
# 附录
## 附录 A:贡献文档
Apache HBase 项目欢迎对项目的所有方面做出贡献,包括文档。
在 HBase 中,文档包括以下几个方面,可能还包括其他方面:
* [HBase 参考指南](https://hbase.apache.org/book.html)(本书)
* [HBase 网站](https://hbase.apache.org/)
* API 文档
* 命令行实用程序输出和帮助文本
* Web UI 字符串,显式帮助文本,上下文相关字符串等
* 记录消息
* 源文件,配置文件和其他内容中的注释
* 将上述任何一种语言本地化为英语以外的目标语言
无论您想要帮助哪个区域,第一步几乎总是下载(通常通过克隆 Git 存储库)并熟悉 HBase 源代码。有关下载和构建源的信息,请参阅[开发人员](#developer)。
### A.1。有助于文档或其他字符串
如果您在 UI,实用程序,脚本,日志消息或其他地方的字符串中发现错误,或者您认为某些内容可以更清晰,或者您认为文本需要添加到当前不存在的位置,那么第一个步骤是提交 JIRA。除了任何其他相关组件外,务必将组件设置为`Documentation`。大多数组件都有一个或多个默认所有者,他们监视进入这些队列的新问题。无论您是否能够修复该错误,您仍应该在看到错误的地方提交错误。
如果您想尝试修复新提交的错误,请将其分配给自己。您需要将 HBase Git 存储库克隆到本地系统并在那里解决问题。当您开发出潜在的修复程序时,请将其提交以供审核。如果它解决了这个问题并被视为一种改进,那么其中一个 HBase 提交者将根据需要将其提交给一个或多个分支。
过程:提交补丁的建议工作流程
这个程序比 Git 专业人员需要的更详细,但是包含在本附录中,以便不熟悉 Git 的人在学习时能够对 HBase 有信心。
1. 如果您还没有这样做,请在本地克隆 Git 存储库。你只需要这样做一次。
2. 通常,在检出跟踪分支时,使用`git pull`命令将远程更改拉入本地存储库。
3. 对于您处理的每个问题,请创建一个新分支。一个适用于命名分支的约定是将给定分支命名为与其相关的 JIRA:
```
$ git checkout -b HBASE-123456
```
4. 在您的分支上进行建议的更改,经常将更改提交到本地存储库。如果您需要切换到处理其他问题,请记得检查相应的分支。
5. 当您准备好提交补丁时,首先要确保 HBase 构建干净,并在修改的分支中按预期运行。
6. 如果您更改了文档,请确保通过运行`mvn clean site`来构建文档和网站。
7. 如果您需要几天或几周的时间来实施修复,或者您知道您正在使用的代码区域最近有很多更改,请确保将分支重新绑定到远程主服务器并处理任何冲突在提交补丁之前。
```
$ git checkout HBASE-123456
$ git rebase origin/master
```
8. 针对远程主服务器生成补丁。从 git 存储库的顶层运行以下命令(通常称为`hbase`):
```
$ git format-patch --stdout origin/master > HBASE-123456.patch
```
补丁的名称应包含 JIRA ID。
9. 查看补丁文件,确保您没有意外更改任何其他文件,并且没有其他意外。
10. 如果您满意,请将补丁附加到 JIRA 并单击 **Patch Available** 按钮。审核人员将审核您的补丁。
11. 如果您需要提交新版本的补丁,请将旧版本保留在 JIRA 上,并在新补丁的名称中添加版本号。
12. 提交更改后,无需保留本地分支。
### A2。编辑 HBase 网站
HBase 网站的源代码位于 HBase 源代码的 _src / site /_ 目录中。在此目录中,各个页面的源位于 _xdocs /_ 目录中,这些页面中引用的图像位于 _resources / [https://hbase.apache.org/images 中/](https://hbase.apache.org/images/)_ 目录。此目录还存储 HBase 参考指南中使用的图像。
该网站的页面是用类似 HTML 的 XML 方言编写的,名为 xdoc,在 [https://maven.apache.org/archives/maven-1.x/plugins/xdoc/reference/xdocs 上有参考指南。 html](https://maven.apache.org/archives/maven-1.x/plugins/xdoc/reference/xdocs.html) 。您可以在纯文本编辑器,IDE 或 XML 编辑器(如 XML Mind XML Editor(XXE)或 Oxygen XML Author)中编辑这些文件。
要预览更改,请使用`mvn clean site -DskipTests`命令构建网站。 HTML 输出位于 _ 目标/站点/_ 目录中。如果对更改感到满意,请按照[提交文档修补程序](#submit_doc_patch_procedure)中的步骤提交补丁。
### A.3。发布 HBase 网站和文档
HBase 使用 ASF 的`gitpubsub`机制。 Jenkins 作业运行`dev-support/jenkins-scripts/generate-hbase-website.sh`脚本,该脚本针对`hbase`存储库的`master`分支运行`mvn clean site site:stage`,并将构建的工件提交到`hbase-site`存储库的`asf-site`分支。按下提交后,将自动重新部署网站。如果脚本遇到错误,则会向开发人员邮件列表发送一封电子邮件。您可以手动运行脚本或检查脚本以查看所涉及的步骤。
### A.4。检查 HBase 网站的断开链接
Jenkins 作业定期运行,使用`dev-support/jenkins-scripts/check-website-links.sh`脚本检查 HBase 网站是否有损坏的链接。此脚本使用名为`linklint`的工具检查错误链接并创建报告。如果找到损坏的链接,则会向开发人员邮件列表发送一封电子邮件。您可以手动运行脚本或检查脚本以查看所涉及的步骤。
### A.5。 HBase 参考指南样式指南和备忘单
HBase 参考指南用 Asciidoc 编写,使用 [AsciiDoctor](http://asciidoctor.org) 构建。以下备忘单供您参考。更多细微而全面的文档可在 [http://asciidoctor.org/docs/user-manual/](http://asciidoctor.org/docs/user-manual/) 上找到。
| 元素类型 | 期望的渲染 | 怎么做 |
| --- | --- | --- |
| 一个段落 | 一个段落 |
只需键入一些顶部和底部带有空行的文本。
| |在段落中添加换行符而不添加空行|手动换行|
这将在加号处打破+。或者在整个段落前面加上包含'[%hardbreaks]'的行
| |给任何东西一个标题彩色斜体粗体不同大小的文字| | |内联代码或命令| monospace |
`text`
| |内联文字内容(完全按照所示输入的内容)|大胆的单声道|
_`typethis`_
| |内联可替换内容(用您自己的值替换的东西)|粗斜体单声道|
__ 类型的东西 __
| |突出显示的代码块|等宽,突出,保留空间|
```
[source,java]
----
myAwesomeCode() {
}
----
```
| |代码块包含在单独的文件中包括就好像它是主文件的一部分|
```
[source,ruby]
----
include\::path/to/app.rb[]
----
```
| |仅包含单独文件的一部分|与 Javadoc 相似|
见 [http://asciidoctor.org/docs/user-manual/#by-tagged-regions](http://asciidoctor.org/docs/user-manual/#by-tagged-regions)
| |文件名,目录名,新术语|斜体|
_hbase-default.xml_
| |外部裸 URL |链接 URL 作为链接文本|
```
link:http://www.google.com
```
| |带文字的外部网址|带有任意链接文本的链接|
```
link:http://www.google.com[Google]
```
| |创建内部锚点以交叉引用|没有呈现|
```
[[anchor_name]]
```
| |使用其默认标题|交叉引用现有锚点使用元素标题的内部超链接(如果可用),否则使用锚名称|
```
<<anchor_name>>
```
| |使用自定义文本交叉引用现有锚点使用任意文本的内部超链接
```
<<anchor_name,Anchor Text>>
```
| |块图像|替代文字的图像|
```
image::sunset.jpg[Alt Text]
```
(将图像放在 src / site / resources / images 目录中)
| |内嵌图像|带有 alt 文本的图像,作为文本流程的一部分
```
image:sunset.jpg [Alt Text]
```
(只有一个冒号)
| |链接到远程图像|显示在别处托管的图像|
```
image::http://inkscape.org/doc/examples/tux.svg[Tux,250,350]
```
(或`image:`)
| |向图像添加尺寸或 URL |取决于|
在 alt 文本后的括号内,指定 width,height 和/或 link =“ [http://my_link.com](http://my_link.com) ”
| |脚注|下标链接带你到脚注|
```
Some text.footnote:[The footnote text.]
```
| |没有标题的注释或警告|告诫图像后面跟着警告|
```
NOTE:My note here
```
```
WARNING:My warning here
```
| |复杂的笔记|该笔记有一个标题和/或多个段落和/或代码块或列表等
```
.The Title
[NOTE]
====
Here is the note text. Everything until the second set of four equals signs is part of the note.
----
some source code
----
====
```
| |子弹列表|子弹列表|
```
* list item 1
```
(见 [http://asciidoctor.org/docs/user-manual/#unordered-lists](http://asciidoctor.org/docs/user-manual/#unordered-lists) )
| |编号列表|编号列表|
```
. list item 2
```
(见 [http://asciidoctor.org/docs/user-manual/#ordered-lists](http://asciidoctor.org/docs/user-manual/#ordered-lists) )
| |清单|选中或未选中的复选框|
经过:
```
- [*]
```
未选中:
```
- [ ]
```
| |多级列表|项目符号或编号或组合|
```
. Numbered (1), at top level
* Bullet (2), nested under 1
* Bullet (3), nested under 1
. Numbered (4), at top level
* Bullet (5), nested under 4
** Bullet (6), nested under 5
- [x] Checked (7), at top level
```
| |标记列表/变量列表|列表项标题或摘要后跟内容|
```
Title:: content
Title::
content
```
| |侧栏,引号或其他文本块|一个文本块,格式与默认值不同
使用不同的分隔符分隔,请参阅 [http://asciidoctor.org/docs/user-manual/#built-in-blocks-summary](http://asciidoctor.org/docs/user-manual/#built-in-blocks-summary) 。上面的一些例子使用分隔符,如....,----,====。
```
[example]
====
This is an example block.
====
[source]
----
This is a source block.
----
[note]
====
This is a note block.
====
[quote]
____
This is a quote block.
____
```
如果要插入一直保持被解释的文字 Asciidoc 内容,如果有疑问,请在顶部和底部使用八个点作为分隔符。
| |嵌套部分|章节,节,小节等|
```
= Book (or chapter if the chapter can be built alone, see the leveloffset info below)
== Chapter (or section if the chapter is standalone)
=== Section (or subsection, etc)
==== Subsection
```
等等多达 6 个级别(仔细考虑深入 4 级以上,也许你可以选择标题段落或列表)。请注意,您可以通过在 include 之前直接添加`:leveloffset:+1`宏指令将一本书包含在另一本书中,然后将其重置为 0。有关示例,请参阅 _book.adoc_ 源代码,因为这是本指南处理章节的方式。 **不要为前言,术语表,附录或其他特殊类型的章节做这些。**
| |包含另一个文件|内容包含在内,就像它是内联的一样
```
include::[/path/to/file.adoc]
```
有很多例子。见 _book.adoc_ 。
| |一张桌子|一张桌子|
见 [http://asciidoctor.org/docs/user-manual/#tables](http://asciidoctor.org/docs/user-manual/#tables) 。通常,行由换行符和换行符按管道分隔
| |注释掉一行|渲染时跳过一行|
`// This line won’t show up`
| |注释掉一个块|在渲染过程中会跳过文件的一部分
```
////
Nothing between the slashes will show up.
////
```
| |突出显示要审阅的文本|文本显示黄色背景|
```
Test between #hash marks# is highlighted yellow.
```
|
### A.6。自动生成的内容
HBase 参考指南的某些部分,特别是 [config.files](#config.files) ,是自动生成的,因此文档的这个区域与代码保持同步。这是通过 XSLT 转换完成的,您可以在 _src / main / xslt / configuration_to_asciidoc _chapter.xsl_ 的源代码中查看。这会将 _hbase-common / src / main / resources / hbase-default.xml_ 文件转换为 Asciidoc 输出,该输出可以包含在参考指南中。
有时,需要添加配置参数或修改其描述。对源文件进行修改,重建后它们将包含在“参考指南”中。
将来可能并且将从 HBase 源文件自动生成其他类型的内容。
### A.7。 HBase 参考指南中的图像
您可以在 HBase 参考指南中包含图像。如果可能,重要的是包括图像标题,并始终包括替代文本。这允许屏幕阅读器导航到图像并且还为图像提供替代文本。以下是带有标题和替代文本的图像示例。注意双冒号。
```
.My Image Title
image::sunset.jpg[Alt Text]
```
以下是带有替换文本的内嵌图像的示例。注意单个冒号。内嵌图像不能有标题。它们通常是像 GUI 按钮这样的小图像。
```
image:sunset.jpg[Alt Text]
```
进行本地构建时,将图像保存到 _src / site / resources / [https://hbase.apache.org/images/](https://hbase.apache.org/images/)_ 目录。链接到图像时,请不要包含路径的目录部分。在构建输出期间,图像将被复制到适当的目标位置。
当您提交包含将图像添加到 HBase 参考指南的修补程序时,请将图像附加到 JIRA。如果提交者询问应该提交映像的位置,它应该进入上面的目录。
### A.8。在 HBase 参考指南中添加新章节
如果要在 HBase 参考指南中添加新章节,最简单的方法是复制现有的章节文件,重命名它,并更改 ID(在双括号中)和标题。章节位于 _src / main / asciidoc / _ 章节/_ 目录中。
删除现有内容并创建新内容。然后打开 _src / main / asciidoc / book.adoc_ 文件,该文件是 HBase 参考指南的主文件,并复制现有的`include`元素以将新章节包含在适当的位置。在创建补丁之前,请务必将新文件添加到 Git 存储库。
如有疑问,请检查其他文件是如何包含的。
### A.9。常见文档问题
经常出现以下文档问题。其中一些是偏好,但其他人可能会产生神秘的构建错误或其他问题。
1. _ 隔离更改以便进行简易差异检查。_
小心漂亮打印或重新格式化整个 XML 文件,即使格式随着时间的推移而降级。如果您需要重新格式化文件,请在不更改任何内容的单独 JIRA 中执行此操作。请注意,因为某些 XML 编辑器在您打开新文件时会进行批量重新格式化,尤其是在编辑器中使用 GUI 模式时。
2. _ 语法突出显示 _
HBase 参考指南使用`coderay`进行语法高亮显示。要为给定代码清单启用语法突出显示,请使用以下类型的语法:
```
[source,xml]
----
<name>My Name</name>
----
```
支持几种语法类型。 HBase 参考指南中最有趣的是`java`,`xml`,`sql`和`bash`。
## 附录 B:常见问题
### B.1。一般
我什么时候应该使用 HBase?
请参阅架构章节中的[概述](#arch.overview)。
还有其他 HBase 常见问题吗?
请参阅维基上的常见问题解答, [HBase Wiki 常见问题解答](https://wiki.apache.org/hadoop/Hbase/FAQ)。
HBase 是否支持 SQL?
并不是的。通过 [Hive](https://hive.apache.org/) 对 HBase 的 SQL-ish 支持正在开发中,但是 Hive 基于 MapReduce,它通常不适用于低延迟请求。有关 HBase 客户端的示例,请参见[数据模型](#datamodel)部分。
如何找到 NoSQL / HBase 的示例?
请参阅[关于 HBase](#other.info) 的其他信息以及其他文章中 BigTable 论文的链接。
HBase 的历史是什么?
见 [hbase.history](#hbase.history) 。
为什么 HBase 不建议使用 10MB 以上的电池?
大细胞不适合 HBase 缓冲数据的方法。首先,大单元在写入时绕过 MemStoreLAB。然后,在读取操作期间,它们不能缓存在 L2 块缓存中。相反,HBase 每次都必须为它们分配堆内存。这可能会对 RegionServer 进程中的垃圾收集器产生重大影响。
### B.2。升级
如何将 Maven 管理的项目从 HBase 0.94 升级到 HBase 0.96+?
