# 2\. 获得文本语料和词汇资源
在自然语言处理的实际项目中,通常要使用大量的语言数据或者语料库。本章的目的是要回答下列问题:
1. 什么是有用的文本语料和词汇资源,我们如何使用 Python 获取它们?
2. 哪些 Python 结构最适合这项工作?
3. 编写 Python 代码时我们如何避免重复的工作?
本章继续通过语言处理任务的例子展示编程概念。在系统的探索每一个 Python 结构之前请耐心等待。如果你看到一个例子中含有一些不熟悉的东西,请不要担心。只需去尝试它,看看它做些什么——如果你很勇敢——通过使用不同的文本或词替换代码的某些部分来进行修改。这样,你会将任务与编程习惯用法关联起来,并在后续的学习中了解怎么会这样和为什么是这样。
## 1 获取文本语料库
正如刚才提到的,一个文本语料库是一大段文本。许多语料库的设计都要考虑一个或多个文体间谨慎的平衡。我们曾在第[1.](./ch01.html#chap-introduction)章研究过一些小的文本集合,例如美国总统就职演说。这种特殊的语料库实际上包含了几十个单独的文本——每个人一个演讲——但为了处理方便,我们把它们头尾连接起来当做一个文本对待。第[1.](./ch01.html#chap-introduction)章中也使用变量预先定义好了一些文本,我们通过输入`from nltk.book import *`来访问它们。然而,因为我们希望能够处理其他文本,本节中将探讨各种文本语料库。我们将看到如何选择单个文本,以及如何处理它们。
## 1.1 古腾堡语料库
NLTK 包含古腾堡项目(Project Gutenberg)电子文本档案的经过挑选的一小部分文本,该项目大约有 25,000 本免费电子图书,放在`http://www.gutenberg.org/`上。我们先要用 Python 解释器加载 NLTK 包,然后尝试`nltk.corpus.gutenberg.fileids()`,下面是这个语料库中的文件标识符:
```py
>>> import nltk
>>> nltk.corpus.gutenberg.fileids()
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-kjv.txt',
'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt',
'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt',
'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt',
'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt',
'shakespeare-macbeth.txt', 'whitman-leaves.txt']
```
让我们挑选这些文本的第一个——简·奥斯丁的 _《爱玛》_——并给它一个简短的名称`emma`,然后找出它包含多少个词:
```py
>>> emma = nltk.corpus.gutenberg.words('austen-emma.txt')
>>> len(emma)
192427
```
注意
在第[1](./ch01.html#sec-computing-with-language-texts-and-words)章中,我们演示了如何使用`text1.concordance()`命令对`text1`这样的文本进行索引。然而,这是假设你正在使用由`from nltk.book import *`导入的 9 个文本之一。现在你开始研究`nltk.corpus`中的数据,像前面的例子一样,你必须采用以下语句对来处理索引和第[1](./ch01.html#sec-computing-with-language-texts-and-words)章中的其它任务:
```py
>>> emma = nltk.Text(nltk.corpus.gutenberg.words('austen-emma.txt'))
>>> emma.concordance("surprize")
```
在我们定义`emma`, 时,我们调用了 NLTK 中的`corpus`包中的`gutenberg`对象的`words()`函数。但因为总是要输入这么长的名字很繁琐,Python 提供了另一个版本的`import`语句,示例如下:
```py
>>> from nltk.corpus import gutenberg
>>> gutenberg.fileids()
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', ...]
>>> emma = gutenberg.words('austen-emma.txt')
```
让我们写一个简短的程序,通过循环遍历前面列出的`gutenberg`文件标识符列表相应的`fileid`,然后计算统计每个文本。为了使输出看起来紧凑,我们将使用`round()`舍入每个数字到最近似的整数。
```py
>>> for fileid in gutenberg.fileids():
... num_chars = len(gutenberg.raw(fileid)) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... num_words = len(gutenberg.words(fileid))
... num_sents = len(gutenberg.sents(fileid))
... num_vocab = len(set(w.lower() for w in gutenberg.words(fileid)))
... print(round(num_chars/num_words), round(num_words/num_sents), round(num_words/num_vocab), fileid)
...
5 25 26 austen-emma.txt
5 26 17 austen-persuasion.txt
5 28 22 austen-sense.txt
4 34 79 bible-kjv.txt
5 19 5 blake-poems.txt
4 19 14 bryant-stories.txt
4 18 12 burgess-busterbrown.txt
4 20 13 carroll-alice.txt
5 20 12 chesterton-ball.txt
5 23 11 chesterton-brown.txt
5 18 11 chesterton-thursday.txt
4 21 25 edgeworth-parents.txt
5 26 15 melville-moby_dick.txt
5 52 11 milton-paradise.txt
4 12 9 shakespeare-caesar.txt
4 12 8 shakespeare-hamlet.txt
4 12 7 shakespeare-macbeth.txt
5 36 12 whitman-leaves.txt
```
这个程序显示每个文本的三个统计量:平均词长、平均句子长度和本文中每个词出现的平均次数(我们的词汇多样性得分)。请看,平均词长似乎是英语的一个一般属性,因为它的值总是`4`。(事实上,平均词长是`3`而不是`4`,因为`num_chars`变量计数了空白字符。)相比之下,平均句子长度和词汇多样性看上去是作者个人的特点。
前面的例子也表明我们怎样才能获取“原始”文本[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#raw-access)而不用把它分割成词符。`raw()`函数给我们没有进行过任何语言学处理的文件的内容。因此,例如`len(gutenberg.raw('blake-poems.txt'))`告诉我们文本中出现的 _ 字符 _ 个数,包括词之间的空格。`sents()`函数把文本划分成句子,其中每一个句子是一个单词列表:
```py
>>> macbeth_sentences = gutenberg.sents('shakespeare-macbeth.txt')
>>> macbeth_sentences
[['[', 'The', 'Tragedie', 'of', 'Macbeth', 'by', 'William', 'Shakespeare',
'1603', ']'], ['Actus', 'Primus', '.'], ...]
>>> macbeth_sentences[1116]
['Double', ',', 'double', ',', 'toile', 'and', 'trouble', ';',
'Fire', 'burne', ',', 'and', 'Cauldron', 'bubble']
>>> longest_len = max(len(s) for s in macbeth_sentences)
>>> [s for s in macbeth_sentences if len(s) == longest_len]
[['Doubtfull', 'it', 'stood', ',', 'As', 'two', 'spent', 'Swimmers', ',', 'that',
'doe', 'cling', 'together', ',', 'And', 'choake', 'their', 'Art', ':', 'The',
'mercilesse', 'Macdonwald', ...]]
```
注意
除了`words()`, `raw()`和`sents()`之外,大多数 NLTK 语料库阅读器还包括多种访问方法。一些语料库提供更加丰富的语言学内容,例如:词性标注,对话标记,语法树等;在后面的章节中,我们将看到这些。
## 1.2 网络和聊天文本
虽然古腾堡项目包含成千上万的书籍,它代表既定的文学。考虑较不正式的语言也是很重要的。NLTK 的网络文本小集合的内容包括 Firefox 交流论坛,在纽约无意听到的对话, _ 加勒比海盗 _ 的电影剧本,个人广告和葡萄酒的评论:
```py
>>> from nltk.corpus import webtext
>>> for fileid in webtext.fileids():
... print(fileid, webtext.raw(fileid)[:65], '...')
...
firefox.txt Cookie Manager: "Don't allow sites that set removed cookies to se...
grail.txt SCENE 1: [wind] [clop clop clop] KING ARTHUR: Whoa there! [clop...
overheard.txt White guy: So, do you have any plans for this evening? Asian girl...
pirates.txt PIRATES OF THE CARRIBEAN: DEAD MAN'S CHEST, by Ted Elliott & Terr...
singles.txt 25 SEXY MALE, seeks attrac older single lady, for discreet encoun...
wine.txt Lovely delicate, fragrant Rhone wine. Polished leather and strawb...
```
还有一个即时消息聊天会话语料库,最初由美国海军研究生院为研究自动检测互联网幼童虐待癖而收集的。语料库包含超过 10,000 张帖子,以“UserNNN”形式的通用名替换掉用户名,手工编辑消除任何其他身份信息,制作而成。语料库被分成 15 个文件,每个文件包含几百个按特定日期和特定年龄的聊天室(青少年、20 岁、30 岁、40 岁、再加上一个通用的成年人聊天室)收集的帖子。文件名中包含日期、聊天室和帖子数量,例如`10-19-20s_706posts.xml`包含 2006 年 10 月 19 日从 20 多岁聊天室收集的 706 个帖子。
```py
>>> from nltk.corpus import nps_chat
>>> chatroom = nps_chat.posts('10-19-20s_706posts.xml')
>>> chatroom[123]
['i', 'do', "n't", 'want', 'hot', 'pics', 'of', 'a', 'female', ',',
'I', 'can', 'look', 'in', 'a', 'mirror', '.']
```
## 1.3 布朗语料库
布朗语料库是第一个百万词级的英语电子语料库的,由布朗大学于 1961 年创建。这个语料库包含 500 个不同来源的文本,按照文体分类,如:_ 新闻 _、_ 社论 _ 等。表[1.1](./ch02.html#tab-brown-sources)给出了各个文体的例子(完整列表,请参阅`http://icame.uib.no/brown/bcm-los.html`)。
表 1.1:
布朗语料库每一部分的示例文档
```py
>>> from nltk.corpus import brown
>>> brown.categories()
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies',
'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance',
'science_fiction']
>>> brown.words(categories='news')
['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...]
>>> brown.words(fileids=['cg22'])
['Does', 'our', 'society', 'have', 'a', 'runaway', ',', ...]
>>> brown.sents(categories=['news', 'editorial', 'reviews'])
[['The', 'Fulton', 'County'...], ['The', 'jury', 'further'...], ...]
```
布朗语料库是一个研究文体之间的系统性差异——一种叫做文体学的语言学研究——很方便的资源。让我们来比较不同文体中的情态动词的用法。第一步是产生特定文体的计数。记住做下面的实验之前要`import nltk`:
```py
>>> from nltk.corpus import brown
>>> news_text = brown.words(categories='news')
>>> fdist = nltk.FreqDist(w.lower() for w in news_text)
>>> modals = ['can', 'could', 'may', 'might', 'must', 'will']
>>> for m in modals:
... print(m + ':', fdist[m], end=' ')
...
can: 94 could: 87 may: 93 might: 38 must: 53 will: 389
```
注意
我们需要包包含`结束 = ' '` 以让 print 函数将其输出放在单独的一行。
注意
**轮到你来:** 选择布朗语料库的不同部分,修改前面的例子,计数包含 wh 的词,如:what, when, where, who 和 why。
下面,我们来统计每一个感兴趣的文体。我们使用 NLTK 提供的带条件的频率分布函数。在第[2](./ch02.html#sec-conditional-frequency-distributions)节中会系统的把下面的代码一行行拆开来讲解。现在,你可以忽略细节,只看输出。
```py
>>> cfd = nltk.ConditionalFreqDist(
... (genre, word)
... for genre in brown.categories()
... for word in brown.words(categories=genre))
>>> genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor']
>>> modals = ['can', 'could', 'may', 'might', 'must', 'will']
>>> cfd.tabulate(conditions=genres, samples=modals)
can could may might must will
news 93 86 66 38 50 389
religion 82 59 78 12 54 71
hobbies 268 58 131 22 83 264
science_fiction 16 49 4 12 8 16
romance 74 193 11 51 45 43
humor 16 30 8 8 9 13
```
请看,新闻文体中最常见的情态动词是 will,而言情文体中最常见的情态动词是 could。你能预言这些吗?这种可以区分文体的词计数方法将在[chap-data-intensive](./ch06.html#chap-data-intensive)中再次谈及。
## 1.4 路透社语料库
路透社语料库包含 10,788 个新闻文档,共计 130 万字。这些文档分成 90 个主题,按照“训练”和“测试”分为两组;因此,fileid 为`'test/14826'`的文档属于测试组。这样分割是为了训练和测试算法的,这种算法自动检测文档的主题,我们将在[chap-data-intensive](./ch06.html#chap-data-intensive)中看到。
```py
>>> from nltk.corpus import reuters
>>> reuters.fileids()
['test/14826', 'test/14828', 'test/14829', 'test/14832', ...]
