中的`hbase.client.scanner.caching`配置的。
### 150.19。 mlockall 用于
通过让服务器在启动时调用 [mlockall](http://linux.die.net/man/2/mlockall) ,可以选择将服务器固定在物理内存中,从而降低在超额订阅环境中换出的可能性。参见 [HBASE-4391 添加以 root 身份启动 RS 的功能,并调用 mlockall](https://issues.apache.org/jira/browse/HBASE-4391) 了解如何构建可选库并使其在启动时运行。
### 150.20。离线压缩工具
**CompactionTool** 提供了一种运行压缩(次要或主要)作为 RegionServer 的独立进程的方法。它重用了 RegionServer 压缩功能执行的相同内部实现类。但是,由于它在一个完全独立的独立 java 进程上运行,因此它会从重写一组 hfiles 所涉及的开销中释放 RegionServers,这对于延迟敏感的用例非常重要。
Usage:
```
$ ./bin/hbase org.apache.hadoop.hbase.regionserver.CompactionTool
Usage: java org.apache.hadoop.hbase.regionserver.CompactionTool \
[-compactOnce] [-major] [-mapred] [-D<property=value>]* files...
Options:
mapred Use MapReduce to run compaction.
compactOnce Execute just one compaction step. (default: while needed)
major Trigger major compaction.
Note: -D properties will be applied to the conf used.
For example:
To stop delete of compacted file, pass -Dhbase.compactiontool.delete=false
To set tmp dir, pass -Dhbase.tmp.dir=ALTERNATE_DIR
Examples:
To compact the full 'TestTable' using MapReduce:
$ hbase org.apache.hadoop.hbase.regionserver.CompactionTool -mapred hdfs://hbase/data/default/TestTable
To compact column family 'x' of the table 'TestTable' region 'abc':
$ hbase org.apache.hadoop.hbase.regionserver.CompactionTool hdfs://hbase/data/default/TestTable/abc/x
```
如上面的使用选项所示, **CompactionTool** 可以作为独立客户端或 mapreduce 作业运行。当作为 mapreduce 作业运行时,每个族目录都作为输入拆分处理,并由单独的映射任务处理。
**compactionOnce** 参数控制在 **CompactionTool** 程序决定完成其工作之前将执行多少次压缩循环。如果省略,它将假定它应该在每个指定的族上继续运行压缩,这由配置的给定压缩策略确定。有关压缩策略的更多信息,请参阅[压缩](#compaction)。
如果需要进行主要压实,可以指定**主要**标志。如果省略, **CompactionTool** 将假定默认需要较小的压缩。
它还允许使用`-D`标志进行配置覆盖。例如,在上面的使用部分中,`-Dhbase.compactiontool.delete=false`选项将指示压缩引擎不从 temp 文件夹中删除原始文件。
必须将目标为压缩的文件指定为父 hdfs dirs。它允许多个 dirs 定义,只要这些 dirs 的每一个都是**家族**,**区域**或**表** dir。如果传递了表或区域目录,程序将递归遍历相关的子文件夹,有效地为表/区域级别下面的每个族运行压缩。
由于这些目录嵌套在 **hbase** hdfs 目录树下, **CompactionTool** 需要 hbase 超级用户权限才能访问所需的 hfiles。
> 在 MapReduce mod 中运行
>
> MapReduce 模式提供了并行处理每个族目录的功能,作为单独的地图任务。通常,在指定一个或多个表目录作为压缩目标时,以此模式运行是有意义的。但需要注意的是,如果要压缩的族数变得太大,相关的 mapreduce 工作可能会对 **RegionServers** 的性能产生间接影响。由于 **NodeManagers** 通常与 RegionServers 共存,因此这些大型作业可能会与 **RegionServers** 竞争 IO /带宽资源。
>
> 由于性能影响,MajorSeraction 在 RegionServers 上完全禁用
>
> **主要压缩**可能是一项代价高昂的操作(参见[压缩](#compaction)),并且确实可以影响 RegionServers 的性能,导致运营商完全禁用它以用于关键的低延迟应用。 **CompactionTool** 可以在这种情况下用作替代方案,但是,需要实现额外的自定义应用程序逻辑,例如决定给定压缩运行的表/区域/族目标的调度和选择。
有关 CompactionTool 的其他详细信息,另请参阅 [CompactionTool](https://hbase.apache.org/devapidocs/org/apache/hadoop/hbase/regionserver/CompactionTool.html) 。
### 150.21。 `hbase clean`
`hbase clean`命令清除 ZooKeeper,HDFS 或两者中的 HBase 数据。适合用于测试。运行它没有使用说明选项。 `hbase clean`命令在 HBase 0.98 中引入。
```
$ bin/hbase clean
Usage: hbase clean (--cleanZk|--cleanHdfs|--cleanAll)
Options:
--cleanZk cleans hbase related data from zookeeper.
--cleanHdfs cleans hbase related data from hdfs.
--cleanAll cleans hbase related data from both zookeeper and hdfs.
```
### 150.22。 `hbase pe`
`hbase pe`命令运行 PerformanceEvaluation 工具,该工具用于测试。
PerformanceEvaluation 工具接受许多不同的选项和命令。有关使用说明,请运行不带任何选项的命令。
PerformanceEvaluation 工具在最近的 HBase 版本中收到了许多更新,包括对命名空间的支持,对标签的支持,单元级 ACL 和可见性标签,对 RPC 调用的多重支持,增加的采样大小,在测试期间随机休眠的选项以及能力在测试开始之前“预热”集群。
### 150.23。 `hbase ltt`
`hbase ltt`命令运行 LoadTestTool 实用程序,该实用程序用于测试。
您必须指定`-init_only`或`-write`,`-update`或`-read`中的至少一个。有关一般使用说明,请传递`-h`选项。
LoadTestTool 在最近的 HBase 版本中收到了许多更新,包括对命名空间的支持,对标签的支持,单元级 ACLS 和可见性标签,测试安全相关功能,指定每台服务器的区域数量的能力,多次获取 RPC 的测试呼叫和与复制有关的测试。
### 150.24。升级前验证程序
在从 HBase 1 升级到 HBase 2 之前,可以使用升级前验证工具检查群集是否存在已知的不兼容性。
```
$ bin/hbase pre-upgrade command ...
```
#### 150.24.1。协处理器验证
HBase 长期支持协处理器,但协处理器 API 可以在主要版本之间进行更改。协处理器验证器尝试确定旧的协处理器是否仍与实际的 HBase 版本兼容。
```
$ bin/hbase pre-upgrade validate-cp [-jar ...] [-class ... | -table ... | -config]
Options:
-e Treat warnings as errors.
-jar <arg> Jar file/directory of the coprocessor.
-table <arg> Table coprocessor(s) to check.
-class <arg> Coprocessor class(es) to check.
-config Scan jar for observers.
```
协处理器类可以通过`-class`选项显式声明,也可以通过`-config`选项从 HBase 配置中获取。表级协处理器也可以通过`-table`选项进行检查。该工具在其类路径上搜索协处理器,但可以通过`-jar`选项进行扩展。可以使用多个`-class`测试多个类,使用多个`-table`选项测试多个表,并使用多个`-jar`选项将多个 jar 添加到类路径中。
该工具可以报告错误和警告。错误意味着 HBase 将无法加载协处理器,因为它与当前版本的 HBase 不兼容。警告意味着可以加载协处理器,但它们无法按预期工作。如果给出`-e`选项,则该工具也将失败以发出警告。
请注意,此工具无法验证 jar 文件的每个方面,它只是进行一些静态检查。
For example:
```
$ bin/hbase pre-upgrade validate-cp -jar my-coprocessor.jar -class MyMasterObserver -class MyRegionObserver
```
它验证位于`my-coprocessor.jar`中的`MyMasterObserver`和`MyRegionObserver`类。
```
$ bin/hbase pre-upgrade validate-cp -table .*
```
它验证表名与`.*`正则表达式匹配的每个表级协处理器。
#### 150.24.2。 DataBlockEncoding 验证
HBase 2.0 从列族中删除了`PREFIX_TREE`数据块编码。有关详细信息,请检查 [_ 前缀树 _ 编码已删除](#upgrade2.0.prefix-tree.removed)。要验证没有任何列族在群集中使用不兼容的数据块编码,请运行以下命令。
```
$ bin/hbase pre-upgrade validate-dbe
```
此检查验证所有列族并打印出任何不兼容性。例如:
```
2018-07-13 09:58:32,028 WARN [main] tool.DataBlockEncodingValidator: Incompatible DataBlockEncoding for table: t, cf: f, encoding: PREFIX_TREE
```
这意味着表`t`,列族`f`的数据块编码不兼容。要修复,请在 HBase shell 中使用`alter`命令:
```
alter 't', { NAME => 'f', DATA_BLOCK_ENCODING => 'FAST_DIFF' }
```
还请验证 HFiles,这将在下一节中介绍。
#### 150.24.3。 HFile 内容验证
即使数据块编码从`PREFIX_TREE`更改,仍然可能有包含以这种方式编码的数据的 HFile。要验证 HFiles 是否可用 HBase 2 读取,请使用 _HFile 内容验证器 _。
```
$ bin/hbase pre-upgrade validate-hfile
```
该工具将记录损坏的 HFile 和有关根本原因的详细信息。如果问题与 PREFIX_TREE 编码有关,则必须在升级到 HBase 2 之前更改编码。
以下日志消息显示错误 HFile 的示例。
```
2018-06-05 16:20:46,976 WARN [hfilevalidator-pool1-t3] hbck.HFileCorruptionChecker: Found corrupt HFile hdfs://example.com:8020/hbase/data/default/t/72ea7f7d625ee30f959897d1a3e2c350/prefix/7e6b3d73263c4851bf2b8590a9b3791e
org.apache.hadoop.hbase.io.hfile.CorruptHFileException: Problem reading HFile Trailer from file hdfs://example.com:8020/hbase/data/default/t/72ea7f7d625ee30f959897d1a3e2c350/prefix/7e6b3d73263c4851bf2b8590a9b3791e
...
Caused by: java.io.IOException: Invalid data block encoding type in file info: PREFIX_TREE
...
Caused by: java.lang.IllegalArgumentException: No enum constant org.apache.hadoop.hbase.io.encoding.DataBlockEncoding.PREFIX_TREE
...
2018-06-05 16:20:47,322 INFO [main] tool.HFileContentValidator: Corrupted file: hdfs://example.com:8020/hbase/data/default/t/72ea7f7d625ee30f959897d1a3e2c350/prefix/7e6b3d73263c4851bf2b8590a9b3791e
2018-06-05 16:20:47,383 INFO [main] tool.HFileContentValidator: Corrupted file: hdfs://example.com:8020/hbase/archive/data/default/t/56be41796340b757eb7fff1eb5e2a905/f/29c641ae91c34fc3bee881f45436b6d1
```
##### 修复 PREFIX_TREE 错误
将数据块编码更改为支持的数据块编码后,可能会出现`PREFIX_TREE`错误。之所以会发生这种情况,是因为有些 HFile 仍然使用`PREFIX_TREE`进行编码,或者仍有一些快照。
为了修复 HFiles,请在表上运行一个主要的压缩(根据日志消息它是`default:t`):
```
major_compact 't'
```
HFile 也可以从快照中引用。当 HFile 位于`archive/data`下时就是这种情况。第一步是根据日志确定哪些快照引用 HFile(文件名是`29c641ae91c34fc3bee881f45436b6d1`):
```
for snapshot in $(hbase snapshotinfo -list-snapshots 2> /dev/null | tail -n -1 | cut -f 1 -d \|);
do
echo "checking snapshot named '${snapshot}'";
hbase snapshotinfo -snapshot "${snapshot}" -files 2> /dev/null | grep 29c641ae91c34fc3bee881f45436b6d1;
done
```
这个 shell 脚本的输出是:
```
checking snapshot named 't_snap'
1.0 K t/56be41796340b757eb7fff1eb5e2a905/f/29c641ae91c34fc3bee881f45436b6d1 (archive)
```
这意味着`t_snap`快照引用了不兼容的 HFile。如果仍然需要快照,则必须使用 HBase shell 重新创建快照:
```
# creating a new namespace for the cleanup process
create_namespace 'pre_upgrade_cleanup'
# creating a new snapshot
clone_snapshot 't_snap', 'pre_upgrade_cleanup:t'
alter 'pre_upgrade_cleanup:t', { NAME => 'f', DATA_BLOCK_ENCODING => 'FAST_DIFF' }
major_compact 'pre_upgrade_cleanup:t'
# removing the invalid snapshot
delete_snapshot 't_snap'
# creating a new snapshot
snapshot 'pre_upgrade_cleanup:t', 't_snap'
# removing temporary table
disable 'pre_upgrade_cleanup:t'
drop 'pre_upgrade_cleanup:t'
drop_namespace 'pre_upgrade_cleanup'
```
有关详细信息,请参阅 [HBASE-20649](https://issues.apache.org/jira/browse/HBASE-20649?focusedCommentId=16535476#comment-16535476) 。
### 150.25。数据块编码工具
使用不同的数据块编码器测试各种压缩算法,以便在现有的 HFile 上进行密钥压缩。用于测试,调试和基准测试。
您必须指定`-f`,这是 HFile 的完整路径。
结果显示了压缩/解压缩和编码/解码的性能(MB / s),以及 HFile 上的数据节省。
```
$ bin/hbase org.apache.hadoop.hbase.regionserver.DataBlockEncodingTool
Usages: hbase org.apache.hadoop.hbase.regionserver.DataBlockEncodingTool
Options:
-f HFile to analyse (REQUIRED)
-n Maximum number of key/value pairs to process in a single benchmark run.
-b Whether to run a benchmark to measure read throughput.
-c If this is specified, no correctness testing will be done.
-a What kind of compression algorithm use for test. Default value: GZ.
-t Number of times to run each benchmark. Default value: 12.
-omit Number of first runs of every benchmark to omit from statistics. Default value: 2.