在 HBase 0.96 中,项目转移到模块化结构。调整项目的依赖关系以依赖`hbase-client`模块或其他模块,而不是单个 JAR。您可以根据您的目标 HBase 版本,在以下之一之后为 Maven 依赖建模。有关更多信息,请参见第 3.5 节“从 0.94.x 升级到 0.96.x”或第 3.3 节“从 0.96.x 升级到 0.98.x”。
Maven 对 HBase 的依赖性为 0.98
```
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.98.5-hadoop2</version>
</dependency>
```
Maven 对 HBase 的依赖性为 0.96
```
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.96.2-hadoop2</version>
</dependency>
```
Maven 对 HBase 的依赖性为 0.94
```
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>0.94.3</version>
</dependency>
```
### B.3。建筑
HBase 如何处理 Region-RegionServer 分配和位置?
见[区域](#regions.arch)。
### B.4。组态
我怎样才能开始使用我的第一个集群?
参见[快速入门 - 独立 HBase](#quickstart) 。
我在哪里可以了解其他配置选项?
请参见 [Apache HBase 配置](#configuration)。
### B.5。架构设计/数据访问
我应该如何在 HBase 中设计我的架构?
参见[数据模型](#datamodel)和 [HBase 和模式设计](#schema)。
如何在 HBase 中存储(填空)?
请参见[支持的数据类型](#supported.datatypes)。
如何处理 HBase 中的二级索引?
请参见[辅助索引和备用查询路径](#secondary.indexes)。
我可以更改表的 rowkeys 吗?
这是一个非常常见的问题。你不能。参见 [Rowkeys](#changing.rowkeys) 的不变性。
HBase 支持哪些 API?
参见[数据模型](#datamodel),[客户端](#architecture.client)和 [Apache HBase 外部 API](#external_apis) 。
### B.6。 MapReduce 的
如何将 MapReduce 与 HBase 一起使用?
参见 [HBase 和 MapReduce](#mapreduce) 。
### B.7。性能和故障排除
如何提高 HBase 集群性能?
参见 [Apache HBase 性能调优](#performance)。
如何解决 HBase 群集问题?
请参阅[疑难解答和调试 Apache HBase](#trouble) 。
### B.8。亚马逊 EC2
我在 Amazon EC2 上运行 HBase 并且......
EC2 问题是一个特例。参见 [Amazon EC2](#trouble.ec2) 和 [Amazon EC2](#perf.ec2) 。
### B.9。操作
如何管理 HBase 群集?
参见 [Apache HBase 运营管理](#ops_mgt)。
如何备份 HBase 群集?
参见 [HBase Backup](#ops.backup) 。
### B.10。 HBase 在行动
我在哪里可以找到有关 HBase 的有趣视频和演示文稿?
参见[关于 HBase](#other.info) 的其他信息。
## 附录 C:访问控制矩阵
以下矩阵显示了在 HBase 中执行操作所需的权限集。在使用该表之前,请阅读有关如何解释它的信息。
解释 ACL 矩阵表
ACL Matrix 表中使用以下约定:
### C.1。领域
从最广泛的范围开始评估权限,并在最窄的范围内进行评估。
范围对应于数据模型的级别。从最广泛到最窄,范围如下:
领域
* 全球
* 命名空间(NS)
* 表
* 柱族(CF)
* 列限定符(CQ)
* 细胞
例如,在表级别授予的权限支配在列族,列限定符或单元级别完成的任何授权。用户可以在表中的任何位置执行授权所暗示的内容。在全局范围内授予的权限支配所有权限:始终允许用户在任何地方执行该操作。
### C.2。权限
可能的权限包括以下内容:
权限
* 超级用户 - 属于“超级组”组的特殊用户,具有无限制访问权限
* 管理员(A)
* 创建(C)
* 写(W)
* 阅读(R)
* 执行(X)
在大多数情况下,权限以预期的方式工作,具有以下警告:
拥有写入权限并不意味着具有读取权限。
用户能够并且有时希望能够写入相同用户无法读取的数据。一个这样的例子是日志写入过程。
无论用户的其他授权或限制如何,每个用户都可以读取 hbase:meta 表。
这是 HBase 正常运行的要求。
如果用户没有写入和读取权限,则`CheckAndPut`和`CheckAndDelete`操作将失败。
`Increment`和`Append`操作不需要读访问权限。
顾名思义,`superuser`具有执行所有可能操作的权限。
对于标有*的操作,检查在后挂钩中完成,只有满足访问检查的结果子集才会返回给用户。
下表按提供每个操作的接口排序。如果表格过时,可以在 _hbase-server / src / test / java / org / apache / hadoop / hbase / security / access / TestAccessController.java 中找到检查权限准确性的单元。_ ,访问控制本身可以在 _hbase-server / src / main / java / org / apache / hadoop / hbase / security / access / AccessController.java_ 中查看。
| 接口 | 手术 | 权限 |
| --- | --- | --- |
| 主 | CREATETABLE | 超级用户|全球(C)| NS(C) |
| | modifyTable | 超级用户|全球(A)|全球(C)| NS(A)| NS(C)|表所有者|表(A)|表(C) |
| | deleteTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) |
| | truncateTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) |
| | addColumn | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) |
| | modifyColumn | 超级用户|全球(A)|全球(C)| NS(A)| NS(C)|表所有者|表(A)|表(C)|柱(A)|柱(C) |
| | deleteColumn | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C)|column(A)|column(C) |
| | enableTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) |
| | disableTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) |
| | disableAclTable | 不允许 |
| | 移动 | 超级用户|全球(A)| NS(A)|表所有者|表(A) |
| | 分配 | superuser|global(A)|NS(A)|TableOwner|table(A) |
| | 取消分配 | superuser|global(A)|NS(A)|TableOwner|table(A) |
| | regionOffline | superuser|global(A)|NS(A)|TableOwner|table(A) |
| | 平衡 | 超级用户|全球(A) |
| | balanceSwitch | superuser|global(A) |
| | 关掉 | superuser|global(A) |
| | stopMaster | superuser|global(A) |
| | 快照 | superuser|global(A)|NS(A)|TableOwner|table(A) |
| | listSnapshot | 超级用户|全球(A)| SnapshotOwner |
| | cloneSnapshot | 超级用户|全局(A)|(SnapshotOwner&amp; TableName 匹配) |
| | restoreSnapshot | 超级用户|全球(A)| SnapshotOwner&amp; (NS(A)|表所有者|表(A)) |
| | deleteSnapshot | superuser|global(A)|SnapshotOwner |
| | createNamespace | superuser|global(A) |
| | deleteNamespace | superuser|global(A) |
| | modifyNamespace | superuser|global(A) |
| | getNamespaceDescriptor | 超级用户|全球(A)| NS(A) |
| | listNamespaceDescriptors * | superuser|global(A)|NS(A) |
| | flushTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) |
| | getTableDescriptors * | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) |
| | getTableNames * | 超级用户| TableOwner |任何全局或表 perm |
| | setUserQuota(全局级别) | superuser|global(A) |
| | setUserQuota(名称空间级别) | superuser|global(A) |
| | setUserQuota(表级) | superuser|global(A)|NS(A)|TableOwner|table(A) |
| | setTableQuota | superuser|global(A)|NS(A)|TableOwner|table(A) |
| | setNamespaceQuota | superuser|global(A) |
| | addReplicationPeer | superuser|global(A) |
| | removeReplicationPeer | superuser|global(A) |
| | enableReplicationPeer | superuser|global(A) |
| | disableReplicationPeer | superuser|global(A) |
| | getReplicationPeerConfig | superuser|global(A) |
| | updateReplicationPeerConfig | superuser|global(A) |
| | listReplicationPeers | superuser|global(A) |
| | getClusterStatus | 任何用户 |
| 区域 | openRegion | superuser|global(A) |
| | closeRegion | superuser|global(A) |
| | 红晕 | 超级用户|全球(A)|全球(C)|表所有者|表(A)|表(C) |
| | 分裂 | 超级用户|全球(A)|表所有者|表所有者|表(A) |
| | 紧凑 | superuser|global(A)|global(C)|TableOwner|table(A)|table(C) |
| | getClosestRowBefore | 超级用户|全球(R)| NS(R)|表所有者|表(R)| CF(R)| CQ(R) |
| | getOp | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) |
| | 存在 | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) |
| | 放 | 超级用户|全球(W)| NS(W)|表(W)|表所有者| CF(W)| CQ(W) |
| | 删除 | superuser|global(W)|NS(W)|table(W)|TableOwner|CF(W)|CQ(W) |
| | batchMutate | 超级用户|全球(W)| NS(W)|表所有者|表(W)| CF(W)| CQ(W) |
| | checkAndPut | 超级用户|全球(RW)| NS(RW)|表所有者|表(RW)| CF(RW)| CQ(RW) |
| | checkAndPutAfterRowLock | 超级用户|全球(R)| NS(R)|表所有者|表(R)| CF(R)| CQ(R) |
| | checkAndDelete | superuser|global(RW)|NS(RW)|TableOwner|table(RW)|CF(RW)|CQ(RW) |
| | checkAndDeleteAfterRowLock | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) |
| | incrementColumnValue | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) |
| | 附加 | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) |
| | appendAfterRowLock | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) |
| | 增量 | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) |
| | incrementAfterRowLock | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) |
| | scannerOpen | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) |
| | scannerNext | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) |
| | scannerClose | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) |
| | bulkLoadHFile | 超级用户|全球(C)|表所有者|表(C)| CF(C) |
| | prepareBulkLoad | superuser|global(C)|TableOwner|table(C)|CF(C) |
| | cleanupBulkLoad | superuser|global(C)|TableOwner|table(C)|CF(C) |
| 端点 | 调用 | 超级用户|全球(X)| NS(X)|表所有者|表(X) |
| AccessController 的 | 补助金(全球一级) | 全球(A) |
| | grant(名称空间级别) | 全球(A)| NS(A) |
| | 授权(表级) | 全球(A)| NS(A)|表所有者|表(A)| CF(A)| CQ(A) |
| | 撤销(全球一级) | global(A) |
| | revoke(名称空间级别) | global(A)|NS(A) |
| | 撤销(表级) | global(A)|NS(A)|TableOwner|table(A)|CF(A)|CQ(A) |
| | getUserPermissions(全局级别) | global(A) |
| | getUserPermissions(名称空间级别) | global(A)|NS(A) |
| | getUserPermissions(表级) | global(A)|NS(A)|TableOwner|table(A)|CF(A)|CQ(A) |
| | hasPermission(表级) | 全球(A)| SelfUserCheck |
| RegionServer 的 | stopRegionServer | superuser|global(A) |
| | mergeRegions | superuser|global(A) |
| | rollWALWriterRequest | superuser|global(A) |
| | replicateLogEntries | 超级用户|全球(W) |
| RSGroup | addRSGroup | superuser|global(A) |
| | balanceRSGroup | superuser|global(A) |
| | getRSGroupInfo | superuser|global(A) |
| | getRSGroupInfoOfTable | superuser|global(A) |
| | getRSGroupOfServer | superuser|global(A) |
| | listRSGroups | superuser|global(A) |
| | moveServers | superuser|global(A) |
| | moveServersAndTables | superuser|global(A) |
| | moveTables | superuser|global(A) |
| | removeRSGroup | superuser|global(A) |
> removeServers |超级用户|全球(A)
## 附录 D:HBase 中的压缩和数据块编码
> 本节中提到的编解码器用于编码和解码数据块或行键。有关复制编解码器的信息,请参见 [cluster.replication.preserving.tags](#cluster.replication.preserving.tags) 。
本节中的一些信息来自 HBase Development 邮件列表中的[讨论](http://search-hadoop.com/m/lL12B1PFVhp1/v=threaded)。
HBase 支持几种不同的压缩算法,可以在 ColumnFamily 上启用。数据块编码试图限制密钥中信息的重复,利用 HBase 的一些基本设计和模式,例如排序的行键和给定表的模式。压缩器减少了单元中大型不透明字节数组的大小,并且可以显着减少存储未压缩数据所需的存储空间。
压缩器和数据块编码可以在同一 ColumnFamily 上一起使用。
压缩后的变化生效
如果更改 ColumnFamily 的压缩或编码,则更改将在压缩期间生效。
一些编解码器利用 Java 内置的功能,例如 GZip 压缩。其他人依赖本地图书馆。本机库可以作为 Hadoop 的一部分提供,例如 LZ4。在这种情况下,HBase 只需要访问适当的共享库。
其他编解码器,例如 Google Snappy,需要先安装。某些编解码器的许可方式与 HBase 的许可证相冲突,不能作为 HBase 的一部分提供。
本节讨论使用 HBase 进行测试的常用编解码器。无论您使用何种编解码器,请确保测试它是否已正确安装并且可在群集中的所有节点上使用。可能需要额外的操作步骤以确保编解码器在新部署的节点上可用。您可以使用 [compression.test](#compression.test) 实用程序检查给定的编解码器是否已正确安装。
要将 HBase 配置为使用压缩器,请参见 [compressor.install](#compressor.install) 。要为 ColumnFamily 启用压缩器,请参阅 [changing.compression](#changing.compression) 。要为 ColumnFamily 启用数据块编码,请参见 [data.block.encoding.enable](#data.block.encoding.enable) 。
块压缩机
* 没有
* 瞬间
* LZO
* LZ4
* GZ
数据块编码类型
字首
通常,键非常相似。具体来说,密钥通常共享一个共同的前缀,并且只在末尾附近不同。例如,一个键可能是`RowKey:Family:Qualifier0`,下一个键可能是`RowKey:Family:Qualifier1`。在前缀编码中,添加了一个额外的列,其中包含当前键和前一个键之间共享的前缀长度。假设此处的第一个密钥与之前的密钥完全不同,则其前缀长度为 0。
第二个密钥的前缀长度为`23`,因为它们共有前 23 个字符。
显然,如果密钥往往没有任何共同点,Prefix 将不会提供太多好处。
下图显示了一个没有数据块编码的假设 ColumnFamily。
图 18.没有编码的 ColumnFamily
这是与前缀数据编码相同的数据。
图 19.带有前缀编码的 ColumnFamily
DIFF
差异编码扩展了前缀编码。不是将密钥顺序地视为单个字节序列,而是分割每个密钥字段,以便可以更有效地压缩密钥的每个部分。
添加了两个新字段:时间戳和类型。
如果 ColumnFamily 与上一行相同,则从当前行中省略它。
如果密钥长度,值长度或类型与前一行相同,则省略该字段。
此外,为了增加压缩,时间戳存储为前一行时间戳的 Diff,而不是完整存储。给定前缀示例中的两个行键,并给出时间戳和相同类型的精确匹配,第二行的值长度或类型都不需要存储,第二行的时间戳值只有 0,而不是一个完整的时间戳。
默认情况下禁用 Diff 编码,因为写入和扫描速度较慢但缓存了更多数据。
此图像显示与之前图像相同的 ColumnFamily,具有 Diff 编码。
图 20.带有 Diff 编码的 ColumnFamily
快速差异
Fast Diff 与 Diff 类似,但使用更快的实现。它还添加了另一个字段,用于存储单个位以跟踪数据本身是否与前一行相同。如果是,则不再存储数据。
如果您有长键或多列,建议使用快速差异。
数据格式几乎与 Diff 编码相同,因此没有图像来说明它。
前缀树
在 HBase 0.96 中引入了前缀树编码作为实验特征。它为 Prefix,Diff 和 Fast Diff 编码器提供了类似的内存节省,但以较慢的编码速度为代价提供了更快的随机访问。它已在 hbase-2.0.0 中删除。这是一个好主意,但很少采用。如果有兴趣重振这项工作,请编写 hbase 开发列表。
### D.1。使用哪种压缩器或数据块编码器
要使用的压缩或编解码器类型取决于数据的特征。选择错误的类型可能会导致数据占用更多空间而不是更少,并且可能会影响性能。
通常,您需要在较小尺寸和较快压缩/解压缩之间权衡您的选择。以下是一些一般性指南,从[关于压缩和编解码器的文档指南](http://search-hadoop.com/m/lL12B1PFVhp1)的讨论中进行了扩展。
* 如果您有长键(与值相比)或许多列,请使用前缀编码器。建议使用 FAST_DIFF。
* 如果值很大(而不是预压缩,例如图像),请使用数据块压缩器。
* 将 GZIP 用于 _ 冷数据 _,不经常访问。 GZIP 压缩比 Snappy 或 LZO 使用更多的 CPU 资源,但提供更高的压缩比。
* 对于经常访问的 _ 热数据 _ 使用 Snappy 或 LZO。 Snappy 和 LZO 比 GZIP 使用更少的 CPU 资源,但不提供高压缩比。
* 在大多数情况下,默认情况下启用 Snappy 或 LZO 是一个不错的选择,因为它们具有较低的性能开销并节省空间。
* 在 2011 年 Snappy 成为谷歌之前,LZO 是默认的。 Snappy 具有与 LZO 相似的品质,但已被证明表现更好。
### D.2。在 HBase 中使用 Hadoop 本机库
Hadoop 共享库有许多功能,包括压缩库和快速 crc'ing - 硬件 crc'ing,如果您的芯片组支持它。要使此工具可用于 HBase,请执行以下操作。如果找不到本机库版本,HBase / Hadoop 将回退使用替代品 - 或者如果你要求显式压缩器并且没有替代可用,则彻底失败。
首先确保你的 Hadoop。如果您看到它启动 Hadoop 进程,请修复此消息:
```
16/02/09 22:40:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
```
这意味着没有正确指向其本机库,或者本地库是为另一个平台编译的。先解决这个问题。
然后,如果您在 HBase 日志中看到以下内容,则表示 HBase 无法找到 Hadoop 本机库:
```
2014-08-07 09:26:20,139 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
```
如果库已成功加载,则不会显示 WARN 消息。通常这意味着你很高兴去阅读。
让我们假设您的 Hadoop 附带了一个适合您正在运行 HBase 的平台的本机库。要检查 Hadoop 本机库是否可用于 HBase,请运行以下工具(可在 Hadoop 2.1 及更高版本中使用):
```
$ ./bin/hbase --config ~/conf_hbase org.apache.hadoop.util.NativeLibraryChecker
2014-08-26 13:15:38,717 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Native library checking:
hadoop: false
zlib: false
snappy: false
lz4: false
bzip2: false
2014-08-26 13:15:38,863 INFO [main] util.ExitUtil: Exiting with status 1
```
上图显示本地 hadoop 库在 HBase 上下文中不可用。
上面的 NativeLibraryChecker 工具可能会回来说所有的文件都是 hunky-dory - 即所有的库都显示'true',它们是可用的 - 但是无论如何都要按照下面的说明来确保本机库在 HBase 上下文中可用,当它们使用它们时。
要解决上述问题,如果 Hadoop 和 HBase 停顿在文件系统中相邻,则将 Hadoop 本机库本地或符号链接复制到它们。您还可以通过在 hbase-env.sh 中设置`LD_LIBRARY_PATH`环境变量来指向其位置。
JVM 寻找本机库的位置是“系统相关的”(参见`java.lang.System#loadLibrary(name)`)。在 linux 上,默认情况下,将查看 _lib / native / PLATFORM_ ,其中`PLATFORM`是安装 HBase 的平台的标签。在本地 linux 机器上,它似乎是 java 属性`os.name`和`os.arch`的串联,后跟是 32 位还是 64 位。启动时 HBase 打印出所有 java 系统属性,因此在日志中找到 os.name 和 os.arch。例如:
```
...