>>> reuters.categories()
['acq', 'alum', 'barley', 'bop', 'carcass', 'castor-oil', 'cocoa',
'coconut', 'coconut-oil', 'coffee', 'copper', 'copra-cake', 'corn',
'cotton', 'cotton-oil', 'cpi', 'cpu', 'crude', 'dfl', 'dlr', ...]
```
与布朗语料库不同,路透社语料库的类别是有互相重叠的,只是因为新闻报道往往涉及多个主题。我们可以查找由一个或多个文档涵盖的主题,也可以查找包含在一个或多个类别中的文档。为方便起见,语料库方法既接受单个的 fileid 也接受 fileids 列表作为参数。
```py
>>> reuters.categories('training/9865')
['barley', 'corn', 'grain', 'wheat']
>>> reuters.categories(['training/9865', 'training/9880'])
['barley', 'corn', 'grain', 'money-fx', 'wheat']
>>> reuters.fileids('barley')
['test/15618', 'test/15649', 'test/15676', 'test/15728', 'test/15871', ...]
>>> reuters.fileids(['barley', 'corn'])
['test/14832', 'test/14858', 'test/15033', 'test/15043', 'test/15106',
'test/15287', 'test/15341', 'test/15618', 'test/15648', 'test/15649', ...]
```
类似的,我们可以以文档或类别为单位查找我们想要的词或句子。这些文本中最开始的几个词是标题,按照惯例以大写字母存储。
```py
>>> reuters.words('training/9865')[:14]
['FRENCH', 'FREE', 'MARKET', 'CEREAL', 'EXPORT', 'BIDS',
'DETAILED', 'French', 'operators', 'have', 'requested', 'licences', 'to', 'export']
>>> reuters.words(['training/9865', 'training/9880'])
['FRENCH', 'FREE', 'MARKET', 'CEREAL', 'EXPORT', ...]
>>> reuters.words(categories='barley')
['FRENCH', 'FREE', 'MARKET', 'CEREAL', 'EXPORT', ...]
>>> reuters.words(categories=['barley', 'corn'])
['THAI', 'TRADE', 'DEFICIT', 'WIDENS', 'IN', 'FIRST', ...]
```
## 1.5 就职演说语料库
在第[1](./ch01.html#sec-computing-with-language-texts-and-words)章,我们看到了就职演说语料库,但是把它当作一个单独的文本对待。图[fig-inaugural](./ch01.html#fig-inaugural)中使用的“词偏移”就像是一个坐标轴;它是语料库中词的索引数,从第一个演讲的第一个词开始算起。然而,语料库实际上是 55 个文本的集合,每个文本都是一个总统的演说。这个集合的一个有趣特性是它的时间维度:
```py
>>> from nltk.corpus import inaugural
>>> inaugural.fileids()
['1789-Washington.txt', '1793-Washington.txt', '1797-Adams.txt', ...]
>>> [fileid[:4] for fileid in inaugural.fileids()]
['1789', '1793', '1797', '1801', '1805', '1809', '1813', '1817', '1821', ...]
```
请注意,每个文本的年代都出现在它的文件名中。要从文件名中获得年代,我们使用`fileid[:4]`提取前四个字符。
让我们来看看词汇 America 和 citizen 随时间推移的使用情况。下面的代码使用`w.lower()` [![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#lowercase-startswith)将就职演说语料库中的词汇转换成小写,然后用`startswith()` [![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#lowercase-startswith)检查它们是否以“目标”词汇`america` 或`citizen`开始。因此,它会计算如 American's 和 Citizens 等词。我们将在第[2](./ch02.html#sec-conditional-frequency-distributions)节学习条件频率分布,现在只考虑输出,如图[1.1](./ch02.html#fig-inaugural2)所示。
```py
>>> cfd = nltk.ConditionalFreqDist(
... (target, fileid[:4])
... for fileid in inaugural.fileids()
... for w in inaugural.words(fileid)
... for target in ['america', 'citizen']
... if w.lower().startswith(target)) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> cfd.plot()
```
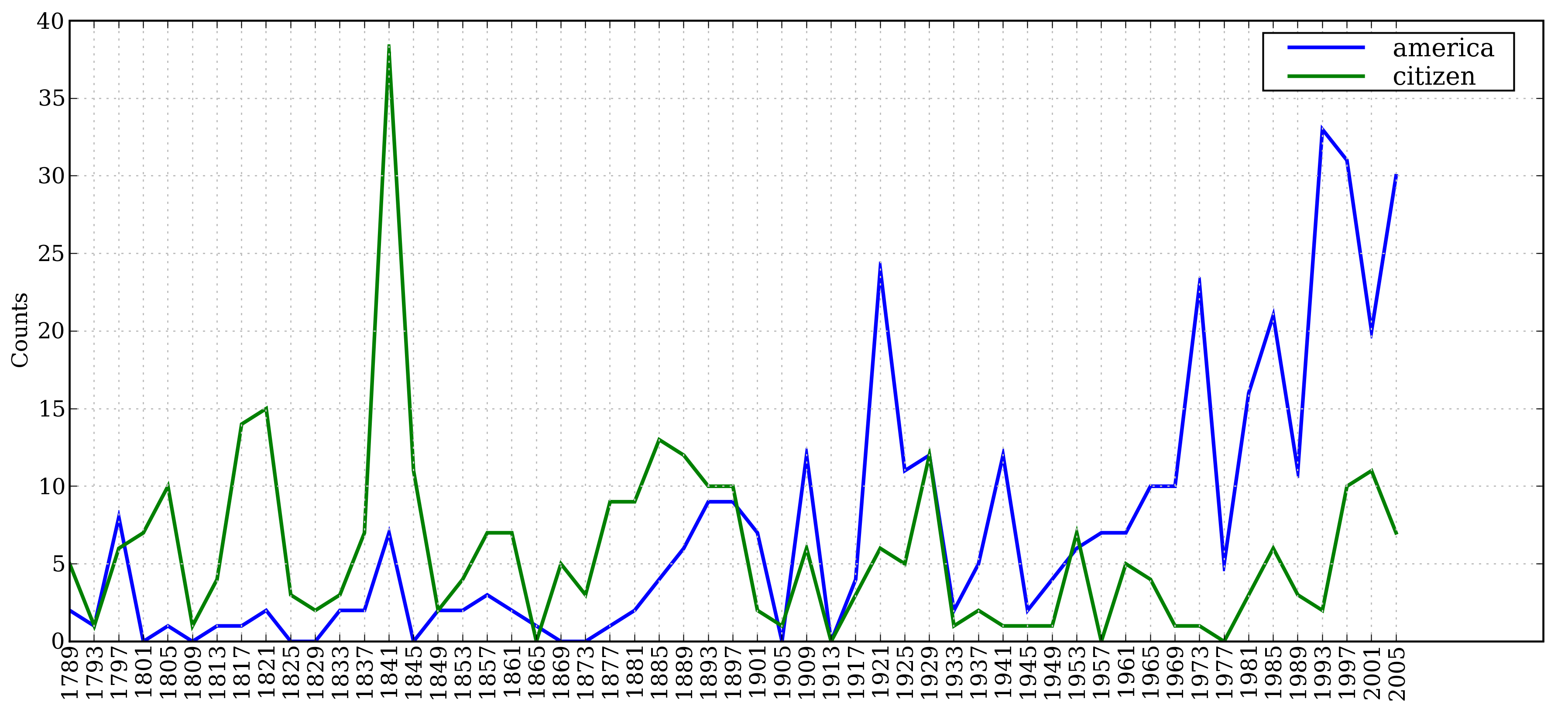
图 1.1:条件频率分布图:计数就职演说语料库中所有以`america` 或`citizen`开始的词;每个演讲单独计数;这样就能观察出随时间变化用法上的演变趋势;计数没有与文档长度进行归一化处理。
## 1.6 标注文本语料库
许多文本语料库都包含语言学标注,有词性标注、命名实体、句法结构、语义角色等。NLTK 中提供了很方便的方式来访问这些语料库中的几个,还有一个包含语料库和语料样本的数据包,用于教学和科研的话可以免费下载。表[1.2](./ch02.html#tab-corpora)列出了其中一些语料库。有关下载信息请参阅`http://nltk.org/data`。关于如何访问 NLTK 语料库的其它例子,请在`http://nltk.org/howto`查阅语料库的 HOWTO。
表 1.2:
NLTK 中的一些语料库和语料库样本:关于下载和使用它们,请参阅 NLTK 网站的信息。
```py
>>> nltk.corpus.cess_esp.words()
['El', 'grupo', 'estatal', 'Electricit\xe9_de_France', ...]
>>> nltk.corpus.floresta.words()
['Um', 'revivalismo', 'refrescante', 'O', '7_e_Meio', ...]
>>> nltk.corpus.indian.words('hindi.pos')
['पूर्ण', 'प्रतिबंध', 'हटाओ', ':', 'इराक', 'संयुक्त', ...]
>>> nltk.corpus.udhr.fileids()
['Abkhaz-Cyrillic+Abkh', 'Abkhaz-UTF8', 'Achehnese-Latin1', 'Achuar-Shiwiar-Latin1',
'Adja-UTF8', 'Afaan_Oromo_Oromiffa-Latin1', 'Afrikaans-Latin1', 'Aguaruna-Latin1',
'Akuapem_Twi-UTF8', 'Albanian_Shqip-Latin1', 'Amahuaca', 'Amahuaca-Latin1', ...]
>>> nltk.corpus.udhr.words('Javanese-Latin1')[11:]
['Saben', 'umat', 'manungsa', 'lair', 'kanthi', 'hak', ...]