```
## 151.区域管理
### 151.1。主要压实
可以通过 HBase shell 或 [Admin.majorCompact](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/Admin.html#majorCompact-org.apache.hadoop.hbase.TableName-) 请求主要压缩。
注意:主要压缩不进行区域合并。有关压缩的更多信息,请参见[压缩](#compaction)。
### 151.2。合并
Merge 是一个可以合并同一个表中相邻区域的实用程序(请参阅 org.apache.hadoop.hbase.util.Merge)。
```
$ bin/hbase org.apache.hadoop.hbase.util.Merge <tablename> <region1> <region2>
```
如果您觉得自己拥有太多区域并希望对它们进行整合,那么 Merge 就是您需要的实用程序。必须在群集关闭时运行合并。有关用法示例,请参阅 [O'Reilly HBase Book](https://web.archive.org/web/20111231002503/http://ofps.oreilly.com/titles/9781449396107/performance.html) 。
您需要将 3 个参数传递给此应用程序。第一个是表名。第二个是要合并的第一个区域的完全限定名称,例如“table_name,\ x0A,1342956111995.7cef47f192318ba7ccc75b1bbf27a82b。”。第三个是要合并的第二个区域的完全限定名称。
此外,还有一个 Ruby 脚本附加到 [HBASE-1621](https://issues.apache.org/jira/browse/HBASE-1621) 以进行区域合并。
## 152.节点管理
### 152.1。节点退役
您可以通过在特定节点上的 HBase 目录中运行以下脚本来停止单个 RegionServer:
```
$ ./bin/hbase-daemon.sh stop regionserver
```
RegionServer 将首先关闭所有区域,然后自行关闭。关闭时,ZooKeeper 中 RegionServer 的临时节点将过期。主人会注意到 RegionServer 已经消失,并将其视为“崩溃”的服务器;它将重新分配 RegionServer 携带的节点。
> 在退役之前禁用负载均衡器
>
> 如果负载均衡器在节点关闭时运行,那么负载均衡器和主服务器恢复刚刚停用的 RegionServer 之间可能存在争用。首先禁用平衡器,避免任何问题。见下面的 [lb](#lb) 。
>
> 杀死节点
>
> 在 hbase-2.0 中,在 bin 目录中,我们添加了一个名为 _ConsideAsDead.sh_ 的脚本,可用于杀死 regionserver。在 zookeeper 超时到期之前,专用监视工具可以检测到硬件问题。 _ 考虑 AsDead.sh_ 是一个将 RegionServer 标记为死的简单函数。它删除服务器的所有 znode,开始恢复过程。将脚本插入监视/故障检测工具以启动更快的故障转移。小心如何使用这种破坏性工具。如果需要在 hbase-2.0 之前的 hbase 版本中使用它,请复制脚本。
上述区域服务器停止的一个缺点是区域可能会在很长一段时间内脱机。地区按顺序关闭。如果服务器上有许多区域,则关闭的第一个区域可能不会重新联机,直到所有区域关闭并且在主站注意到 RegionServer 的 znode 消失之后。在 Apache HBase 0.90.2 中,我们添加了一个设备,让节点逐渐减少负载,然后关闭自己。 Apache HBase 0.90.2 添加了 _graceful _stop.sh_ 脚本。这是它的用法:
```
$ ./bin/graceful_stop.sh
Usage: graceful_stop.sh [--config &conf-dir>] [--restart] [--reload] [--thrift] [--rest] &hostname>
thrift If we should stop/start thrift before/after the hbase stop/start
rest If we should stop/start rest before/after the hbase stop/start
restart If we should restart after graceful stop
reload Move offloaded regions back on to the stopped server
debug Move offloaded regions back on to the stopped server
hostname Hostname of server we are to stop
```
要停用已加载的 RegionServer,请运行以下命令:$ ./bin/graceful_stop.sh HOSTNAME 其中`HOSTNAME`是承载您将停用的 RegionServer 的主机。
> 在'HOSTNAME 上
>
> 传递给 _graceful _stop.sh_ 的`HOSTNAME`必须与 hbase 用于识别 RegionServers 的主机名匹配。检查主 UI 中的 RegionServers 列表,了解 HBase 如何引用服务器。它通常是主机名,但也可以是 FQDN。无论 HBase 使用什么,这都应该通过 _graceful _stop.sh_ 解除授权脚本。如果您传递 IP,则该脚本还不够智能,无法创建它的主机名(或 FQDN),因此在检查服务器当前是否正在运行时它将失败;优雅的地区卸货将无法运行。
_graceful _stop.sh_ 脚本将一次一个地移出退役的 RegionServer 区域,以最大限度地减少区域流失。它将在移动下一个区域之前验证在新位置部署的区域,依此类推,直到退役的服务器携带零区域。此时,_graceful _stop.sh_ 告诉 RegionServer `stop`。此时主服务器会注意到 RegionServer 已经消失但所有区域都已经重新部署,并且因为 RegionServer 干净利落,所以没有 WAL 日志可以拆分。
> 负载均衡器
>
> 假设在`graceful_stop`脚本运行时禁用了区域负载平衡器(否则平衡器和解除授权脚本将最终争夺区域部署)。使用 shell 禁用平衡器:
>
> ```
> hbase(main):001:0> balance_switch false
> true
> 0 row(s) in 0.3590 seconds
> ```
>
> 这会关闭平衡器。要启用,请执行:
>
> ```
> hbase(main):001:0> balance_switch true
> false
> 0 row(s) in 0.3590 seconds
> ```
>
> `graceful_stop`将检查平衡器,如果启用,将在其开始工作前将其关闭。如果由于错误而提前退出,则不会重置平衡器。因此,除了`graceful_stop`在完成 w / graceful_stop 之后重新启用平衡器之外,最好还是管理平衡器。
#### 152.1.1。同时停用多个 Regions 服务器
如果您有一个大型群集,则可能希望通过同时正常停止多个 RegionServers 来同时停用多台计算机。为了同时优雅地排空多个区域服务器,可以将 RegionServers 置于“排空”状态。这是通过在 _hbase _root / draining_ znode 下的 ZooKeeper 中创建一个条目,将 RegionServer 标记为引出节点来完成的。这个 znode 的格式`name,port,startcode`就像 _hbase _root / rs_ znode 下的 regionserver 条目一样。
没有这种设施,退出多个节点可能是非最佳的,因为从一个区域服务器排出的区域可能被移动到也正在耗尽的其他区域服务器。将 RegionServers 标记为处于排水状态会阻止这种情况发生。有关详细信息,请参阅[博客文章](http://inchoate-clatter.blogspot.com/2012/03/hbase-ops-automation.html)。
#### 152.1.2。坏或失败的磁盘
如果在磁盘普通模具的情况下每台机器有相当数量的磁盘,那么设置 [dfs.datanode.failed.volumes.tolerated](#dfs.datanode.failed.volumes.tolerated) 就可以了。但通常磁盘会执行“John Wayne” - 即在 _dmesg_ 中花费一段时间来减少喷射错误 - 或者由于某种原因,运行速度比他们的同伴慢得多。在这种情况下,您希望停用磁盘。你有两个选择。您可以[停用 datanode](https://wiki.apache.org/hadoop/FAQ#I_want_to_make_a_large_cluster_smaller_by_taking_out_a_bunch_of_nodes_simultaneously._How_can_this_be_done.3F) ,或者破坏性较小,因为只有坏磁盘数据会被重新复制,可以停止 datanode,卸载坏卷(在 datanode 使用它时你无法卸载卷) ,然后重新启动 datanode(假设您已设置 dfs.datanode.failed.volumes.tolerated&gt; 0)。区域服务器会在其日志中抛出一些错误,因为它会重新校准从哪里获取数据 - 它也可能会滚动其 WAL 日志 - 但总的来说,但是对于某些延迟峰值,它应该继续保持正常运行。
> 短路读
>
> 如果您正在进行短路读取,则必须在停止 datanode 之前将区域移出 regionserver;当短路读取时,虽然 chmod'd 区域服务器无法访问,因为它已经打开文件,即使 datanode 已关闭,它也能够继续从坏磁盘读取文件块。重新启动 datanode 后,将区域移回。
### 152.2。滚动重启
某些群集配置更改需要重新启动整个群集或 RegionServers 才能获取更改。此外,支持滚动重新启动以升级到次要版本或维护版本,如果可能的话,还支持主要版本。请参阅要升级到的发行版的发行说明,以了解执行滚动升级的能力限制。
根据您的具体情况,有多种方法可以重新启动群集节点。这些方法详述如下。
#### 152.2.1。使用`rolling-restart.sh`脚本
HBase 附带一个脚本 _bin / rolling-restart.sh_ ,它允许您在整个集群,仅主服务器或 RegionServers 上执行滚动重新启动。该脚本作为您自己脚本的模板提供,未经过明确测试。它需要配置无密码的 SSH 登录,并假定您已使用 tarball 进行部署。该脚本要求您在运行之前设置一些环境变量。检查脚本并根据需要进行修改。
_rolling-restart.sh_ 一般用法
```
$ ./bin/rolling-restart.sh --help
Usage: rolling-restart.sh [--config <hbase-confdir>] [--rs-only] [--master-only] [--graceful] [--maxthreads xx]
```
仅在 RegionServers 上滚动重新启动
要仅在 RegionServers 上执行滚动重新启动,请使用`--rs-only`选项。如果您需要重新启动单个 RegionServer,或者进行仅影响 RegionServers 而不影响其他 HBase 进程的配置更改,则可能需要执行此操作。
仅在 Masters 上滚动重启
要在活动和备份主站上执行滚动重新启动,请使用`--master-only`选项。如果您知道配置更改仅影响主服务器而不影响 RegionServers,或者您需要重新启动运行主服务器的服务器,则可以使用此方法。
优雅的重启
如果指定`--graceful`选项,则使用 _bin / graceful _stop.sh_ 脚本重新启动 RegionServers,该脚本会在重新启动 RegionServer 之前将区域移出 RegionServer。这样更安全,但可以延迟重启。
限制线程数
要将滚动重启限制为仅使用特定数量的线程,请使用`--maxthreads`选项。
#### 152.2.2。手动滚动重启
要保留对流程的更多控制,您可能希望在群集中手动执行滚动重新启动。这使用`graceful-stop.sh`命令[退役](#decommission)。在此方法中,您可以单独重新启动每个 RegionServer,然后将其旧区域移回原位,保留位置。如果还需要重新启动主服务器,则需要单独执行此操作,并在使用此方法重新启动 RegionServers 之前重新启动主服务器。以下是此类命令的示例。您可能需要根据您的环境进行定制。此脚本仅对 RegionServers 进行滚动重新启动。它在移动区域之前禁用负载平衡器。
```
$ for i in `cat conf/regionservers|sort`; do ./bin/graceful_stop.sh --restart --reload --debug $i; done &> /tmp/log.txt &;
```
监视 _/tmp/log.txt_ 文件的输出以跟踪脚本的进度。
#### 152.2.3。制作自己的滚动重启脚本的逻辑
如果要创建自己的滚动重新启动脚本,请使用以下准则。
1. 解压缩新版本,验证其配置,并使用`rsync`,`scp`或其他安全同步机制将其同步到群集的所有节点。
2. 首先重启 master。如果新的 HBase 目录与旧的 HBase 目录不同,则可能需要修改这些命令,例如升级。
```
$ ./bin/hbase-daemon.sh stop master; ./bin/hbase-daemon.sh start master
```
3. 从 Master 中使用以下脚本正常重新启动每个 RegionServer。
```
$ for i in `cat conf/regionservers|sort`; do ./bin/graceful_stop.sh --restart --reload --debug $i; done &> /tmp/log.txt &
```
如果您正在运行 Thrift 或 REST 服务器,请传递--thrift 或--rest 选项。对于其他可用选项,请运行`bin/graceful-stop.sh --help`命令。
重启多个 RegionServers 时,重要的是要慢慢耗尽 HBase 区域。否则,多个区域同时脱机,必须重新分配给其他节点,这些节点也可能很快脱机。这可能会对性能产生负面影响。您可以在上面的脚本中注入延迟,例如,通过添加 Shell 命令,例如`sleep`。要在每次 RegionServer 重新启动之间等待 5 分钟,请将以上脚本修改为以下内容:
```
$ for i in `cat conf/regionservers|sort`; do ./bin/graceful_stop.sh --restart --reload --debug $i & sleep 5m; done &> /tmp/log.txt &
```
4. 再次重新启动 Master,清除死服务器列表并重新启用负载均衡器。
### 152.3。添加新节点
在 HBase 中添加一个新的 regionserver 基本上是免费的,你只需这样启动:`$ ./bin/hbase-daemon.sh start regionserver`它将自己注册到 master。理想情况下,您还在同一台计算机上启动了 DataNode,以便 RS 最终可以开始拥有本地文件。如果您依靠 ssh 来启动守护进程,请不要忘记在主服务器上的 _conf / regionservers_ 中添加新主机名。
此时,区域服务器不提供数据,因为还没有区域移动到它。如果启用了平衡器,它将开始将区域移动到新 RS。在小型/中型群集上,这会对延迟产生非常不利的影响,因为许多区域将同时脱机。因此,建议在停用节点并手动移动区域时使用相同的方式禁用平衡器(或者更好,使用逐个移动它们的脚本)。
移动的区域都将具有 0%的位置,并且缓存中不会有任何块,因此区域服务器必须使用网络来处理请求。除了导致更高的延迟,它还可以使用您的所有网卡容量。出于实际目的,请考虑标准的 1GigE NIC 不能读取比 _100MB / s_ 更多的内容。在这种情况下,或者如果您处于 OLAP 环境中并且需要具有位置,则建议主要压缩移动的区域。
## 153\. HBase 指标
HBase 会发出符合 [Hadoop 指标](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/Metrics.html) API 的指标。从 HBase 0.95 <sup class="footnote">[ [5](#_footnote_5 "View footnote.") ]</sup> 开始,HBase 配置为发出一组默认的度量,默认采样周期为每 10 秒。您可以将 HBase 指标与 Ganglia 结合使用。您还可以过滤发布的指标并扩展指标框架,以捕获适合您环境的自定义指标。
### 153.1。度量标准设置
对于 HBase 0.95 及更新版本,HBase 附带默认指标配置或 _sink_ 。这包括各种各样的指标,默认情况下每 10 秒发出一次。要配置给定区域服务器的度量标准,请编辑 _conf / hadoop-metrics2-hbase.properties_ 文件。重新启动区域服务器以使更改生效。
要更改默认接收器的采样率,请编辑以`*.period`开头的行。要过滤发布的指标或扩展指标框架,请参阅 [https://hadoop.apache.org/docs/current/api/org/apache/hadoop/metrics2/package-summary.html](https://hadoop.apache.org/docs/current/api/org/apache/hadoop/metrics2/package-summary.html)
> HBase Metrics 和 Gangli
>
> 默认情况下,HBase 会为每个区域服务器发出大量指标。 Ganglia 可能难以处理所有这些指标。考虑增加 Ganglia 服务器的容量或减少 HBase 发出的指标数量。请参阅[指标过滤](https://hadoop.apache.org/docs/current/api/org/apache/hadoop/metrics2/package-summary.html#filtering)。
### 153.2。禁用指标
要禁用区域服务器的度量标准,请编辑 _conf / hadoop-metrics2-hbase.properties_ 文件并注释掉所有未注释的行。重新启动区域服务器以使更改生效。
### 153.3。发现可用的指标
您可以浏览可用的指标,无论是作为 JSON 输出还是通过 JMX,而不是列出默认情况下 HBase 发出的每个指标。为主进程和每个区域服务器进程公开不同的度量标准。
过程:访问可用度量标准的 JSON 输出
1. 启动 HBase 后,访问区域服务器的 Web UI,默认情况下为 [http:// REGIONSERVER_HOSTNAME:60030](http://REGIONSERVER_HOSTNAME:60030) (或 HBase 1.0+中的端口 16030)。
2. 单击顶部附近的 Metrics Dump 链接。区域服务器的度量标准显示为 JSON 格式的 JMX bean 的转储。这将转储所有指标名称及其值。要在列表中包含指标描述 - 这在您探索可用内容时非常有用 - 添加查询字符串`?description=true`,以便您的网址变为 [http:// REGIONSERVER_HOSTNAME:60030 / jmx?description = true](http://REGIONSERVER_HOSTNAME:60030/jmx?description=true) 。并非所有 bean 和属性都有描述。
3. 要查看 Master 的指标,请改为连接到 Master 的 Web UI(默认为 [http:// localhost:60010](http://localhost:60010) 或 HBase 1.0+中的端口 16010)并单击其 Metrics Dump 链接。要在列表中包含指标描述 - 这在您探索可用内容时非常有用 - 添加查询字符串`?description=true`,以便您的网址变为 [http:// REGIONSERVER_HOSTNAME:60010 / jmx?description = true](http://REGIONSERVER_HOSTNAME:60010/jmx?description=true) 。并非所有 bean 和属性都有描述。
您可以使用许多不同的工具通过浏览 MBean 来查看 JMX 内容。此过程使用`jvisualvm`,这是 JDK 中通常可用的应用程序。
过程:浏览可用度量标准的 JMX 输出
1. 启动 HBase,如果它尚未运行。
2. 在具有 GUI 显示的主机上运行命令`jvisualvm`。您可以从命令行或适用于您的操作系统的其他方法启动它。
3. 确保已安装 VisualVM-MBeans 插件。浏览到**工具→插件**。单击“已安装”并检查是否列出了插件。如果没有,请单击“可用插件”,选择它,然后单击**安装**。完成后,单击**关闭**。
4. 要查看给定 HBase 进程的详细信息,请双击左侧面板中 Local 子树中的进程。右侧面板中将打开详细视图。单击 MBeans 选项卡,该选项卡显示为右侧面板顶部的选项卡。
5. 要访问 HBase 指标,请导航到相应的子 bean :. _ 大师:。_ RegionServer:
6. 每个度量标准的名称及其当前值都显示在“属性”选项卡中。对于包含更多详细信息(包括每个属性的说明)的视图,请单击“元数据”选项卡。
### 153.4。度量单位度量单位
根据需要,不同的度量以不同的单位表示。通常,度量单位在名称中(如度量`shippedKBs`)。否则,请使用以下准则。如有疑问,您可能需要检查给定指标的来源。
* 引用某个时间点的度量标准通常表示为时间戳。
* 引用年龄的度量标准(例如`ageOfLastShippedOp`)通常以毫秒表示。
* 引用内存大小的度量标准以字节为单位。
* 队列的大小(例如`sizeOfLogQueue`)表示为队列中的项目数。通过乘以块大小来确定大小(HDFS 中的默认值为 64 MB)。
* 引用诸如给定类型的操作(例如`logEditsRead`)的数量之类的度量标准表示为整数。
### 153.5。最重要的主要指标
注意:计数通常超过最后一个度量报告间隔。
hbase.master.numRegionServers
实时区域服务器的数量
hbase.master.numDeadRegionServers
死区服务器的数量
hbase.master.ritCount
过渡地区的数量
hbase.master.ritCountOverThreshold
转换区域的数量超过阈值时间(默认值:60 秒)
hbase.master.ritOldestAge
转换中最长区域的年龄,以毫秒为单位
### 153.6。最重要的 RegionServer 指标
Note: Counts are usually over the last metrics reporting interval.