2014-08-06 15:27:22,853 INFO [main] zookeeper.ZooKeeper: Client environment:os.name=Linux
2014-08-06 15:27:22,853 INFO [main] zookeeper.ZooKeeper: Client environment:os.arch=amd64
...
```
所以在这种情况下,PLATFORM 字符串是`Linux-amd64-64`。在 _lib / native / Linux-amd64-64_ 复制 Hadoop 本机库或符号链接将确保找到它们。完成此更改后滚动重新启动。
以下是如何设置符号链接的示例。让 hadoop 和 hbase 安装在您的主目录中。假设您的 hadoop 本机库位于〜/ hadoop / lib / native。假设您使用的是 Linux-amd64-64 平台。在这种情况下,您将执行以下操作来链接 hadoop 本机库,以便 hbase 可以找到它们。
```
...
$ mkdir -p ~/hbaseLinux-amd64-64 -> /home/stack/hadoop/lib/native/lib/native/
$ cd ~/hbase/lib/native/
$ ln -s ~/hadoop/lib/native Linux-amd64-64
$ ls -la
# Linux-amd64-64 -> /home/USER/hadoop/lib/native
...
```
如果您在堆栈轨道中看到 PureJavaCrc32C,或者如果在 perf 跟踪中看到类似下面的内容,则本机不起作用;您使用的是 java CRC 函数而不是 native 函数:
```
5.02% perf-53601.map [.] Lorg/apache/hadoop/util/PureJavaCrc32C;.update
```
请参阅 [HBASE-11927 使用 Native Hadoop Library 进行 HFile 校验和(并将默认值从 CRC32 转换为 CRC32C)](https://issues.apache.org/jira/browse/HBASE-11927),有关本机校验和支持的更多信息。请特别参阅发行说明,了解如何检查硬件是否支持处理器是否支持硬件 CRC。或者查看 HBase 博客文章中的 Apache [Checksums。](https://blogs.apache.org/hbase/entry/saving_cpu_using_native_hadoop)
以下是如何使用`LD_LIBRARY_PATH`环境变量指向 Hadoop 库的示例:
```
$ LD_LIBRARY_PATH=~/hadoop-2.5.0-SNAPSHOT/lib/native ./bin/hbase --config ~/conf_hbase org.apache.hadoop.util.NativeLibraryChecker
2014-08-26 13:42:49,332 INFO [main] bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
2014-08-26 13:42:49,337 INFO [main] zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
Native library checking:
hadoop: true /home/stack/hadoop-2.5.0-SNAPSHOT/lib/native/libhadoop.so.1.0.0
zlib: true /lib64/libz.so.1
snappy: true /usr/lib64/libsnappy.so.1
lz4: true revision:99
bzip2: true /lib64/libbz2.so.1
```
在启动 HBase 时在 _hbase-env.sh_ 中设置 LD_LIBRARY_PATH 环境变量。
### D.3。压缩器配置,安装和使用
#### D.3.1。为压缩器配置 HBase
在 HBase 可以使用给定的压缩器之前,它的库需要可用。由于许可问题,默认安装中只有 Gase 压缩可用于 HBase(通过本机 Java 库)。其他压缩库可通过与 hadoop 捆绑在一起的共享库提供。当 HBase 启动时,需要找到 hadoop 本机库。看到
主机上的压缩器支持
在 HBase 0.95 中引入了新的配置设置,以检查主服务器以确定在其上安装和配置了哪些数据块编码器,并假设整个群集配置相同。此选项`hbase.master.check.compression`默认为`true`。这可以防止 [HBASE-6370](https://issues.apache.org/jira/browse/HBASE-6370) 中描述的情况,其中创建或修改表以支持区域服务器不支持的编解码器,从而导致需要很长时间才能发生的故障并且难以调试。
如果启用了`hbase.master.check.compression`,则需要在主服务器上安装和配置所有所需压缩程序的库,即使主服务器未运行区域服务器也是如此。
通过本机库安装 GZ 支持
HBase 使用 Java 的内置 GZip 支持,除非 CLASSPATH 上有本机 Hadoop 库。将库添加到 CLASSPATH 的推荐方法是为运行 HBase 的用户设置环境变量`HBASE_LIBRARY_PATH`。如果本机库不可用且使用 Java 的 GZIP,则`Got brand-new compressor`报告将出现在日志中。见 [brand.new.compressor](#brand.new.compressor) )。
安装 LZO 支持
由于 HBase 使用 Apache 软件许可证(ASL)和使用 GPL 许可证的 LZO 之间不兼容,因此 HBase 无法附带 LZO。有关配置 HBase 的 LZO 支持的信息,请参阅 Twitter 上的 [Hadoop-LZO。](https://github.com/twitter/hadoop-lzo/blob/master/README.md)
如果您依赖于 LZO 压缩,请考虑在 LZO 不可用时将 RegionServers 配置为无法启动。参见 [hbase.regionserver.codecs](#hbase.regionserver.codecs) 。
配置 LZ4 支持
LZ4 支持与 Hadoop 捆绑在一起。启动 HBase 时,确保可以访问 hadoop 共享库(libhadoop.so)。配置完平台后(参见 [hadoop.native.lib](#hadoop.native.lib) ),您可以建立从 HBase 到本机 Hadoop 库的符号链接。这假定两个软件安装是共同的。例如,如果我的'平台'是 Linux-amd64-64:
```
$ cd $HBASE_HOME
$ mkdir lib/native
$ ln -s $HADOOP_HOME/lib/native lib/native/Linux-amd64-64
```
使用压缩工具检查所有节点上是否安装了 LZ4。启动(或重启)HBase。之后,您可以创建和更改表以使 LZ4 成为压缩编解码器:
```
hbase(main):003:0> alter 'TestTable', {NAME => 'info', COMPRESSION => 'LZ4'}
```
安装 Snappy 支持
由于许可问题,HBase 不附带 Snappy 支持。您可以安装 Snappy 二进制文件(例如,在 CentOS 上使用 yum install snappy)或从源代码构建 Snappy。安装 Snappy 后,搜索共享库,它将被称为 _libsnappy.so.X_ ,其中 X 是一个数字。如果您是从源构建的,请将共享库复制到系统上的已知位置,例如 _/ opt / snappy / lib /_ 。
除了 Snappy 库之外,HBase 还需要访问 Hadoop 共享库,它将被称为 _libhadoop.so.X.Y_ ,其中 X 和 Y 都是数字。记下 Hadoop 库的位置,或将其复制到与 Snappy 库相同的位置。
| |
需要在群集的每个节点上提供 Snappy 和 Hadoop 库。请参阅 [compression.test](#compression.test) 以了解如何测试这种情况。
如果给定的压缩器不可用,请参见 [hbase.regionserver.codecs](#hbase.regionserver.codecs) 以配置 RegionServers 无法启动。
|
需要将每个库位置添加到运行 HBase 的操作系统用户的环境变量`HBASE_LIBRARY_PATH`中。您需要重新启动 RegionServer 才能使更改生效。
压缩测试
您可以使用 CompressionTest 工具验证您的压缩器是否可用于 HBase:
```
$ hbase org.apache.hadoop.hbase.util.CompressionTest hdfs://host/path/to/hbase snappy
```
在 RegionServer 上强制执行压缩设置
您可以通过将选项 hbase.regionserver.codecs 添加到 _hbase-site.xml_ 并将其值设置为逗号分隔来配置 RegionServer,以便在压缩配置不正确时无法重新启动需要可用的编解码器列表。例如,如果将此属性设置为`lzo,gz`,则如果两个压缩程序都不可用,则 RegionServer 将无法启动。这样可以防止在没有正确配置编解码器的情况下将新服务器添加到群集中。
#### D.3.2。在 ColumnFamily 上启用压缩
要为 ColumnFamily 启用压缩,请使用`alter`命令。您无需重新创建表或复制数据。如果要更改编解码器,请确保旧的编解码器仍然可用,直到所有旧的 StoreFiles 都已压缩为止。
使用 HBase Shell 在现有表的列族上启用压缩
```
hbase> disable 'test'
hbase> alter 'test', {NAME => 'cf', COMPRESSION => 'GZ'}
hbase> enable 'test'
```
在 ColumnFamily 上使用压缩创建新表
```
hbase> create 'test2', { NAME => 'cf2', COMPRESSION => 'SNAPPY' }
```
验证 ColumnFamily 的压缩设置
```
hbase> describe 'test'
DESCRIPTION ENABLED
'test', {NAME => 'cf', DATA_BLOCK_ENCODING => 'NONE false
', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0',
VERSIONS => '1', COMPRESSION => 'GZ', MIN_VERSIONS
=> '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'fa
lse', BLOCKSIZE => '65536', IN_MEMORY => 'false', B
LOCKCACHE => 'true'}
1 row(s) in 0.1070 seconds
```
#### D.3.3。测试压缩性能
HBase 包含一个名为 LoadTestTool 的工具,它提供了测试压缩性能的机制。必须指定`-write`或`-update-read`作为第一个参数,如果未指定其他参数,则为每个选项打印使用建议。
LoadTestTool 用法
```
$ bin/hbase org.apache.hadoop.hbase.util.LoadTestTool -h
usage: bin/hbase org.apache.hadoop.hbase.util.LoadTestTool <options>
Options:
-batchupdate Whether to use batch as opposed to separate
updates for every column in a row
-bloom <arg> Bloom filter type, one of [NONE, ROW, ROWCOL]
-compression <arg> Compression type, one of [LZO, GZ, NONE, SNAPPY,
LZ4]
-data_block_encoding <arg> Encoding algorithm (e.g. prefix compression) to
use for data blocks in the test column family, one
of [NONE, PREFIX, DIFF, FAST_DIFF, ROW_INDEX_V1].
-encryption <arg> Enables transparent encryption on the test table,
one of [AES]
-generator <arg> The class which generates load for the tool. Any
args for this class can be passed as colon
separated after class name
-h,--help Show usage
-in_memory Tries to keep the HFiles of the CF inmemory as far
as possible. Not guaranteed that reads are always
served from inmemory
-init_only Initialize the test table only, don't do any
loading
-key_window <arg> The 'key window' to maintain between reads and
writes for concurrent write/read workload. The
default is 0.
-max_read_errors <arg> The maximum number of read errors to tolerate
before terminating all reader threads. The default
is 10.
-multiput Whether to use multi-puts as opposed to separate
puts for every column in a row
-num_keys <arg> The number of keys to read/write
-num_tables <arg> A positive integer number. When a number n is
speicfied, load test tool will load n table
parallely. -tn parameter value becomes table name
prefix. Each table name is in format
<tn>_1...<tn>_n
-read <arg> <verify_percent>[:<#threads=20>]
-regions_per_server <arg> A positive integer number. When a number n is
specified, load test tool will create the test
table with n regions per server
-skip_init Skip the initialization; assume test table already
exists
-start_key <arg> The first key to read/write (a 0-based index). The
default value is 0.