```
这些语料库的最后,`udhr`,是超过 300 种语言的世界人权宣言。这个语料库的 fileids 包括有关文件所使用的字符编码,如`UTF8`或者`Latin1`。让我们用条件频率分布来研究`udhr`语料库中不同语言版本中的字长差异。图[1.2](./ch02.html#fig-word-len-dist) 中所示的输出(自己运行程序可以看到一个彩色图)。注意,`True`和`False`是 Python 内置的布尔值。
```py
>>> from nltk.corpus import udhr
>>> languages = ['Chickasaw', 'English', 'German_Deutsch',
... 'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']
>>> cfd = nltk.ConditionalFreqDist(
... (lang, len(word))
... for lang in languages
... for word in udhr.words(lang + '-Latin1'))
>>> cfd.plot(cumulative=True)
```
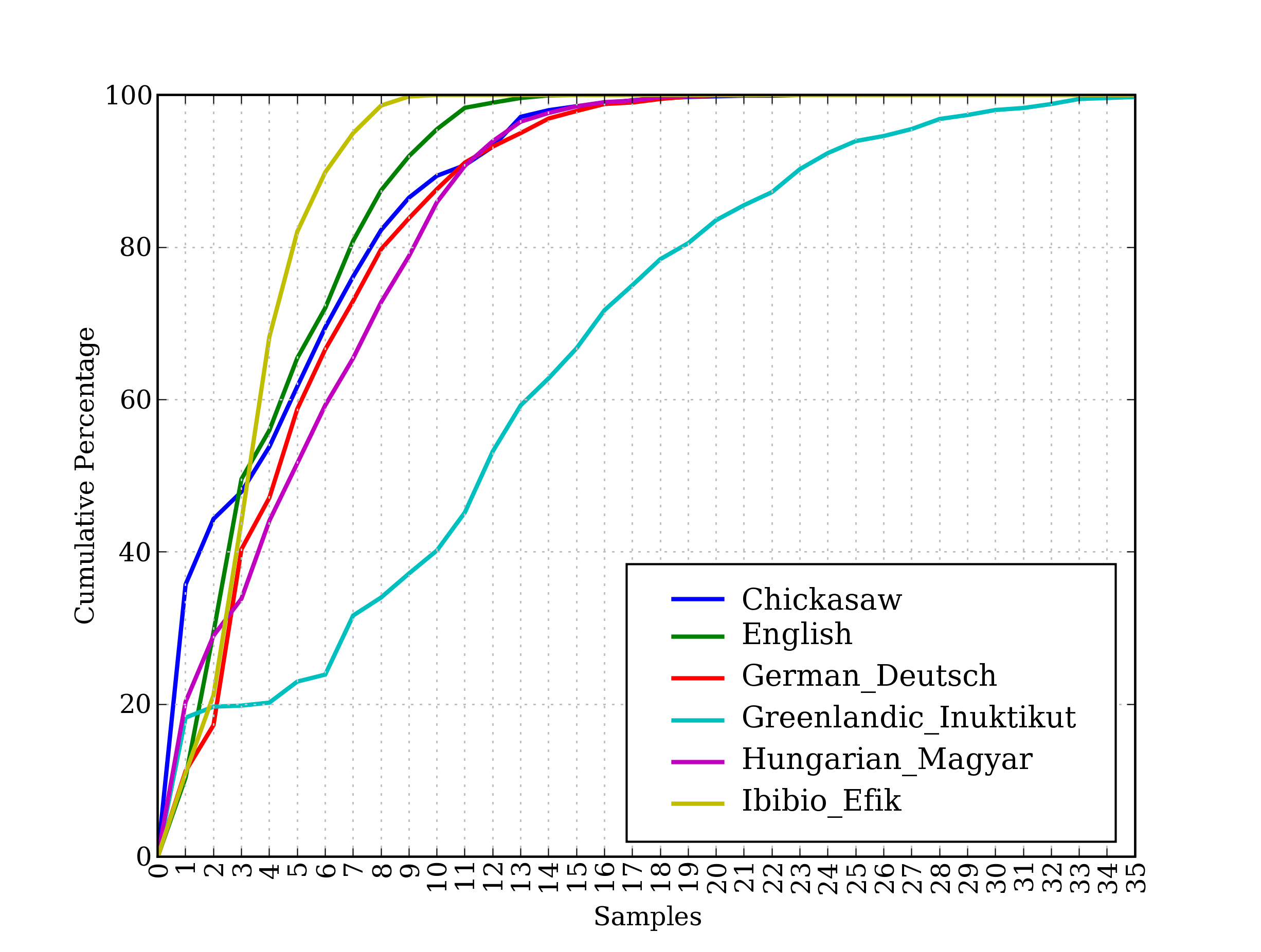
图 1.2:累积字长分布:世界人权宣言的 6 个翻译版本;此图显示,5 个或 5 个以下字母组成的词在 Ibibio 语言的文本中占约 80%,在德语文本中占 60%,在 Inuktitut 文本中占 25%。
注意
**轮到你来:**在`udhr.fileids()`中选择一种感兴趣的语言,定义一个变量`raw_text = udhr.raw(`_Language-Latin1_`)`。使用`nltk.FreqDist(raw_text).plot()`画出此文本的字母频率分布图。
不幸的是,许多语言没有大量的语料库。通常是政府或工业对发展语言资源的支持不够,个人的努力是零碎的,难以发现或重用。有些语言没有既定的书写系统,或濒临灭绝。(见第[7](./ch02.html#sec-further-reading-corpora)节有关如何寻找语言资源的建议。)
## 1.8 文本语料库的结构
到目前为止,我们已经看到了大量的语料库结构;[1.3](./ch02.html#fig-text-corpus-structure)总结了它们。最简单的一种没有任何结构,仅仅是一个文本集合。通常,文本会按照其可能对应的文体、来源、作者、语言等分类。有时,这些类别会重叠,尤其是在按主题分类的情况下,因为一个文本可能与多个主题相关。偶尔的,文本集有一个时间结构,新闻集合是最常见的例子。
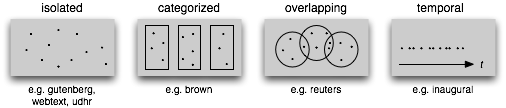
图 1.3:文本语料库的常见结构:最简单的一种语料库是一些孤立的没有什么特别的组织的文本集合;一些语料库按如文体(布朗语料库)等分类组织结构;一些分类会重叠,如主题类别(路透社语料库);另外一些语料库可以表示随时间变化语言用法的改变(就职演说语料库)。
表 1.3:
NLTK 中定义的基本语料库函数:使用`help(nltk.corpus.reader)`可以找到更多的文档,也可以阅读`http://nltk.org/howto`上的在线语料库的 HOWTO。
```py
>>> raw = gutenberg.raw("burgess-busterbrown.txt")
>>> raw[1:20]
'The Adventures of B'
>>> words = gutenberg.words("burgess-busterbrown.txt")
>>> words[1:20]
['The', 'Adventures', 'of', 'Buster', 'Bear', 'by', 'Thornton', 'W', '.',
'Burgess', '1920', ']', 'I', 'BUSTER', 'BEAR', 'GOES', 'FISHING', 'Buster',
'Bear']
>>> sents = gutenberg.sents("burgess-busterbrown.txt")
>>> sents[1:20]
[['I'], ['BUSTER', 'BEAR', 'GOES', 'FISHING'], ['Buster', 'Bear', 'yawned', 'as',
'he', 'lay', 'on', 'his', 'comfortable', 'bed', 'of', 'leaves', 'and', 'watched',
'the', 'first', 'early', 'morning', 'sunbeams', 'creeping', 'through', ...], ...]
```
## 1.9 加载你自己的语料库
如果你有自己收集的文本文件,并且想使用前面讨论的方法访问它们,你可以很容易地在 NLTK 中的`PlaintextCorpusReader`帮助下加载它们。检查你的文件在文件系统中的位置;在下面的例子中,我们假定你的文件在`/usr/share/dict`目录下。不管是什么位置,将变量`corpus_root` [![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#corpus-root-dict)的值设置为这个目录。`PlaintextCorpusReader`初始化函数[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#corpus-reader)的第二个参数可以是一个如`['a.txt', 'test/b.txt']`这样的 fileids 列表,或者一个匹配所有 fileids 的模式,如`'[abc]/.*\.txt'`(关于正则表达式的信息见[3.4](./ch03.html#sec-regular-expressions-word-patterns)节)。
```py
>>> from nltk.corpus import PlaintextCorpusReader
>>> corpus_root = '/usr/share/dict' ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> wordlists = PlaintextCorpusReader(corpus_root, '.*') ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> wordlists.fileids()
['README', 'connectives', 'propernames', 'web2', 'web2a', 'words']
>>> wordlists.words('connectives')
['the', 'of', 'and', 'to', 'a', 'in', 'that', 'is', ...]
```
举另一个例子,假设你在本地硬盘上有自己的宾州树库(第 3 版)的拷贝,放在`C:\corpora`。我们可以使用`BracketParseCorpusReader`访问这些语料。我们指定`corpus_root`为存放语料库中解析过的《华尔街日报》部分[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#corpus-root-treebank)的位置,并指定`file_pattern`与它的子文件夹中包含的文件匹配[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#file-pattern)(用前斜杠)。
```py
>>> from nltk.corpus import BracketParseCorpusReader
>>> corpus_root = r"C:\corpora\penntreebank\parsed\mrg\wsj" ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> file_pattern = r".*/wsj_.*\.mrg" ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> ptb = BracketParseCorpusReader(corpus_root, file_pattern)
>>> ptb.fileids()
['00/wsj_0001.mrg', '00/wsj_0002.mrg', '00/wsj_0003.mrg', '00/wsj_0004.mrg', ...]
>>> len(ptb.sents())
49208
>>> ptb.sents(fileids='20/wsj_2013.mrg')[19]
['The', '55-year-old', 'Mr.', 'Noriega', 'is', "n't", 'as', 'smooth', 'as', 'the',
'shah', 'of', 'Iran', ',', 'as', 'well-born', 'as', 'Nicaragua', "'s", 'Anastasio',
'Somoza', ',', 'as', 'imperial', 'as', 'Ferdinand', 'Marcos', 'of', 'the', 'Philippines',
'or', 'as', 'bloody', 'as', 'Haiti', "'s", 'Baby', Doc', 'Duvalier', '.']
```
## 2 条件频率分布
我们在第[3](./ch01.html#sec-computing-with-language-simple-statistics)节介绍了频率分布。我们看到给定某个词汇或其他元素的列表`mylist`,`FreqDist(mylist)`会计算列表中每个元素项目出现的次数。在这里,我们将推广这一想法。
当语料文本被分为几类,如文体、主题、作者等时,我们可以计算每个类别独立的频率分布。这将允许我们研究类别之间的系统性差异。在上一节中,我们是用 NLTK 的`ConditionalFreqDist`数据类型实现的。条件频率分布是频率分布的集合,每个频率分布有一个不同的“条件”。这个条件通常是文本的类别。[2.1](./ch02.html#fig-tally2)描绘了一个带两个条件的条件频率分布的片段,一个是新闻文本,一个是言情文本。
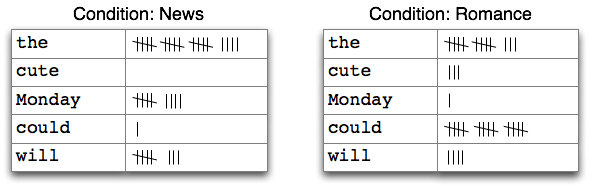
图 2.1:计数文本集合中单词出现次数(条件频率分布)
## 2.1 条件和事件
频率分布计算观察到的事件,如文本中出现的词汇。条件频率分布需要给每个事件关联一个条件。所以不是处理一个单词词序列[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#seq-words),我们必须处理的是一个配对序列[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#seq-pairs):
```py
>>> text = ['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...] ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> pairs = [('news', 'The'), ('news', 'Fulton'), ('news', 'County'), ...] ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
```
每个配对的形式是:`(条件, 事件)`。如果我们按文体处理整个布朗语料库,将有 15 个条件(每个文体一个条件)和 1,161,192 个事件(每一个词一个事件)。
## 2.2 按文体计数词汇
在[1](./ch02.html#sec-extracting-text-from-corpora)中,我们看到一个条件频率分布,其中条件为布朗语料库的每一节,并对每节计数词汇。`FreqDist()`以一个简单的列表作为输入,`ConditionalFreqDist()` 以一个配对列表作为输入。
```py
>>> from nltk.corpus import brown
>>> cfd = nltk.ConditionalFreqDist(
... (genre, word)
... for genre in brown.categories()
... for word in brown.words(categories=genre))
```
让我们拆开来看,只看两个文体,新闻和言情。对于每个文体[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#each-genre),我们遍历文体中的每个词[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch02.html#each-word),以产生文体与词的配对[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#genre-word-pairs) :
```py
>>> genre_word = [(genre, word) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... for genre in ['news', 'romance'] ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
... for word in brown.words(categories=genre)] ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
>>> len(genre_word)
170576
```
因此,在下面的代码中我们可以看到,列表`genre_word`的前几个配对将是 (`'news'`, _word_) [![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#start-genre)的形式,而最后几个配对将是 (`'romance'`, _word_) [![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#end-genre)的形式。
```py
>>> genre_word[:4]
[('news', 'The'), ('news', 'Fulton'), ('news', 'County'), ('news', 'Grand')] # [_start-genre]
>>> genre_word[-4:]
[('romance', 'afraid'), ('romance', 'not'), ('romance', "''"), ('romance', '.')] # [_end-genre]
```
现在,我们可以使用此配对列表创建一个`ConditionalFreqDist`,并将它保存在一个变量`cfd`中。像往常一样,我们可以输入变量的名称来检查它[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#inspect-cfd),并确认它有两个条件[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#conditions-cfd):
```py
>>> cfd = nltk.ConditionalFreqDist(genre_word)
>>> cfd ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
<ConditionalFreqDist with 2 conditions>
>>> cfd.conditions()
['news', 'romance'] # [_conditions-cfd]
```
让我们访问这两个条件,它们每一个都只是一个频率分布:
```py
>>> print(cfd['news'])
<FreqDist with 14394 samples and 100554 outcomes>
>>> print(cfd['romance'])
<FreqDist with 8452 samples and 70022 outcomes>
>>> cfd['romance'].most_common(20)
[(',', 3899), ('.', 3736), ('the', 2758), ('and', 1776), ('to', 1502),
('a', 1335), ('of', 1186), ('``', 1045), ("''", 1044), ('was', 993),
('I', 951), ('in', 875), ('he', 702), ('had', 692), ('?', 690),
('her', 651), ('that', 583), ('it', 573), ('his', 559), ('she', 496)]
>>> cfd['romance']['could']