hbase.regionserver.regionCount
区域服务器托管的区域数量
hbase.regionserver.storeFileCount
当前由 regionserver 管理的磁盘上的存储文件数
hbase.regionserver.storeFileSize
磁盘上存储文件的聚合大小
hbase.regionserver.hlogFileCount
尚未归档的预写日志数
hbase.regionserver.totalRequestCount
收到的请求总数
hbase.regionserver.readRequestCount
收到的读取请求数
hbase.regionserver.writeRequestCount
收到的写入请求数
hbase.regionserver.numOpenConnections
RPC 层的打开连接数
hbase.regionserver.numActiveHandler
主动为请求提供服务的 RPC 处理程序的数量
hbase.regionserver.numCallsInGeneralQueue
当前排队的用户请求数
hbase.regionserver.numCallsInReplicationQueue
从复制中收到的当前排队操作的数量
hbase.regionserver.numCallsInPriorityQueue
当前排队的优先级(内部管家)请求的数量
hbase.regionserver.flushQueueLength
memstore 刷新队列的当前深度。如果增加,我们落后于清除 HDFS 的存储库。
hbase.regionserver.updatesBlockedTime
已阻止更新的毫秒数,因此可以刷新 memstore
hbase.regionserver.compactionQueueLength
压缩请求队列的当前深度。如果增加,我们落后于 storefile 压缩。
hbase.regionserver.blockCacheHitCount
块缓存命中数
hbase.regionserver.blockCacheMissCount
块缓存未命中数
hbase.regionserver.blockCacheExpressHitPercent
打开缓存请求的时间百分比达到缓存
hbase.regionserver.percentFilesLocal
可从本地 DataNode 读取的存储文件数据的百分比,0-100
hbase.regionserver。 <op>_<measure></measure></op>
操作延迟,其中<op>是 Append,Delete,Mutate,Get,Replay,Increment 之一;其中<measure>是 min,max,mean,median,75th_percentile,95th_percentile,99th_percentile</measure> </op>中的一个
hbase.regionserver.slow <op>计数</op>
我们认为操作的数量很慢,其中<op>是以上列表中的一个</op>
hbase.regionserver.GcTimeMillis
垃圾收集所花费的时间,以毫秒为单位
hbase.regionserver.GcTimeMillisParNew
在年轻一代的垃圾收集中花费的时间,以毫秒为单位
hbase.regionserver.GcTimeMillisConcurrentMarkSweep
在旧一代的垃圾收集中花费的时间,以毫秒为单位
hbase.regionserver.authenticationSuccesses
身份验证成功的客户端连接数
hbase.regionserver.authenticationFailures
客户端连接验证失败的次数
hbase.regionserver.mutationsWithoutWALCount
提交的写入计数带有一个标志,指示它们应绕过写入日志
## 154\. HBase 监测
### 154.1。概观
以下指标可以说是监控每个 RegionServer 进行“宏监控”的最重要指标,最好是使用像 [OpenTSDB](http://opentsdb.net/) 这样的系统。如果您的群集出现性能问题,您可能会发现此群组存在异常情况。
HBase 的
* 见 [rs 指标](#rs_metrics)
OS
* IO 等待
* 用户 CPU
Java 的
* GC
有关 HBase 指标的更多信息,请参阅 [hbase 指标](#hbase_metrics)。
### 154.2。慢查询日志
HBase 慢查询日志由可解析的 JSON 结构组成,这些结构描述了运行时间太长或产生过多输出的客户端操作(获取,推送,删除等)的属性。 “太长而不能运行”和“太多输出”的阈值是可配置的,如下所述。输出在主区域服务器日志中内联生成,因此很容易从上下文中发现与其他已记录事件的更多详细信息。它还附有识别标签`(responseTooSlow)`,`(responseTooLarge)`,`(operationTooSlow)`和`(operationTooLarge)`,以便在用户希望仅查看慢速查询的情况下,使用 grep 轻松过滤。
#### 154.2.1。组态
有两个配置旋钮可用于调整记录查询的阈值。
* `hbase.ipc.warn.response.time`可以在不记录的情况下运行查询的最大毫秒数。默认为 10000 或 10 秒。可以设置为-1 以禁用按时间记录。
* `hbase.ipc.warn.response.size`查询无需记录即可返回的响应的最大字节大小。默认为 100 兆字节。可以设置为-1 以禁用按大小记录。
#### 154.2.2。度量
慢查询日志向 JMX 公开指标。
* `hadoop.regionserver_rpc_slowResponse`一个全局指标,反映触发记录的所有响应的持续时间。
* `hadoop.regionserver_rpc_methodName.aboveOneSec`一个指标,反映持续时间超过一秒的所有响应的持续时间。
#### 154.2.3。产量
输出用例如操作标记。 `(operationTooSlow)`如果调用是客户端操作,例如 Put,Get 或 Delete,我们会为其公开详细的指纹信息。如果没有,它被标记为`(responseTooSlow)`并且仍然产生可解析的 JSON 输出,但是只有关于 RPC 本身的持续时间和大小的冗长信息。如果响应大小触发了日志记录,则`TooLarge`将替换`TooSlow`,即使在大小和持续时间都触发日志记录的情况下也会出现`TooLarge`。
#### 154.2.4。例
```
2011-09-08 10:01:25,824 WARN org.apache.hadoop.ipc.HBaseServer: (operationTooSlow): {"tables":{"riley2":{"puts":[{"totalColumns":11,"families":{"actions":[{"timestamp":1315501284459,"qualifier":"0","vlen":9667580},{"timestamp":1315501284459,"qualifier":"1","vlen":10122412},{"timestamp":1315501284459,"qualifier":"2","vlen":11104617},{"timestamp":1315501284459,"qualifier":"3","vlen":13430635}]},"row":"cfcd208495d565ef66e7dff9f98764da:0"}],"families":["actions"]}},"processingtimems":956,"client":"10.47.34.63:33623","starttimems":1315501284456,"queuetimems":0,"totalPuts":1,"class":"HRegionServer","responsesize":0,"method":"multiPut"}
```
请注意,“表”结构中的所有内容都是由 MultiPut 指纹生成的,而其余信息是特定于 RPC 的,例如处理时间和客户端 IP /端口。其他客户操作遵循相同的模式和相同的一般结构,由于各个操作的性质而具有必要的差异。在呼叫不是客户端操作的情况下,将完全不存在详细的指纹信息。
例如,这个特定的例子表明,慢速的可能原因只是一个非常大的(大约 100MB)多输出,正如我们可以通过 multiput 中每个 put 的“vlen”或值长度字段来判断的那样。 。
### 154.3。阻止缓存监控
从 HBase 0.98 开始,HBase Web UI 包括监视和报告块缓存性能的功能。要查看块缓存报告,请单击。以下是报告功能的几个示例。