-tn <arg> The name of the table to read or write
-update <arg> <update_percent>[:<#threads=20>][:<#whether to
ignore nonce collisions=0>]
-write <arg> <avg_cols_per_key>:<avg_data_size>[:<#threads=20>]
-zk <arg> ZK quorum as comma-separated host names without
port numbers
-zk_root <arg> name of parent znode in zookeeper
```
LoadTestTool 的示例用法
```
$ hbase org.apache.hadoop.hbase.util.LoadTestTool -write 1:10:100 -num_keys 1000000
-read 100:30 -num_tables 1 -data_block_encoding NONE -tn load_test_tool_NONE
```
### D.4。启用数据块编码
编解码器内置于 HBase 中,因此无需额外配置。通过设置`DATA_BLOCK_ENCODING`属性在表上启用编解码器。在更改其 DATA_BLOCK_ENCODING 设置之前禁用该表。以下是使用 HBase Shell 的示例:
在表上启用数据块编码
```
hbase> disable 'test'
hbase> alter 'test', { NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF' }
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2820 seconds
hbase> enable 'test'
0 row(s) in 0.1580 seconds
```
验证 ColumnFamily 的数据块编码
```
hbase> describe 'test'
DESCRIPTION ENABLED
'test', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST true
_DIFF', BLOOMFILTER => 'ROW', REPLICATION_SCOPE =>
'0', VERSIONS => '1', COMPRESSION => 'GZ', MIN_VERS
IONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS =
> 'false', BLOCKSIZE => '65536', IN_MEMORY => 'fals
e', BLOCKCACHE => 'true'}
1 row(s) in 0.0650 seconds
```
## 附录 E:SQL over HBase
以下项目为 SQL over HBase 提供了一些支持。
### E.1。 Apache Phoenix
[Apache Phoenix](https://phoenix.apache.org)
### E.2。 Trafodion
[Trafodion:事务性 SQL-on-HBase](https://trafodion.incubator.apache.org/)
## 附录 F:YCSB
[YCSB:雅虎!云服务基准测试](https://github.com/brianfrankcooper/YCSB/)和 HBase
TODO:描述 YCSB 如何通过提供合适的集群负载而变穷。
TODO:描述 YCSB for HBase 的设置。特别是,在开始运行之前预先对你的表进行预分解。请参阅 [HBASE-4163 为 YCSB 基准创建拆分策略](https://issues.apache.org/jira/browse/HBASE-4163)了解为什么以及如何执行此操作的一些 shell 命令。
Ted Dunning 重新编写了 YCSB,因此它已经进行了专业化,并添加了用于验证工作负载的工具。见 [Ted Dunning 的 YCSB](https://github.com/tdunning/YCSB) 。
## 附录 G:HFile 格式
本附录描述了 HFile 格式的演变。
### G.1。 HBase 文件格式(版本 1)
由于我们将讨论对 HFile 格式的更改,因此简要概述原始(HFile 版本 1)格式。
#### G.1.1。版本 1 概述
版本 1 格式的 HFile 结构如下:
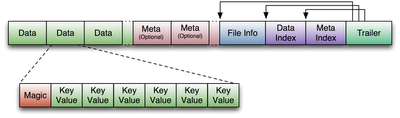图 21\. HFile V1 格式
#### G.1.2。版本 1 中的块索引格式
版本 1 中的块索引非常简单。对于每个条目,它包含:
1. 偏移(长)
2. 未压缩的大小(int)
3. 键(使用 Bytes.writeByteArray 编写的序列化字节数组)
1. 密钥长度为可变长度整数(VInt)
2. 关键字节
块索引中的条目数存储在固定文件尾部中,并且必须传递给读取块索引的方法。版本 1 中块索引的一个限制是它不提供块的压缩大小,这对于解压缩来说是必要的。因此,HFile 读取器必须从块之间的偏移差异推断出该压缩大小。我们在版本 2 中修复了这个限制,我们存储了磁盘块大小而不是未压缩的大小,并从块头获得未压缩的大小。
### G.2。带内联块的 HBase 文件格式(版本 2)
注意:此功能是在 HBase 0.92 中引入的
#### G.2.1。动机
我们发现有必要在遇到高内存使用率和由区域服务器中的大 Bloom 过滤器和块索引引起的慢启动时间后修改 HFile 格式。 Bloom 过滤器每个 HFile 可以达到 100 MB,在 20 个区域聚合时可以增加 2 GB。在同一组区域中,块索引的总大小可以增加到 6 GB。在加载所有块索引数据之前,不会将区域视为已打开。 Large Bloom 过滤器会产生不同的性能问题:第一个需要 Bloom 过滤器查找的 get 请求将导致加载整个 Bloom 过滤器位阵列的延迟。
为了加速区域服务器启动,我们打破 Bloom 过滤器并将索引阻塞到多个块中,并在它们填满时写出这些块,这也减少了 HFile writer 的内存占用。在 Bloom 过滤器的情况下,“填充块”意味着累积足够的密钥以有效地利用固定大小的位阵列,并且在块索引的情况下,我们累积所需大小的“索引块”。布隆过滤器块和索引块(我们称之为“内联块”)散布在数据块中,作为副作用,我们不再依赖块偏移之间的差异来确定数据块长度,就像在版本 1 中完成的那样。
HFile 是一种低级文件格式,它不应该处理特定于应用程序的细节,例如在 StoreFile 级别处理的 Bloom 过滤器。因此,我们在 HFile“内联”块中调用 Bloom 过滤器块。我们还为 HFile 提供了一个用于编写这些内联块的接口。
旨在减少区域服务器启动时间的另一种格式修改是使用连续的“加载打开”部分,该部分必须在打开 HFile 时加载到存储器中。目前,当 HFile 打开时,会有单独的搜索操作来读取预告片,数据/元索引和文件信息。要读取布隆过滤器,对其“数据”和“元”部分还有两个搜索操作。在版本 2 中,我们寻求一次阅读预告片并再次寻找从连续块中打开文件所需的其他内容。
#### G.2.2。版本 2 概述
引入上述功能的 HBase 版本同时读取版本 1 和 2 HFiles,但仅写入版本 2 HFiles。版本 2 HFile 的结构如下:
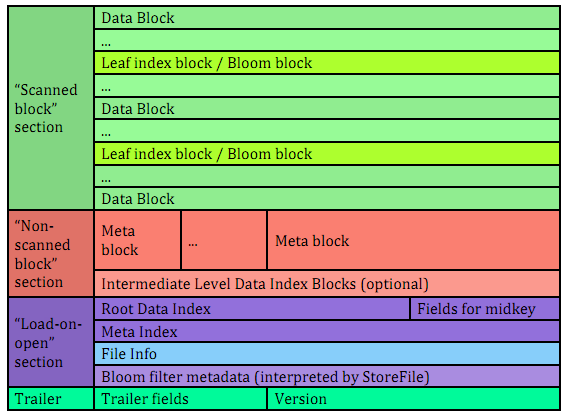图 22\. HFile 版本 2 结构
#### G.2.3。统一版本 2 块格式
在版本 2 中,数据部分中的每个块都包含以下字段:
1. 8 字节:块类型,相当于版本 1 的“魔术记录”的字节序列。支持的块类型是:
1. 数据 - 数据块
2. LEAF_INDEX - 多级块索引中的叶级索引块
3. BLOOM_CHUNK - Bloom 过滤器块
4. META - 元块(不再用于版本 2 中的 Bloom 过滤器)
5. INTERMEDIATE_INDEX - 多级块索引中的中间级索引块
6. ROOT_INDEX - 多级块索引中的根级索引块
7. FILE_INFO - “文件信息”块,元数据的小键值映射
8. BLOOM_META - 加载时打开部分中的 Bloom 过滤器元数据块
9. TRAILER - 固定大小的文件预告片。与上述相反,这不是 HFile v2 块,而是固定大小(对于每个 HFile 版本)数据结构
10. INDEX_V1 - 此块类型仅用于传统的 HFile v1 块
2. 块数据的压缩大小,不包括头(int)。
扫描 HFile 数据时可用于跳过当前数据块。
3. 块的数据未压缩大小,不包括头(int)
如果压缩算法为 NONE,则等于压缩大小
4. 相同类型的前一个块的文件偏移量(长)
可用于寻找以前的数据/索引块
5. 压缩数据(如果压缩算法为 NONE,则为未压缩数据)。
以上格式的块用于以下 HFile 部分:
扫描块部分
该部分之所以如此命名是因为它包含了顺序扫描 HFile 时需要读取的所有数据块。还包含 Leaf 索引块和 Bloom 块块。
非扫描块部分
此部分仍包含统一格式的 v2 块,但在执行顺序扫描时不必读取它。本节包含“元”块和中级索引块。
我们在版本 2 中支持“meta”块的方式与版本 1 中支持的方式相同,即使我们不再将 Bloom 过滤器数据存储在这些块中。
#### G.2.4。阻止版本 2 中的索引
HFile 版本 2 中有三种类型的块索引,以两种不同的格式(root 和 non-root)存储:
1. 数据索引 - 版本 2 多级块索引,包括:
1. 版本 2 根索引,存储在文件的数据块索引部分
2. (可选)版本 2 中间级别,以非根格式存储在文件的数据索引部分中。如果存在叶级块,则只能存在中间级别
3. (可选)版本 2 叶级别,以非根格式存储,与数据块内联
2. 元索引 - 仅版本 2 根索引格式,存储在文件的元索引部分中
3. Bloom 索引 - 仅版本 2 根索引格式,作为 Bloom 过滤器元数据的一部分存储在''load-on-open'部分中。
#### G.2.5。版本 2 中的根块索引格式
此格式适用于:
1. 版本 2 数据索引的根级别
2. 版本 2 中的整个 meta 和 Bloom 索引始终是单级的。
版本 2 根索引块是以下格式的条目序列,类似于版本 1 块索引的条目,但存储磁盘大小而不是未压缩大小。
1. Offset (long)
该偏移可以指向数据块或更深层索引块。
2. 磁盘大小(int)
3. 键(使用 Bytes.writeByteArray 存储的序列化字节数组)
4. 钥匙(VInt)
5. Key bytes
单级版本 2 块索引仅包含单个根索引块。要读取版本 2 的根索引块,需要知道条目数。对于数据索引和元索引,条目数存储在预告片中,对于 Bloom 索引,它存储在复合布隆过滤器元数据中。
对于多级块索引,除了上面描述的数据结构之外,我们还将以下字段存储在 HFile 的 load-on-open 部分的根索引块中:
1. 中叶索引块偏移
2. 中间叶块磁盘大小(表示包含对文件“中间”数据块的引用的叶索引块)
3. 中间叶级块中的中间键(在下面定义)的索引。
这些附加字段用于有效地检索 HFile 分裂中使用的 HFile 的中间密钥,我们将其定义为具有零基索引(n-1)/ 2 的块的第一个密钥,如果总数为 HFile 中的块是 n。此定义与 HFile 版本 1 中确定中间密钥的方式一致,并且通常是合理的,因为块的平均大小可能相同,但我们没有对单个键/值对大小的任何估计。
在编写版本 2 HFile 时,每个叶级索引块指向的数据块总数将被跟踪。当我们完成写入并确定叶级块的总数时,很清楚哪个叶级块包含中键,并且计算上面列出的字段。当读取 HFile 并请求中键时,我们检索中间叶索引块(可能来自块缓存)并从该叶块内的适当位置获取中键值。
#### G.2.6。版本 2 中的非 root 块索引格式
此格式适用于版本 2 多级数据块索引的中间级别和叶索引块。每个非根索引块的结构如下。
1. numEntries:条目数(int)。
2. entryOffsets:块中条目偏移的“二级索引”,便于快速二进制搜索键(`numEntries + 1` int 值)。最后一个值是此索引块中所有条目的总长度。例如,在条目大小为 60,80,50 的非根索引块中,“二级索引”将包含以下 int 数组:`{0, 60, 140, 190}`。
3. 参赛作品。每个条目包含:
1. 文件中此条目引用的块的偏移量(长整数)
2. 引用块的磁盘大小(int)
3. 键。长度可以从 entryOffsets 计算。
#### G.2.7。版本 2 中的 Bloom 过滤器
与版本 1 相比,在版本 2 中,HFile Bloom 过滤器元数据存储在 HFile 的 open-on-open 部分中,以便快速启动。
1. 复合布隆过滤器。
2. Bloom 过滤器版本= 3(int)。曾经有一个 DynamicByteBloomFilter 类,其 Bloom 过滤器版本号为 2
3. 所有复合 Bloom 过滤器块的总字节大小(长)
4. 散列函数数(int)
5. 哈希函数的类型(int)
6. 插入 Bloom 过滤器的总密钥数(长)
7. 布隆过滤器中的最大键数(长)
8. 块数(int)
9. 用于 Bloom 过滤器键的比较器类,使用 Bytes.writeByteArray 存储的 UTF&gt; 8 编码字符串
10. 版本 2 根块索引格式中的 Bloom 块索引
#### G.2.8。版本 1 和 2 中的文件信息格式
文件信息块是从字节数组到字节数组的序列化映射,包括以下键。 StoreFile 级逻辑为此添加了更多密钥。
| hfile.LASTKEY |文件的最后一个键(字节数组)| | hfile.AVG_KEY_LEN |文件中的平均密钥长度(int)| | hfile.AVG_VALUE_LEN |文件(int)|中的平均值长度
在版本 2 中,我们没有更改文件格式,但是我们将文件信息移动到文件的最后一部分,可以在打开 HFile 时将其作为一个块加载。
此外,我们不再将比较器存储在版本 2 文件信息中。相反,我们将其存储在固定文件预告片中。这是因为我们需要在解析 HFile 的 open-on-open 部分时知道比较器。
#### G.2.9。修复了版本 1 和版本 2 之间的文件尾部格式差异
下表显示了版本 1 和版本 2 中固定文件预告片之间的常见字段和不同字段。请注意,预告片的大小因版本而异,因此仅在一个版本中“固定”。但是,版本始终存储为文件中的最后四个字节整数。
| 版本 1 | 版本 2 |
| --- | --- |
| | 文件信息偏移(长) |
| 数据索引偏移量(长) | loadOnOpenOffset(long)/打开文件时需要加载的部分的偏移量./ |
| | 数据索引条目数(int) |
| metaIndexOffset(long)/版本 1 读者不使用此字段,因此我们将其从版本 2 中删除。 | uncompressedDataIndexSize(long)/整个数据块索引的未压缩总大小,包括根级别,中级别和叶级别块./ |
| | 元索引条目数(int) |
| | 未压缩字节总数(长) |
| numEntries(int) | numEntries(长) |
| 压缩编解码器:0 = LZO,1 = GZ,2 = NONE(int) | Compression codec: 0 = LZO, 1 = GZ, 2 = NONE (int) |
| | 数据块索引中的级别数(int) |
| | firstDataBlockOffset(long)/第一个数据块的偏移量。扫描时使用./ |
| | lastDataBlockEnd(long)/最后一个键/值数据块之后的第一个字节的偏移量。扫描时我们不需要超出此偏移量./ |
| 版本:1(int) | 版本:2(int) |
#### G.2.10。 getShortMidpointKey(数据索引块的优化)
注意:此优化是在 HBase 0.95+中引入的
HFiles 包含许多包含一系列已排序单元格的块。每个单元都有一个键。为了在读取 Cells 时保存 IO,HFile 还有一个索引,它将 Cell 的开始键映射到特定块开头的偏移量。在此优化之前,HBase 将使用每个数据块中第一个单元的键作为索引键。
在 HBASE-7845 中,我们生成一个新的键,其按字典顺序大于前一个块的最后一个键,并按字典顺序等于或小于当前块的起始键。虽然实际的密钥可能很长,但这个“假密钥”或“虚拟密钥”可以短得多。例如,如果前一个块的停止键是“快速棕色狐狸”,则当前块的开始键是“谁”,我们可以在我们的 hfile 索引中使用“r”作为我们的虚拟键。
这有两个好处:
* 拥有较短的密钥会减少 hfile 索引的大小,(允许我们在内存中保留更多的索引),以及
* 当目标密钥位于“虚拟密钥”和目标块中第一个元素的密钥之间时,使用更靠近前一个块的结束键的东西允许我们避免可能的额外 IO。
此优化(由 getShortMidpointKey 方法实现)的灵感来自 LevelDB 的 ByteWiseComparatorImpl :: FindShortestSeparator()和 FindShortSuccessor()。
### G.3。具有安全增强功能的 HBase 文件格式(版本 3)
注意:此功能是在 HBase 0.98 中引入的
#### G.3.1。动机
HFile 的第 3 版进行了更改,以简化静态加密和单元级元数据的加密管理(这又是单元级 ACL 和单元级可见性标签所必需的)。有关更多信息,请参阅 [hbase.encryption.server](#hbase.encryption.server) , [hbase.tags](#hbase.tags) , [hbase.accesscontrol.configuration](#hbase.accesscontrol.configuration) 和 [hbase.visibility.labels](#hbase.visibility.labels) 。
#### G.3.2。概观
引入上述功能的 HBase 版本在版本 1,2 和 3 中读取 HFile,但仅写入版本 3 HFile。版本 3 HFile 的结构与版本 2 HFile 相同。有关更多信息,请参阅 [hfilev2.overview](#hfilev2.overview) 。
#### G.3.3。版本 3 中的文件信息块
版本 3 将另外两条信息添加到文件信息块中的保留键。