193
```
## 2.3 绘制分布图和分布表
除了组合两个或两个以上的频率分布和更容易初始化之外,`ConditionalFreqDist`还为制表和绘图提供了一些有用的方法。
[1.1](./ch02.html#fig-inaugural2)是基于下面的代码产生的一个条件频率分布绘制的。条件是词 america 或 citizen[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#america-citizen),被绘图的计数是在特定演讲中出现的词的次数。它利用了每个演讲的文件名——例如`1865-Lincoln.txt` ——的前 4 个字符包含年代的事实[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#first-four-chars)。这段代码为文件`1865-Lincoln.txt`中每个小写形式以 america 开头的词——如 Americans——产生一个配对`('america', '1865')`。
```py
>>> from nltk.corpus import inaugural
>>> cfd = nltk.ConditionalFreqDist(
... (target, fileid[:4]) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... for fileid in inaugural.fileids()
... for w in inaugural.words(fileid)
... for target in ['america', 'citizen'] ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
... if w.lower().startswith(target))
```
图[1.2](./ch02.html#fig-word-len-dist)也是基于下面的代码产生的一个条件频率分布绘制的。这次的条件是语言的名称,图中的计数来源于词长[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#lang-len-word)。它利用了每一种语言的文件名是语言名称后面跟`'-Latin1'`(字符编码)的事实。
```py
>>> from nltk.corpus import udhr
>>> languages = ['Chickasaw', 'English', 'German_Deutsch',
... 'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']
>>> cfd = nltk.ConditionalFreqDist(
... (lang, len(word)) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... for lang in languages
... for word in udhr.words(lang + '-Latin1'))
```
在`plot()`和`tabulate()`方法中,我们可以使用`conditions=`来选择指定哪些条件显示。如果我们忽略它,所有条件都会显示。同样,我们可以使用`samples=`parameter 来限制要显示的样本。这使得载入大量数据到一个条件频率分布,然后通过选定条件和样品,绘图或制表的探索成为可能。这也使我们能全面控制条件和样本的显示顺序。例如:我们可以为两种语言和长度少于 10 个字符的词汇绘制累计频率数据表,如下所示。我们解释一下上排最后一个单元格中数值的含义是英文文本中 9 个或少于 9 个字符长的词有 1,638 个。
```py
>>> cfd.tabulate(conditions=['English', 'German_Deutsch'],
... samples=range(10), cumulative=True)
0 1 2 3 4 5 6 7 8 9
English 0 185 525 883 997 1166 1283 1440 1558 1638
German_Deutsch 0 171 263 614 717 894 1013 1110 1213 1275
```
注意
**轮到你来:** 处理布朗语料库的新闻和言情文体,找出一周中最有新闻价值并且是最浪漫的日子。定义一个变量`days`,包含星期的列表,如`['Monday', ...]`。然后使用`cfd.tabulate(samples=days)`为这些词的计数制表。接下来用`plot`替代`tabulate`尝试同样的事情。你可以在额外的参数`samples=['Monday', ...]`的帮助下控制星期输出的顺序。
你可能已经注意到:我们已经在使用的条件频率分布看上去像列表推导,但是不带方括号。通常,我们使用列表推导作为一个函数的参数,如`set([w.lower() for w in t])`,忽略掉方括号而只写`set(w.lower() for w in t)`是允许的。(更多的讲解请参见[4.2](./ch04.html#sec-sequences)节“生成器表达式”的讨论。)
## 2.4 使用双连词生成随机文本
我们可以使用条件频率分布创建一个双连词表(词对)。(我们在[3](./ch01.html#sec-computing-with-language-simple-statistics)中介绍过。)`bigrams()`函数接受一个单词列表,并建立一个连续的词对列表。记住,为了能看到结果而不是神秘的"生成器对象",我们需要使用`list()`函数︰
```py
>>> sent = ['In', 'the', 'beginning', 'God', 'created', 'the', 'heaven',
... 'and', 'the', 'earth', '.']
>>> list(nltk.bigrams(sent))
[('In', 'the'), ('the', 'beginning'), ('beginning', 'God'), ('God', 'created'),
('created', 'the'), ('the', 'heaven'), ('heaven', 'and'), ('and', 'the'),
('the', 'earth'), ('earth', '.')]
```
在[2.2](./ch02.html#code-random-text)中,我们把每个词作为一个条件,对每个词我们有效的创建它的后续词的频率分布。函数`generate_model()`包含一个简单的循环来生成文本。当我们调用这个函数时,我们选择一个词(如`'living'`)作为我们的初始内容,然后进入循环,我们输入变量`word`的当前值,重新设置`word`为上下文中最可能的词符(使用`max()`);下一次进入循环,我们使用那个词作为新的初始内容。正如你通过检查输出可以看到的,这种简单的文本生成方法往往会在循环中卡住;另一种方法是从可用的词汇中随机选择下一个词。
```py
def generate_model(cfdist, word, num=15):
for i in range(num):
print(word, end=' ')
word = cfdist[word].max()
text = nltk.corpus.genesis.words('english-kjv.txt')
bigrams = nltk.bigrams(text)
cfd = nltk.ConditionalFreqDist(bigrams) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
```
条件频率分布是一个对许多 NLP 任务都有用的数据结构。[2.1](./ch02.html#tab-conditionalfreqdist)总结了它们常用的方法。
表 2.1:
NLTK 中的条件频率分布:定义、访问和可视化一个计数的条件频率分布的常用方法和习惯用法。
```py
print('Monty Python')
```
你也可以输入`from monty import *`,它将做同样的事情。
从现在起,你可以选择使用交互式解释器或文本编辑器来创建你的程序。使用解释器测试你的想法往往比较方便,修改一行代码直到达到你期望的效果。测试好之后,你就可以将代码粘贴到文本编辑器(去除所有`>>>` 和`...`提示符),继续扩展它。给文件一个小而准确的名字,使用所有的小写字母,用下划线分割词汇,使用`.py`文件名后缀,例如`monty_python.py`。
注意
**要点:** 我们的内联代码的例子包含`>>>`和`...`提示符,好像我们正在直接与解释器交互。随着程序变得更加复杂,你应该在编辑器中输入它们,没有提示符,如前面所示的那样在编辑器中运行它们。当我们在这本书中提供更长的程序时,我们将不使用提示符以提醒你在文件中输入它而不是使用解释器。你可以看到[2.2](./ch02.html#code-random-text)已经这样了。请注意,这个例子还包括两行代码带有 Python 提示符;它是任务的互动部分,在这里你观察一些数据,并调用一个函数。请记住,像[2.2](./ch02.html#code-random-text)这样的所有示例代码都可以从`http://nltk.org/`下载。
## 3.2 函数
假设你正在分析一些文本,这些文本包含同一个词的不同形式,你的一部分程序需要将给定的单数名词变成复数形式。假设需要在两个地方做这样的事,一个是处理一些文本,另一个是处理用户的输入。
比起重复相同的代码好几次,把这些事情放在一个函数中会更有效和可靠。一个函数是命名的代码块,执行一些明确的任务,就像我们在[1](./ch01.html#sec-computing-with-language-texts-and-words)中所看到的那样。一个函数通常被定义来使用一些称为参数的变量接受一些输入,并且它可能会产生一些结果,也称为返回值。我们使用关键字`def`加函数名以及所有输入参数来定义一个函数,接下来是函数的主体。这里是我们在[1](./ch01.html#sec-computing-with-language-texts-and-words)看到的函数(对于 Python 2,请包含`import`语句,这样可以使除法像我们期望的那样运算):
```py
>>> from __future__ import division
>>> def lexical_diversity(text):
... return len(text) / len(set(text))
```
我们使用关键字`return`表示函数作为输出而产生的值。在这个例子中,函数所有的工作都在`return`语句中完成。下面是一个等价的定义,使用多行代码做同样的事。我们将把参数名称从`text`变为`my_text_data`,注意这只是一个任意的选择:
```py
>>> def lexical_diversity(my_text_data):
... word_count = len(my_text_data)
... vocab_size = len(set(my_text_data))
... diversity_score = vocab_size / word_count
... return diversity_score
```
请注意,我们已经在函数体内部创造了一些新的变量。这些是局部变量,不能在函数体外访问。现在我们已经定义一个名为`lexical_diversity`的函数。但只定义它不会产生任何输出!函数在被“调用”之前不会做任何事情:
```py
>>> from nltk.corpus import genesis
>>> kjv = genesis.words('english-kjv.txt')
>>> lexical_diversity(kjv)
0.06230453042623537
```
让我们回到前面的场景,实际定义一个简单的函数来处理英文的复数词。[3.1](./ch02.html#code-plural)中的函数`plural()`接受单数名词,产生一个复数形式,虽然它并不总是正确的。(我们将在[4.4](./ch04.html#sec-functions)中以更长的篇幅讨论这个函数。)
```py
def plural(word):
if word.endswith('y'):
return word[:-1] + 'ies'
elif word[-1] in 'sx' or word[-2:] in ['sh', 'ch']:
return word + 'es'
elif word.endswith('an'):
return word[:-2] + 'en'
else:
return word + 's'
```
`endswith()`函数总是与一个字符串对象一起使用(如[3.1](./ch02.html#code-plural)中的`word`)。要调用此函数,我们使用对象的名字,一个点,然后跟函数的名称。这些函数通常被称为方法。
## 3.3 模块
随着时间的推移,你将会发现你创建了大量小而有用的文字处理函数,结果你不停的把它们从老程序复制到新程序中。哪个文件中包含的才是你要使用的函数的最新版本?如果你能把你的劳动成果收集在一个单独的地方,而且访问以前定义的函数不必复制,生活将会更加轻松。
要做到这一点,请将你的函数保存到一个文件`text_proc.py`。现在,你可以简单的通过从文件导入它来访问你的函数:
```py
>>> from text_proc import plural
>>> plural('wish')
wishes
>>> plural('fan')
fen
```
显然,我们的复数函数明显存在错误,因为 fan 的复数是 fans。不必再重新输入这个函数的新版本,我们可以简单的编辑现有的。因此,在任何时候我们的复数函数只有一个版本,不会再有使用哪个版本的困扰。
在一个文件中的变量和函数定义的集合被称为一个 Python 模块。相关模块的集合称为一个包。处理布朗语料库的 NLTK 代码是一个模块,处理各种不同的语料库的代码的集合是一个包。NLTK 的本身是包的集合,有时被称为一个库。
小心!
如果你正在创建一个包含一些你自己的 Python 代码的文件,一定 _ 不 _ 要将文件命名为`nltk.py`:这可能会在导入时占据“真正的”NLTK 包。当 Python 导入模块时,它先查找当前目录(文件夹)。
## 4 词汇资源
词典或者词典资源是一个词和/或短语以及一些相关信息的集合,例如:词性和词意定义等相关信息。词典资源附属于文本,通常在文本的帮助下创建和丰富。例如:如果我们定义了一个文本`my_text`,然后`vocab = sorted(set(my_text))`建立`my_text`的词汇,同时`word_freq = FreqDist(my_text)`计数文本中每个词的频率。`vocab`和`word_freq`都是简单的词汇资源。同样,如我们在[1](./ch01.html#sec-computing-with-language-texts-and-words)中看到的,词汇索引为我们提供了有关词语用法的信息,可能在编写词典时有用。[4.1](./ch02.html#fig-lexicon)中描述了词汇相关的标准术语。一个词项包括词目(也叫词条)以及其他附加信息,例如词性和词意定义。两个不同的词拼写相同被称为同音异义词。

图 4.1:词典术语:两个拼写相同的词条(同音异义词)的词汇项,包括词性和注释信息。
最简单的词典是除了一个词汇列表外什么也没有。复杂的词典资源包括在词汇项内和跨词汇项的复杂的结构。在本节,我们来看看 NLTK 中的一些词典资源。
## 4.1 词汇列表语料库
NLTK 包括一些仅仅包含词汇列表的语料库。词汇语料库是 Unix 中的`/usr/share/dict/words`文件,被一些拼写检查程序使用。我们可以用它来寻找文本语料中不寻常的或拼写错误的词汇,如[4.2](./ch02.html#code-unusual)所示。
```py
def unusual_words(text):
text_vocab = set(w.lower() for w in text if w.isalpha())
english_vocab = set(w.lower() for w in nltk.corpus.words.words())
unusual = text_vocab - english_vocab
return sorted(unusual)
>>> unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt'))
['abbeyland', 'abhorred', 'abilities', 'abounded', 'abridgement', 'abused', 'abuses',
'accents', 'accepting', 'accommodations', 'accompanied', 'accounted', 'accounts',
'accustomary', 'aches', 'acknowledging', 'acknowledgment', 'acknowledgments', ...]