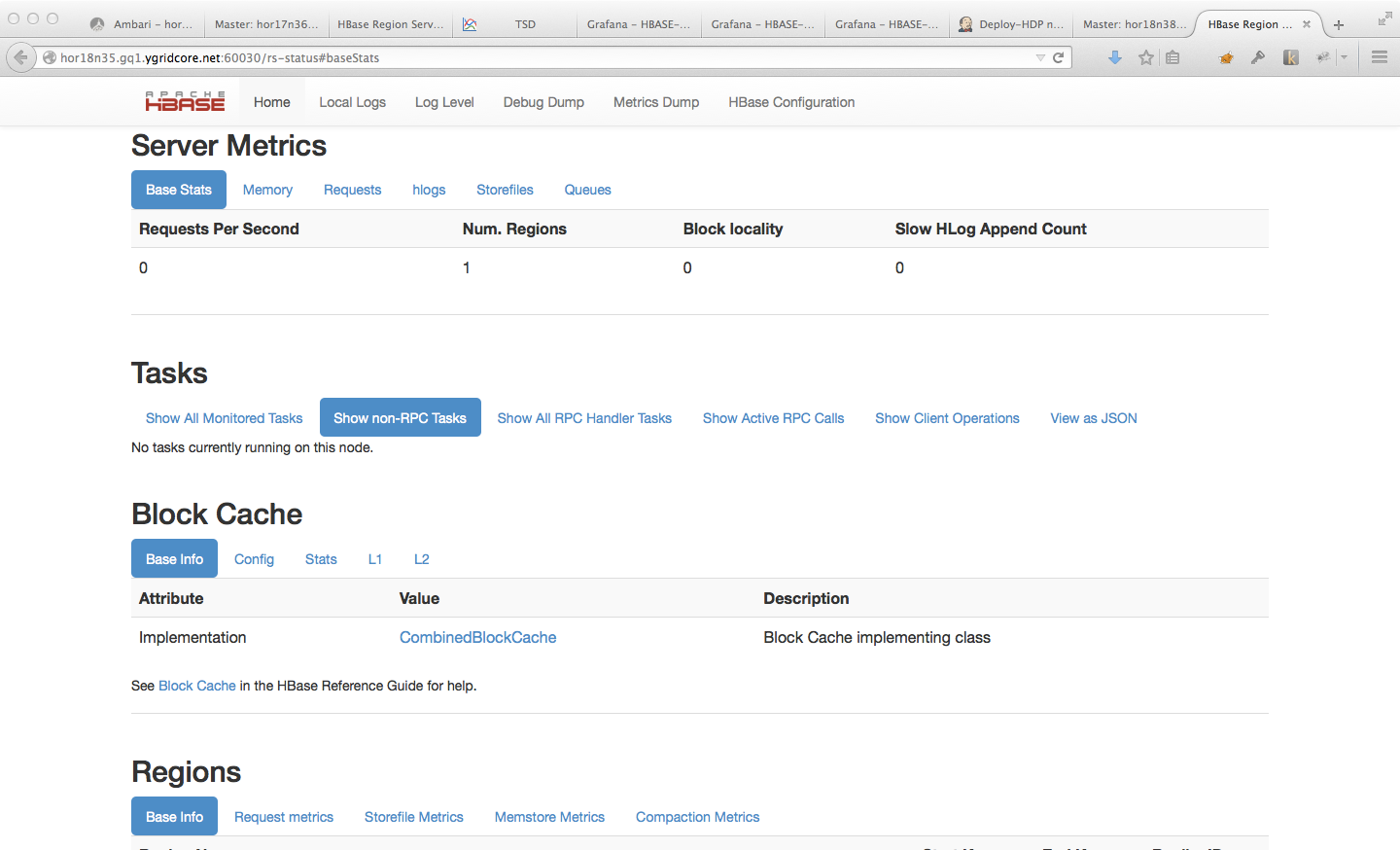图 8.基本信息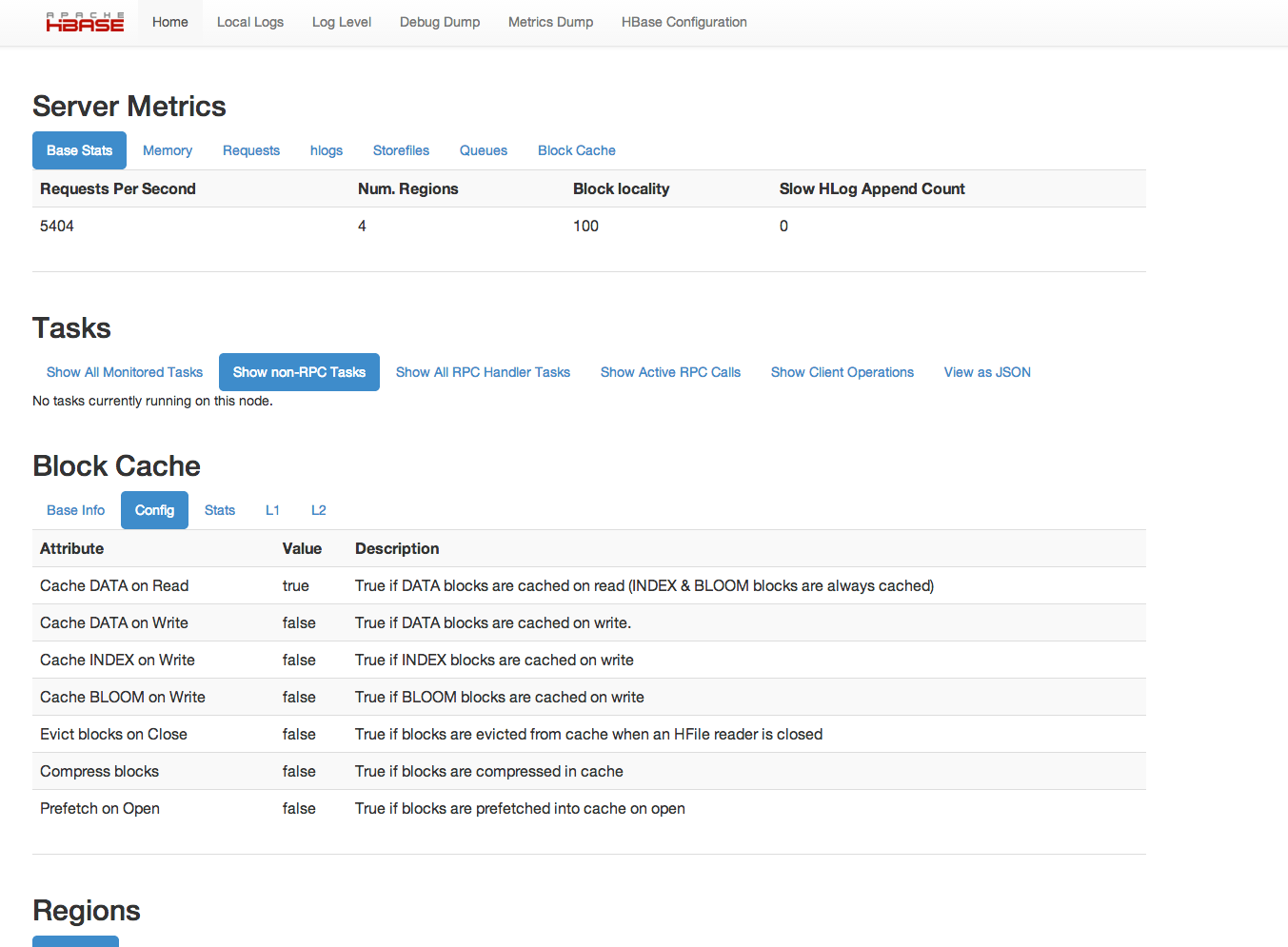图 9.配置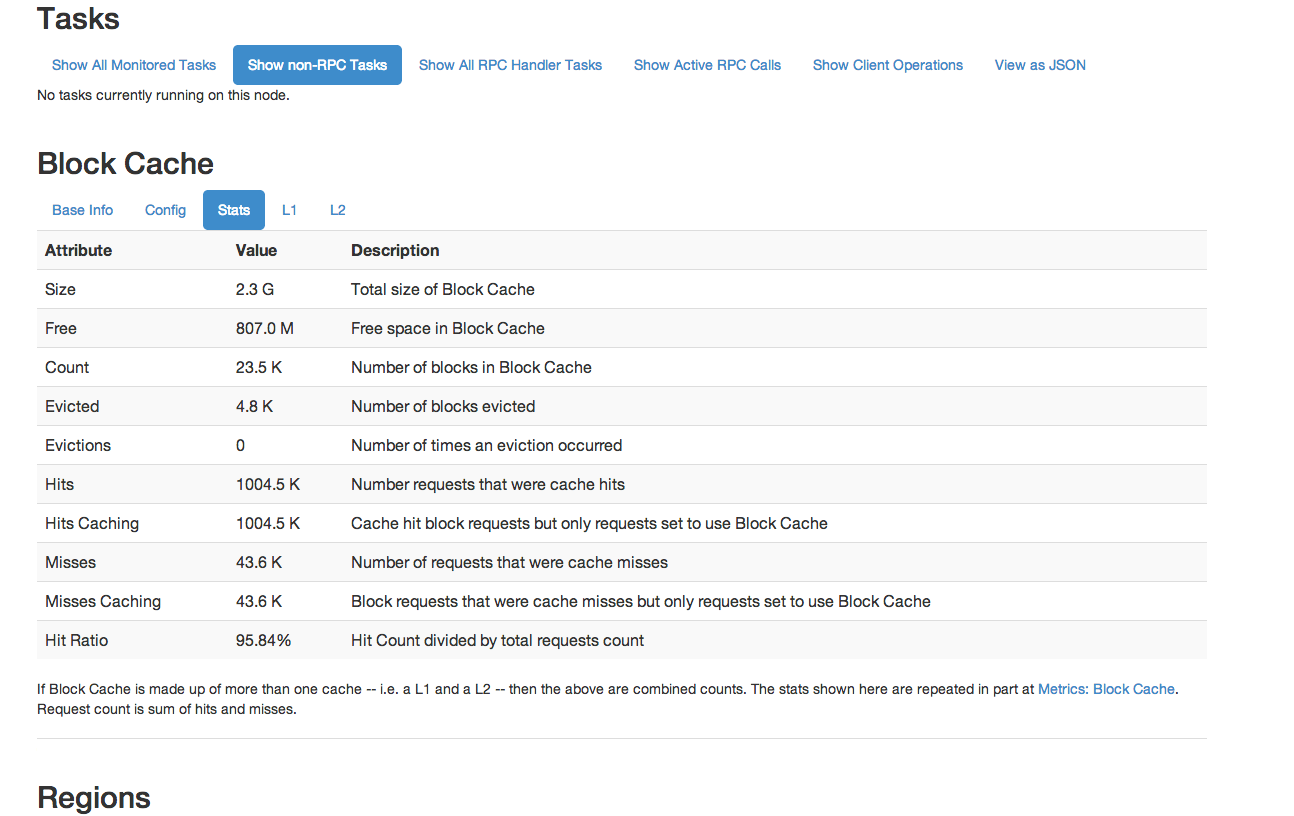图 10.统计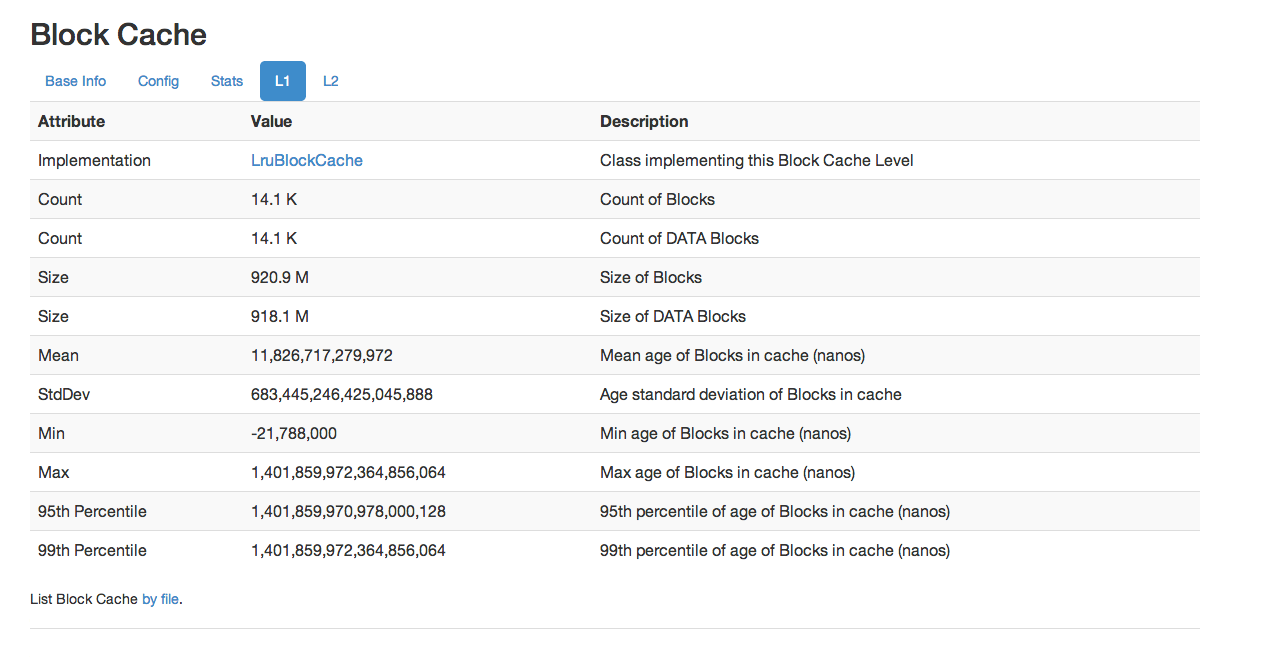图 11\. L1 和 L2
这不是所有可用屏幕和报告的详尽列表。看一下 Web UI。
### 154.4。快照空间使用情况监控
从 HBase 0.95 开始,HBase Master Web UI 中显示了各个快照的快照使用信息。从 HBase 1.3 开始,这进一步增强,以显示快照集的总文件文件大小。以下指标显示在使用 HBase 1.3 及更高版本的主 Web UI 中。
* Shared Storefile Size 是快照和活动表之间共享的 Storefile 大小。
* Mob Storefile Size 是快照和活动表之间共享的 Mob Storefile 大小。
* 存档的 Storefile Size 是存档中的存储文件大小。
存档文件大小的格式为 NNN(MMM)。 NNN 是存档中的存储文件总大小,MMM 是存档中特定于快照的存储文件总大小(不与其他快照和表共享)。
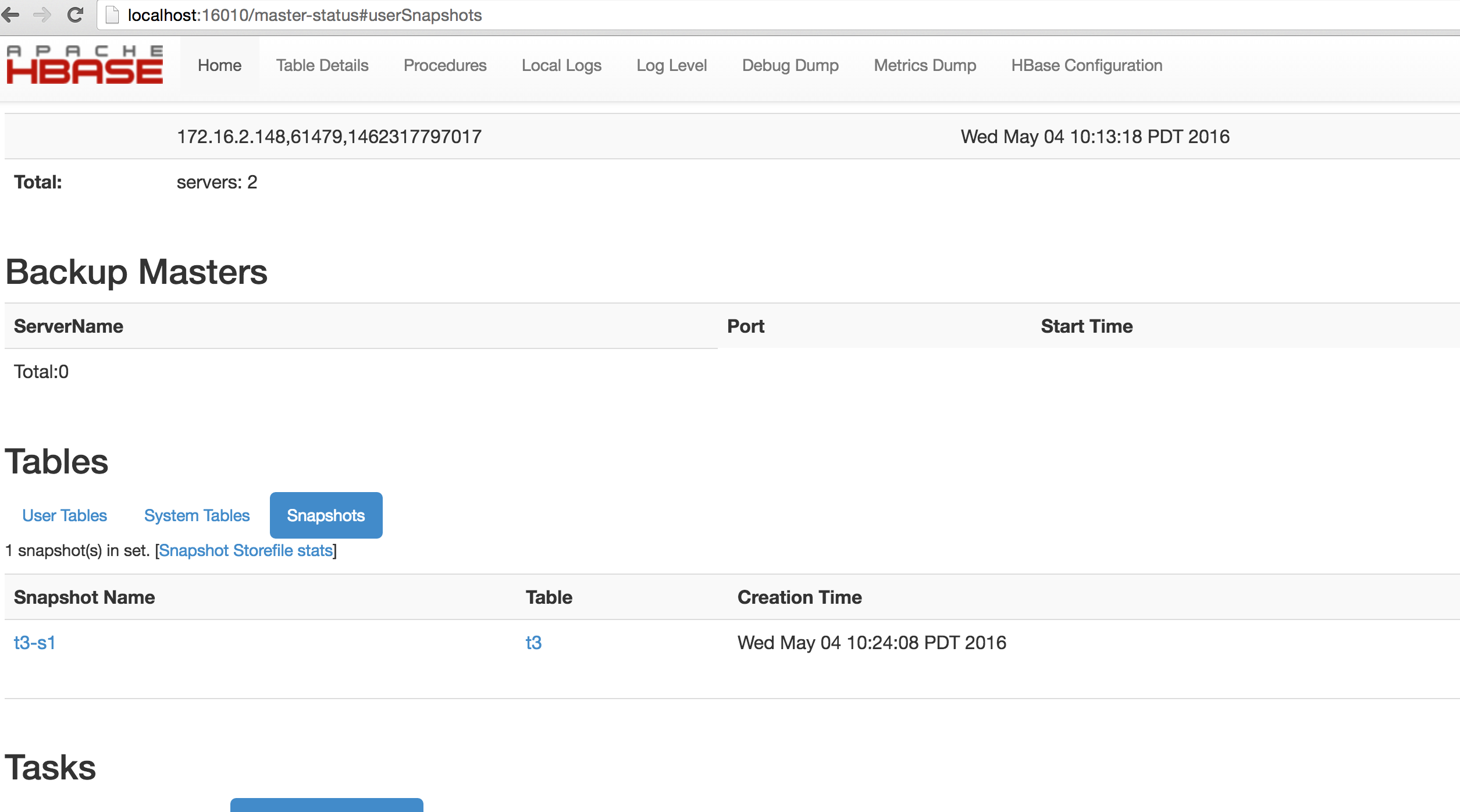图 12.主快照概述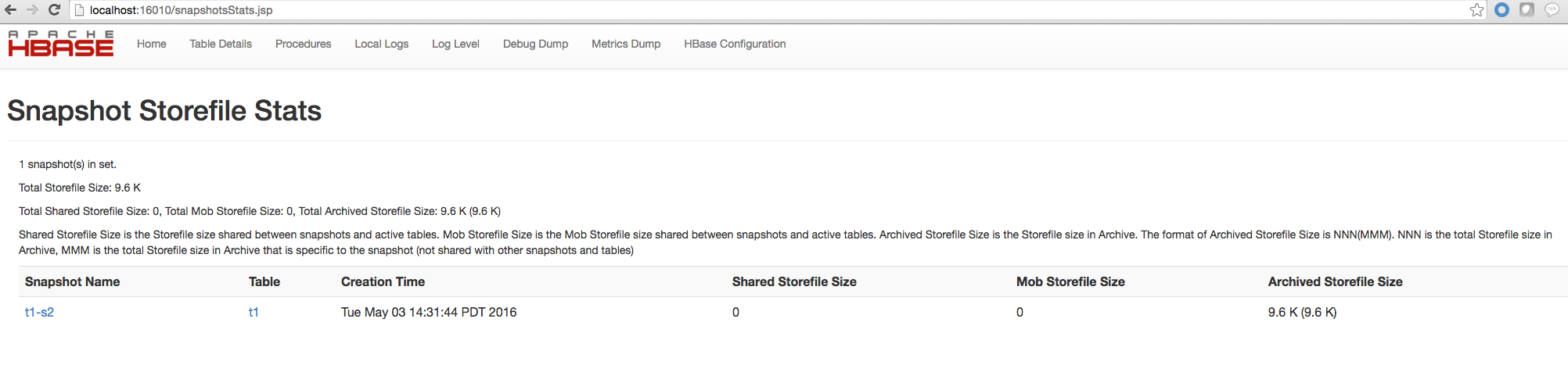图 13.快照存储文件统计示例 1 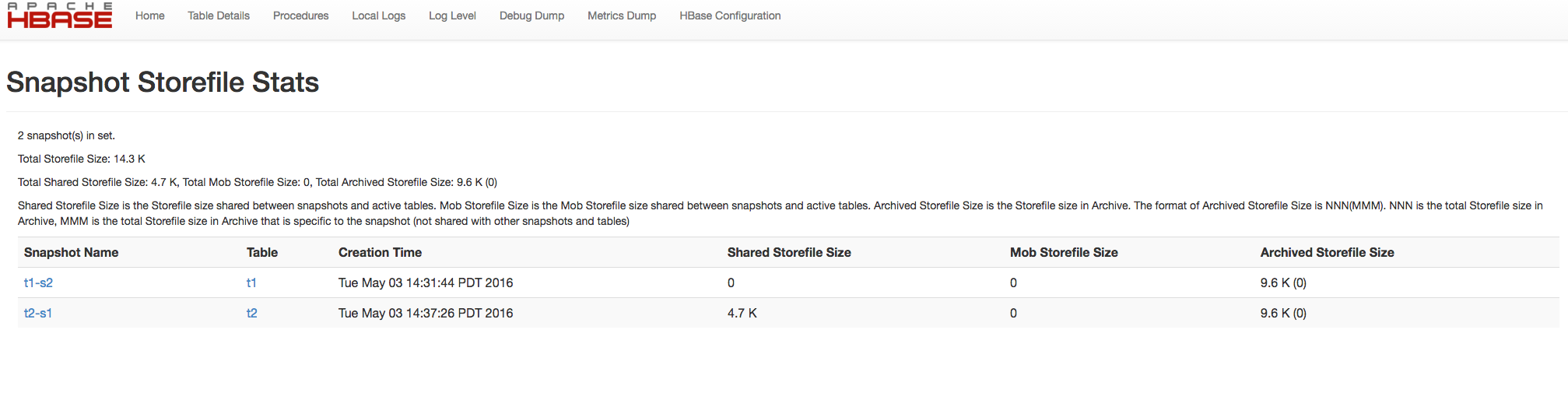图 14.快照存储文件统计示例 2 图 15.空快照 Storfile 统计示例
## 155.群集复制
> 此信息以前在 [Cluster Replication](https://hbase.apache.org/0.94/replication.html) 中提供。
HBase 提供了一种群集复制机制,允许您使用源群集的预写日志(WAL)来传播更改,从而使一个群集的状态与另一个群集的状态保持同步。集群复制的一些用例包括:
* 备份和灾难恢复
* 数据聚合
* 地理数据分布
* 在线数据提取与离线数据分析相结合
> 以列族的粒度启用复制。在为列族启用复制之前,请在目标群集上创建要复制的表和所有列族。
>
> 复制是异步的,因为我们将 WAL 发送到后台的另一个集群,这意味着当您想通过复制进行恢复时,可能会丢失一些数据。为解决此问题,我们引入了一项称为同步复制的新功能。由于机制有点不同所以我们使用一个单独的部分来描述它。请参见[同步复制](#syncreplication)。
### 155.1。复制概述
群集复制使用源推送方法。 HBase 集群可以是源(也称为主服务器或主服务器,意味着它是新数据的发起者),目标服务器(也称为从服务器或被动服务器,意味着它通过复制接收数据),或者可以同时满足这两个角色。复制是异步的,复制的目标是最终的一致性。当源接收对启用了复制的列族的编辑时,该编辑将使用 WAL 传播到所有目标群集,以用于管理相关区域的 RegionServer 上的该列族。
当数据从一个集群复制到另一个集群时,将通过集群 ID 跟踪数据的原始源,集群 ID 是元数据的一部分。在 HBase 0.96 和更新的( [HBASE-7709](https://issues.apache.org/jira/browse/HBASE-7709) )中,还跟踪已经消耗了数据的所有簇。这可以防止复制循环。
只要需要将数据复制到任何从属群集,每个区域服务器的 WAL 必须保留在 HDFS 中。每个区域服务器都从需要复制的最旧日志中读取,并跟踪其在 ZooKeeper 中处理 WAL 的进度,以简化故障恢复。指示从属群集的进度的位置标记以及要处理的 WAL 的队列对于每个从属群集可以是不同的。
参与复制的集群可以具有不同的大小。主群集依赖于随机化来尝试平衡从属群集上的复制流。预期从属群集具有存储容量来保存复制数据,以及它负责摄取的任何数据。如果从属群集的空间不足或由于其他原因而无法访问,则会抛出错误并且主服务器会保留 WAL 并每隔一段时间重试一次复制。
> 复制群集的一致性
>
> 在复制过程中,您的应用程序如何构建在 HBase API 之上。 HBase 的复制系统至少为已启用的列系列向每个已配置的目标群集提供客户端编辑。如果未能到达给定目标,复制系统将以可能重复给定消息的方式重试发送编辑。 HBase 提供了两种复制方式,一种是原始复制,另一种是串行复制。在以前的复制方式中,客户端编辑没有保证的交付顺序。如果 RegionServer 发生故障,复制队列的恢复将独立于服务器先前处理的各个区域的恢复而发生。这意味着尚未复制的编辑可能由 RegionServer 提供服务,该 RegionServer 目前比在失败后处理编辑的更复杂。
>
> 这两个属性的组合(至少一次传递和缺少消息排序)意味着如果您的应用程序使用非幂等的操作,某些目标群集可能最终处于不同的状态,例如,增量。
>
> 为了解决这个问题,HBase 现在支持串行复制,它将编辑作为客户端请求的顺序发送到目标集群。请参见[串行复制](#_serial_replication)。
>
> 术语变化
>
> 以前, _master-master_ , _master-slave_ 和 _cyclical_ 等术语用于描述 HBase 中的复制关系。这些术语增加了混淆,并且已经放弃了有利于讨论适用于不同场景的集群拓扑。
群集拓扑
* 中央源群集可能会将更改传播到多个目标群集,以进行故障转移或由于地理分布。
* 源群集可能会将更改推送到目标群集,这可能还会将其自身的更改推送回原始群集。
* 许多不同的低延迟群集可能会将更改推送到一个集中式群集,以进行备份或资源密集型数据分析作业。然后,处理后的数据可能会被复制回低延迟群集。
可以将多个级别的复制链接在一起以满足组织的需要。下图显示了一个假设的场景。使用箭头跟随数据路径。
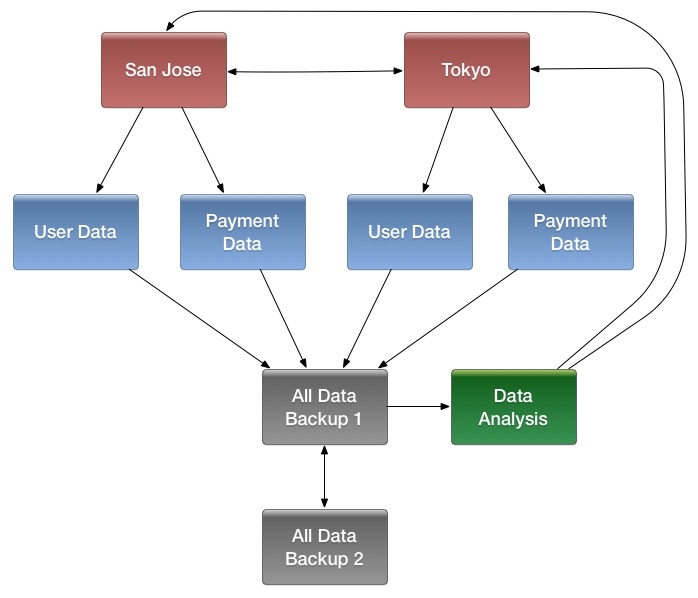图 16.复杂群集复制配置示例
HBase 复制借鉴了 MySQL 使用的基于 _ 语句的复制 _ 设计中的许多概念。而不是 SQL 语句,将复制整个 WALEdits(包括来自客户端上的 Put 和 Delete 操作的多个单元格插入),以保持原子性。
### 155.2。管理和配置群集复制
群集配置概述
1. 配置并启动源和目标群集。在源群集和目标群集上创建具有相同名称和列系列的表,以便目标群集知道将在何处存储将接收的数据。
2. 源和目标群集中的所有主机都应该可以相互访问。
3. 如果两个群集都使用相同的 ZooKeeper 群集,则必须使用不同的`zookeeper.znode.parent`,因为它们无法在同一文件夹中写入。
4. 在源群集上,在 HBase Shell 中,使用`add_peer`命令将目标群集添加为对等方。
5. 在源群集上,在 HBase Shell 中,使用`enable_table_replication`命令启用表复制。
6. 检查日志以查看是否正在进行复制。如果是这样,您将看到来自 ReplicationSource 的以下消息。
```
LOG.info("Replicating "+clusterId + " -> " + peerClusterId);
```
串行复制配置
参见[串行复制](#_serial_replication)
群集管理命令
add_peer
在两个群集之间添加复制关系。
* ID - 唯一字符串,不得包含连字符。
* CLUSTER_KEY:使用以下模板和适当的占位符组成:`hbase.zookeeper.quorum:hbase.zookeeper.property.clientPort:zookeeper.znode.parent`。可以在主 UI 信息页面上找到此值。
* STATE(可选):ENABLED 或 DISABLED,默认值为 ENABLED
list_peers
列出此群集已知的所有复制关系
enable_peer
启用先前禁用的复制关系
disable_peer
禁用复制关系。 HBase 将不再向该对等集群发送编辑,但它仍会跟踪在重新启用时需要复制的所有新 WAL。只要存在对等体,在启用或禁用复制时将保留 WAL。
remove_peer
禁用并删除复制关系。 HBase 将不再向该对等集群发送编辑或跟踪 WAL。
enable_table_replication<table_name></table_name>
为其所有列系列启用表复制开关。如果在目标集群中找不到该表,则它将创建一个具有相同名称和列族的表。
disable_table_replication<table_name></table_name>
禁用其所有列系列的表复制开关。
### 155.3。串行复制
注意:此功能在 HBase 2.1 中引入
串行复制的功能
串行复制支持以与日志到达源群集相同的顺序将日志推送到目标群集。
为什么需要串行复制?