| hfile.MAX_TAGS_LEN |存储此 hfile(int)中任何单个单元格的序列化标记所需的最大字节数| hfile.TAGS_COMPRESSED |该 hfile 的块编码器是否压缩标签? (布尔)。仅当 hfile.MAX_TAGS_LEN 也存在时才应存在。 |
在读取版本 3 HFile 时,`MAX_TAGS_LEN`的存在用于确定如何对数据块内的单元进行反序列化。因此,消费者必须在读取任何数据块之前读取文件的信息块。
在编写版本 3 HFile 时,HBase 在将 memstore 刷新到底层文件系统时将始终包含[COD0]。
压缩现有文件时,如果所选的所有文件本身不包含任何带标记的单元格,则默认编写器将省略`MAX_TAGS_LEN`。
有关压缩文件选择算法的详细信息,请参见[压缩](#compaction)。
#### G.3.4。版本 3 中的数据块
内的 HFILE,HBase 的细胞被存储在数据块作为键值来的序列(见 [hfilev1.overview](#hfilev1.overview) 或[拉斯乔治的很好的介绍 HBase 的寄存](http://www.larsgeorge.com/2009/10/hbase-architecture-101-storage.html))。在版本 3 中,这些 KeyValue 可选地包含一组 0 个或更多标记:
| 版本 1&amp; 2,版本 3 没有 MAX_TAGS_LEN | 版本 3,MAX_TAGS_LEN |
| --- | --- |
| 密钥长度(4 个字节) |
| 值长度(4 个字节) |
| 关键字节(变量) |
| 值字节(变量) |
| | 标签长度(2 个字节) |
| | 标签字节(变量) |
如果给定 HFile 的 info 块包含`MAX_TAGS_LEN`的条目,则每个单元格将包含该单元格标签的长度,即使该长度为零。实际标签存储为标签长度(2 个字节),标签类型(1 个字节),标签字节(变量)的序列。单个标记的字节格式取决于标记类型。
请注意,对 info 块内容的依赖意味着在读取任何数据块之前,必须首先处理文件的 info 块。它还意味着在写入数据块之前,您必须知道文件的信息块是否包含`MAX_TAGS_LEN`。
#### G.3.5。修复了版本 3 中的文件预告片
使用 HFile 版本 3 编写的固定文件预告片始终使用协议缓冲区进行序列化。此外,它还为名为 encryption_key 的版本 2 协议缓冲区添加了一个可选字段。如果 HBase 配置为加密 HFile,则此字段将存储此特定 HFile 的数据加密密钥,使用 AES 使用当前群集主密钥加密。有关更多信息,请参阅 [hbase.encryption.server](#hbase.encryption.server) 。
## 附录 H:关于 HBase 的其他信息
### H.1。 HBase 视频
HBase 简介
* [Todd Lipcon 介绍 HBase](https://vimeo.com/23400732) (2011 年芝加哥数据峰会)。
* [使用 HBase](https://vimeo.com/26804675) 在 Facebook 上建立实时服务作者:Jonathan Gray(柏林流行语 2011)
* [Jean-Daniel Cryans 的 HBase](http://www.cloudera.com/videos/hw10_video_how_stumbleupon_built_and_advertising_platform_using_hbase_and_hadoop) 的多重用途(柏林流行语 2011)。
### H.2。 HBase 演示文稿(幻灯片)
[高级 HBase 架构设计](https://www.slideshare.net/cloudera/hadoop-world-2011-advanced-hbase-schema-design-lars-george-cloudera)作者:Lars George(Hadoop World 2011)。
[Todd Lipcon 介绍 HBase](http://www.slideshare.net/cloudera/chicago-data-summit-apache-hbase-an-introduction) (2011 年芝加哥数据峰会)。
[通过 Ryan Rawson,Jonathan Gray(Hadoop World 2009)从 HBase 安装](http://www.slideshare.net/cloudera/hw09-practical-h-base-getting-the-most-from-your-h-base-install)中获得最大收益。
### H.3。 HBase 论文
[BigTable](http://research.google.com/archive/bigtable.html) 由谷歌(2006)。
[HBase 和 HDFS Locality](http://www.larsgeorge.com/2010/05/hbase-file-locality-in-hdfs.html) 作者:Lars George(2010)。
[无关系:非关系型数据库的混合祝福](http://ianvarley.com/UT/MR/Varley_MastersReport_Full_2009-08-07.pdf),Ian Varley(2009)。
### H.4。 HBase 网站
[Cloudera 的 HBase 博客](https://blog.cloudera.com/blog/category/hbase/)有很多链接到有用的 HBase 信息。
[CAP Confusion](https://blog.cloudera.com/blog/2010/04/cap-confusion-problems-with-partition-tolerance/) 是分布式存储系统背景信息的相关条目。
来自 DZone 的 [HBase RefCard](http://refcardz.dzone.com/refcardz/hbase) 。
### H.5。 HBase 书籍
[HBase:Lars George 的权威指南](http://shop.oreilly.com/product/0636920014348.do)。
### H.6。 Hadoop 书籍
[Hadoop:Tom White 的权威指南](http://shop.oreilly.com/product/9780596521981.do)。
## 附录 I:HBase 历史
* 2006 年: [BigTable](http://research.google.com/archive/bigtable.html) 论文由 Google 发布。
* 2006 年(年底):HBase 开发。
* 2008 年:HBase 成为 Hadoop 子项目。
* 2010 年:HBase 成为 Apache 顶级项目。
## 附录 J:HBase 和 Apache 软件基金会
HBase 是 Apache Software Foundation 中的一个项目,因此 ASF 有责任确保项目健康。
### J.1。 ASF 开发流程
有关 ASF 结构的各种信息(例如,PMC,提交者,贡献者),有关贡献和参与的提示以及开源在 ASF 中的工作原理,请参见 [Apache 开发流程页面](https://www.apache.org/dev/#committers)。
### J.2。 ASF 董事会报告
每季度一次,ASF 投资组合中的每个项目都会向 ASF 董事会提交报告。这是由 HBase 项目负责人和提交者完成的。有关详细信息,请参阅 [ASF 板报告](https://www.apache.org/foundation/board/reporting)。
## 附录 K:Apache HBase Orca
图 23\. Apache HBase Orca,HBase 颜色,&amp;字形
[Orca 是 Apache HBase 的吉祥物。](https://issues.apache.org/jira/browse/HBASE-4920) 见 NOTICES.txt。我们在这里得到的 Orca 徽标: [http://www.vectorfree.com/jumping-orca](http://www.vectorfree.com/jumping-orca) 它是 Creative Commons Attribution 3.0 的许可。参见 [https://creativecommons.org/licenses/by/3.0/us/](https://creativecommons.org/licenses/by/3.0/us/) 我们通过剥离彩色背景,反转它然后旋转一些来改变徽标。
“官方”HBase 颜色是“国际橙色(工程)”,旧金山[金门大桥](https://en.wikipedia.org/wiki/International_orange)的颜色和 NASA 使用的太空服。
我们的'字体'是 [Bitsumishi](http://www.dafont.com/bitsumishi.font) 。
## 附录 L:在 HBase 中启用类似 Dapper 的跟踪
HBase 包括使用开源跟踪库 [Apache HTrace](https://htrace.incubator.apache.org/) 跟踪请求的工具。设置跟踪非常简单,但是它目前需要对客户端代码进行一些非常小的更改(将来可能会删除此要求)。
在 [HBASE-6449](https://issues.apache.org/jira/browse/HBASE-6449) 中添加了在 HBase 中使用 HTrace 3 支持此功能。从 HBase 2.0 开始,通过 [HBASE-18601](https://issues.apache.org/jira/browse/HBASE-18601) 对 HTrace 4 进行了不兼容的更新。本节提供的示例将使用 HTrace 4 包名称,语法和约定。有关较旧的示例,请参阅本指南的早期版本。
### L.1。 SpanReceivers
跟踪系统通过在称为“Spans”的结构中收集信息来工作。您可以通过实现`SpanReceiver`接口来选择接收此信息的方式,该接口定义了一种方法:
```
public void receiveSpan(Span span);
```
每当跨度完成时,此方法用作回调。 HTrace 允许您根据需要使用尽可能多的 SpanReceivers,因此您可以轻松地将跟踪信息发送到多个目的地。
通过在 _hbase-site.xml_ 属性中实现`SpanReceiver`的类的完全限定类名称的逗号分隔列表来配置您希望我们使用的 SpanReceivers:`hbase.trace.spanreceiver.classes`。
HTrace 包含`LocalFileSpanReceiver`,它以基于 JSON 的格式将所有跨度信息写入本地文件。 `LocalFileSpanReceiver`在 _hbase-site.xml_ 中查找`hbase.local-file-span-receiver.path`属性,其值描述节点应写入其跨度信息的文件的名称。
```
<property>
<name>hbase.trace.spanreceiver.classes</name>
<value>org.apache.htrace.core.LocalFileSpanReceiver</value>
</property>
<property>
<name>hbase.htrace.local-file-span-receiver.path</name>
<value>/var/log/hbase/htrace.out</value>
</property>
```
HTrace 还提供`ZipkinSpanReceiver`,它将跨度转换为 [Zipkin](http://github.com/twitter/zipkin) span 格式并将它们发送到 Zipkin 服务器。要使用此 span 接收器,您需要将 htrace-zipkin jar 安装到群集中所有节点上的 HBase 类路径中。
_htrace-zipkin_ 发布到 [Maven 中央存储库](http://search.maven.org/#search%7Cgav%7C1%7Cg%3A%22org.apache.htrace%22%20AND%20a%3A%22htrace-zipkin%22)。您可以从那里获得最新版本或只是在本地构建它(请参阅 [HTrace](https://htrace.incubator.apache.org/) 主页以获取有关如何执行此操作的信息),然后将其复制到所有节点。
`ZipkinSpanReceiver`用于 _hbase-site.xml_ 中名为`hbase.htrace.zipkin.collector-hostname`和`hbase.htrace.zipkin.collector-port`的属性,其值描述了发送范围信息的 Zipkin 收集器服务器。
```
<property>
<name>hbase.trace.spanreceiver.classes</name>
<value>org.apache.htrace.core.ZipkinSpanReceiver</value>
</property>
<property>
<name>hbase.htrace.zipkin.collector-hostname</name>
<value>localhost</value>
</property>
<property>
<name>hbase.htrace.zipkin.collector-port</name>
<value>9410</value>
</property>
```
如果您不想使用附带的跨接收发器,建议您编写自己的接收器(以`LocalFileSpanReceiver`为例)。如果您认为其他人会从您的接收器中受益,请向 HTrace 项目提交 JIRA。
## 201.客户修改
为了在客户端代码中启用跟踪,您必须初始化每个客户端进程一次向接收器发送跨度的模块。
```
private SpanReceiverHost spanReceiverHost;
...
Configuration conf = HBaseConfiguration.create();
SpanReceiverHost spanReceiverHost = SpanReceiverHost.getInstance(conf);
```
然后,您只需在您认为有趣的请求之前开始跟踪跨度,并在请求完成时关闭它。例如,如果要跟踪所有获取操作,请更改此设置:
```
Configuration config = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("t1"));
Get get = new Get(Bytes.toBytes("r1"));
Result res = table.get(get);
```
成:
```
TraceScope ts = Trace.startSpan("Gets", Sampler.ALWAYS);
try {
Table table = connection.getTable(TableName.valueOf("t1"));
Get get = new Get(Bytes.toBytes("r1"));
Result res = table.get(get);
} finally {
ts.close();
}
```
如果你想跟踪一半的“获取”操作,你会传入:
```
new ProbabilitySampler(0.5)
```
代替`Sampler.ALWAYS`至`Trace.startSpan()`。有关采样器的更多信息,请参见 HTrace _README_ 。
## 202.追踪 HBase Shell
您可以使用`trace`命令跟踪来自 HBase Shell 的请求。 `trace 'start'`命令打开跟踪,`trace 'stop'`命令关闭跟踪。
```
hbase(main):001:0> trace 'start'
hbase(main):002:0> put 'test', 'row1', 'f:', 'val1' # traced commands
hbase(main):003:0> trace 'stop'
```
`trace 'start'`和`trace 'stop'`始终返回表示是否存在正在进行的跟踪的布尔值。结果,`trace 'stop'`成功返回 false。如果打开跟踪,`trace 'status'`只会返回。
```
hbase(main):001:0> trace 'start'
=> true
hbase(main):002:0> trace 'status'
=> true
hbase(main):003:0> trace 'stop'
=> false
hbase(main):004:0> trace 'status'
=> false
```
## 附录 M:0.95 RPC 规范
在 0.95 中,所有客户端/服务器通信都是使用 [protobuf'ed](https://developers.google.com/protocol-buffers/) 消息而不是 [Hadoop Writables](https://hadoop.apache.org/docs/current/api/org/apache/hadoop/io/Writable.html) 完成的。因此我们的 RPC 线格式会发生变化本文档描述了客户端/服务器请求/响应协议以及我们新的 RPC 线路格式。
对于 0.94 及之前的 RPC,请参阅 Benoît/ Tsuna 的[非官方 Hadoop / HBase RPC 协议文档](https://github.com/OpenTSDB/asynchbase/blob/master/src/HBaseRpc.java#L164)。有关我们如何达到此规范的更多背景信息,请参阅 [HBase RPC:WIP](https://docs.google.com/document/d/1WCKwgaLDqBw2vpux0jPsAu2WPTRISob7HGCO8YhfDTA/edit#)
### M.1。目标
1. 我们可以发展一种线形式
2. 一种格式,不需要我们的重写服务器核心或从根本上改变其当前架构(以后)。
### M.2。去做
1. 当前指定格式的问题列表以及我们希望在版本 2 中的位置等。例如,如果要移动服务器异步或支持流/分块,我们必须更改什么?