>>> unusual_words(nltk.corpus.nps_chat.words())
['aaaaaaaaaaaaaaaaa', 'aaahhhh', 'abortions', 'abou', 'abourted', 'abs', 'ack',
'acros', 'actualy', 'adams', 'adds', 'adduser', 'adjusts', 'adoted', 'adreniline',
'ads', 'adults', 'afe', 'affairs', 'affari', 'affects', 'afk', 'agaibn', 'ages', ...]
```
还有一个停用词语料库,就是那些高频词汇,如 the,to 和 also,我们有时在进一步的处理之前想要将它们从文档中过滤。停用词通常几乎没有什么词汇内容,而它们的出现会使区分文本变困难。
```py
>>> from nltk.corpus import stopwords
>>> stopwords.words('english')
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours',
'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers',
'herself', 'it', 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves',
'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are',
'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does',
'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until',
'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into',
'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down',
'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here',
'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more',
'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so',
'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', 'should', 'now']
```
让我们定义一个函数来计算文本中 _ 没有 _ 在停用词列表中的词的比例:
```py
>>> def content_fraction(text):
... stopwords = nltk.corpus.stopwords.words('english')
... content = [w for w in text if w.lower() not in stopwords]
... return len(content) / len(text)
...
>>> content_fraction(nltk.corpus.reuters.words())
0.7364374824583169
```
因此,在停用词的帮助下,我们筛选掉文本中四分之一的词。请注意,我们在这里结合了两种不同类型的语料库,使用词典资源来过滤文本语料的内容。

图 4.3:一个字母拼词谜题::在由随机选择的字母组成的网格中,选择里面的字母组成词;这个谜题叫做“目标”。
一个词汇列表对解决如图[4.3](./ch02.html#fig-target)中这样的词的谜题很有用。我们的程序遍历每一个词,对于每一个词检查是否符合条件。检查必须出现的字母[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#obligatory-letter)和长度限制[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#length-constraint)是很容易的(这里我们只查找 6 个或 6 个以上字母的词)。只使用指定的字母组合作为候选方案,尤其是一些指定的字母出现了两次(这里如字母 v)这样的检查是很棘手的。`FreqDist`比较法[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch02.html#freqdist-compare)允许我们检查每个 _ 字母 _ 在候选词中的频率是否小于或等于相应的字母在拼词谜题中的频率。
```py
>>> puzzle_letters = nltk.FreqDist('egivrvonl')
>>> obligatory = 'r'
>>> wordlist = nltk.corpus.words.words()
>>> [w for w in wordlist if len(w) >= 6 ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... and obligatory in w ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
... and nltk.FreqDist(w) <= puzzle_letters] ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
['glover', 'gorlin', 'govern', 'grovel', 'ignore', 'involver', 'lienor',
'linger', 'longer', 'lovering', 'noiler', 'overling', 'region', 'renvoi',
'revolving', 'ringle', 'roving', 'violer', 'virole']
```
另一个词汇列表是名字语料库,包括 8000 个按性别分类的名字。男性和女性的名字存储在单独的文件中。让我们找出同时出现在两个文件中的名字,即性别暧昧的名字:
```py
>>> names = nltk.corpus.names
>>> names.fileids()
['female.txt', 'male.txt']
>>> male_names = names.words('male.txt')
>>> female_names = names.words('female.txt')
>>> [w for w in male_names if w in female_names]
['Abbey', 'Abbie', 'Abby', 'Addie', 'Adrian', 'Adrien', 'Ajay', 'Alex', 'Alexis',
'Alfie', 'Ali', 'Alix', 'Allie', 'Allyn', 'Andie', 'Andrea', 'Andy', 'Angel',
'Angie', 'Ariel', 'Ashley', 'Aubrey', 'Augustine', 'Austin', 'Averil', ...]
```
正如大家都知道的,以字母 a 结尾的名字几乎都是女性。我们可以在[4.4](./ch02.html#fig-cfd-gender)中看到这一点以及一些其它的模式,该图是由下面的代码产生的。请记住`name[-1]`是`name`的最后一个字母。
```py
>>> cfd = nltk.ConditionalFreqDist(
... (fileid, name[-1])
... for fileid in names.fileids()
... for name in names.words(fileid))
>>> cfd.plot()
```
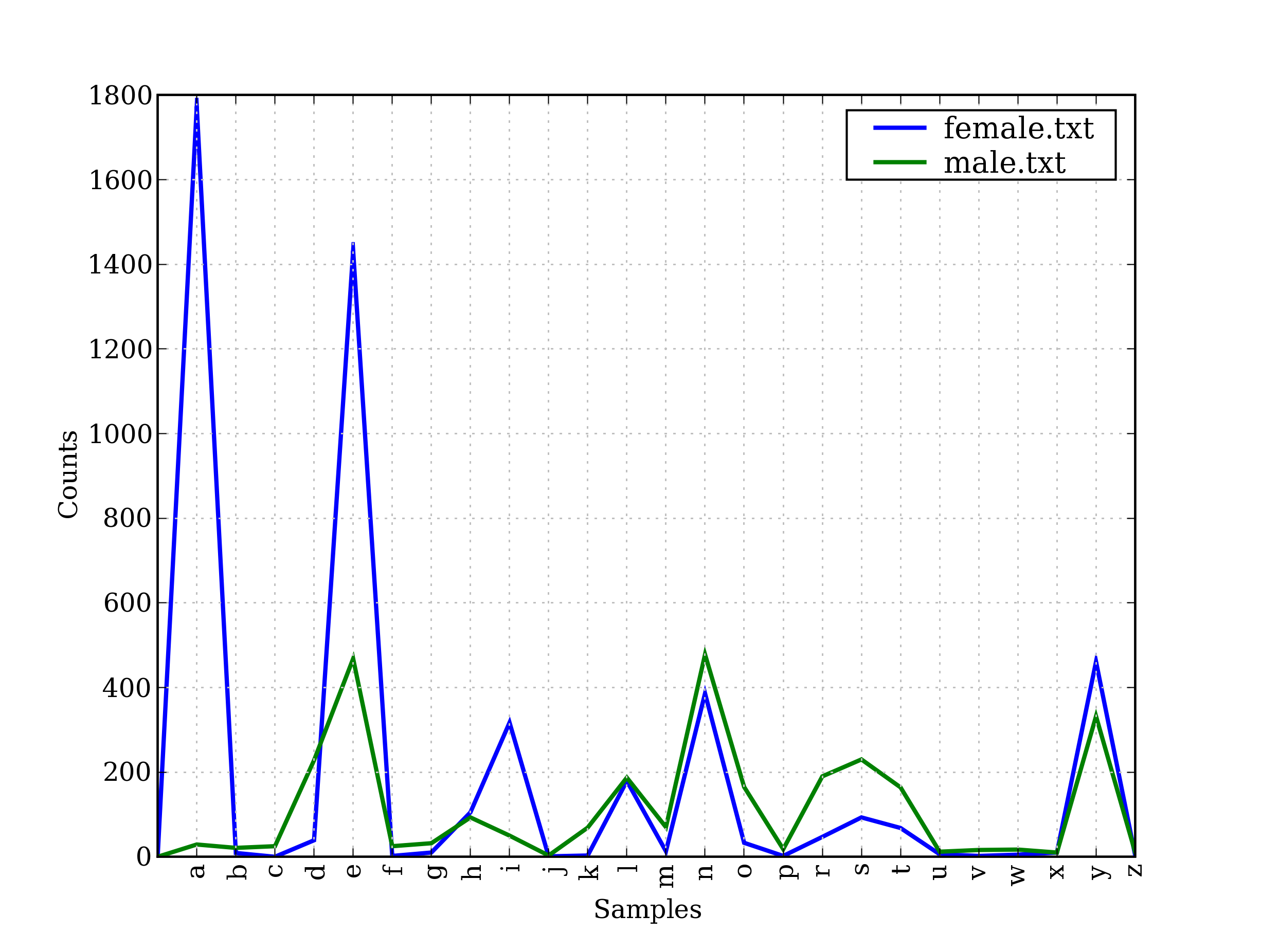
图 4.4:条件频率分布:此图显示男性和女性名字的结尾字母;大多数以 a,e 或 i 结尾的名字是女性;以 h 和 l 结尾的男性和女性同样多;以 k, o, r, s 和 t 结尾的更可能是男性。
## 4.2 发音的词典
一个稍微丰富的词典资源是一个表格(或电子表格),在每一行中含有一个词加一些性质。NLTK 中包括美国英语的 CMU 发音词典,它是为语音合成器使用而设计的。
```py
>>> entries = nltk.corpus.cmudict.entries()
>>> len(entries)
133737
>>> for entry in entries[42371:42379]:
... print(entry)
...
('fir', ['F', 'ER1'])
('fire', ['F', 'AY1', 'ER0'])
('fire', ['F', 'AY1', 'R'])
('firearm', ['F', 'AY1', 'ER0', 'AA2', 'R', 'M'])
('firearm', ['F', 'AY1', 'R', 'AA2', 'R', 'M'])
('firearms', ['F', 'AY1', 'ER0', 'AA2', 'R', 'M', 'Z'])
('firearms', ['F', 'AY1', 'R', 'AA2', 'R', 'M', 'Z'])
('fireball', ['F', 'AY1', 'ER0', 'B', 'AO2', 'L'])
```
对每一个词,这个词典资源提供语音的代码——不同的声音不同的标签——叫做 phones。请看 fire 有两个发音(美国英语中):单音节`F AY1 R`和双音节`F AY1 ER0`。CMU 发音词典中的符号是从 _Arpabet_ 来的,更多的细节请参考`http://en.wikipedia.org/wiki/Arpabet`。
每个条目由两部分组成,我们可以用一个复杂的`for`语句来一个一个的处理这些。我们没有写`for entry in entries:`,而是用 _ 两个 _ 变量名`word, pron`替换`entry`[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#word-pron)。现在,每次通过循环时,`word`被分配条目的第一部分,`pron`被分配条目的第二部分:
```py
>>> for word, pron in entries: ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... if len(pron) == 3: ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
... ph1, ph2, ph3 = pron ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
... if ph1 == 'P' and ph3 == 'T':
... print(word, ph2, end=' ')
...
pait EY1 pat AE1 pate EY1 patt AE1 peart ER1 peat IY1 peet IY1 peete IY1 pert ER1
pet EH1 pete IY1 pett EH1 piet IY1 piette IY1 pit IH1 pitt IH1 pot AA1 pote OW1
pott AA1 pout AW1 puett UW1 purt ER1 put UH1 putt AH1
```
上面的程序扫描词典中那些发音包含三个音素的条目[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#len-pron-three)。如果条件为真,就将`pron`的内容分配给三个新的变量:`ph1`, `ph2`和`ph3`。请注意实现这个功能的语句的形式并不多见[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch02.html#tuple-assignment)。
这里是同样的`for`语句的另一个例子,这次使用内部的列表推导。这段程序找到所有发音结尾与 nicks 相似的词汇。你可以使用此方法来找到押韵的词。
```py
>>> syllable = ['N', 'IH0', 'K', 'S']
>>> [word for word, pron in entries if pron[-4:] == syllable]
["atlantic's", 'audiotronics', 'avionics', 'beatniks', 'calisthenics', 'centronics',
'chamonix', 'chetniks', "clinic's", 'clinics', 'conics', 'conics', 'cryogenics',
'cynics', 'diasonics', "dominic's", 'ebonics', 'electronics', "electronics'", ...]