在 HBase 的复制中,我们通过在每个区域服务器中读取 WAL 来将突变推送到目标集群。我们有一个 WAL 文件的队列,所以我们可以按照创建时间的顺序读取它们。但是,当源群集中发生区域移动或 RS 故障时,在区域移动或 RS 失败之前未被推送的 hlog 条目将被原始 RS(用于区域移动)或另一个接管剩余 hlog 的 RS 推送。死 RS(用于 RS 失败),同一区域的新条目将由现在服务于区域的 RS 推送,但它们同时推送同一区域的 hlog 条目而不进行协调。
这种处理可能导致源和目标集群之间的数据不一致:
1. 有 put 然后删除写入源集群。
2. 由于区域移动/ RS 失败,它们被不同的复制源线程推送到对等集群。
3. 如果在放入之前将删除推送到对等集群,并且在将 put 推送到对等集群之前在对等集群中发生 flush 和 major-compact,则收集删除并且放置在对等集群中,但是在源集群中,放置被掩盖了删除,因此源和目标集群之间的数据不一致。
串行复制配置
将复制节点的串行标志设置为 true。默认的串行标志为 false。
* 添加一个串行标志为 true 的新复制对等体
```
hbase> add_peer '1', CLUSTER_KEY => "server1.cie.com:2181:/hbase", SERIAL => true
```
* 将复制对等方的串行标志设置为 false
```
hbase> set_peer_serial '1', false
```
* 将复制对等方的串行标志设置为 true
```
hbase> set_peer_serial '1', true
```
首先在 [HBASE-9465](https://issues.apache.org/jira/browse/HBASE-9465) 中进行了系列复制,然后在 [HBASE-20046](https://issues.apache.org/jira/browse/HBASE-20046) 中进行了回复和重做。您可以在这些问题中找到更多详细信息。
### 155.4。验证复制数据
`VerifyReplication` MapReduce 作业(包含在 HBase 中)对两个不同集群之间的复制数据进行系统比较。在主群集上运行 VerifyReplication 作业,为其提供用于验证的对等 ID 和表名。您可以通过指定时间范围或特定系列来进一步限制验证。这份工作的简称是`verifyrep`。要运行作业,请使用如下命令:
+
```
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` "${HADOOP_HOME}/bin/hadoop" jar "${HBASE_HOME}/hbase-mapreduce-VERSION.jar" verifyrep --starttime=<timestamp> --endtime=<timestamp> --families=<myFam> <ID> <tableName>
```
* `VerifyReplication`命令打印出`GOODROWS`和`BADROWS`计数器,以指示正确复制和未复制的行。
### 155.5。有关群集复制的详细信息
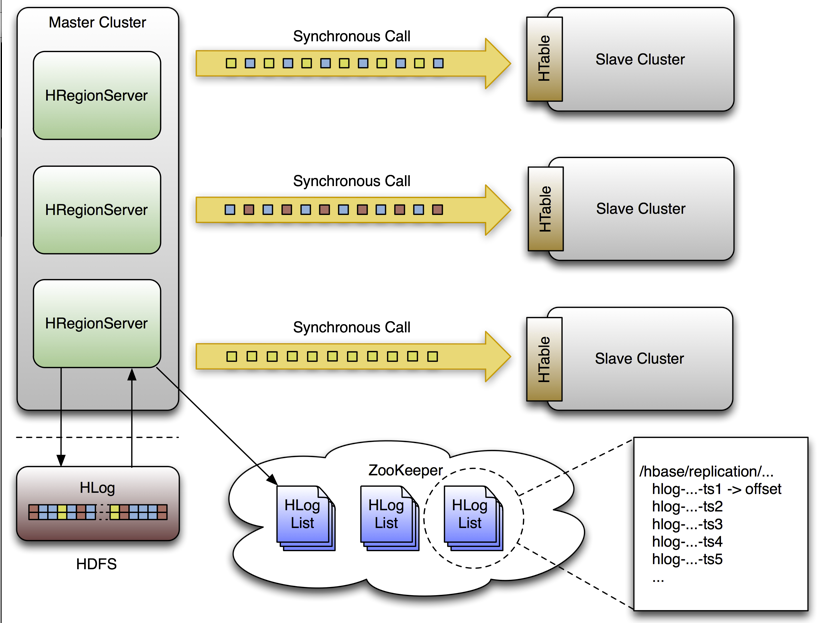图 17.复制架构概述
#### 155.5.1。 WAL 编辑的生活
单个 WAL 编辑将经历几个步骤,以便复制到从属群集。
1. HBase 客户端使用 Put 或 Delete 操作来操作 HBase 中的数据。
2. 区域服务器以某种方式将请求写入 WAL,如果未成功写入则允许重放。
3. 如果更改的单元格对应于作为复制作用域的列族,则会将编辑添加到队列以进行复制。
4. 在单独的线程中,作为批处理的一部分,从日志中读取编辑。仅保留符合复制条件的 KeyValues。可复制的 KeyValues 是列族的一部分,其列的范围为 GLOBAL,不是`hbase:meta`等目录的一部分,不是源自目标从属群集,并且尚未被目标从群集使用。
5. 编辑用主 UUID 标记并添加到缓冲区。填充缓冲区或读取器到达文件末尾时,缓冲区将发送到从属群集上的随机区域服务器。
6. 区域服务器按顺序读取编辑并将它们分成缓冲区,每个表一个缓冲区。读取所有编辑后,使用 HBase 的普通客户端[表](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/Table.html)刷新每个缓冲区。主服务器的 UUID 和已经使用数据的从服务器的 UUID 将保留在应用的编辑中,以防止复制循环。
7. 在主服务器中,当前正在复制的 WALL 的偏移量在 ZooKeeper 中注册。
8. 插入编辑的前三个步骤是相同的。
9. 同样在单独的线程中,区域服务器以与上面相同的方式读取,过滤和编辑日志编辑。从属区域服务器不响应 RPC 调用。
10. 主人睡眠并再次尝试可配置的次数。
11. 如果从属区域服务器仍然不可用,则主服务器选择要复制到的区域服务器的新子集,并再次尝试发送编辑缓冲区。
12. 同时,WALs 被滚动并存储在 ZooKeeper 的队列中。由区域服务器将 _ 归档 _ 的日志从区域服务器的日志目录移动到中央日志目录,将更新其在复制线程的内存中队列中的路径。
13. 当从属群集最终可用时,缓冲区的应用方式与正常处理时相同。然后,主区域服务器将复制在中断期间累积的积压日志。
传播队列故障转移负载
复制处于活动状态时,源群集中的一部分区域服务器负责将编辑内容传送到接收器。与进程或节点崩溃时的所有其他区域服务器功能一样,此责任必须进行故障转移。建议使用以下配置设置来维护源群集中其余活动服务器上的复制活动的均匀分布:
* 将`replication.source.maxretriesmultiplier`设置为`300`。
* 将`replication.source.sleepforretries`设置为`1`(1 秒)。该值与`replication.source.maxretriesmultiplier`的值相结合,导致重试周期持续约 5 分钟。
* 在源群集站点配置中将`replication.sleep.before.failover`设置为`30000`(30 秒)。
在复制期间保留标记
默认情况下,用于群集之间复制的编解码器会从单元格中剥离标记,例如单元级 ACL。要防止标记被剥离,您可以使用不剥离标记的其他编解码器。在复制中涉及的源和接收区域服务器上配置`hbase.replication.rpc.codec`以使用`org.apache.hadoop.hbase.codec.KeyValueCodecWithTags`。该选项在 [HBASE-10322](https://issues.apache.org/jira/browse/HBASE-10322) 中引入。
#### 155.5.2。复制内部
ZooKeeper 中的复制状态
HBase 复制在 ZooKeeper 中维护其状态。默认情况下,状态包含在基节点 _/ hbase / replication_ 中。该节点包含两个子节点,`Peers` znode 和`RS` znode。
`Peers` Znode
`peers` znode 默认存储在 _/ hbase / replication / peers_ 中。它由所有对等复制集群的列表以及每个集群的状态组成。每个对等方的值是其群集密钥,它在 HBase Shell 中提供。群集密钥包含群集仲裁中的 ZooKeeper 节点列表,ZooKeeper 仲裁的客户端端口以及该群集上 HDFS 中 HBase 的基本 znode。
`RS` Znode
`rs` znode 包含需要复制的 WAL 日志列表。此列表分为由区域服务器组织的一组队列和区域服务器将日志传送到的对等群集。 rs znode 为集群中的每个区域服务器都有一个子 znode。子 znode 名称是区域服务器的主机名,客户端端口和起始代码。此列表包括实时和死区服务器。
#### 155.5.3。选择要复制到的区域服务器
当主群集区域服务器向从群集启动复制源时,它首先使用提供的群集密钥连接到从属的 ZooKeeper 集合。然后扫描 _rs /_ 目录以发现所有可用的接收器(接受要复制的输入流的区域服务器),并使用配置的比率随机选择它们的子集,其默认值为 10 %。例如,如果从属群集有 150 台计算机,则将选择 15 个作为此主群集区域服务器发送的编辑的潜在接收者。由于此选择由每个主区域服务器执行,因此使用所有从属区域服务器的概率非常高,并且此方法适用于任何大小的群集。例如,10 台机器的主集群复制到 5 台机器的从机集群,比率为 10%,这使得主集群区域服务器可以随机选择一台机器。
ZooKeeper 观察器由每个主集群的区域服务器放置在从集群的 _$ {zookeeper.znode.parent} / rs_ 节点上。此表用于监视从属群集组成的变化。从节点集群中删除节点后,或节点关闭或重新启动时,主集群的区域服务器将通过选择要复制到的新的从属区域服务器池进行响应。
#### 155.5.4。跟踪日志
每个主群集区域服务器在复制 znodes 层次结构中都有自己的 znode。它包含每个对等群集一个 znode(如果创建了 5 个从属群集,创建了 5 个 znode),并且每个群集都包含要处理的 WAL 队列。这些队列中的每一个都将跟踪该区域服务器创建的 WAL,但它们的大小可能不同。例如,如果一个从属群集在一段时间内不可用,则不应删除 WAL,因此在处理其他群集时,它们需要保留在队列中。有关示例,请参见 [rs.failover.details](#rs.failover.details) 。
实例化源时,它包含区域服务器正在写入的当前 WAL。在日志滚动期间,新文件将在可用之前添加到每个从属群集的 znode 的队列中。这可确保所有源都知道在区域服务器能够向其中添加编辑之前存在新日志,但此操作现在更加昂贵。当复制线程无法从文件中读取更多条目(因为它到达最后一个块的末尾)并且队列中有其他文件时,将丢弃队列项。这意味着如果源是最新的并且从区域服务器写入的日志中复制,则读取当前文件的“结尾”将不会删除队列中的项目。
如果日志不再使用或日志数超过`hbase.regionserver.maxlogs`,则可以归档日志,因为插入速率比刷新区域的速度快。归档日志时,会通知源线程该日志的路径发生更改。如果特定源已经完成了归档日志,它将忽略该消息。如果日志在队列中,则路径将在内存中更新。如果当前正在复制日志,则更改将以原子方式完成,以便读取器在已移动时不会尝试打开该文件。因为移动文件是 NameNode 操作,如果读者当前正在读取日志,则不会生成任何异常。
#### 155.5.5。阅读,过滤和发送编辑
默认情况下,源会尝试从 WAL 读取并尽快将日志条目发送到接收器。速度受到日志条目过滤的限制只保留作用域为 GLOBAL 且不属于目录表的 KeyValues。速度也受到每个从站复制的编辑列表总大小的限制,默认情况下限制为 64 MB。使用此配置,具有三个从属服务器的主群集区域服务器将使用最多 192 MB 来存储要复制的数据。这不会考虑已过滤但未收集垃圾的数据。
一旦编辑的最大编辑大小被缓冲或读者到达 WAL 的末尾,源线程就会停止读取并随机选择一个接收器复制到(从通过仅保留从属区域服务器的子集生成的列表) 。它直接向选定的区域服务器发出 RPC 并等待方法返回。如果 RPC 成功,源将确定当前文件是否已清空,或者是否包含需要读取的更多数据。如果文件已清空,则源将删除队列中的 znode。否则,它会在日志的 znode 中注册新的偏移量。如果 RPC 引发异常,源将在尝试查找不同的接收器之前重试 10 次。
#### 155.5.6。清理日志
如果未启用复制,则主服务器的日志清理线程将使用配置的 TTL 删除旧日志。这种基于 TTL 的方法不适用于复制,因为已超过其 TTL 的存档日志可能仍在队列中。默认行为是增强的,因此如果日志超过其 TTL,则清理线程会查找每个队列,直到找到日志,同时缓存已找到的队列。如果未在任何队列中找到日志,则将删除该日志。下次清理过程需要查找日志时,它首先使用其缓存列表。
> 只要存在对等体,就会在启用或禁用复制时保存 WAL。
#### 155.5.7。区域服务器故障转移
当没有区域服务器发生故障时,跟踪 ZooKeeper 中的日志不会增加任何值。遗憾的是,区域服务器确实失败,并且由于 ZooKeeper 具有高可用性,因此在发生故障时管理队列的传输非常有用。
每个主集群区域服务器在每个其他区域服务器上保持观察者,以便在一个人死亡时得到通知(就像主人一样)。当发生故障时,他们都会竞争在死区服务器的 znode 中创建一个名为`lock`的 znode,该 znode 包含其队列。成功创建它的区域服务器然后将所有队列传输到它自己的 znode,一次一个,因为 ZooKeeper 不支持重命名队列。队列全部转移后,将从旧位置删除它们。使用附加了死服务器名称的从属群集的 ID 重命名已恢复的 znode。
接下来,主集群区域服务器为每个复制的队列创建一个新的源线程,并且每个源线程遵循读取/过滤器/发布模式。主要区别在于这些队列永远不会收到新数据,因为它们不属于新的区域服务器。当阅读器到达最后一个日志的末尾时,队列的 znode 将被删除,主群集区域服务器将关闭该复制源。
给定具有 3 个区域服务器的主集群复制到具有 id `2`的单个从属服务器,以下层次结构表示 znodes 布局在某个时间点可能是什么。区域服务器的 znode 都包含一个包含单个队列的`peers` znode。队列中的 znode 名称以`address,port.timestamp`的形式表示 HDFS 上的实际文件名。
```
/hbase/replication/rs/
1.1.1.1,60020,123456780/
2/
1.1.1.1,60020.1234 (Contains a position)
1.1.1.1,60020.1265
1.1.1.2,60020,123456790/
2/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
1.1.1.3,60020, 123456630/
2/
1.1.1.3,60020.1280 (Contains a position)
```
假设 1.1.1.2 丢失了 ZooKeeper 会话。幸存者将竞争创造一个锁,并且,任意地,1.1.1.3 获胜。然后,它将通过附加死服务器的名称开始将所有队列传输到其本地对等方 znode。在 1.1.1.3 之前能够清理旧的 znode,布局将如下所示:
```
/hbase/replication/rs/
1.1.1.1,60020,123456780/
2/
1.1.1.1,60020.1234 (Contains a position)
1.1.1.1,60020.1265
1.1.1.2,60020,123456790/
lock
2/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
1.1.1.3,60020,123456630/
2/
1.1.1.3,60020.1280 (Contains a position)
2-1.1.1.2,60020,123456790/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
```
一段时间之后,但在 1.1.1.3 之前能够完成从 1.1.1.2 复制最后一个 WAL,它也会死掉。在正常队列中也创建了一些新日志。然后,最后一个区域服务器将尝试锁定 1.1.1.3 的 znode 并开始传输所有队列。新的布局将是:
```
/hbase/replication/rs/
1.1.1.1,60020,123456780/
2/
1.1.1.1,60020.1378 (Contains a position)
2-1.1.1.3,60020,123456630/
1.1.1.3,60020.1325 (Contains a position)
1.1.1.3,60020.1401
2-1.1.1.2,60020,123456790-1.1.1.3,60020,123456630/
1.1.1.2,60020.1312 (Contains a position)
1.1.1.3,60020,123456630/
lock
2/
1.1.1.3,60020.1325 (Contains a position)
1.1.1.3,60020.1401
2-1.1.1.2,60020,123456790/
1.1.1.2,60020.1312 (Contains a position)
```
### 155.6。复制指标
以下度量标准在全局区域服务器级别和对等级别公开:
`source.sizeOfLogQueue`
复制源处理的 WAL 数(不包括正在处理的 WAL)
`source.shippedOps`
发送的突变数量
`source.logEditsRead`
从复制源处的 WAL 读取的突变数
`source.ageOfLastShippedOp`
复制源发送的最后一批的时间
`source.completedLogs`
已完成其已确认发送到与此源关联的对等方的预写日志文件的数量。此度量标准的增量是 HBase 复制的正常操作的一部分。
`source.completedRecoverQueues`
此源已完成发送到关联对等方的恢复队列数。在失败的区域服务器面前,此度量标准的增量是 HBase 复制的正常恢复的一部分。
`source.uncleanlyClosedLogs`
复制系统在面对不正确关闭的文件到达可读条目末尾后认为已完成的预写日志文件数。
`source.ignoredUncleanlyClosedLogContentsInBytes`
如果未完全关闭预写日志文件,则可能会有一些已部分序列化的条目。此度量标准包含 HBase 复制系统认为在面对不正确关闭的文件时跳过的文件末尾的此类条目的字节数。这些字节应该在不同的文件中,或者表示未被确认的客户端写入。
`source.restartedLogReading`
HBase 复制系统检测到无法正确解析完全关闭的预写日志文件的次数。在这种情况下,系统从一开始就重放整个日志,确保相关对等体不能确认编辑。此度量标准的增量表示 HBase 复制系统难以正确处理底层分布式存储系统中的故障。不应出现数据删除,但您应检查 Region Server 日志文件以获取故障的详细信息。
`source.repeatedLogFileBytes`
当 HBase 复制系统确定它需要重放给定的预写日志文件时,此度量标准将增加复制系统认为在重新开始之前已由关联对等方确认的字节数。
`source.closedLogsWithUnknownFileLength`
当 HBase 复制系统认为它位于预写日志文件的末尾但是无法确定底层分布式存储系统中该文件的长度时,会增加。可以指示 dataloss,因为复制系统无法确定可读条目的末尾是否与文件的预期结束对齐。您应该检查 Region Server 日志文件以获取故障的详细信息。
### 155.7。复制配置选项
| 选项 | 描述 | 默认 |
| --- | --- | --- |
| zookeeper.znode.parent | 用于 HBase 的基本 ZooKeeper znode 的名称 | / HBase 的 |
| zookeeper.znode.replication | 用于复制的基本 znode 的名称 | 复制 |
| zookeeper.znode.replication.peers | 对等 znode 的名称 | 同行 |
| zookeeper.znode.replication.peers.state | 对等状态 znode 的名称 | 对等状态 |
| zookeeper.znode.replication.rs | rs znode 的名称 | RS |
| replication.sleep.before.failover | 在尝试复制死区服务器 WAL 队列之前,工作者应该睡多少毫秒。 | |
| replication.executor.workers | 给定区域服务器应尝试同时进行故障转移的区域服务器数。 | 1 |
### 155.8。监控复制状态
您可以使用 HBase Shell 命令`status 'replication'`来监视群集上的复制状态。该命令有三个变体: _`status 'replication'` - 打印每个源及其接收器的状态,按主机名排序。_ `status 'replication', 'source'` - 打印每个复制源的状态,按主机名排序。 * `status 'replication', 'sink'` - 打印每个复制接收器的状态,按主机名排序。
## 156.在单个群集上运行多个工作负载
HBase 提供以下机制来管理处理多个工作负载的集群的性能:。 [配额](#quota)。 [请求队列](#request_queues)。 [多种类型的队列](#multiple-typed-queues)
### 156.1。配额
HBASE-11598 引入了 RPC 配额,允许您根据以下限制限制请求:
1. [给定时间范围内请求(读,写或读+写)的数量或大小](#request-quotas)
2. [命名空间中允许的表数](#namespace_quotas)
可以对指定的用户,表或命名空间强制实施这些限制。
启用配额
默认情况下禁用配额。要启用该功能,请在 _hbase-site.xml_ 文件中为所有群集节点将`hbase.quota.enabled`属性设置为`true`。
一般配额语法
1. THROTTLE_TYPE 可以表示为 READ,WRITE 或默认类型(读取+写入)。
2. 时间范围可以用以下单位表示:`sec`,`min`,`hour`,`day`
3. 请求大小可以用以下单位表示:`B`(字节),`K`(千字节),`M`(兆字节),`G`(千兆字节),`T`(兆兆字节),`P`(千兆字节) )
4. 请求数表示为整数,后跟字符串`req`
5. 与时间相关的限制表示为 req / time 或 size / time。例如`10req/day`或`100P/hour`。
6. 表或区域的数量表示为整数。
设置请求配额
您可以提前设置配额规则,也可以在运行时更改限制。配额刷新期到期后,更改将传播。此有效期默认为 5 分钟。要更改它,请修改`hbase-site.xml`中的`hbase.quota.refresh.period`属性。此属性以毫秒表示,默认为`300000`。
```
# Limit user u1 to 10 requests per second
hbase> set_quota TYPE => THROTTLE, USER => 'u1', LIMIT => '10req/sec'
# Limit user u1 to 10 read requests per second
hbase> set_quota TYPE => THROTTLE, THROTTLE_TYPE => READ, USER => 'u1', LIMIT => '10req/sec'
# Limit user u1 to 10 M per day everywhere
hbase> set_quota TYPE => THROTTLE, USER => 'u1', LIMIT => '10M/day'
# Limit user u1 to 10 M write size per sec
hbase> set_quota TYPE => THROTTLE, THROTTLE_TYPE => WRITE, USER => 'u1', LIMIT => '10M/sec'
# Limit user u1 to 5k per minute on table t2
hbase> set_quota TYPE => THROTTLE, USER => 'u1', TABLE => 't2', LIMIT => '5K/min'