2. 关于它如何工作的图表
3. 简洁地描述线格式的语法。目前我们有这些单词和 rpc protobuf idl 的内容,但来回的语法将有助于 groking rpc。此外,客户端/服务器上的一个小型状态机交互将有助于理解(并确保正确实现)。
### M.3。 RPC
客户端将发送有关连接建立的设置信息。此后,客户端调用针对远程服务器的方法发送 protobuf 消息并接收 protobuf 消息作为响应。沟通是同步的。所有来回前面都有一个 int,它具有请求/响应的总长度。可选地,Cells(KeyValues)可以在后续 Cell 块中的 protobufs 之外传递(因为[我们不能 protobuf 兆字节的 KeyValues](https://docs.google.com/document/d/1WEtrq-JTIUhlnlnvA0oYRLp0F8MKpEBeBSCFcQiacdw/edit#) 或 Cells)。这些 CellBlock 被编码并可选地压缩。
有关所涉及的 protobufs 的更多详细信息,请参阅 master 中的 [RPC.proto](https://github.com/apache/hbase/blob/master/hbase-protocol/src/main/protobuf/RPC.proto) 文件。
#### M.3.1。连接设置
客户端启动连接。
##### 客户
在连接设置上,客户端发送前导码,后跟连接头。
<preamble>
```
<MAGIC 4 byte integer> <1 byte RPC Format Version> <1 byte auth type>
```
我们需要 auth 方法规范。这里,如果启用 auth,则编码连接头。
例如:HBas0x000x50 - 4 个字节的 MAGIC - “HBas” - 加上一个字节的版本,在这种情况下为 0,还有一个字节,0x50(SIMPLE)。一个身份验证类型。
<protobuf connectionheader="" message="">
有用户信息和``protocol'',以及客户端将使用发送 CellBlocks 的编码器和压缩。 CellBlock 编码器和压缩器用于连接的生命周期。 CellBlock 编码器实现 org.apache.hadoop.hbase.codec.Codec。然后也可以压缩 CellBlock。压缩器实现 org.apache.hadoop.io.compress.CompressionCodec。这个 protobuf 是使用 writeDelimited 编写的,所以它是以带有序列化长度的 pb varint 开头的
##### 服务器
客户端发送前导码和连接头后,如果连接设置成功,服务器不响应。没有响应意味着服务器准备好接受请求并给出响应。如果前导中的版本或身份验证不合适或服务器在解析前导码时遇到问题,则会抛出 org.apache.hadoop.hbase.ipc.FatalConnectionException 来解释错误,然后断开连接。如果连接头中的客户端 - 即连接前导码后面的 protobuf'd 消息 - 要求服务器不支持服务器或服务器没有的编解码器,我们再次抛出 FatalConnectionException 并附带说明。
#### M.3.2。请求
建立连接后,客户端发出请求。服务器响应。
请求由 protobuf RequestHeader 和 protobuf Message 参数组成。标头包括方法名称和可选的 CellBlock 上可能跟随的元数据。参数类型适合被调用的方法:即,如果我们正在执行 getRegionInfo 请求,则 protobuf Message param 将是 GetRegionInfoRequest 的实例。响应将是 GetRegionInfoResponse。 CellBlock 可选地用于传送大量 RPC 数据:即 Cells / KeyValues。
##### 索取零件
<total length="">
该请求以一个 int 开头,该 int 保存后面的总长度。
<protobuf message="" requestheader="">
将包含 call.id,trace.id 和方法名称等,包括 IFF 上的 Cell 块上的可选元数据。数据在此 pb 消息中是内联的,或者可选地包含在以下 CellBlock 中
<protobuf message="" param="">
如果调用的方法是 getRegionInfo,如果您研究客户端的服务描述符到 regionserver 协议,您会发现请求在此位置发送 GetRegionInfoRequest protobuf 消息参数。
<cellblock>
经编码且可选地压缩的 Cell 块。
#### M.3.3。响应
与 Request 相同,它是一个 protobuf ResponseHeader,后跟一个 protobuf Message 响应,其中 Message 响应类型适合调用的方法。大量数据可能会出现在以下 CellBlock 中。
##### 响应部分
<total length="">
响应以一个 int 开头,该 int 保存了后面的总长度。
<protobuf message="" responseheader="">
将有 call.id 等。如果处理失败将包括异常。可选地包括关于可选的元数据,IFF 下面有一个 CellBlock。
<protobuf message="" response="">
如果例外,则返回或可能无效。如果调用的方法是 getRegionInfo,如果您研究客户端的服务描述符到 regionserver 协议,您会发现响应在此位置发送 GetRegionInfoResponse protobuf 消息参数。
<cellblock>
An encoded and optionally compressed Cell block.
#### M.3.4。例外
有两种不同的类型。请求失败,它封装在响应的响应头内。连接保持打开状态以接收新请求。第二种类型 FatalConnectionException 会终止连接。
例外可以携带额外的信息。请参阅 ExceptionResponse protobuf 类型。它有一个标志,表示不重试以及其他杂项有效负载,以帮助提高客户响应能力。
#### M.3.5。牢房
这些都没有版本。服务器可以执行编解码器,也可以不执行。如果编解码器的新版本说更严格的编码,那么给它一个新的类名。编解码器将一直存在于服务器上,以便老客户端可以连接。
### M.4。笔记
约束
在某些部分,当前的线路格式 - 即所有请求和响应前面都有一个长度 - 由当前的服务器非异步架构决定。
一个胖 pb 请求或标题+参数
我们用 pb 标题跟随 pb param 发出请求和 pb 标题然后是 pb 响应。执行 header + param 而不是一个包含 header 和 param 内容的 protobuf 消息:
1. 更接近我们现在拥有的
2. 有一个单一的脂肪 pb 需要额外的复制将已经 pb'd 的参数放入脂肪请求 pb 的主体(并且相同的结果)
3. 在我们阅读参数之前,我们可以决定是否接受请求;例如,请求可能是低优先级。当然,我们一次性读取 header + param,因为服务器当前已实现,因此这是一个 TODO。
优点很小。如果以后,胖请求有明显的优势,以后可以推出 v2。
#### M.4.1。 RPC 配置
CellBlock 编解码器
要启用默认`KeyValueCodec`以外的编解码器,请将`hbase.client.rpc.codec`设置为要使用的 Codec 类的名称。编解码器必须实现 hbase 的`Codec`接口。连接建立后,所有传递的单元块将与此编解码器一起发送。只要编解码器在服务器的 CLASSPATH 上,服务器就会使用相同的编解码器返回单元块(否则你将获得`UnsupportedCellCodecException`)。
要更改默认编解码器,请设置`hbase.client.default.rpc.codec`。
要完全禁用单元块并转到纯 protobuf,请将默认值设置为空 String,并且不要在 Configuration 中指定编解码器。因此,将`hbase.client.default.rpc.codec`设置为空字符串,不要设置`hbase.client.rpc.codec`。这将导致客户端连接到没有指定编解码器的服务器。如果服务器没有看到编解码器,它将返回纯 protobuf 中的所有响应。一直运行纯 protobuf 比使用 cellblocks 运行要慢。
压缩
使用 hadoop 的压缩编解码器。要启用压缩传递的 CellBlock,请将`hbase.client.rpc.compressor`设置为要使用的 Compressor 的名称。 Compressor 必须实现 Hadoop 的 CompressionCodec 接口。连接建立后,所有传递的单元块将被压缩发送。只要压缩器在 CLASSPATH 上,服务器就会返回使用同一压缩器压缩的单元块(否则你将获得`UnsupportedCompressionCodecException`)。
## 附录 N:HBase 版本中已知的不兼容性
## 203\. HBase 2.0 不兼容的变化
本附录描述了早期版本的 HBase 与 HBase 2.0 的不兼容更改。此列表并不意味着完全包含所有可能的不兼容性。相反,这些内容旨在深入了解大多数用户将从 HBase 1.x 版本中遇到的一些明显的不兼容性。
### 203.1。 HBase 2.0 的主要变更清单
* HBASE-1912-HBCK 是用于捕获不一致性的 HBase 数据库检查工具。作为 HBase 管理员,您不应使用 HBase 1.0 版 hbck 工具来检查 HBase 2.0 数据库。这样做会破坏数据库并引发异常错误。
* HBASE-16189 和 HBASE-18945-您无法通过 HBase 1.0 版本打开 HBase 2.0 hfiles。如果您是使用 HBase 版本 1.x 的管理员或 HBase 用户,则必须先滚动升级到最新版本的 HBase 1.x,然后再升级到 HBase 2.0。
* HBASE-18240 - 更改了 ReplicationEndpoint 接口。它还引入了一个新的 hbase-third party 1.0,它打包了所有第三方实用程序,这些实用程序预计将在 hbase 集群中运行。
### 203.2。协处理器 API 更改
* HBASE-16769 - 来自 MasterObserver 和 RegionServerObserver 的不推荐的 PB 引用。
* HBASE-17312 - [JDK8]使用 Observer 协处理器的默认方法。 BaseMasterAndRegionObserver,BaseMasterObserver,BaseRegionObserver,BaseRegionServerObserver 和 BaseWALObserver 的接口类使用 JDK8 的'default'关键字来提供空的和无操作的实现。
* 接口 HTableInterface HBase 2.0 对下面列出的方法进行了以下更改:
#### 203.2.1。 [ - ]接口协处理器环境变化(2)
| 更改 | 结果 |
| --- | --- |
| 抽象方法 getTable(TableName)已被删除。 | NoSuchMethodError 异常可能会中断客户端程序。 |
| 抽象方法 getTable(TableName,ExecutorService)已被删除。 | A client program may be interrupted by NoSuchMethodError exception. |
* 公众观众
下表描述了协处理器的更改。
##### [ - ]类 CoprocessorRpcChannel(1)
| Change | Result |
| --- | --- |
| 这个类已成为界面。 | IncompatibleClassChangeError 或 InstantiationError 异常可能会中断客户端程序,具体取决于此类的用法。 |
##### 类 CoprocessorHost
Audience Private 但已删除的类。
| Change | Result |
| --- | --- |
| 字段协处理器的类型已从 java.util.SortedSet <e>更改为 org.apache.hadoop.hbase.util.SortedList <e>。</e></e> | NoSuchFieldError 异常可能会中断客户端程序。 |
#### 203.2.2。 MasterObserver
HBase 2.0 引入了对 MasterObserver 接口的以下更改。
##### [ - ]界面 MasterObserver(14)
| Change | Result |
| --- | --- |
| 已从此界面中删除抽象方法 voidpostCloneSnapshot(ObserverContext <mastercoprocessorenvironment>,HBaseProtos.SnapshotDescription,HTableDescriptor)。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 voidpostCreateTable(ObserverContext <mastercoprocessorenvironment>,HTableDescriptor,HRegionInfo [])。</mastercoprocessorenvironment> | NoSuchMethodErrorexception 可能会中断客户端程序。 |
| 已从此界面中删除抽象方法 voidpostDeleteSnapshot(ObserverContext <mastercoprocessorenvironment>,HBaseProtos.SnapshotDescription)。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此接口中删除抽象方法 voidpostGetTableDescriptors(ObserverContext <mastercoprocessorenvironment>,List <htabledescriptor>)。</htabledescriptor></mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此接口中删除抽象方法 voidpostModifyTable(ObserverContext <mastercoprocessorenvironment>,TableName,HTableDescriptor)。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此界面中删除抽象方法 voidpostRestoreSnapshot(ObserverContext <mastercoprocessorenvironment>,HBaseProtos.SnapshotDescription,HTableDescriptor)。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此界面中删除抽象方法 voidpostSnapshot(ObserverContext <mastercoprocessorenvironment>,HBaseProtos.SnapshotDescription,HTableDescriptor)。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此界面中删除抽象方法 voidpreCloneSnapshot(ObserverContext <mastercoprocessorenvironment>,HBaseProtos.SnapshotDescription,HTableDescriptor)。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此接口中删除抽象方法 voidpreCreateTable(ObserverContext <mastercoprocessorenvironment>,HTableDescriptor,HRegionInfo [])。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此界面中删除抽象方法 voidpreDeleteSnapshot(ObserverContext <mastercoprocessorenvironment>,HBaseProtos.SnapshotDescription)。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此接口中删除抽象方法 voidpreGetTableDescriptors(ObserverContext <mastercoprocessorenvironment>,List <tablename>,List <htabledescriptor>)。</htabledescriptor></tablename></mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此接口中删除抽象方法 voidpreModifyTable(ObserverContext <mastercoprocessorenvironment>,TableName,HTableDescriptor)。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此界面中删除抽象方法 voidpreRestoreSnapshot(ObserverContext <mastercoprocessorenvironment>,HBaseProtos.SnapshotDescription,HTableDescriptor)。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
| 已从此界面中删除抽象方法 voidpreSnapshot(ObserverContext <mastercoprocessorenvironment>,HBaseProtos.SnapshotDescription,HTableDescriptor)。</mastercoprocessorenvironment> | A client program may be interrupted by NoSuchMethodErrorexception. |
#### 203.2.3。 RegionObserver
HBase 2.0 引入了对 RegionObserver 接口的以下更改。
##### [ - ] interface RegionObserver(13)
| Change | Result |
| --- | --- |
| 已从此界面中删除抽象方法 voidpostCloseRegionOperation(ObserverContext <regioncoprocessorenvironment>,HRegion.Operation)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此接口中删除抽象方法 voidpostCompactSelection(ObserverContext <regioncoprocessorenvironment>,Store,ImmutableList <storefile>)。</storefile></regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 voidpostCompactSelection(ObserverContext <regioncoprocessorenvironment>,Store,ImmutableList <storefile>,CompactionRequest)。</storefile></regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此接口中删除抽象方法 voidpostGetClosestRowBefore(ObserverContext <regioncoprocessorenvironment>,byte [],byte [],Result)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除了抽象方法 DeleteTrackerpostInstantiateDeleteTracker(ObserverContext <regioncoprocessorenvironment>,DeleteTracker)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 voidpostSplit(ObserverContext <regioncoprocessorenvironment>,HRegion,HRegion)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 voidpostStartRegionOperation(ObserverContext <regioncoprocessorenvironment>,HRegion.Operation)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 StoreFile.ReaderpostStoreFileReaderOpen(ObserverContext <regioncoprocessorenvironment>,FileSystem,Path,FSDataInputStreamWrapper,long,CacheConfig,Reference,StoreFile.Reader)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 voidpostWALRestore(ObserverContext <regioncoprocessorenvironment>,HRegionInfo,HLogKey,WALEdit)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除了抽象方法 InternalScannerpreFlushScannerOpen(ObserverContext <regioncoprocessorenvironment>,Store,KeyValueScanner,InternalScanner)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此接口中删除抽象方法 voidpreGetClosestRowBefore(ObserverContext <regioncoprocessorenvironment>,byte [],byte [],Result)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 StoreFile.ReaderpreStoreFileReaderOpen(ObserverContext <regioncoprocessorenvironment>,FileSystem,Path,FSDataInputStreamWrapper,long,CacheConfig,Reference,StoreFile.Reader)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 voidpreWALRestore(ObserverContext <regioncoprocessorenvironment>,HRegionInfo,HLogKey,WALEdit)。</regioncoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.4。 WALObserver
HBase 2.0 引入了对 WALObserver 接口的以下更改。
###### [ - ]界面 WALObserver
| Change | Result |
| --- | --- |
| 已从此界面中删除抽象方法 voidpostWALWrite(ObserverContext <walcoprocessorenvironment>,HRegionInfo,HLogKey,WALEdit)。</walcoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 booleanpreWALWrite(ObserverContext <walcoprocessorenvironment>,HRegionInfo,HLogKey,WALEdit)。</walcoprocessorenvironment> | A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.5。杂
HBase 2.0 引入了以下类的更改:
hbase-server-1.0.0.jar,OnlineRegions.class 包 org.apache.hadoop.hbase.regionserver
##### [ - ] OnlineRegions.getFromOnlineRegions(String p1)[abstract]:HRegion
组织/阿帕奇/ hadoop 的/ HBase 的/ RegionServer 的/ OnlineRegions.getFromOnlineRegions:(Ljava /郎/字符串;)Lorg /阿帕奇/ hadoop 的/ HBase 的/ RegionServer 的/ HRegion;
| Change | Result |
| --- | --- |
| 返回值类型已从 Region 更改为 Region。 | 此方法已被删除,因为返回类型是方法签名的一部分。 NoSuchMethodError 异常可能会中断客户端程序。 |
hbase-server-1.0.0.jar,RegionCoprocessorEnvironment.class 包 org.apache.hadoop.hbase.coprocessor
##### [ - ] RegionCoprocessorEnvironment.getRegion()[abstract]:HRegion
组织/阿帕奇/ hadoop 的/ HBase 的/协处理器/ RegionCoprocessorEnvironment.getRegion :()Lorg /阿帕奇/ hadoop 的/ HBase 的/ RegionServer 的/ HRegion;
| Change | Result |
| --- | --- |
| 返回值类型已从 org.apache.hadoop.hbase.regionserver.HRegion 更改为 org.apache.hadoop.hbase.regionserver.Region。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
hbase-server-1.0.0.jar,RegionCoprocessorHost.class 包 org.apache.hadoop.hbase.regionserver
##### [ - ] RegionCoprocessorHost.postAppend(追加追加,结果结果):void
组织/阿帕奇/ hadoop 的/ HBase 的/ RegionServer 的/ RegionCoprocessorHost.postAppend:(Lorg /阿帕奇/ hadoop 的/ HBase 的/客户端/追加; Lorg /阿帕奇/ hadoop 的/ HBase 的/客户/结果;)V
| Change | Result |
| --- | --- |
| 返回值类型已从 void 更改为 org.apache.hadoop.hbase.client.Result。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### [ - ] RegionCoprocessorHost.preStoreFileReaderOpen(FileSystem fs,Path p,FSDataInputStreamWrapper in,long size,CacheConfig cacheConf,Reference r):StoreFile.Reader