```
请注意,有几种方法来拼读一个读音:nics, niks, nix 甚至 ntic's 加一个无声的 t,如词 atlantic's。让我们来看看其他一些发音与书写之间的不匹配。你可以总结一下下面的例子的功能,并解释它们是如何实现的?
```py
>>> [w for w, pron in entries if pron[-1] == 'M' and w[-1] == 'n']
['autumn', 'column', 'condemn', 'damn', 'goddamn', 'hymn', 'solemn']
>>> sorted(set(w[:2] for w, pron in entries if pron[0] == 'N' and w[0] != 'n'))
['gn', 'kn', 'mn', 'pn']
```
音素包含数字表示主重音(`1`),次重音(`2`)和无重音(`0`)。作为我们最后的一个例子,我们定义一个函数来提取重音数字,然后扫描我们的词典,找到具有特定重音模式的词汇。
```py
>>> def stress(pron):
... return [char for phone in pron for char in phone if char.isdigit()]
>>> [w for w, pron in entries if stress(pron) == ['0', '1', '0', '2', '0']]
['abbreviated', 'abbreviated', 'abbreviating', 'accelerated', 'accelerating',
'accelerator', 'accelerators', 'accentuated', 'accentuating', 'accommodated',
'accommodating', 'accommodative', 'accumulated', 'accumulating', 'accumulative', ...]
>>> [w for w, pron in entries if stress(pron) == ['0', '2', '0', '1', '0']]
['abbreviation', 'abbreviations', 'abomination', 'abortifacient', 'abortifacients',
'academicians', 'accommodation', 'accommodations', 'accreditation', 'accreditations',
'accumulation', 'accumulations', 'acetylcholine', 'acetylcholine', 'adjudication', ...]
```
注意
这段程序的精妙之处在于:我们的用户自定义函数`stress()`调用一个内含条件的列表推导。还有一个双层嵌套`for`循环。这里有些复杂,等你有了更多的使用列表推导的经验后,你可能会想回过来重新阅读。
我们可以使用条件频率分布来帮助我们找到词汇的最小受限集合。在这里,我们找到所有 p 开头的三音素词[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#p3-words),并按照它们的第一个和最后一个音素来分组[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#group-first-last)。
```py
>>> p3 = [(pron[0]+'-'+pron[2], word) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... for (word, pron) in entries
... if pron[0] == 'P' and len(pron) == 3] ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> cfd = nltk.ConditionalFreqDist(p3)
>>> for template in sorted(cfd.conditions()):
... if len(cfd[template]) > 10:
... words = sorted(cfd[template])
... wordstring = ' '.join(words)
... print(template, wordstring[:70] + "...")
...
P-CH patch pautsch peach perch petsch petsche piche piech pietsch pitch pit...
P-K pac pack paek paik pak pake paque peak peake pech peck peek perc perk ...
P-L pahl pail paille pal pale pall paul paule paull peal peale pearl pearl...
P-N paign pain paine pan pane pawn payne peine pen penh penn pin pine pinn...
P-P paap paape pap pape papp paup peep pep pip pipe pipp poop pop pope pop...
P-R paar pair par pare parr pear peer pier poor poore por pore porr pour...
P-S pace pass pasts peace pearse pease perce pers perse pesce piece piss p...
P-T pait pat pate patt peart peat peet peete pert pet pete pett piet piett...
P-UW1 peru peugh pew plew plue prew pru prue prugh pshew pugh...
```
我们可以通过查找特定词汇来访问词典,而不必遍历整个词典。我们将使用 Python 的词典数据结构,在[3](./ch05.html#sec-dictionaries)节我们将系统的学习它。通过指定词典的名字后面跟一个包含在方括号里的关键字(例如词`'fire'`)来查词典[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#dict-key)。
```py
>>> prondict = nltk.corpus.cmudict.dict()
>>> prondict['fire'] ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
[['F', 'AY1', 'ER0'], ['F', 'AY1', 'R']]
>>> prondict['blog'] ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'blog'
>>> prondict['blog'] = [['B', 'L', 'AA1', 'G']] ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
>>> prondict['blog']
[['B', 'L', 'AA1', 'G']]
```
如果我们试图查找一个不存在的关键字[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#dict-key-error),就会得到一个`KeyError`。这与我们使用一个过大的整数索引一个列表时产生一个`IndexError`是类似的。词 blog 在发音词典中没有,所以我们对我们自己版本的词典稍作调整,为这个关键字分配一个值[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch02.html#dict-assign)(这对 NLTK 语料库是没有影响的;下一次我们访问它,blog 依然是空的)。
我们可以用任何词典资源来处理文本,如过滤掉具有某些词典属性的词(如名词),或者映射文本中每一个词。例如,下面的文本到发音函数在发音词典中查找文本中每个词:
```py
>>> text = ['natural', 'language', 'processing']
>>> [ph for w in text for ph in prondict[w][0]]
['N', 'AE1', 'CH', 'ER0', 'AH0', 'L', 'L', 'AE1', 'NG', 'G', 'W', 'AH0', 'JH',
'P', 'R', 'AA1', 'S', 'EH0', 'S', 'IH0', 'NG']
```
## 4.3 比较词表
表格词典的另一个例子是比较词表。NLTK 中包含了所谓的斯瓦迪士核心词列表,几种语言中约 200 个常用词的列表。语言标识符使用 ISO639 双字母码。
```py
>>> from nltk.corpus import swadesh
>>> swadesh.fileids()
['be', 'bg', 'bs', 'ca', 'cs', 'cu', 'de', 'en', 'es', 'fr', 'hr', 'it', 'la', 'mk',
'nl', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sr', 'sw', 'uk']
>>> swadesh.words('en')
['I', 'you (singular), thou', 'he', 'we', 'you (plural)', 'they', 'this', 'that',
'here', 'there', 'who', 'what', 'where', 'when', 'how', 'not', 'all', 'many', 'some',
'few', 'other', 'one', 'two', 'three', 'four', 'five', 'big', 'long', 'wide', ...]
```
我们可以通过在`entries()` 方法中指定一个语言列表来访问多语言中的同源词。更进一步,我们可以把它转换成一个简单的词典(我们将在[3](./ch05.html#sec-dictionaries)学到`dict()`函数)。
```py
>>> fr2en = swadesh.entries(['fr', 'en'])
>>> fr2en
[('je', 'I'), ('tu, vous', 'you (singular), thou'), ('il', 'he'), ...]
>>> translate = dict(fr2en)
>>> translate['chien']
'dog'
>>> translate['jeter']
'throw'
```
通过添加其他源语言,我们可以让我们这个简单的翻译器更为有用。让我们使用`dict()`函数把德语-英语和西班牙语-英语对相互转换成一个词典,然后用这些添加的映射 _ 更新 _ 我们原来的`翻译`词典:
```py
>>> de2en = swadesh.entries(['de', 'en']) # German-English
>>> es2en = swadesh.entries(['es', 'en']) # Spanish-English
>>> translate.update(dict(de2en))
>>> translate.update(dict(es2en))
>>> translate['Hund']
'dog'
>>> translate['perro']
'dog'
```
我们可以比较日尔曼语族和拉丁语族的不同:
```py
>>> languages = ['en', 'de', 'nl', 'es', 'fr', 'pt', 'la']
>>> for i in [139, 140, 141, 142]:
... print(swadesh.entries(languages)[i])
...
('say', 'sagen', 'zeggen', 'decir', 'dire', 'dizer', 'dicere')
('sing', 'singen', 'zingen', 'cantar', 'chanter', 'cantar', 'canere')
('play', 'spielen', 'spelen', 'jugar', 'jouer', 'jogar, brincar', 'ludere')
('float', 'schweben', 'zweven', 'flotar', 'flotter', 'flutuar, boiar', 'fluctuare')
```
## 4.4 词汇工具:Shoebox 和 Toolbox
可能最流行的语言学家用来管理数据的工具是 _Toolbox_,以前叫做 _Shoebox_,因为它用满满的档案卡片占据了语言学家的旧鞋盒。Toolbox 可以免费从`http://www.sil.org/computing/toolbox/`下载。
一个 Toolbox 文件由一个大量条目的集合组成,其中每个条目由一个或多个字段组成。大多数字段都是可选的或重复的,这意味着这个词汇资源不能作为一个表格或电子表格来处理。
下面是一个罗托卡特语的词典。我们只看第一个条目,词 kaa 的意思是"to gag":
```py
>>> from nltk.corpus import toolbox
>>> toolbox.entries('rotokas.dic')
[('kaa', [('ps', 'V'), ('pt', 'A'), ('ge', 'gag'), ('tkp', 'nek i pas'),
('dcsv', 'true'), ('vx', '1'), ('sc', '???'), ('dt', '29/Oct/2005'),
('ex', 'Apoka ira kaaroi aioa-ia reoreopaoro.'),
('xp', 'Kaikai i pas long nek bilong Apoka bikos em i kaikai na toktok.'),
('xe', 'Apoka is gagging from food while talking.')]), ...]
```
条目包括一系列的属性-值对,如`('ps', 'V')`表示词性是`'V'`(动词),`('ge', 'gag')`表示英文注释是'`'gag'`。最后的 3 个配对包含一个罗托卡特语例句和它的巴布亚皮钦语及英语翻译。
Toolbox 文件松散的结构使我们在现阶段很难更好的利用它。XML 提供了一种强有力的方式来处理这种语料库,我们将在[11.](./ch11.html#chap-data)回到这个的主题。
注意
罗托卡特语是巴布亚新几内亚的布干维尔岛上使用的一种语言。这个词典资源由 Stuart Robinson 贡献给 NLTK。罗托卡特语以仅有 12 个音素(彼此对立的声音)而闻名。详情请参考:`http://en.wikipedia.org/wiki/Rotokas_language`
## 5 WordNet
WordNet 是面向语义的英语词典,类似与传统辞典,但具有更丰富的结构。NLTK 中包括英语 WordNet,共有 155,287 个词和 117,659 个同义词集合。我们将以寻找同义词和它们在 WordNet 中如何访问开始。
## 5.1 意义与同义词
考虑[(1a)](./ch02.html#ex-car1)中的句子。如果我们用 automobile 替换掉[(1a)](./ch02.html#ex-car1)中的词 motorcar,变成[(1b)](./ch02.html#ex-car2),句子的意思几乎保持不变:
```py
>>> from nltk.corpus import wordnet as wn
>>> wn.synsets('motorcar')
[Synset('car.n.01')]
```
因此,motorcar 只有一个可能的含义,它被定义为`car.n.01`,car 的第一个名词意义。`car.n.01`被称为 synset 或“同义词集”,意义相同的词(或“词条”)的集合:
```py
>>> wn.synset('car.n.01').lemma_names()
['car', 'auto', 'automobile', 'machine', 'motorcar']
```
同义词集中的每个词可以有多种含义,例如:car 也可能是火车车厢、一个货车或电梯厢。但我们只对这个同义词集中所有词来说最常用的一个意义感兴趣。同义词集也有一些一般的定义和例句:
```py
>>> wn.synset('car.n.01').definition()
'a motor vehicle with four wheels; usually propelled by an internal combustion engine'
>>> wn.synset('car.n.01').examples()
['he needs a car to get to work']
```
虽然定义帮助人们了解一个同义词集的本意,同义词集中的词往往对我们的程序更有用。为了消除歧义,我们将这些词标记为`car.n.01.automobile`,`car.n.01.motorcar`等。这种同义词集和词的配对叫做词条。我们可以得到指定同义词集的所有词条[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch02.html#get-lemmas),查找特定的词条[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch02.html#lookup-lemma),得到一个词条对应的同义词集[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch02.html#get-synset),也可以得到一个词条的“名字”[![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)](./ch02.html#get-name):
```py
>>> wn.synset('car.n.01').lemmas() ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
[Lemma('car.n.01.car'), Lemma('car.n.01.auto'), Lemma('car.n.01.automobile'),
Lemma('car.n.01.machine'), Lemma('car.n.01.motorcar')]
>>> wn.lemma('car.n.01.automobile') ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
Lemma('car.n.01.automobile')
>>> wn.lemma('car.n.01.automobile').synset() ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
Synset('car.n.01')
>>> wn.lemma('car.n.01.automobile').name() ![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)
'automobile'
```
与词 motorcar 意义明确且只有一个同义词集不同,词 car 是含糊的,有五个同义词集:
```py
>>> wn.synsets('car')
[Synset('car.n.01'), Synset('car.n.02'), Synset('car.n.03'), Synset('car.n.04'),
Synset('cable_car.n.01')]
>>> for synset in wn.synsets('car'):
... print(synset.lemma_names())
...