# Limit user u1 to 10 read requests per sec on table t2
hbase> set_quota TYPE => THROTTLE, THROTTLE_TYPE => READ, USER => 'u1', TABLE => 't2', LIMIT => '10req/sec'
# Remove an existing limit from user u1 on namespace ns2
hbase> set_quota TYPE => THROTTLE, USER => 'u1', NAMESPACE => 'ns2', LIMIT => NONE
# Limit all users to 10 requests per hour on namespace ns1
hbase> set_quota TYPE => THROTTLE, NAMESPACE => 'ns1', LIMIT => '10req/hour'
# Limit all users to 10 T per hour on table t1
hbase> set_quota TYPE => THROTTLE, TABLE => 't1', LIMIT => '10T/hour'
# Remove all existing limits from user u1
hbase> set_quota TYPE => THROTTLE, USER => 'u1', LIMIT => NONE
# List all quotas for user u1 in namespace ns2
hbase> list_quotas USER => 'u1, NAMESPACE => 'ns2'
# List all quotas for namespace ns2
hbase> list_quotas NAMESPACE => 'ns2'
# List all quotas for table t1
hbase> list_quotas TABLE => 't1'
# list all quotas
hbase> list_quotas
```
您还可以通过应用`GLOBAL_BYPASS`属性来设置全局限制并从限制中排除用户或表。
```
hbase> set_quota NAMESPACE => 'ns1', LIMIT => '100req/min' # a per-namespace request limit
hbase> set_quota USER => 'u1', GLOBAL_BYPASS => true # user u1 is not affected by the limit
```
设置命名空间配额
通过在命名空间上设置`hbase.namespace.quota.maxtables property`,可以在创建命名空间时或通过更改现有命名空间来指定给定命名空间中允许的最大表或区域数。
每个命名空间限制表
```
# Create a namespace with a max of 5 tables
hbase> create_namespace 'ns1', {'hbase.namespace.quota.maxtables'=>'5'}
# Alter an existing namespace to have a max of 8 tables
hbase> alter_namespace 'ns2', {METHOD => 'set', 'hbase.namespace.quota.maxtables'=>'8'}
# Show quota information for a namespace
hbase> describe_namespace 'ns2'
# Alter an existing namespace to remove a quota
hbase> alter_namespace 'ns2', {METHOD => 'unset', NAME=>'hbase.namespace.quota.maxtables'}
```
每个命名空间限制区域
```
# Create a namespace with a max of 10 regions
hbase> create_namespace 'ns1', {'hbase.namespace.quota.maxregions'=>'10'
# Show quota information for a namespace
hbase> describe_namespace 'ns1'
# Alter an existing namespace to have a max of 20 tables
hbase> alter_namespace 'ns2', {METHOD => 'set', 'hbase.namespace.quota.maxregions'=>'20'}
# Alter an existing namespace to remove a quota
hbase> alter_namespace 'ns2', {METHOD => 'unset', NAME=> 'hbase.namespace.quota.maxregions'}
```
### 156.2。请求队列
如果未配置限制策略,则当 RegionServer 收到多个请求时,它们现在将被放入等待空闲执行槽的队列(HBASE-6721)。最简单的队列是 FIFO 队列,其中每个请求在运行之前等待队列中的所有先前请求完成。快速或交互式查询可能会滞后于大量请求。
如果您能够猜测请求需要多长时间,您可以通过将长请求推送到队列末尾并允许短请求抢占它们来重新排序请求。最终,您仍然必须执行大型请求并确定其后面的新请求的优先级。短请求将更新,因此结果并不可怕,但与允许将大量请求拆分为多个较小请求的机制相比仍然不是最理想的。
HBASE-10993 引入了这样一种系统,用于对长时间运行的扫描仪进行优先级排序。有两种类型的队列,`fifo`和`deadline`。要配置使用的队列类型,请在`hbase-site.xml`中配置`hbase.ipc.server.callqueue.type`属性。无法估计每个请求可能需要多长时间,因此取消优先级只会影响扫描,并且基于扫描请求所做的“下一次”调用的次数。假设当您进行全表扫描时,您的作业可能不是交互式的,因此如果存在并发请求,则可以通过设置`hbase.ipc.server.queue.max.call.delay`属性将长时间运行的扫描延迟到可调整的限制。延迟的斜率由`(numNextCall * weight)`的简单平方根计算,其中权重可通过设置`hbase.ipc.server.scan.vtime.weight`属性进行配置。
### 156.3。多类型队列
您还可以通过配置指定数量的专用处理程序和队列来确定不同类型请求的优先级或优先级。您可以使用单个处理程序在单个队列中隔离扫描请求,并且所有其他可用队列可以为短`Get`请求提供服务。
您可以使用静态调整选项根据工作负载类型调整 IPC 队列和处理程序。此方法是临时的第一步,最终将允许您在运行时更改设置,并根据负载动态调整值。
多个队列
为了避免争用并分离不同类型的请求,请配置`hbase.ipc.server.callqueue.handler.factor`属性,该属性允许您增加队列数量并控制可以共享同一队列的处理程序数量。允许管理员增加队列数量并确定多少处理程序共享同一队列。
使用更多队列可以在将任务添加到队列或从队列中选择任务时减少争用。您甚至可以为每个处理程序配置一个队列权衡是,如果某些队列包含长时间运行的任务,则处理程序可能需要等待从该队列执行而不是从具有等待任务的另一个队列中窃取。
读写队列
使用多个队列,您现在可以划分读取和写入请求,为一种或另一种类型提供更多优先级(更多队列)。使用`hbase.ipc.server.callqueue.read.ratio`属性选择提供更多读取或更多写入。
获取和扫描队列
与读/写拆分类似,您可以通过调整`hbase.ipc.server.callqueue.scan.ratio`属性来拆分获取和扫描,以便为获取或扫描提供更多优先级。 `0.1`的扫描比率将为传入的获取提供更多的队列/处理程序,这意味着可以同时处理更多的获取,并且可以同时执行更少的扫描。值`0.9`将为扫描提供更多队列/处理程序,因此执行的扫描次数将增加,并且获取次数将减少。
### 156.4。空间配额
[HBASE-16961](https://issues.apache.org/jira/browse/HBASE-16961) 为 HBase 引入了一种新的配额来利用:文件系统配额。这些“空间”配额限制了 HBase 名称空间和表可以使用的文件系统上的空间量。如果恶意或无知的用户有足够的时间将数据写入 HBase,则该用户可以通过消耗所有可用空间来有效地崩溃 HBase(或更糟糕的 HDFS)。当没有可用的文件系统空间时,HBase 崩溃,因为它无法再为预写日志创建/同步数据。
此功能允许在表或命名空间的大小上设置限制。在命名空间上设置空间配额时,配额的限制适用于该命名空间中所有表的使用总和。在具有配额的命名空间中存在具有配额的表时,表配额优先于命名空间配额。这允许可以对表集合施加大限制的情况,但该集合中的单个表可以具有细粒度限制集。
现有的`set_quota`和`list_quota` HBase shell 命令可用于与空间配额交互。空间配额是`TYPE` `SPACE`的配额,具有`LIMIT`和`POLICY`属性。 `LIMIT`是一个字符串,它指的是配额主题(例如表或命名空间)可能消耗的文件系统上的空间量。例如,`LIMIT`的有效值为`'10G'`,`'2T'`或`'256M'`。 `POLICY`是指当配额主体的使用量超过`LIMIT`时 HBase 将采取的行动。以下是有效的`POLICY`值。
* `NO_INSERTS` - 无法写入新数据(例如`Put`,`Increment`,`Append`)。
* `NO_WRITES` - 与`NO_INSERTS`相同,但`Deletes`也不允许。
* `NO_WRITES_COMPACTIONS` - 与`NO_WRITES`相同,但也不允许压缩。
* `DISABLE` - 禁用表,阻止所有读/写访问。
设置简单的空间配额
```
# Sets a quota on the table 't1' with a limit of 1GB, disallowing Puts/Increments/Appends when the table exceeds 1GB
hbase> set_quota TYPE => SPACE, TABLE => 't1', LIMIT => '1G', POLICY => NO_INSERTS
# Sets a quota on the namespace 'ns1' with a limit of 50TB, disallowing Puts/Increments/Appends/Deletes
hbase> set_quota TYPE => SPACE, NAMESPACE => 'ns1', LIMIT => '50T', POLICY => NO_WRITES
# Sets a quota on the table 't3' with a limit of 2TB, disallowing any writes and compactions when the table exceeds 2TB.
hbase> set_quota TYPE => SPACE, TABLE => 't3', LIMIT => '2T', POLICY => NO_WRITES_COMPACTIONS
# Sets a quota on the table 't2' with a limit of 50GB, disabling the table when it exceeds 50GB
hbase> set_quota TYPE => SPACE, TABLE => 't2', LIMIT => '50G', POLICY => DISABLE
```
请考虑以下方案在命名空间上设置配额,覆盖该命名空间中表的配额
表和命名空间空间配额
```
hbase> create_namespace 'ns1'
hbase> create 'ns1:t1'
hbase> create 'ns1:t2'
hbase> create 'ns1:t3'
hbase> set_quota TYPE => SPACE, NAMESPACE => 'ns1', LIMIT => '100T', POLICY => NO_INSERTS
hbase> set_quota TYPE => SPACE, TABLE => 'ns1:t2', LIMIT => '200G', POLICY => NO_WRITES
hbase> set_quota TYPE => SPACE, TABLE => 'ns1:t3', LIMIT => '20T', POLICY => NO_WRITES
```
在上面的场景中,名称空间`ns1`中的表将不允许在文件系统之间消耗超过 100TB 的空间。表'ns1:t2'的大小仅允许为 200GB,并且当使用率超过此限制时将禁止所有写入。表'ns1:t3'的大小允许增长到 20TB,并且还将禁止所有写入,然后使用超出此限制。由于'ns1:t1'上没有表配额,因此该表可以增长到 100TB,但仅当'ns1:t2'和'ns1:t3'使用零字节时才会增长。实际上,它的限制是'ns1:t2'和'ns1:t3'的当前使用量减去 100TB。
### 156.5。禁用自动空间配额删除
默认情况下,如果删除具有空间配额的表或命名空间,则也会删除配额本身。在某些情况下,可能需要不自动删除空间配额。在这些情况下,用户可以将系统配置为不通过 hbase-site.xml 自动删除任何空间配额。
```
<property>
<name>hbase.quota.remove.on.table.delete</name>
<value>false</value>
</property>
```
默认情况下,该值设置为`true`。
### 156.6。具有空间配额的 HBase 快照
与 HBase 一起使用的非预期文件系统的一个常见区域是通过 HBase 快照。由于快照存在于 HBase 表管理之外,因此管理员突然意识到 HBase 快照正在使用数百 GB 或 TB 的空间并且这些空间被遗忘并且从未被删除的情况并不少见。
[HBASE-17748](https://issues.apache.org/jira/browse/HBASE-17748) 是一个伞形 JIRA 问题,它扩展了原始空间配额功能,还包括 HBase 快照。虽然这是一个令人困惑的主题,但实现尝试以尽可能合理和简单的方式为管理员提供此支持。此功能不会对管理员与空间配额的交互进行任何更改,仅在表/命名空间使用的内部计算中进行。表和命名空间使用将根据下面定义的规则自动合并快照占用的大小。
作为回顾,我们将介绍快照的生命周期:快照是指向文件系统上的 HFile 列表的元数据。这就是为什么创建快照是一个非常便宜的操作;实际上没有复制 HBase 表数据来执行快照。出于同样的原因,将快照克隆到新表或恢复表是一种廉价的操作;新表引用文件系统中已存在但没有副本的文件。要在空间配额中包含快照,我们需要在快照引用文件时定义哪个表“拥有”文件(“拥有”是指包含该文件的文件系统用法)。
考虑针对表格创建的快照。当快照引用文件并且表不再引用该文件时,“originating”表“拥有”该文件。当多个快照引用同一文件且没有表引用该文件时,将选择具有最低排序名称(按字典顺序排列)的快照,并且从“拥有”该文件创建该快照的表。 HFile 不是“重复计算”的表,而一个或多个快照指的是 HFile。
当表格“重新物化”时(通过`clone_snapshot`或`restore_snapshot`),会出现类似的文件所有权问题。在这种情况下,虽然重新表示的表引用了快照也引用的文件,但该表并不“拥有”该文件。创建快照的表仍然“拥有”该文件。当压缩重新实现的表或删除快照时,重新实现的表将唯一地引用新文件并“拥有”该文件的使用。类似地,当通过快照和`restore_snapshot`复制表时,新表将不会消耗任何配额大小,直到原始表停止引用文件,原因是由于原始表上的压缩,新表上的压缩,或原始表被删除。
添加了一个新的 HBase shell 命令来检查 HBase 实例中每个快照的计算大小。
```
hbase> list_snapshot_sizes
SNAPSHOT SIZE
t1.s1 1159108
```
## 157\. HBase 备份
执行 HBase 备份有两种广泛的策略:使用完全群集关闭进行备份,以及在实时群集上备份。每种方法都有利有弊。
有关其他信息,请参阅 Sematext 博客上的 [HBase 备份选项](http://blog.sematext.com/2011/03/11/hbase-backup-options/)。
### 157.1。完全关机备份
某些环境可以容忍其 HBase 群集的定期完全关闭,例如,如果它正在使用后端分析容量而不是服务于前端 Web 页面。好处是 NameNode / Master 是 RegionServers 已关闭,因此没有机会错过对 StoreFiles 或元数据的任何正在进行的更改。显而易见的是群集已关闭。步骤包括:
#### 157.1.1。停止 HBase
#### 157.1.2。 DistCp 使用
Distcp 可用于将 HDFS 中 HBase 目录的内容复制到另一个目录中的同一群集,或复制到另一个群集。
注意:Distcp 适用于这种情况,因为群集已关闭,并且没有对文件的正在进行的编辑。通常不建议在实时群集上对 HBase 目录中的文件进行分拣。
#### 157.1.3。恢复(如果需要)
从 HDFS 备份 hbase 目录通过 distcp 复制到'real'hbase 目录。复制这些文件的行为会创建新的 HDFS 元数据,这就是为什么这种恢复不需要从 HBase 备份时恢复 NameNode 的原因,因为它是特定 HDFS 目录的恢复(通过 distcp) (即 HBase 部分)不是整个 HDFS 文件系统。
### 157.2。实时群集备份 - 复制
此方法假定存在第二个集群。有关详细信息,请参阅[复制](https://hbase.apache.org/book.html#_cluster_replication)上的 HBase 页面。
### 157.3。实时群集备份 - CopyTable
[copytable](#copy.table) 实用程序可用于将数据从一个表复制到同一个集群上的另一个表,或者将数据复制到另一个集群上的另一个表。
由于群集已启动,因此存在复制过程中可能遗漏编辑的风险。
### 157.4。实时群集备份 - 导出
[export](#export) 方法将表的内容转储到同一群集上的 HDFS。要恢复数据,将使用 [import](#import) 实用程序。
由于群集已启动,因此存在导出过程中可能错过编辑的风险。
## 158\. HBase 快照
HBase 快照允许您获取表的副本(包括内容和元数据),并且性能影响非常小。快照是表元数据的不可变集合,以及在拍摄快照时包含表的 HFile 列表。快照的“克隆”从该快照创建新表,快照的“恢复”将表的内容返回到创建快照时的内容。 “克隆”和“恢复”操作不需要复制任何数据,因为底层 HFiles(包含 HBase 表数据的文件)不会被任何操作修改。 Simiarly,将快照导出到另一个集群对本地集群的 RegionServers 几乎没有影响。
在版本 0.94.6 之前,备份或克隆表的唯一方法是使用 CopyTable / ExportTable,或者在禁用表后复制 HDFS 中的所有 hfiles。这些方法的缺点是您可以降低区域服务器性能(复制/导出表),或者您需要禁用表,这意味着没有读取或写入;这通常是不可接受的。
### 158.1。组态
要打开快照支持,只需将`hbase.snapshot.enabled`属性设置为 true 即可。 (默认情况下,快照在 0.95+中启用,默认情况下在 0.94.6+时关闭)
```
<property>
<name>hbase.snapshot.enabled</name>
<value>true</value>
</property>
```
### 158.2。拍一张快照
无论是启用还是禁用,您都可以创建表的快照。快照操作不涉及任何数据复制。
```
$ ./bin/hbase shell
hbase> snapshot 'myTable', 'myTableSnapshot-122112'
```
拍摄快照而不刷新
默认行为是在拍摄快照之前在内存中执行数据刷新。这意味着内存中的数据包含在快照中。在大多数情况下,这是期望的行为。但是,如果您的设置可以容忍从快照中排除内存中的数据,则可以使用`snapshot`命令的`SKIP_FLUSH`选项在拍摄快照时禁用和刷新。
```
hbase> snapshot 'mytable', 'snapshot123', {SKIP_FLUSH => true}
```
> 无论是启用还是禁用刷新,都无法确定或预测给定快照中是否包含非常并发的插入或更新。快照仅是时间窗口中表的表示。快照操作到达每个区域服务器所花费的时间可能从几秒到一分钟不等,具体取决于资源负载和硬件或网络的速度等因素。也无法知道给定的插入或更新是在内存中还是已刷新。
### 158.3。列出快照
列出所有拍摄的快照(通过打印名称和相关信息)。
```
$ ./bin/hbase shell
hbase> list_snapshots
```
### 158.4。删除快照
您可以删除快照,如果不再需要,将删除为该快照保留的文件。
```
$ ./bin/hbase shell
hbase> delete_snapshot 'myTableSnapshot-122112'
```
### 158.5。从快照克隆表
从快照中,您可以创建一个新表(克隆操作),其中包含拍摄快照时的相同数据。克隆操作不涉及数据副本,对克隆表的更改不会影响快照或原始表。
```
$ ./bin/hbase shell
hbase> clone_snapshot 'myTableSnapshot-122112', 'myNewTestTable'
```
### 158.6。恢复快照
还原操作需要禁用表,并且表将恢复到拍摄快照时的状态,如果需要,还会更改数据和架构。
```
$ ./bin/hbase shell
hbase> disable 'myTable'
hbase> restore_snapshot 'myTableSnapshot-122112'
```
> 由于 Replication 在日志级别工作,而快照在文件系统级别工作,因此在还原之后,副本将与主服务器处于不同的状态。如果要使用还原,则需要停止复制并重做引导程序。
如果由于行为不当而导致部分数据丢失,而不是需要禁用表的完全恢复,您可以从快照克隆表并使用 Map-Reduce 作业从您复制所需的数据,克隆到主要的一个。
### 158.7。快照操作和 ACL
如果您使用 AccessController 协处理器的安全性(请参阅 [hbase.accesscontrol.configuration](#hbase.accesscontrol.configuration) ),则只有全局管理员才能获取,克隆或还原快照,并且这些操作不会捕获 ACL 权限。这意味着还原表会保留现有表的 ACL 权限,而克隆表会创建一个没有 ACL 权限的新表,直到管理员添加它们为止。
### 158.8。导出到另一个群集
ExportSnapshot 工具将与快照(hfiles,日志,快照元数据)相关的所有数据复制到另一个群集。该工具执行类似于 distcp 的 Map-Reduce 作业,以在两个集群之间复制文件,并且由于它在文件系统级别工作,因此 hbase 集群不必在线。
使用 16 个映射器将名为 MySnapshot 的快照复制到 HBase 集群 srv2(hdfs:/// srv2:8082 / hbase):