组织/阿帕奇/ hadoop 的/ HBase 的/ RegionServer 的/ RegionCoprocessorHost.preStoreFileReaderOpen:(Lorg /阿帕奇/ hadoop 的/ FS /文件系统; Lorg /阿帕奇/ hadoop 的/ FS /路径; Lorg /阿帕奇/ hadoop 的/ HBase 的/ IO / FSDataInputStreamWrapper; JLorg /阿帕奇/ hadoop 的/ HBase 的/ IO / HFILE / CacheConfig; Lorg /阿帕奇/ hadoop 的/ HBase 的/ IO /参考)Lorg /阿帕奇/ hadoop 的/ HBase 的/ RegionServer 的/ StoreFile $阅读器;
| Change | Result |
| --- | --- |
| 返回值类型已从 StoreFile.Reader 更改为 StoreFileReader。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.6。 IPC
#### 203.2.7。调度程序更改:
1. 以下方法变得抽象:
包 org.apache.hadoop.hbase.ipc
##### [ - ] class RpcScheduler(1)
| Change | Result |
| --- | --- |
| 抽象方法 void dispatch(CallRunner)已从此类中删除。 | A client program may be interrupted by NoSuchMethodError exception. |
hbase-server-1.0.0.jar,RpcScheduler.class 包 org.apache.hadoop.hbase.ipc
##### [ - ] RpcScheduler.dispatch(CallRunner p1)[abstract]:void 1
组织/阿帕奇/ hadoop 的/ HBase 的/ IPC / RpcScheduler.dispatch:(Lorg /阿帕奇/ hadoop 的/ HBase 的/ IPC / CallRunner;)V
| Change | Result |
| --- | --- |
| 返回值类型已从 void 更改为 boolean。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
1. 以下摘要方法已被删除:
##### [ - ] interface PriorityFunction(2)
| Change | Result |
| --- | --- |
| 已从此接口中删除了抽象方法 longgetDeadline(RPCProtos.RequestHeader,Message)。 | A client program may be interrupted by NoSuchMethodError exception. |
| 抽象方法 int getPriority(RPCProtos.RequestHeader,Message)已从此接口中删除。 | A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.8。服务器 API 更改:
##### [ - ]类 RpcServer(12)
| Change | Result |
| --- | --- |
| 字段类型 CurCall 已从 java.lang.ThreadLocal <rpcserver.call>更改为 java.lang.ThreadLocal <rpccall>。</rpccall></rpcserver.call> | A client program may be interrupted by NoSuchFieldError exception. |
| 这堂课变得抽象了。 | InstantiationError 异常可能会中断客户端程序。 |
| 抽象方法 int getNumOpenConnections()已添加到此类中。 | 此类变为抽象,客户端程序可能会被 InstantiationError 异常中断。 |
| 已从此类中删除 org.apache.hadoop.hbase.util.Counter 类型的字段 callQueueSize。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除了类型为 java.util.List <rpcserver.connection>的字段 connectionList。</rpcserver.connection> | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除 int 类型的字段 maxIdleTime。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除 int 类型的字段 numConnections。 | A client program may be interrupted by NoSuchFieldError exception. |
| int 类型的字段端口已从此类中删除。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除了 long 类型的字段 purgeTimeout。 | A client program may be interrupted by NoSuchFieldError exception. |
| RpcServer.Responder 类型的字段响应程序已从此类中删除。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除 int 类型的字段 socketSendBufferSize。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除 int 类型的字段 thresholdIdleConnections。 | A client program may be interrupted by NoSuchFieldError exception. |
以下摘要方法已被删除:
| Change | Result |
| --- | --- |
| 抽象方法 Pair <message>调用(BlockingService,Descriptors.MethodDescriptor,Message,CellScanner,long,MonitoredRPCHandler)已从此界面中删除。</message> | A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.9。复制和 WAL 更改:
HBASE-18733:WALKey 已在 HBase 2.0 中完全清除。以下是 WALKey 的更改:
##### [ - ] classWALKey(8)
| Change | Result |
| --- | --- |
| 字段 clusterIds 的访问级别已从 protected 更改为 private。 | IllegalAccessError 异常可能会中断客户端程序。 |
| 字段 compressionContext 的访问级别已从 protected 更改为 private。 | A client program may be interrupted by IllegalAccessError exception. |
| 字段 encodedRegionName 的访问级别已从 protected 更改为 private。 | A client program may be interrupted by IllegalAccessError exception. |
| 字段表名的访问级别已从 protected 更改为 private。 | A client program may be interrupted by IllegalAccessError exception. |
| 字段 writeTime 的访问级别已从 protected 更改为 private。 | A client program may be interrupted by IllegalAccessError exception. |
以下字段已被删除:
| Change | Result |
| --- | --- |
| 已从此类中删除 org.apache.commons.logging.Log 类型的字段日志。 | A client program may be interrupted by NoSuchFieldError exception. |
| WALKey.Version 类型的字段 VERSION 已从此类中删除。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除了 long 类型的字段 logSeqNum。 | A client program may be interrupted by NoSuchFieldError exception. |
以下是对 WALEdit.class 的更改:hbase-server-1.0.0.jar,WALEdit.class 包 org.apache.hadoop.hbase.regionserver.wal
##### WALEdit.getCompaction(Cell kv)[静态]:WALProtos.CompactionDescriptor(1)
组织/阿帕奇/ hadoop 的/ HBase 的/ RegionServer 的/沃尔玛/ WALEdit.getCompaction:(Lorg /阿帕奇/ hadoop 的/ HBase 的/细胞)Lorg /阿帕奇/ hadoop 的/ HBase 的/ protobuf 的/生成/ WALProtos $ CompactionDescriptor;
| Change | Result |
| --- | --- |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generated.WALProtos.CompactionDescriptor 更改为 org.apache.hadoop.hbase.shaded.protobuf.generated.WALProtos.CompactionDescriptor。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### WALEdit.getFlushDescriptor(Cell cell)[静态]:WALProtos.FlushDescriptor(1)
组织/阿帕奇/ hadoop 的/ HBase 的/ RegionServer 的/沃尔玛/ WALEdit.getFlushDescriptor:(Lorg /阿帕奇/ hadoop 的/ HBase 的/细胞)Lorg /阿帕奇/ hadoop 的/ HBase 的/ protobuf 的/生成/ WALProtos $ FlushDescriptor;
| Change | Result |
| --- | --- |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generated.WALProtos.FlushDescriptor 更改为 org.apache.hadoop.hbase.shaded.protobuf.generated.WALProtos.FlushDescriptor。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### WALEdit.getRegionEventDescriptor(Cell cell)[静态]:WALProtos.RegionEventDescriptor(1)
组织/阿帕奇/ hadoop 的/ HBase 的/ RegionServer 的/沃尔玛/ WALEdit.getRegionEventDescriptor:(Lorg /阿帕奇/ hadoop 的/ HBase 的/细胞)Lorg /阿帕奇/ hadoop 的/ HBase 的/ protobuf 的/生成/ WALProtos $ RegionEventDescriptor;
| Change | Result |
| --- | --- |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generated.WALProtos.RegionEventDescriptor 更改为 org.apache.hadoop.hbase.shaded.protobuf.generated.WALProtos.RegionEventDescriptor。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
以下是对 WALKey.class:package org.apache.hadoop.hbase.wal 的更改
##### WALKey.getBuilder(WALCellCodec.ByteStringCompressor 压缩器):WALProtos.WALKey.Builder 1
组织/阿帕奇/ hadoop 的/ HBase 的/沃尔玛/ WALKey.getBuilder:(Lorg /阿帕奇/ hadoop 的/ HBase 的/ RegionServer 的/沃尔/ WALCellCodec $ ByteStringCompressor)Lorg /阿帕奇/ hadoop 的/ HBase 的/ protobuf 的/生成/ WALProtos $ $ WALKey 助洗剂;
| Change | Result |
| --- | --- |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generated.WALProtos.WALKey.Builder 更改为 org.apache.hadoop.hbase.shaded.protobuf.generated.WALProtos.WALKey.Builder。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.10。不推荐使用的 API 或协处理器:
HBASE-16769 - 已删除 MasterObserver 和 RegionServerObserver 中的 PB 引用。
#### 203.2.11。管理界面 API 更改:
您无法管理 HBase 2.0 群集与 HBase 1.0 客户端,其中包括 Admin ops 的 RelicationAdmin,ACC,Thrift 和 REST 使用。返回 protobufs 的方法已更改为返回 POJO。 pb 不再用于 API 中。异步方法的返回值已从 void 更改为 Future。 HBASE-18106 - Admin.listProcedures 和 Admin.listLocks 重命名为 getProcedures 和 getLocks。 MapReduce 使用 Admin 执行以下 admin.getClusterStatus()来计算 Splits。
* 管理 API 的节约使用:compact(ByteBuffer)createTable(ByteBuffer,List <columndescriptor>)deleteTable(ByteBuffer)disableTable(ByteBuffer)enableTable(ByteBuffer)getTableNames()majorCompact(ByteBuffer)</columndescriptor>
* Admin API 的 REST 用法:hbase-rest org.apache.hadoop.hbase.rest RootResource getTableList()TableName [] tableNames = servlet.getAdmin()。listTableNames(); SchemaResource delete(UriInfo)Admin admin = servlet.getAdmin(); update(TableSchemaModel,boolean,UriInfo)Admin admin = servlet.getAdmin(); StorageClusterStatusResource get(UriInfo)ClusterStatus status = servlet.getAdmin()。getClusterStatus(); StorageClusterVersionResource get(UriInfo)model.setVersion(servlet.getAdmin()。getClusterStatus()。getHBaseVersion()); TableResource exists()返回 servlet.getAdmin()。tableExists(TableName.valueOf(table));
以下是对 Admin 界面的更改:
##### [ - ]界面管理员(9)
| Change | Result |
| --- | --- |
| 已从此接口中删除抽象方法 createTableAsync(HTableDescriptor,byte [] [])。 | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此接口中删除抽象方法 disableTableAsync(TableName)。 | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此接口中删除抽象方法 enableTableAsync(TableName)。 | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此接口中删除抽象方法 getCompactionState(TableName)。 | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此接口中删除抽象方法 getCompactionStateForRegion(byte [])。 | A client program may be interrupted by NoSuchMethodError exception. |
| 抽象方法 isSnapshotFinished(HBaseProtos.SnapshotDescription)已从此界面中删除。 | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 snapshot(String,TableName,HBaseProtos.SnapshotDescription.Type)。 | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法快照(HBaseProtos.SnapshotDescription)。 | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此接口中删除抽象方法 takeSnapshotAsync(HBaseProtos.SnapshotDescription)。 | A client program may be interrupted by NoSuchMethodError exception. |
以下是对 Admin.class 的更改:hbase-client-1.0.0.jar,Admin.class 包 org.apache.hadoop.hbase.client
##### [ - ] Admin.createTableAsync(HTableDescriptor p1,byte [] [] p2)[abstract]:void 1
组织/阿帕奇/ hadoop 的/ HBase 的/客户端/ Admin.createTableAsync:(Lorg /阿帕奇/ hadoop 的/ HBase 的/ HTableDescriptor; [[B)V
| Change | Result |
| --- | --- |
| 返回值类型已从 void 更改为 java.util.concurrent.Future <java.lang.void>。</java.lang.void> | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### [ - ] Admin.disableTableAsync(TableName p1)[abstract]:void 1
组织/阿帕奇/ hadoop 的/ HBase 的/客户端/ Admin.disableTableAsync:(Lorg /阿帕奇/ hadoop 的/ HBase 的/表名;)V
| Change | Result |
| --- | --- |
| Return value type has been changed from void to java.util.concurrent.Future<java.lang.void>.</java.lang.void> | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### Admin.enableTableAsync(TableName p1)[abstract]:void 1
组织/阿帕奇/ hadoop 的/ HBase 的/客户端/ Admin.enableTableAsync:(Lorg /阿帕奇/ hadoop 的/ HBase 的/表名;)V
| Change | Result |
| --- | --- |
| Return value type has been changed from void to java.util.concurrent.Future<java.lang.void>.</java.lang.void> | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### [ - ] Admin.getCompactionState(TableName p1)[abstract]:AdminProtos.GetRegionInfoResponse.CompactionState 1
组织/阿帕奇/ hadoop 的/ HBase 的/客户端/ Admin.getCompactionState:(Lorg /阿帕奇/ hadoop 的/ HBase 的/表名)Lorg /阿帕奇/ hadoop 的/ HBase 的/ protobuf 的/生成/ AdminProtos $ $ GetRegionInfoResponse CompactionState;
| Change | Result |
| --- | --- |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generated.AdminProtos.GetRegionInfoResponse.CompactionState 更改为 CompactionState。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### [ - ] Admin.getCompactionStateForRegion(byte [] p1)[abstract]:AdminProtos.GetRegionInfoResponse.CompactionState 1
组织/阿帕奇/ hadoop 的/ HBase 的/客户端/ Admin.getCompactionStateForRegion:([B)Lorg /阿帕奇/ hadoop 的/ HBase 的/ protobuf 的/生成/ AdminProtos $ $ GetRegionInfoResponse CompactionState;
| Change | Result |
| --- | --- |
| Return value type has been changed from org.apache.hadoop.hbase.protobuf.generated.AdminProtos.GetRegionInfoResponse.CompactionState to CompactionState. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.12。 HTableDescriptor 和 HColumnDescriptor 发生了变化
HTableDescriptor 和 HColumnDescriptor 已成为接口,您可以通过 Builders 创建它。 HCD 已成为 CFD。它不再实现可写接口。包 org.apache.hadoop.hbase
##### [ - ]类 HColumnDescriptor(1)
| Change | Result |
| --- | --- |
| 删除了超级接口 org.apache.hadoop.io.WritableComparable <hcolumndescriptor>。</hcolumndescriptor> | A client program may be interrupted by NoSuchMethodError exception. |
HColumnDescriptor in 1.0.0 {code} @ InterfaceAudience.Public @ InterfaceStability.Evolving public class HColumnDescriptor 实现 WritableComparable <hcolumndescriptor>{{code}</hcolumndescriptor>
HColumnDescriptor in 2.0 {code} @ InterfaceAudience.Public @Deprecated //在 3.0 公共类中删除它 HColumnDescriptor 实现 ColumnFamilyDescriptor,Comparable <hcolumndescriptor>{{code}</hcolumndescriptor>
对于 META_TABLEDESC,制造商方法已在 1.0.0 中的 HTD 中弃用。 OWNER_KEY 仍处于 HTD 状态。
##### 类 HTableDescriptor(3)
| Change | Result |
| --- | --- |
| 删除了超级接口 org.apache.hadoop.io.WritableComparable <htabledescriptor>。</htabledescriptor> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此类中删除了类型为 HTableDescriptor 的字段 META_TABLEDESC。 | A client program may be interrupted by NoSuchFieldError exception. |
hbase-client-1.0.0.jar,HTableDescriptor.class 包 org.apache.hadoop.hbase
##### [ - ] HTableDescriptor.getColumnFamilies():HColumnDescriptor [](1)
组织/阿帕奇/ hadoop 的/ HBase 的/ HTableDescriptor.getColumnFamilies:()[Lorg /阿帕奇/ hadoop 的/ HBase 的/ HColumnDescriptor;
##### [−] class HColumnDescriptor (1)
| Change | Result |
| --- | --- |
| 返回值类型已从 HColumnDescriptor []更改为 client.ColumnFamilyDescriptor []。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### [ - ] HTableDescriptor.getCoprocessors():List <string>(1)</string>
组织/阿帕奇/ hadoop 的/ HBase 的/ HTableDescriptor.getCoprocessors :()Ljava / util 的/列表;
| Change | Result |
| --- | --- |
| 返回值类型已从 java.util.List <java.lang.string>更改为 java.util.Collection。</java.lang.string> | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