['car', 'auto', 'automobile', 'machine', 'motorcar']
['car', 'railcar', 'railway_car', 'railroad_car']
['car', 'gondola']
['car', 'elevator_car']
['cable_car', 'car']
```
为方便起见,我们可以用下面的方式访问所有包含词 car 的词条。
```py
>>> wn.lemmas('car')
[Lemma('car.n.01.car'), Lemma('car.n.02.car'), Lemma('car.n.03.car'),
Lemma('car.n.04.car'), Lemma('cable_car.n.01.car')]
```
注意
**轮到你来:**写下词 dish 的你能想到的所有意思。现在,在 WordNet 的帮助下使用前面所示的相同的操作探索这个词。
## 5.2 WordNet 的层次结构
WordNet 的同义词集对应于抽象的概念,它们并不总是有对应的英语词汇。这些概念在层次结构中相互联系在一起。一些概念也很一般,如 _ 实体 _、_ 状态 _、_ 事件 _;这些被称为唯一前缀或者根同义词集。其他的,如 _ 油老虎 _ 和 _ 有仓门式后背的汽车 _ 等就比较具体的多。[5.1](./ch02.html#fig-wn-hierarchy)展示了一个概念层次的一小部分。
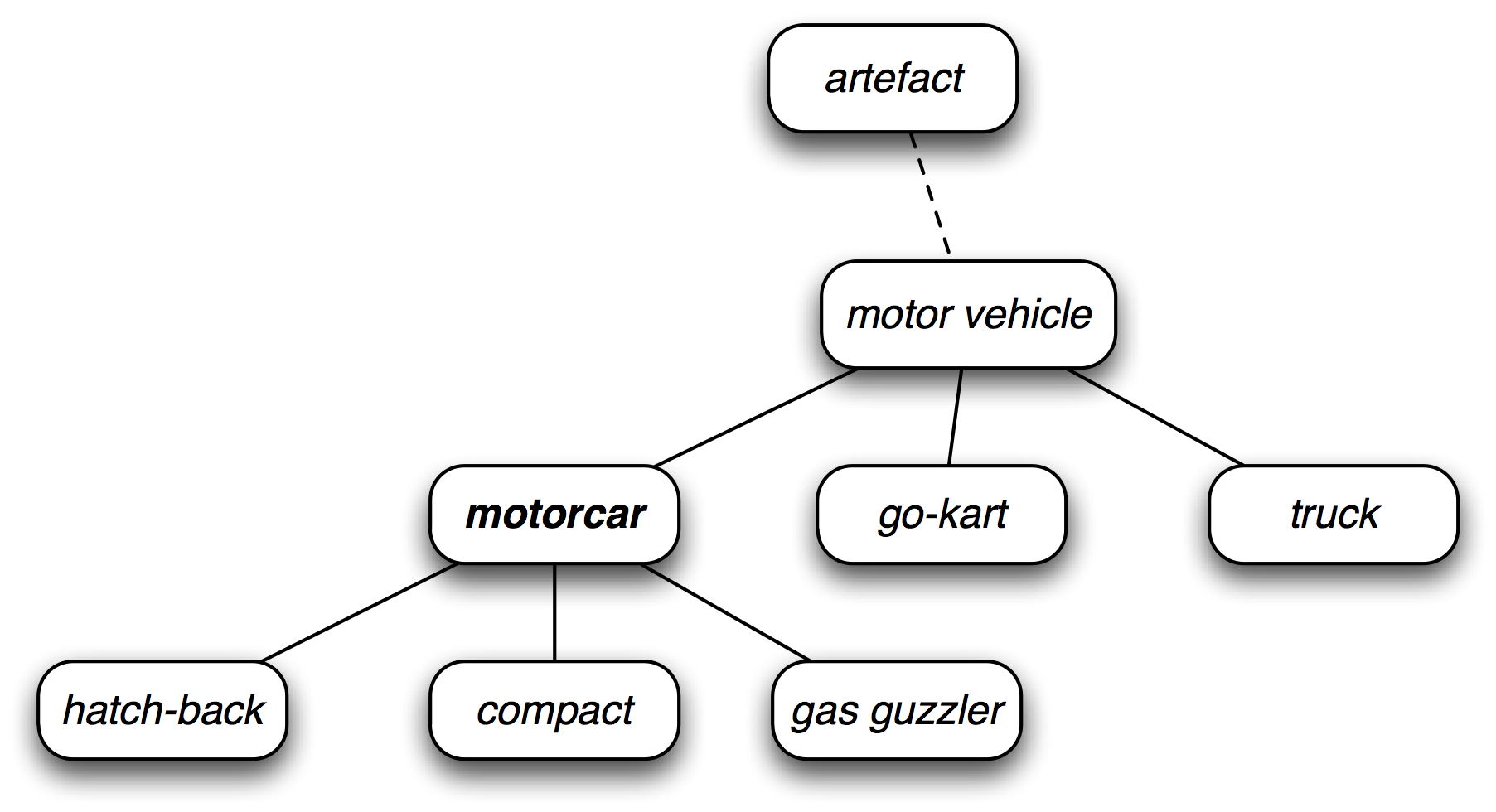
图 5.1:WordNet 概念层次片段:每个节点对应一个同义词集;边表示上位词/下位词关系,即上级概念与从属概念的关系。
WordNet 使在概念之间漫游变的容易。例如:一个如 _motorcar_ 这样的概念,我们可以看到它的更加具体(直接)的概念——下位词。
```py
>>> motorcar = wn.synset('car.n.01')
>>> types_of_motorcar = motorcar.hyponyms()
>>> types_of_motorcar[0]
Synset('ambulance.n.01')
>>> sorted(lemma.name() for synset in types_of_motorcar for lemma in synset.lemmas())
['Model_T', 'S.U.V.', 'SUV', 'Stanley_Steamer', 'ambulance', 'beach_waggon',
'beach_wagon', 'bus', 'cab', 'compact', 'compact_car', 'convertible',
'coupe', 'cruiser', 'electric', 'electric_automobile', 'electric_car',
'estate_car', 'gas_guzzler', 'hack', 'hardtop', 'hatchback', 'heap',
'horseless_carriage', 'hot-rod', 'hot_rod', 'jalopy', 'jeep', 'landrover',
'limo', 'limousine', 'loaner', 'minicar', 'minivan', 'pace_car', 'patrol_car',
'phaeton', 'police_car', 'police_cruiser', 'prowl_car', 'race_car', 'racer',
'racing_car', 'roadster', 'runabout', 'saloon', 'secondhand_car', 'sedan',
'sport_car', 'sport_utility', 'sport_utility_vehicle', 'sports_car', 'squad_car',
'station_waggon', 'station_wagon', 'stock_car', 'subcompact', 'subcompact_car',
'taxi', 'taxicab', 'tourer', 'touring_car', 'two-seater', 'used-car', 'waggon',
'wagon']
```
我们也可以通过访问上位词来浏览层次结构。有些词有多条路径,因为它们可以归类在一个以上的分类中。`car.n.01`与`entity.n.01`间有两条路径,因为`wheeled_vehicle.n.01`可以同时被归类为车辆和容器。
```py
>>> motorcar.hypernyms()
[Synset('motor_vehicle.n.01')]
>>> paths = motorcar.hypernym_paths()
>>> len(paths)
2
>>> [synset.name() for synset in paths[0]]
['entity.n.01', 'physical_entity.n.01', 'object.n.01', 'whole.n.02', 'artifact.n.01',
'instrumentality.n.03', 'container.n.01', 'wheeled_vehicle.n.01',
'self-propelled_vehicle.n.01', 'motor_vehicle.n.01', 'car.n.01']
>>> [synset.name() for synset in paths[1]]
['entity.n.01', 'physical_entity.n.01', 'object.n.01', 'whole.n.02', 'artifact.n.01',
'instrumentality.n.03', 'conveyance.n.03', 'vehicle.n.01', 'wheeled_vehicle.n.01',
'self-propelled_vehicle.n.01', 'motor_vehicle.n.01', 'car.n.01']
```
我们可以用如下方式得到一个最一般的上位(或根上位)同义词集:
```py
>>> motorcar.root_hypernyms()
[Synset('entity.n.01')]
```
注意
**轮到你来:** 尝试 NLTK 中便捷的图形化 WordNet 浏览器:`nltk.app.wordnet()`。沿着上位词与下位词之间的链接,探索 WordNet 的层次结构。
## 5.3 更多的词汇关系
上位词和下位词被称为词汇关系,因为它们是同义集之间的关系。这个关系定位上下为“是一个”层次。WordNet 网络另一个重要的漫游方式是从元素到它们的部件(部分)或到它们被包含其中的东西(整体)。例如,一棵树的部分是它的树干,树冠等;这些都是`part_meronyms()`。一棵树的 _ 实质 _ 是包括心材和边材组成的,即`substance_meronyms()`。树木的集合形成了一个森林,即`member_holonyms()`:
```py
>>> wn.synset('tree.n.01').part_meronyms()
[Synset('burl.n.02'), Synset('crown.n.07'), Synset('limb.n.02'),
Synset('stump.n.01'), Synset('trunk.n.01')]
>>> wn.synset('tree.n.01').substance_meronyms()
[Synset('heartwood.n.01'), Synset('sapwood.n.01')]
>>> wn.synset('tree.n.01').member_holonyms()
[Synset('forest.n.01')]
```
来看看可以获得多么复杂的东西,考虑具有几个密切相关意思的词 mint。我们可以看到`mint.n.04`是`mint.n.02`的一部分,是组成`mint.n.05`的材质。
```py
>>> for synset in wn.synsets('mint', wn.NOUN):
... print(synset.name() + ':', synset.definition())
...