```
$ bin/hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot MySnapshot -copy-to hdfs://srv2:8082/hbase -mappers 16
```
限制带宽消耗
您可以通过指定`-bandwidth`参数来限制导出快照时的带宽消耗,该参数需要一个表示每秒兆字节数的整数。以下示例将上述示例限制为 200 MB /秒。
```
$ bin/hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot MySnapshot -copy-to hdfs://srv2:8082/hbase -mappers 16 -bandwidth 200
```
### 158.9。将快照存储在 Amazon S3 存储桶中
您可以使用以下过程从 Amazon S3 存储和检索快照。
> 您还可以在 Microsoft Azure Blob 存储中存储快照。请参阅[在 Microsoft Azure Blob 存储](#snapshots_azure)中存储快照。
先决条件
* 您必须使用 HBase 1.0 或更高版本以及 Hadoop 2.6.1 或更高版本,这是第一个使用 Amazon AWS SDK 的配置。
* 您必须使用`s3a://`协议连接到 Amazon S3。旧的`s3n://`和`s3://`协议有各种限制,不使用 Amazon AWS SDK。
* 必须在运行用于导出和还原快照的命令的服务器上配置`s3a://` URI 并使其可用。
完成先决条件后,像平常一样拍摄快照。之后,您可以使用`org.apache.hadoop.hbase.snapshot.ExportSnapshot`命令将其导出,如下所示,替换`copy-from`或`copy-to`指令中您自己的`s3a://`路径,并根据需要替换或修改其他选项:
```
$ hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot MySnapshot \
-copy-from hdfs://srv2:8082/hbase \
-copy-to s3a://<bucket>/<namespace>/hbase \
-chuser MyUser \
-chgroup MyGroup \
-chmod 700 \
-mappers 16
```
```
$ hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot MySnapshot
-copy-from s3a://<bucket>/<namespace>/hbase \
-copy-to hdfs://srv2:8082/hbase \
-chuser MyUser \
-chgroup MyGroup \
-chmod 700 \
-mappers 16
```
您也可以通过包含`-remote-dir`选项将`org.apache.hadoop.hbase.snapshot.SnapshotInfo`实用程序与`s3a://`路径一起使用。
```
$ hbase org.apache.hadoop.hbase.snapshot.SnapshotInfo \
-remote-dir s3a://<bucket>/<namespace>/hbase \
-list-snapshots
```
## 159.在 Microsoft Azure Blob 存储中存储快照
您可以使用与[在 Amazon S3 存储桶中存储快照](#snapshots_s3)中相同的技术将快照存储在 Microsoft Azure 博客存储中。
Prerequisites
* 您必须在 Hadoop 2.7.1 或更高版本上使用 HBase 1.2 或更高版本。没有版本的 HBase 支持 Hadoop 2.7.0。
* 必须将主机配置为了解 Azure Blob 存储文件系统。见 [https://hadoop.apache.org/docs/r2.7.1/hadoop-azure/index.html](https://hadoop.apache.org/docs/r2.7.1/hadoop-azure/index.html) 。
满足先决条件后,请按照[在 Amazon S3 存储桶中存储快照](#snapshots_s3)中的说明,将协议说明符替换为`wasb://`或`wasbs://`。
## 160.能力规划和区域规划
在规划 HBase 群集的容量和执行初始配置时,需要考虑几个因素。首先要充分了解 HBase 如何在内部处理数据。
### 160.1。节点计数和硬件/ VM 配置
#### 160.1.1。物理数据大小
磁盘上的物理数据大小与数据的逻辑大小不同,并受以下因素影响:
* HBase 开销增加
* 参见 [keyvalue](#keyvalue) 和 [keysize](#keysize) 。每个键值(单元格)至少 24 个字节可以更多。小键/值意味着更多的相对开销。
* KeyValue 实例聚合为块,这些块已编制索引。索引也必须存储。 Blocksize 可以基于每个 ColumnFamily 进行配置。见 [regions.arch](#regions.arch) 。
* 由[压缩](#compression)和数据块编码减少,具体取决于数据。另见[这个帖子](http://search-hadoop.com/m/lL12B1PFVhp1)。您可能希望测试哪些压缩和编码(如果有)对您的数据有意义。
* 区域服务器 [wal](#wal) 的大小增加(通常固定且可忽略不计 - 小于 RS 内存大小的一半,每 RS)。
* HDFS 复制增加 - 通常是 x3。
除了存储数据所需的磁盘空间之外,由于区域计数和大小的一些实际限制,一个 RS 可能无法提供任意大量的数据(参见 [ops.capacity.regions](#ops.capacity.regions) )。
#### 160.1.2。读/写吞吐量
节点数也可以由读取和/或写入所需的吞吐量驱动。每个节点可以获得的吞吐量很大程度上取决于数据(尤其是密钥/值大小)和请求模式,以及节点和系统配置。如果负载可能是节点数量增加的主要驱动因素,则应该针对峰值负载进行规划。 PerformanceEvaluation 和 [ycsb](#ycsb) 工具可用于测试单个节点或测试集群。
对于写入,通常每个 RS 可以达到 5-15Mb / s,因为每个区域服务器只有一个活动的 WAL。读取没有很好的估计,因为它很大程度上取决于数据,请求和缓存命中率。 [perf.casestudy](#perf.casestudy) 可能会有帮助。
#### 160.1.3。 JVM GC 限制
由于 GC 的成本,RS 目前无法使用非常大的堆。每个服务器运行多个 RS-es 也没有好办法(除了每台机器运行多个 VM)。因此,建议专用于一个 RS 的~20-24Gb 或更少的存储器。大堆大小需要 GC 调整。参见 [gcpause](#gcpause) , [trouble.log.gc](#trouble.log.gc) 和其他地方(TODO:哪里?)
### 160.2。确定区域数量和大小
通常较少的区域使得运行集群更加平滑(您可以随后手动拆分大区域(如果需要)以在集群上传播数据或请求加载);每个 RS 20-200 个区域是合理的范围。无法直接配置区域数量(除非您完全 [disable.splitting](#disable.splitting) );调整区域大小以达到给定表大小的目标区域大小。
为多个表配置区域时,请注意,可以通过 [HTableDescriptor](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/HTableDescriptor.html) 以及 shell 命令在每个表的基础上设置大多数区域设置。这些设置将覆盖`hbase-site.xml`中的设置。如果您的表具有不同的工作负载/用例,那么这很有用。
另请注意,在这里讨论区域大小时, _HDFS 复制因子不会(也不应该)被考虑在内,而其他因素 [ops.capacity.nodes.datasize](#ops.capacity.nodes.datasize) 应该是。_ 因此,如果你的数据被 HDFS 压缩和复制 3 种方式,“9 Gb 区域”意味着 9 Gb 的压缩数据。 HDFS 复制因子仅影响磁盘使用,对大多数 HBase 代码不可见。
#### 160.2.1。查看当前的区域数量
您可以使用 HMaster UI 查看给定表的当前区域数。在“表”部分中,“在线区域”列中列出了每个表的联机区域数。此总计仅包括内存中状态,不包括禁用或脱机区域。
#### 160.2.2。每个 RS 的区域数 - 上限
在生产场景中,如果您拥有大量数据,通常会关注每台服务器可以拥有的最大区域数。 [太多地区](#too_many_regions)就此问题进行了技术讨论。基本上,区域的最大数量主要由 memstore 内存使用量决定。每个地区都有自己的 memstore;它们长大到可配置的大小;通常在 128-256 MB 范围内,请参见 [hbase.hregion.memstore.flush.size](#hbase.hregion.memstore.flush.size) 。每个列族存在一个 memstore(因此,如果表中有一个 CF,则每个区域只有一个)。 RS 将总内存的一部分专用于其存储器(参见 [hbase.regionserver.global.memstore.size](#hbase.regionserver.global.memstore.size) )。如果超出此内存(memstore 使用率过高),则可能会导致不良后果,例如无响应的服务器或压缩风暴。每个 RS 的区域数量(假设一个表)的良好起点是:
```
((RS memory) * (total memstore fraction)) / ((memstore size)*(# column families))
```
这个公式是伪代码。以下是使用实际可调参数的两个公式,首先是 HBase 0.98+,第二个是 HBase 0.94.x.
HBase 0.98.x
```
((RS Xmx) * hbase.regionserver.global.memstore.size) / (hbase.hregion.memstore.flush.size * (# column families))
```
HBase 0.94.x
```
((RS Xmx) * hbase.regionserver.global.memstore.upperLimit) / (hbase.hregion.memstore.flush.size * (# column families))+
```
如果给定的 RegionServer 具有 16 GB 的 RAM,并且具有默认设置,则该公式可以达到 16384 * 0.4 / 128~51 个区域,每个 RS 是一个起点。公式可以扩展到多个表;如果它们都具有相同的配置,只需使用总系列数。
这个数字可以调整;上面的公式假设您所有的区域都以大致相同的速率填充。如果只有一部分区域将被主动写入,则可以将结果除以该分数以获得更大的区域计数。然后,即使写入所有区域,也不会均匀地填充所有区域存储器,并且最终出现抖动,即使它们是(由于并发刷新的数量有限)。因此,人们可以拥有比起点多 2-3 倍的区域;然而,增加的数字会增加风险。
对于写入繁重的工作负载,可以在配置中增加 memstore 分数,但代价是块缓存;这也将允许一个人拥有更多的地区。
#### 160.2.3。每个 RS 的区域数 - 下限
HBase 通过跨多个服务器的区域来扩展。因此,如果您有 16 个数据的 2 个区域,则在 20 节点计算机上,您的数据将集中在几台计算机上 - 几乎整个群集都将处于空闲状态。这真的不够强调,因为一个常见的问题是将 200MB 数据加载到 HBase 中,然后想知道为什么你真棒的 10 节点集群没有做任何事情。
另一方面,如果您拥有大量数据,您可能还需要选择更多区域以避免区域过大。
#### 160.2.4。最大区域大小
对于生产场景中的大型表,最大区域大小主要受到压缩的限制 - 非常大的压缩,尤其是压缩。 major,会降低集群性能。目前,推荐的最大区域大小为 10-20Gb,最佳区域为 5-10Gb。对于较早的 0.90.x 代码库,regionsize 的上限约为 4Gb,默认值为 256Mb。
区域分成两部分的大小通常通过 [hbase.hregion.max.filesize](#hbase.hregion.max.filesize) 配置;有关详细信息,请参阅 [arch.region.splits](#arch.region.splits) 。
如果你不能很好地估计表的大小,那么在开始时,最好坚持使用默认的区域大小,对于热表可能会更小(或者手动拆分热区以将负载分散到集群上),或者与如果您的细胞大小往往较大(100k 及以上),则区域尺寸较大。
在 HBase 0.98 中,添加了实验条带压缩功能,允许更大的区域,特别是对于日志数据。见 [ops.stripe](#ops.stripe) 。
#### 160.2.5。每个区域服务器的总数据大小
根据区域大小和每个区域服务器区域数量的上述数字,在乐观估计中,每个 RS 10 GB×100 个区域将为每个区域服务器提供高达 1TB 的服务,这与一些报告的多 PB 用例一致。但是,重要的是要考虑 RS 级别的数据与缓存大小比率。每个服务器有 1TB 的数据和 10 GB 的块缓存,只有 1%的数据会被缓存,这几乎不能覆盖所有的块索引。
### 160.3。初始配置和调整
首先,参见[重要配置](#important_configurations)。请注意,某些配置(多于其他配置)取决于特定方案。特别注意:
* [hbase.regionserver.handler.count](#hbase.regionserver.handler.count) - 请求处理程序线程数,对高吞吐量工作负载至关重要。
* [config.wals](#config.wals) - WAL 文件的阻塞数量取决于您的 memstore 配置,应相应地设置以防止在执行大量写入时可能阻塞。
然后,在设置群集和表时需要考虑一些因素。
#### 160.3.1。 Compactions
根据读/写卷和延迟要求,最佳压缩设置可能不同。有关详细信息,请参见[压缩](#compaction)。
但是,在为大数据量配置时,请记住压缩会影响写入吞吐量。因此,对于写入密集型工作负载,您可以选择较少频繁的压缩和每个区域的更多存储文件。压缩的最小文件数(`hbase.hstore.compaction.min`)可以设置为更高的值; [hbase.hstore.blockingStoreFiles](#hbase.hstore.blockingStoreFiles) 也应该增加,因为在这种情况下可能会累积更多文件。您也可以考虑手动管理压缩: [managed.compactions](#managed.compactions)
#### 160.3.2。预分割表格
根据每个 RS 的区域的目标数量(参见 [ops.capacity.regions.count](#ops.capacity.regions.count) )和 RS 的数量,可以在创建时预分割表。当表开始填满时,这将避免一些昂贵的拆分,并确保表已经分布在许多服务器上。
如果预计该表会增长到足以证明其合理性,则应创建每个 RS 至少一个区域。不建议立即分成完整目标区域数(例如 50 * RSes 数),但可以选择低中间值。对于多个表,建议保守预分裂(例如,每个 RS 最多预分割 1 个区域),特别是如果您不知道每个表将增长多少。如果分割太多,最终可能会出现太多区域,某些表区域的区域太多。
对于预分割方法,请参见[手动区域分割决策](#manual_region_splitting_decisions)和 [precreate.regions](#precreate.regions) 。
## 161.表重命名
在 hbase 及更早版本的 0.90.x 版本中,我们有一个简单的脚本,它将重命名 hdfs 表目录,然后编辑 hbase:meta 表,用 new 替换旧表名的所有提及。该脚本被称为`./bin/rename_table.rb`。该脚本已被弃用和删除,主要是因为它没有维护并且脚本执行的操作是残酷的。
从 hbase 0.94.x 开始,您可以使用快照工具重命名表。以下是使用 hbase shell 的方法:
```
hbase shell> disable 'tableName'
hbase shell> snapshot 'tableName', 'tableSnapshot'
hbase shell> clone_snapshot 'tableSnapshot', 'newTableName'
hbase shell> delete_snapshot 'tableSnapshot'
hbase shell> drop 'tableName'
```
或者在代码中它将如下:
```
void rename(Admin admin, String oldTableName, TableName newTableName) {
String snapshotName = randomName();
admin.disableTable(oldTableName);
admin.snapshot(snapshotName, oldTableName);
admin.cloneSnapshot(snapshotName, newTableName);
admin.deleteSnapshot(snapshotName);
admin.deleteTable(oldTableName);
}
```
## 162\. RegionServer 分组
RegionServer Grouping(A.K.A `rsgroup`)是一种高级功能,用于将区域服务器划分为独特的组以进行严格隔离。它只应由足够复杂的用户使用,以便了解完整的含义并具有足够的背景来管理 HBase 集群。它是由雅虎开发的!并且他们在大型网格集群上大规模运行它。请参阅雅虎的 [HBase!比例](http://www.slideshare.net/HBaseCon/keynote-apache-hbase-at-yahoo-scale)。
RSGroups 是使用 shell 命令定义和管理的。 shell 驱动一个 Coprocessor 端点,其 API 被标记为私有,因为这是一个不断发展的功能;协处理器 API 不供公众使用。可以将服务器添加到具有主机名和端口对的组中,并且可以将表移动到该组,以便只有同一 rsgroup 中的区域服务器可以托管表的区域。 RegionServers 和表一次只能属于一个 rsgroup。默认情况下,所有表和区域服务器都属于`default` rsgroup。系统表也可以使用常规 API 放入 rsgroup。自定义平衡器实现跟踪每个 rsgroup 的分配,并确保将区域移动到该 rsgroup 中的相关区域服务器。 rsgroup 信息存储在常规 HBase 表中,并且在集群引导时使用基于 zookeeper 的只读缓存。
要启用,请将以下内容添加到 hbase-site.xml 并重新启动主服务器:
```
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.rsgroup.RSGroupAdminEndpoint</value>
</property>
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.hadoop.hbase.rsgroup.RSGroupBasedLoadBalancer</value>
</property>
```
然后使用 shell _rsgroup_ 命令创建和操作 RegionServer 组:例如添加一个 rsgroup,然后添加一个服务器。要查看 hbase shell 类型中可用的 rsgroup 命令列表,请执行以下操作:
```
hbase(main):008:0> help ‘rsgroup’
Took 0.5610 seconds
```
高级别,使用 _add _rsgroup_ 命令创建一个不同于`default`组的 rsgroup。然后使用 _move_servers _rsgroup_ 和 _move_tables _rsgroup_ 命令将服务器和表添加到该组。如果表格很慢,请使用 _balance _rsgroup_ 命令迁移到组专用服务器(如果不需要),则必要时为组运行余额。要监视命令的效果,请参阅 Master UI 主页末尾的`Tables`选项卡。如果单击某个表,则可以查看它所部署的服务器。您应该在这里看到使用 shell 命令完成的分组的反映。如果出现问题,请查看主日志。
以下是使用一些 rsgroup 命令的示例。要添加组,请执行以下操作:
```
hbase(main):008:0> add_rsgroup 'my_group'
Took 0.5610 seconds
```
> 必须启用 RegionServer Groups
>
> 如果尚未在主服务器中启用 rsgroup 协处理器端点,并且运行任何 rsgroup shell 命令,您将看到如下错误消息:
>
> ```
> ERROR: org.apache.hadoop.hbase.exceptions.UnknownProtocolException: No registered master coprocessor service found for name RSGroupAdminService
> at org.apache.hadoop.hbase.master.MasterRpcServices.execMasterService(MasterRpcServices.java:604)
> at org.apache.hadoop.hbase.shaded.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java)
> at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:1140)
> at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:133)
> at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:277)
> at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:257)
> ```
使用 _move_servers _rsgroup_ 命令将服务器(由主机名+端口指定)添加到刚创组中,如下所示:
```
hbase(main):010:0> move_servers_rsgroup 'my_group',['k.att.net:51129']
```
> 主机名和端口与 ServerNam
>
> rsgroup 功能是指群集中仅具有主机名和端口的服务器。它不使用标识 RegionServers 的 HBase ServerName 类型; ie hostname + port + starttime 来区分 RegionServer 实例。 rsgroup 功能在 RegionServer 重新启动时保持工作,因此 ServerName 的启动时间 - 因此 ServerName 类型 - 不合适。管理
服务器在群集的生命周期中来回走动。目前,您必须手动将 rsgroups 中引用的服务器与正在运行的集群中的节点的实际状态对齐。我们的意思是,如果您停用服务器,那么您必须更新 rsgroups 作为服务器停用过程中删除引用的一部分。
但是,你说没有 _remove_offline_servers_rsgroup_command!