* HBASE-12990 删除了 MetaScanner,它被 MetaTableAccessor 取代。
##### HTableWrapper 更改:
hbase-server-1.0.0.jar,HTableWrapper.class 包 org.apache.hadoop.hbase.client
##### [ - ] HTableWrapper.createWrapper(List <htableinterface>openTables,TableName tableName,CoprocessorHost.Environment env,ExecutorService pool)[静态]:HTableInterface 1</htableinterface>
组织/阿帕奇/的 Hadoop / HBase 的/客户/ HTableWrapper.createWrapper:(Ljava / UTIL /列表; Lorg /阿帕奇/的 Hadoop / HBase 的/表名; Lorg /阿帕奇/的 Hadoop / HBase 的/协/ CoprocessorHost $环境; Ljava / UTIL /并发/ ExecutorService 的;)Lorg /阿帕奇/ hadoop 的/ HBase 的/客户/ HTableInterface;
| Change | Result |
| --- | --- |
| 返回值类型已从 HTableInterface 更改为 Table。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
* HBASE-12586:删除所有公共 HTable 构造函数并删除 ConnectionManager#{delete,get} Connection。
* HBASE-9117:删除 HTablePool 和所有与 HConnection 池相关的 API。
* HBASE-13214:从 HTable 类中删除不推荐使用和未使用的方法以下是对 Table 接口的更改:
##### [ - ]界面表(4)
| Change | Result |
| --- | --- |
| 已从此界面中删除抽象方法批处理(List&lt;?&gt;)。 | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此界面中删除抽象方法 batchCallback(List&lt;?&gt;,Batch.Callback <r>)。</r> | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此接口中删除抽象方法 getWriteBufferSize()。 | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此接口中删除抽象方法 setWriteBufferSize(long)。 | A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.13。表(在 1.0.1 中)中不推荐使用缓冲区方法,在 2.0.0 中删除
* HBASE-13298-澄清表。{set | get} WriteBufferSize()是否已弃用。
* LockTimeoutException 和 OperationConflictException 类已被删除。
#### 203.2.14。 class OperationConflictException(1)
| Change | Result |
| --- | --- |
| 此课程已被删除。 | NoClassDefFoundErrorexception 可能会中断客户端程序。 |
#### 203.2.15。 class class LockTimeoutException(1)
| Change | Result |
| --- | --- |
| This class has been removed. | A client program may be interrupted by NoClassDefFoundErrorexception. |
#### 203.2.16。过滤 API 更改:
已删除以下方法:package org.apache.hadoop.hbase.filter
##### [ - ]类过滤器(2)
| Change | Result |
| --- | --- |
| 已从此类中删除抽象方法 getNextKeyHint(KeyValue)。 | A client program may be interrupted by NoSuchMethodError exception. |
| 已从此类中删除抽象方法 transform(KeyValue)。 | A client program may be interrupted by NoSuchMethodError exception. |
* HBASE-12296 过滤器应该与 ByteBufferedCell 一起使用。
* HBase 2.0 中删除了 HConnection。
* RegionLoad 和 ServerLoad 在内部移动到着色的 PB。
##### [ - ] class RegionLoad(1)
| Change | Result |
| --- | --- |
| 字段 regionLoadPB 的类型已从 protobuf.generated.ClusterStatusProtos.RegionLoad 更改为 shaded.protobuf.generated.ClusterStatusProtos.RegionLoad。 | A client program may be interrupted by NoSuchFieldError exception. |
* HBASE-15783:AccessControlConstants#OP_ATTRIBUTE_ACL_STRATEGY_CELL_FIRST 不再使用。包 org.apache.hadoop.hbase.security.access
##### [ - ]接口 AccessControlConstants(3)
| Change | Result |
| --- | --- |
| 已从此接口中删除了类型为 java.lang.String 的字段 OP_ATTRIBUTE_ACL_STRATEGY。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此接口中删除 byte []类型的字段 OP_ATTRIBUTE_ACL_STRATEGY_CELL_FIRST。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此接口中删除 byte []类型的字段 OP_ATTRIBUTE_ACL_STRATEGY_DEFAULT。 | A client program may be interrupted by NoSuchFieldError exception. |
##### ServerLoad 返回 long 而不是 int 1
hbase-client-1.0.0.jar,ServerLoad.class 包 org.apache.hadoop.hbase
##### [ - ] ServerLoad.getNumberOfRequests():int 1
组织/阿帕奇/的 Hadoop / HBase 的/ ServerLoad.getNumberOfRequests :()我
| Change | Result |
| --- | --- |
| 返回值类型已从 int 更改为 long。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### [ - ] ServerLoad.getReadRequestsCount():int 1
组织/阿帕奇/的 Hadoop / HBase 的/ ServerLoad.getReadRequestsCount :()我
| Change | Result |
| --- | --- |
| Return value type has been changed from int to long. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### [ - ] ServerLoad.getTotalNumberOfRequests():int 1
组织/阿帕奇/的 Hadoop / HBase 的/ ServerLoad.getTotalNumberOfRequests :()我
| Change | Result |
| --- | --- |
| Return value type has been changed from int to long. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
##### [ - ] ServerLoad.getWriteRequestsCount():int 1
组织/阿帕奇/的 Hadoop / HBase 的/ ServerLoad.getWriteRequestsCount :()我
| Change | Result |
| --- | --- |
| Return value type has been changed from int to long. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
* HBASE-13636 删除 HBASE-4072 的弃用(阅读 zoo.cfg)
* HConstants 被删除。 HBASE-16040 删除配置“hbase.replication”
##### [ - ]班级 HConstants(6)
| Change | Result |
| --- | --- |
| 已从此类中删除类型为 boolean 的字段 DEFAULT_HBASE_CONFIG_READ_ZOOKEEPER_CONFIG。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除了类型为 java.lang.String 的字段 HBASE_CONFIG_READ_ZOOKEEPER_CONFIG。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除类型为 boolean 的字段 REPLICATION_ENABLE_DEFAULT。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除 java.lang.String 类型的字段 REPLICATION_ENABLE_KEY。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除了类型为 java.lang.String 的字段 ZOOKEEPER_CONFIG_NAME。 | A client program may be interrupted by NoSuchFieldError exception. |
| 已从此类中删除了类型为 java.lang.String 的字段 ZOOKEEPER_USEMULTI。 | A client program may be interrupted by NoSuchFieldError exception. |
* HBASE-18732:[compat 1-2] HBASE-14047 删除了 Cell 方法而没有弃用周期。
##### [ - ]界面单元格 5
| Change | Result |
| --- | --- |
| 抽象方法 getFamily()已从此接口中删除。 | A client program may be interrupted by NoSuchMethodError exception. |
| 抽象方法 getMvccVersion()已从此接口中删除。 | A client program may be interrupted by NoSuchMethodError exception. |
| 抽象方法 getQualifier()已从此接口中删除。 | A client program may be interrupted by NoSuchMethodError exception. |
| 抽象方法 getRow()已从此接口中删除。 | A client program may be interrupted by NoSuchMethodError exception. |
| 抽象方法 getValue()已从此接口中删除。 | A client program may be interrupted by NoSuchMethodError exception. |
* HBASE-18795:仅为测试公开 KeyValue.getBuffer()。仅在以前不推荐使用的测试中允许 KV#getBuffer。
#### 203.2.17。区域扫描仪更改:
##### [ - ]界面 RegionScanner(1)
| Change | Result |
| --- | --- |
| 已从此接口中删除抽象方法 boolean nextRaw(List <cell>,int)。</cell> | A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.18。 StoreFile 更改:
##### [ - ]类 StoreFile(1)
| Change | Result |
| --- | --- |
| 这个类成了界面。 | 客户端程序可能会因 IncompatibleClassChangeError 或 InstantiationError 异常而中断,具体取决于此类的用法。 |
#### 203.2.19。 Mapreduce 更改:
HFile *格式已在 HBase 2.0 中删除。
#### 203.2.20。 ClusterStatus 更改:
HBASE-15843:用 Set hbase-client-1.0.0.jar,ClusterStatus.class 包 org.apache.hadoop.hbase 替换 RegionState.getRegionInTransition()Map
##### [ - ] ClusterStatus.getRegionsInTransition():Map <string>1</string>
组织/阿帕奇/ hadoop 的/ HBase 的/ ClusterStatus.getRegionsInTransition :()Ljava / util 的/地图;
| Change | Result |
| --- | --- |
| 返回值类型已从 java.util.Map <java.lang.string>更改为 java.util.List <master.regionstate>。</master.regionstate></java.lang.string> | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
ClusterStatus 中的其他更改包括删除从 API 中清除 PB 后不再需要的转换方法。
#### 203.2.21。从 API 中清除 PB
PBase 已在 HBase 2.0 中的 API 中弃用。
##### [ - ] HBaseSnapshotException.getSnapshotDescription():HBaseProtos.SnapshotDescription 1
组织/阿帕奇/ hadoop 的/ HBase 的/快照/ HBaseSnapshotException.getSnapshotDescription :()Lorg /阿帕奇/ hadoop 的/ HBase 的/ protobuf 的/生成/ HBaseProtos $ SnapshotDescription;
| Change | Result |
| --- | --- |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.SnapshotDescription 更改为 org.apache.hadoop.hbase.client.SnapshotDescription。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
* HBASE-15609:从 Result,DoubleColumnInterpreter 和 2.0 的任何此类面向公共的类中删除 PB 引用。 hbase-client-1.0.0.jar,Result.class 包 org.apache.hadoop.hbase.client
##### [ - ] Result.getStats():ClientProtos.RegionLoadStats 1
组织/阿帕奇/ hadoop 的/ HBase 的/客户端/ Result.getStats :()Lorg /阿帕奇/ hadoop 的/ HBase 的/ protobuf 的/生成/ ClientProtos $ RegionLoadStats;
| Change | Result |
| --- | --- |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generated.ClientProtos.RegionLoadStats 更改为 RegionLoadStats。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.22。 REST 更改:
hbase-rest-1.0.0.jar,Client.class 包 org.apache.hadoop.hbase.rest.client
##### [ - ] Client.getHttpClient():HttpClient 1
组织/阿帕奇/的 Hadoop / HBase 的/ REST /客户/ Client.getHttpClient :()Lorg /阿帕奇/公/ HttpClient 的/ HttpClient 的
| Change | Result |
| --- | --- |
| 返回值类型已从 org.apache.commons.httpclient.HttpClient 更改为 org.apache.http.client.HttpClient。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
hbase-rest-1.0.0.jar,Response.class 包 org.apache.hadoop.hbase.rest.client
##### [ - ] Response.getHeaders():标题[] 1
组织/阿帕奇/ hadoop 的/ HBase 的/休息/客户端/ Response.getHeaders:()[Lorg /阿帕奇/公地/ HttpClient 的/报头;
| Change | Result |
| --- | --- |
| 返回值类型已从 org.apache.commons.httpclient.Header []更改为 org.apache.http.Header []。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.23。 PrettyPrinter 更改:
hbase-server-1.0.0.jar,HFilePrettyPrinter.class 包 org.apache.hadoop.hbase.io.hfile
##### [ - ] HFilePrettyPrinter.processFile(Path file):void 1
组织/阿帕奇/ hadoop 的/ HBase 的/ IO / HFILE / HFilePrettyPrinter.processFile:(Lorg /阿帕奇/ hadoop 的/ FS /路径;)V
| Change | Result |
| --- | --- |
| 返回值类型已从 void 更改为 int。 | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
#### 203.2.24。 AccessControlClient 更改:
HBASE-13171 更改 AccessControlClient 方法以接受连接对象以减少设置时间。参数已在以下方法中更改:
* hbase-client-1.2.7-SNAPSHOT.jar,AccessControlClient.class 包 org.apache.hadoop.hbase.security.access AccessControlClient.getUserPermissions(Configuration conf,String tableRegex)[静态]:列表 <userpermission>**DEPRECATED** org / apache / hadoop / hbase / security / access / AccessControlClient.getUserPermissions:(Lorg / apache / hadoop / conf / Configuration; Ljava / lang / String;)Ljava / util / List;</userpermission>
* AccessControlClient.grant(Configuration conf,String namespace,String userName,Permission.Action ... actions)[静态]:void **DEPRECATED** org / apache / hadoop / hbase / security / access / AccessControlClient.grant:(Lorg /阿帕奇/ Hadoop 的/ conf 目录/配置; Ljava /朗/字符串; Ljava /朗/字符串; Lorg /阿帕奇/的 Hadoop / HBase 的/安全/访问/权限$行动;)V
* AccessControlClient.grant(Configuration conf,String userName,Permission.Action ... actions)[静态]:void **DEPRECATED** org / apache / hadoop / hbase / security / access / AccessControlClient.grant:(Lorg / apache / Hadoop 的/ conf 目录/配置; Ljava /朗/字符串; Lorg /阿帕奇/的 Hadoop / HBase 的/安全/访问/权限$行动;)V
* AccessControlClient.grant(Configuration conf,TableName tableName,String userName,byte [] family,byte [] qual,Permission.Action ... actions)[静态]:void **DEPRECATED** org / apache / hadoop / hbase /安全/访问/ AccessControlClient.grant:(Lorg /阿帕奇/ hadoop 的/ CONF /配置; Lorg /阿帕奇/ hadoop 的/ HBase 的/表名; Ljava /郎/字符串; [B [B [Lorg /阿帕奇/ hadoop 的/ HBase 的/安全/访问/权限$行动;)V
* AccessControlClient.isAccessControllerRunning(Configuration conf)[静态]:boolean **DEPRECATED** org / apache / hadoop / hbase / security / access / AccessControlClient.isAccessControllerRunning:(Lorg / apache / hadoop / conf / Configuration;)Z
* AccessControlClient.revoke(Configuration conf,String namespace,String userName,Permission.Action ... actions)[静态]:void **DEPRECATED** org / apache / hadoop / hbase / security / access / AccessControlClient.revoke:(Lorg /阿帕奇/ Hadoop 的/ conf 目录/配置; Ljava /朗/字符串; Ljava /朗/字符串; Lorg /阿帕奇/的 Hadoop / HBase 的/安全/访问/权限$行动;)V
* AccessControlClient.revoke(Configuration conf,String userName,Permission.Action ... actions)[静态]:void **DEPRECATED** org / apache / hadoop / hbase / security / access / AccessControlClient.revoke:(Lorg / apache / Hadoop 的/ conf 目录/配置; Ljava /朗/字符串; Lorg /阿帕奇/的 Hadoop / HBase 的/安全/访问/权限$行动;)V
* AccessControlClient.revoke(Configuration conf,TableName tableName,String username,byte [] family,byte []限定符,Permission.Action ... actions)[静态]:void **DEPRECATED** org / apache / hadoop / hbase /安全/访问/ AccessControlClient.revoke:(Lorg /阿帕奇/ hadoop 的/ CONF /配置; Lorg /阿帕奇/ hadoop 的/ HBase 的/表名; Ljava /郎/字符串; [B [B [Lorg /阿帕奇/ hadoop 的/ HBase 的/安全/访问/权限$行动;)V
* HBASE-18731:[compat 1-2]标记受保护的 QuotaSettings 方法,它们将 Protobuf 内部接触为 IA.Private
</cellblock></protobuf></protobuf></total></cellblock></protobuf></protobuf></total></protobuf></preamble>
- HBase™ 中文参考指南 3.0
- Preface
- Getting Started
- Apache HBase Configuration
- Upgrading
- The Apache HBase Shell
- Data Model
- HBase and Schema Design
- RegionServer Sizing Rules of Thumb
- HBase and MapReduce
- Securing Apache HBase
- Architecture
- In-memory Compaction
- Backup and Restore
- Synchronous Replication
- Apache HBase APIs
- Apache HBase External APIs
- Thrift API and Filter Language
- HBase and Spark
- Apache HBase Coprocessors
- Apache HBase Performance Tuning
- Troubleshooting and Debugging Apache HBase
- Apache HBase Case Studies
- Apache HBase Operational Management
- Building and Developing Apache HBase
- Unit Testing HBase Applications
- Protobuf in HBase
- Procedure Framework (Pv2): HBASE-12439
- AMv2 Description for Devs
- ZooKeeper
- Community
- Appendix