删除服务器的方法是将其移动到`default`组。 `default`组很特别。所有 rsgroup,但`default` rsgroup,都是静态的,因为通过 shell 命令进行的编辑会持久保存到系统`hbase:rsgroup`表中。如果它们引用了已停用的服务器,则需要更新它们以撤消引用。
`default`组与其他 rsgroup 不同,因为它是动态的。其服务器列表镜像了集群的当前状态;即如果您关闭属于`default` rsgroup 的服务器,然后执行 _get _rsgroup_ `default`以在 shell 中列出其内容,则将不再列出服务器。对于非`default`组,虽然模式可能处于脱机状态,但它将保留在非`default`组的服务器列表中。但是,如果将脱机服务器从非默认 rsgroup 移动到默认值,它将不会显示在`default`列表中。它将被删除。
### 162.1。最佳实践
rsgroup 功能的作者,雅虎! HBase 工程团队已经在他们的网格上运行了很长一段时间,并根据他们的经验提出了一些最佳实践。
#### 162.1.1。隔离系统表
有一个系统 rsgroup,其中所有系统表都是或者只是将系统表保留在`default` rsgroup 中,并且所有用户空间表都在非`default` rsgroups 中。
#### 162.1.2。死节点
雅虎已经发现它在规模上有用,可以保留特殊的死组或可疑节点组;这是一种让它们在运行之前保持运行的方法。
小心替换 rsgroup 中的死节点。确保在开始移除死亡之前有足够的活动节点。如果必须,首先移动好的实时节点。
### 162.2。故障排除
查看主日志将为您提供有关 rsgroup 操作的信息。
如果卡住,请重新启动主进程。
### 162.3。删除 RegionServer 分组
除了从`hbase-site.xml`中删除相关属性之外,从启用了它的群集中删除 RegionServer 分组功能还涉及更多步骤。这是为了清除 RegionServer 分组相关的元数据,以便在将来重新启用该功能时,旧的元数据不会影响群集的功能。
* 将非默认 rsgroup 中的所有表移动到`default` regionserver 组
```
#Reassigning table t1 from non default group - hbase shell
hbase(main):005:0> move_tables_rsgroup 'default',['t1']
```
* 将非默认 rsgroup 中的所有 regionservers 移动到`default` regionserver 组
```
#Reassigning all the servers in the non-default rsgroup to default - hbase shell
hbase(main):008:0> move_servers_rsgroup 'default',['rs1.xxx.com:16206','rs2.xxx.com:16202','rs3.xxx.com:16204']
```
* 删除所有非默认 rsgroups。隐式创建的`default` rsgroup 不必删除
```
#removing non default rsgroup - hbase shell
hbase(main):009:0> remove_rsgroup 'group2'
```
* 删除`hbase-site.xml`中所做的更改并重新启动群集
* 从`hbase`中删除表`hbase:rsgroup`
```
#Through hbase shell drop table hbase:rsgroup
hbase(main):001:0> disable 'hbase:rsgroup'
0 row(s) in 2.6270 seconds
hbase(main):002:0> drop 'hbase:rsgroup'
0 row(s) in 1.2730 seconds
```
* 使用 zkCli.sh 从集群 ZooKeeper 中删除 znode `rsgroup`
```
#From ZK remove the node /hbase/rsgroup through zkCli.sh
rmr /hbase/rsgroup
```
### 162.4。 ACL
要启用 ACL,请将以下内容添加到 hbase-site.xml 并重新启动 Master:
```
<property>
<name>hbase.security.authorization</name>
<value>true</value>
<property>
```
## 163\. Region Normalizer
Region Normalizer 尝试在表中创建大小相同的区域。它通过找到粗略的平均值来做到这一点。任何大于这个大小两倍的区域都会被拆分。任何小得多的区域都会合并到一个相邻区域。最好在群集运行一段时间之后的停机时间运行 Normalizer,或者在一系列活动(例如大型删除)之后说。
(下面的大部分内容是由 Romil Choksi 在 [HBase Region Normalizer](https://community.hortonworks.com/articles/54987/hbase-region-normalizer.html) )的博客中批发复制的。
区域规范化器自 HBase-1.2 起可用。它运行一组预先计算的合并/拆分操作,以调整与给定表的平均区域大小相比太大或太小的区域。调用时的 Region Normalizer 计算 HBase 中所有表的规范化“计划”。在计算计划时,将忽略系统表(例如 hbase:meta,hbase:命名空间,Phoenix 系统表等)和禁用规范化的用户表。对于启用规范化的表,规范化计划跨多个表并行执行。
可以使用 HBase shell 中的“normalizer_switch”命令为整个集群全局启用或禁用 Normalizer。还可以基于每个表控制规范化,默认情况下在创建表时禁用规范化。通过将 NORMALIZATION_ENABLED 表属性设置为 true 或 false,可以启用或禁用表的规范化。
检查规范器状态并启用/禁用规范化器
```
hbase(main):001:0> normalizer_enabled
true
0 row(s) in 0.4870 seconds
hbase(main):002:0> normalizer_switch false
true
0 row(s) in 0.0640 seconds
hbase(main):003:0> normalizer_enabled
false
0 row(s) in 0.0120 seconds
hbase(main):004:0> normalizer_switch true
false
0 row(s) in 0.0200 seconds
hbase(main):005:0> normalizer_enabled
true
0 row(s) in 0.0090 seconds
```
启用后,每 5 分钟(默认情况下)在后台调用 Normalizer,可以使用`hbase-site.xml`中的`hbase.normalization.period`进行配置。也可以使用 HBase shell 的`normalize`命令手动/编程调用 Normalizer。 HBase 默认使用`SimpleRegionNormalizer`,但只要用户实现 RegionNormalizer 接口,用户就可以设计自己的规范化器。有关`SimpleRegionNormalizer`用于计算其归一化计划的逻辑的详细信息,请参见 [](https://hbase.apache.org/devapidocs/org/apache/hadoop/hbase/master/normalizer/SimpleRegionNormalizer.html) 。
下面的示例显示了为用户表计算的规范化计划,以及由 SimpleRegionNormalizer 计算的规范化计划的结果。
考虑具有一些预分割区域的用户表,所述预分割区域具有 3 个相等大的区域(大约 100K 行)和 1 个相对小的区域(大约 25K 行)。以下是 hbase 元表扫描的片段,显示用户表的每个预分割区域。
```
table_p8ddpd6q5z,,1469494305548.68b9892220865cb6048 column=info:regioninfo, timestamp=1469494306375, value={ENCODED => 68b9892220865cb604809c950d1adf48, NAME => 'table_p8ddpd6q5z,,1469494305548.68b989222 09c950d1adf48\. 0865cb604809c950d1adf48.', STARTKEY => '', ENDKEY => '1'}
....
table_p8ddpd6q5z,1,1469494317178.867b77333bdc75a028 column=info:regioninfo, timestamp=1469494317848, value={ENCODED => 867b77333bdc75a028bb4c5e4b235f48, NAME => 'table_p8ddpd6q5z,1,1469494317178.867b7733 bb4c5e4b235f48\. 3bdc75a028bb4c5e4b235f48.', STARTKEY => '1', ENDKEY => '3'}
....
table_p8ddpd6q5z,3,1469494328323.98f019a753425e7977 column=info:regioninfo, timestamp=1469494328486, value={ENCODED => 98f019a753425e7977ab8636e32deeeb, NAME => 'table_p8ddpd6q5z,3,1469494328323.98f019a7 ab8636e32deeeb. 53425e7977ab8636e32deeeb.', STARTKEY => '3', ENDKEY => '7'}
....
table_p8ddpd6q5z,7,1469494339662.94c64e748979ecbb16 column=info:regioninfo, timestamp=1469494339859, value={ENCODED => 94c64e748979ecbb166f6cc6550e25c6, NAME => 'table_p8ddpd6q5z,7,1469494339662.94c64e74 6f6cc6550e25c6\. 8979ecbb166f6cc6550e25c6.', STARTKEY => '7', ENDKEY => '8'}
....
table_p8ddpd6q5z,8,1469494339662.6d2b3f5fd1595ab8e7 column=info:regioninfo, timestamp=1469494339859, value={ENCODED => 6d2b3f5fd1595ab8e7c031876057b1ee, NAME => 'table_p8ddpd6q5z,8,1469494339662.6d2b3f5f c031876057b1ee. d1595ab8e7c031876057b1ee.', STARTKEY => '8', ENDKEY => ''}
```
使用 HBase shell 中的'normalize'调用规范化程序,HMaster 日志中的以下日志片段显示了根据为 SimpleRegionNormalizer 定义的逻辑计算的规范化计划。由于表中相邻最小区域的总区域大小(以 MB 为单位)小于平均区域大小,因此归一化器计算合并这两个区域的计划。
```
2016-07-26 07:08:26,928 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] master.HMaster: Skipping normalization for table: hbase:namespace, as it's either system table or doesn't have auto
normalization turned on
2016-07-26 07:08:26,928 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] master.HMaster: Skipping normalization for table: hbase:backup, as it's either system table or doesn't have auto normalization turned on
2016-07-26 07:08:26,928 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] master.HMaster: Skipping normalization for table: hbase:meta, as it's either system table or doesn't have auto normalization turned on
2016-07-26 07:08:26,928 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] master.HMaster: Skipping normalization for table: table_h2osxu3wat, as it's either system table or doesn't have autonormalization turned on
2016-07-26 07:08:26,928 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] normalizer.SimpleRegionNormalizer: Computing normalization plan for table: table_p8ddpd6q5z, number of regions: 5
2016-07-26 07:08:26,929 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] normalizer.SimpleRegionNormalizer: Table table_p8ddpd6q5z, total aggregated regions size: 12
2016-07-26 07:08:26,929 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] normalizer.SimpleRegionNormalizer: Table table_p8ddpd6q5z, average region size: 2.4
2016-07-26 07:08:26,929 INFO [B.fifo.QRpcServer.handler=20,queue=2,port=20000] normalizer.SimpleRegionNormalizer: Table table_p8ddpd6q5z, small region size: 0 plus its neighbor size: 0, less thanthe avg size 2.4, merging them
2016-07-26 07:08:26,971 INFO [B.fifo.QRpcServer.handler=20,queue=2,port=20000] normalizer.MergeNormalizationPlan: Executing merging normalization plan: MergeNormalizationPlan{firstRegion={ENCODED=> d51df2c58e9b525206b1325fd925a971, NAME => 'table_p8ddpd6q5z,,1469514755237.d51df2c58e9b525206b1325fd925a971.', STARTKEY => '', ENDKEY => '1'}, secondRegion={ENCODED => e69c6b25c7b9562d078d9ad3994f5330, NAME => 'table_p8ddpd6q5z,1,1469514767669.e69c6b25c7b9562d078d9ad3994f5330.',
STARTKEY => '1', ENDKEY => '3'}}
```
区域规范化器根据其计算的计划,将具有开始键的区域合并为“”并将结束键合并为“1”,将另一个区域的起始键合并为“1”并将结束键合并为“3”。现在,这些区域已合并,我们看到一个新区域,其开始键为'',结束键为'3'
```
table_p8ddpd6q5z,,1469516907210.e06c9b83c4a252b130e column=info:mergeA, timestamp=1469516907431,
value=PBUF\x08\xA5\xD9\x9E\xAF\xE2*\x12\x1B\x0A\x07default\x12\x10table_p8ddpd6q5z\x1A\x00"\x011(\x000\x00 ea74d246741ba. 8\x00
table_p8ddpd6q5z,,1469516907210.e06c9b83c4a252b130e column=info:mergeB, timestamp=1469516907431,
value=PBUF\x08\xB5\xBA\x9F\xAF\xE2*\x12\x1B\x0A\x07default\x12\x10table_p8ddpd6q5z\x1A\x011"\x013(\x000\x0 ea74d246741ba. 08\x00
table_p8ddpd6q5z,,1469516907210.e06c9b83c4a252b130e column=info:regioninfo, timestamp=1469516907431, value={ENCODED => e06c9b83c4a252b130eea74d246741ba, NAME => 'table_p8ddpd6q5z,,1469516907210.e06c9b83c ea74d246741ba. 4a252b130eea74d246741ba.', STARTKEY => '', ENDKEY => '3'}
....
table_p8ddpd6q5z,3,1469514778736.bf024670a847c0adff column=info:regioninfo, timestamp=1469514779417, value={ENCODED => bf024670a847c0adffb74b2e13408b32, NAME => 'table_p8ddpd6q5z,3,1469514778736.bf024670 b74b2e13408b32\. a847c0adffb74b2e13408b32.' STARTKEY => '3', ENDKEY => '7'}
....
table_p8ddpd6q5z,7,1469514790152.7c5a67bc755e649db2 column=info:regioninfo, timestamp=1469514790312, value={ENCODED => 7c5a67bc755e649db22f49af6270f1e1, NAME => 'table_p8ddpd6q5z,7,1469514790152.7c5a67bc 2f49af6270f1e1\. 755e649db22f49af6270f1e1.', STARTKEY => '7', ENDKEY => '8'}
....
table_p8ddpd6q5z,8,1469514790152.58e7503cda69f98f47 column=info:regioninfo, timestamp=1469514790312, value={ENCODED => 58e7503cda69f98f4755178e74288c3a, NAME => 'table_p8ddpd6q5z,8,1469514790152.58e7503c 55178e74288c3a. da69f98f4755178e74288c3a.', STARTKEY => '8', ENDKEY => ''}
```
对于具有 3 个较小区域和 1 个相对较大区域的用户表,可以看到类似的示例。对于此示例,我们有一个用户表,其中包含 1 个包含 100K 行的大区域,以及 3 个相对较小的区域,每个区域包含大约 33K 行。从规范化计划可以看出,由于较大的区域是平均区域大小的两倍以上,因此它被分成两个区域 - 一个用起始键作为'1',一个键作为'154717',另一个区域用起始键作为'154717'。 '154717'和结束键为'3'
```
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] master.HMaster: Skipping normalization for table: hbase:backup, as it's either system table or doesn't have auto normalization turned on
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Computing normalization plan for table: table_p8ddpd6q5z, number of regions: 4
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Table table_p8ddpd6q5z, total aggregated regions size: 12
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Table table_p8ddpd6q5z, average region size: 3.0
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: No normalization needed, regions look good for table: table_p8ddpd6q5z
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Computing normalization plan for table: table_h2osxu3wat, number of regions: 5
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Table table_h2osxu3wat, total aggregated regions size: 7
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Table table_h2osxu3wat, average region size: 1.4
2016-07-26 07:39:45,636 INFO [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Table table_h2osxu3wat, large region table_h2osxu3wat,1,1469515926544.27f2fdbb2b6612ea163eb6b40753c3db. has size 4, more than twice avg size, splitting
2016-07-26 07:39:45,640 INFO [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SplitNormalizationPlan: Executing splitting normalization plan: SplitNormalizationPlan{regionInfo={ENCODED => 27f2fdbb2b6612ea163eb6b40753c3db, NAME => 'table_h2osxu3wat,1,1469515926544.27f2fdbb2b6612ea163eb6b40753c3db.', STARTKEY => '1', ENDKEY => '3'}, splitPoint=null}
2016-07-26 07:39:45,656 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] master.HMaster: Skipping normalization for table: hbase:namespace, as it's either system table or doesn't have auto normalization turned on
2016-07-26 07:39:45,656 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] master.HMaster: Skipping normalization for table: hbase:meta, as it's either system table or doesn't
have auto normalization turned on …..…..….
2016-07-26 07:39:46,246 DEBUG [AM.ZK.Worker-pool2-t278] master.RegionStates: Onlined 54de97dae764b864504704c1c8d3674a on hbase-test-rc-5.openstacklocal,16020,1469419333913 {ENCODED => 54de97dae764b864504704c1c8d3674a, NAME => 'table_h2osxu3wat,1,1469518785661.54de97dae764b864504704c1c8d3674a.', STARTKEY => '1', ENDKEY => '154717'}
2016-07-26 07:39:46,246 INFO [AM.ZK.Worker-pool2-t278] master.RegionStates: Transition {d6b5625df331cfec84dce4f1122c567f state=SPLITTING_NEW, ts=1469518786246, server=hbase-test-rc-5.openstacklocal,16020,1469419333913} to {d6b5625df331cfec84dce4f1122c567f state=OPEN, ts=1469518786246,
server=hbase-test-rc-5.openstacklocal,16020,1469419333913}
2016-07-26 07:39:46,246 DEBUG [AM.ZK.Worker-pool2-t278] master.RegionStates: Onlined d6b5625df331cfec84dce4f1122c567f on hbase-test-rc-5.openstacklocal,16020,1469419333913 {ENCODED => d6b5625df331cfec84dce4f1122c567f, NAME => 'table_h2osxu3wat,154717,1469518785661.d6b5625df331cfec84dce4f1122c567f.', STARTKEY => '154717', ENDKEY => '3'}
```
- HBase™ 中文参考指南 3.0
- Preface
- Getting Started
- Apache HBase Configuration
- Upgrading
- The Apache HBase Shell
- Data Model
- HBase and Schema Design
- RegionServer Sizing Rules of Thumb
- HBase and MapReduce
- Securing Apache HBase
- Architecture
- In-memory Compaction
- Backup and Restore
- Synchronous Replication
- Apache HBase APIs
- Apache HBase External APIs
- Thrift API and Filter Language
- HBase and Spark
- Apache HBase Coprocessors
- Apache HBase Performance Tuning
- Troubleshooting and Debugging Apache HBase
- Apache HBase Case Studies
- Apache HBase Operational Management
- Building and Developing Apache HBase
- Unit Testing HBase Applications
- Protobuf in HBase
- Procedure Framework (Pv2): HBASE-12439
- AMv2 Description for Devs
- ZooKeeper
- Community
- Appendix