batch.n.02: (often followed by `of') a large number or amount or extent
mint.n.02: any north temperate plant of the genus Mentha with aromatic leaves and
small mauve flowers
mint.n.03: any member of the mint family of plants
mint.n.04: the leaves of a mint plant used fresh or candied
mint.n.05: a candy that is flavored with a mint oil
mint.n.06: a plant where money is coined by authority of the government
>>> wn.synset('mint.n.04').part_holonyms()
[Synset('mint.n.02')]
>>> wn.synset('mint.n.04').substance_holonyms()
[Synset('mint.n.05')]
```
动词之间也有关系。例如,走路的动作包括抬脚的动作,所以走路蕴涵着抬脚。一些动词有多个蕴涵:
```py
>>> wn.synset('walk.v.01').entailments()
[Synset('step.v.01')]
>>> wn.synset('eat.v.01').entailments()
[Synset('chew.v.01'), Synset('swallow.v.01')]
>>> wn.synset('tease.v.03').entailments()
[Synset('arouse.v.07'), Synset('disappoint.v.01')]
```
词条之间的一些词汇关系,如反义词:
```py
>>> wn.lemma('supply.n.02.supply').antonyms()
[Lemma('demand.n.02.demand')]
>>> wn.lemma('rush.v.01.rush').antonyms()
[Lemma('linger.v.04.linger')]
>>> wn.lemma('horizontal.a.01.horizontal').antonyms()
[Lemma('inclined.a.02.inclined'), Lemma('vertical.a.01.vertical')]
>>> wn.lemma('staccato.r.01.staccato').antonyms()
[Lemma('legato.r.01.legato')]
```
你可以使用`dir()`查看词汇关系和同义词集上定义的其它方法,例如`dir(wn.synset('harmony.n.02'))`。
## 5.4 语义相似度
我们已经看到同义词集之间构成复杂的词汇关系网络。给定一个同义词集,我们可以遍历 WordNet 网络来查找相关含义的同义词集。知道哪些词是语义相关的,对索引文本集合非常有用,当搜索一个一般性的用语例如车辆时,就可以匹配包含具体用语例如豪华轿车的文档。
回想一下每个同义词集都有一个或多个上位词路径连接到一个根上位词,如`entity.n.01`。连接到同一个根的两个同义词集可能有一些共同的上位词(见图[5.1](./ch02.html#fig-wn-hierarchy))。如果两个同义词集共用一个非常具体的上位词——在上位词层次结构中处于较低层的上位词——它们一定有密切的联系。
```py
>>> right = wn.synset('right_whale.n.01')
>>> orca = wn.synset('orca.n.01')
>>> minke = wn.synset('minke_whale.n.01')
>>> tortoise = wn.synset('tortoise.n.01')
>>> novel = wn.synset('novel.n.01')
>>> right.lowest_common_hypernyms(minke)
[Synset('baleen_whale.n.01')]
>>> right.lowest_common_hypernyms(orca)
[Synset('whale.n.02')]
>>> right.lowest_common_hypernyms(tortoise)
[Synset('vertebrate.n.01')]
>>> right.lowest_common_hypernyms(novel)
[Synset('entity.n.01')]
```
当然,我们知道,鲸鱼是非常具体的(须鲸更是如此),脊椎动物是更一般的,而实体完全是抽象的一般的。我们可以通过查找每个同义词集深度量化这个一般性的概念:
```py
>>> wn.synset('baleen_whale.n.01').min_depth()
14
>>> wn.synset('whale.n.02').min_depth()
13
>>> wn.synset('vertebrate.n.01').min_depth()
8
>>> wn.synset('entity.n.01').min_depth()
0
```
WordNet 同义词集的集合上定义的相似度能够包括上面的概念。例如,`path_similarity`是基于上位词层次结构中相互连接的概念之间的最短路径在`0`-`1`范围的打分(两者之间没有路径就返回`-1`)。同义词集与自身比较将返回`1`。考虑以下的相似度:露脊鲸与小须鲸、逆戟鲸、乌龟以及小说。数字本身的意义并不大,当我们从海洋生物的语义空间转移到非生物时它是减少的。
```py
>>> right.path_similarity(minke)
0.25
>>> right.path_similarity(orca)
0.16666666666666666
>>> right.path_similarity(tortoise)
0.07692307692307693
>>> right.path_similarity(novel)
0.043478260869565216
```
注意
还有一些其它的相似性度量方法;你可以输入`help(wn)`获得更多信息。NLTK 还包括 VerbNet,一个连接到 WordNet 的动词的层次结构的词典。It can be accessed with `nltk.corpus.verbnet`.
## 6 小结
* 文本语料库是一个大型结构化文本的集合。NLTK 包含了许多语料库,如布朗语料库`nltk.corpus.brown`。
* 有些文本语料库是分类的,例如通过文体或者主题分类;有时候语料库的分类会相互重叠。
* 条件频率分布是一个频率分布的集合,每个分布都有一个不同的条件。它们可以用于通过给定内容或者文体对词的频率计数。
* 行数较多的 Python 程序应该使用文本编辑器来输入,保存为`.py`后缀的文件,并使用`import`语句来访问。
* Python 函数允许你将一段特定的代码块与一个名字联系起来,然后重用这些代码想用多少次就用多少次。
* 一些被称为“方法”的函数与一个对象联系在起来,我们使用对象名称跟一个点然后跟方法名称来调用它,就像:`x.funct(y)`或者`word.isalpha()`。
* 要想找到一些关于某个变量`v`的信息,可以在 Pyhon 交互式解释器中输入`help(v)`来阅读这一类对象的帮助条目。
* WordNet 是一个面向语义的英语词典,由同义词的集合——或称为同义词集——组成,并且组织成一个网络。
* 默认情况下有些函数是不能使用的,必须使用 Python 的`import`语句来访问。
## 7 深入阅读
本章的附加材料发布在`http://nltk.org/`,包括网络上免费提供的资源的链接。语料库方法总结请参阅`http://nltk.org/howto`上的语料库 HOWTO,在线 API 文档中也有更广泛的资料。
公开发行的语料库的重要来源是语言数据联盟((LDC)和欧洲语言资源局(ELRA)。提供几十种语言的数以百计的已标注文本和语音语料库。非商业许可证允许这些数据用于教学和科研目的。其中一些语料库也提供商业许可(但需要较高的费用)。
用于创建标注的文本语料库的好工具叫做 Brat,可从`http://brat.nlplab.org/`访问。
这些语料库和许多其他语言资源使用 OLAC 元数据格式存档,可以通过 `http://www.language-archives.org/`上的 OLAC 主页搜索到。Corpora List 是一个讨论语料库内容的邮件列表,你可以通过搜索列表档案来找到资源或发布资源到列表中。_Ethnologue_ 是最完整的世界上的语言的清单,`http://www.ethnologue.com/`。7000 种语言中只有几十中有大量适合 NLP 使用的数字资源。
本章触及语料库语言学领域。在这一领域的其他有用的书籍包括[(Biber, Conrad, & Reppen, 1998)](./bibliography.html#biber1998), [(McEnery, 2006)](./bibliography.html#mcenery2006), [(Meyer, 2002)](./bibliography.html#meyer2002), [(Sampson & McCarthy, 2005)](./bibliography.html#sampson2005), [(Scott & Tribble, 2006)](./bibliography.html#scott2006)。在语言学中海量数据分析的深入阅读材料有:[(Baayen, 2008)](./bibliography.html#baayen2008), [(Gries, 2009)](./bibliography.html#gries2009), [(Woods, Fletcher, & Hughes, 1986)](./bibliography.html#woods1986)。
WordNet 原始描述是[(Fellbaum, 1998)](./bibliography.html#fellbaum1998)。虽然 WordNet 最初是为心理语言学研究开发的,它目前在自然语言处理和信息检索领域被广泛使用。WordNets 正在开发许多其他语言的版本,在`http://www.globalwordnet.org/`中有记录。学习 WordNet 相似性度量可以阅读[(Budanitsky & Hirst, 2006)](./bibliography.html#budanitsky2006ewb)。
本章触及的其它主题是语音和词汇语义学,读者可以参考[(Jurafsky & Martin, 2008)](./bibliography.html#jurafskymartin2008)的第 7 和第 20 章。
## 8 练习
1. ☼ 创建一个变量`phrase`包含一个词的列表。实验本章描述的操作,包括加法、乘法、索引、切片和排序。
2. ☼ 使用语料库模块处理`austen-persuasion.txt`。这本书中有多少词符?多少词型?
3. ☼ 使用布朗语料库阅读器`nltk.corpus.brown.words()`或网络文本语料库阅读器`nltk.corpus.webtext.words()`来访问两个不同文体的一些样例文本。
4. ☼ 使用`state_union`语料库阅读器,访问 _《国情咨文报告》_ 的文本。计数每个文档中出现的`men`、`women`和`people`。随时间的推移这些词的用法有什么变化?
5. ☼ 考查一些名词的整体部分关系。请记住,有 3 种整体部分关系,所以你需要使用:`member_meronyms()`, `part_meronyms()`, `substance_meronyms()`, `member_holonyms()`, `part_holonyms()`和`substance_holonyms()`。
6. ☼ 在比较词表的讨论中,我们创建了一个对象叫做`translate`,通过它你可以使用德语和意大利语词汇查找对应的英语词汇。这种方法可能会出现什么问题?你能提出一个办法来避免这个问题吗?
7. ☼ 根据 Strunk 和 White 的 _《Elements of Style》_,词 however 在句子开头使用是“in whatever way”或“to whatever extent”的意思,而没有“nevertheless”的意思。他们给出了正确用法的例子:However you advise him, he will probably do as he thinks best.(`http://www.bartleby.com/141/strunk3.html`) 使用词汇索引工具在我们一直在思考的各种文本中研究这个词的实际用法。也可以看 _LanguageLog_ 发布在`http://itre.cis.upenn.edu/~myl/languagelog/archives/001913.html`上的“Fossilized prejudices abou‘t however’”。
8. ◑ 在名字语料库上定义一个条件频率分布,显示哪个 _ 首 _ 字母在男性名字中比在女性名字中更常用(参见[4.4](./ch02.html#fig-cfd-gender))。
9. ◑ 挑选两个文本,研究它们之间在词汇、词汇丰富性、文体等方面的差异。你能找出几个在这两个文本中词意相当不同的词吗,例如在 _《白鲸记》_ 与 _《理智与情感》_ 中的 monstrous?
10. ◑ 阅读 BBC 新闻文章:_UK's Vicky Pollards 'left behind'_ `http://news.bbc.co.uk/1/hi/education/6173441.stm`。文章给出了有关青少年语言的以下统计:“使用最多的 20 个词,包括 yeah, no, but 和 like,占所有词的大约三分之一”。对于大量文本源来说,所有词标识符的三分之一有多少词类型?你从这个统计中得出什么结论?更多相关信息请阅读`http://itre.cis.upenn.edu/~myl/languagelog/archives/003993.html`上的 _LanguageLog_。
11. ◑ 调查模式分布表,寻找其他模式。试着用你自己对不同文体的印象理解来解释它们。你能找到其他封闭的词汇归类,展现不同文体的显著差异吗?
12. ◑ CMU 发音词典包含某些词的多个发音。它包含多少种不同的词?具有多个可能的发音的词在这个词典中的比例是多少?
13. ◑ 没有下位词的名词同义词集所占的百分比是多少?你可以使用`wn.all_synsets('n')`得到所有名词同义词集。
14. ◑ 定义函数`supergloss(s)`,使用一个同义词集`s`作为它的参数,返回一个字符串,包含`s`的定义和`s`所有的上位词与下位词的定义的连接字符串。
15. ◑ 写一个程序,找出所有在布朗语料库中出现至少 3 次的词。
16. ◑ 写一个程序,生成一个词汇多样性得分表(例如词符/词型的比例),如我们在[1.1](./ch01.html#tab-brown-types)所看到的。包括布朗语料库文体的全集 (`nltk.corpus.brown.categories()`)。哪个文体词汇多样性最低(每个类型的标识符数最多)?这是你所期望的吗?
17. ◑ 写一个函数,找出一个文本中最常出现的 50 个词,停用词除外。
18. ◑ 写一个程序,输出一个文本中 50 个最常见的双连词(相邻词对),忽略包含停用词的双连词。
19. ◑ 写一个程序,按文体创建一个词频表,以[1](./ch02.html#sec-extracting-text-from-corpora)节给出的词频表为范例。选择你自己的词汇,并尝试找出那些在一个文体中很突出或很缺乏的词汇。讨论你的发现。
20. ◑ 写一个函数`word_freq()`,用一个词和布朗语料库中的一个部分的名字作为参数,计算这部分语料中词的频率。
21. ◑ 写一个程序,估算一个文本中的音节数,利用 CMU 发音词典。
22. ◑ 定义一个函数`hedge(text)`,处理一个文本和产生一个新的版本在每三个词之间插入一个词`'like'`。
23. ★ **齐夫定律**:_f(w)_ 是一个自由文本中的词 _w_ 的频率。假设一个文本中的所有词都按照它们的频率排名,频率最高的在最前面。齐夫定律指出一个词类型的频率与它的排名成反比(即 _f_ × _r = k_,_k_ 是某个常数)。例如:最常见的第 50 个词类型出现的频率应该是最常见的第 150 个词型出现频率的 3 倍。
1. 写一个函数来处理一个大文本,使用`pylab.plot`画出相对于词的排名的词的频率。你认可齐夫定律吗?(提示:使用对数刻度会有帮助。)所绘的线的极端情况是怎样的?
2. 随机生成文本,如使用`random.choice("abcdefg ")`,注意要包括空格字符。你需要事先`import random`。使用字符串连接操作将字符累积成一个很长的字符串。然后为这个字符串分词,产生前面的齐夫图,比较这两个图。此时你怎么看齐夫定律?
24. ★ 修改例[2.2](./ch02.html#code-random-text)的文本生成程序,进一步完成下列任务:
1. 在一个列表`words`中存储 _n_ 个最相似的词,使用`random.choice()`从列表中随机选取一个词。(你将需要事先`import random`。)
2. 选择特定的文体,如布朗语料库中的一部分或者《创世纪》翻译或者古腾堡语料库中的文本或者一个网络文本。在此语料上训练一个模型,产生随机文本。你可能要实验不同的起始字。文本的可理解性如何?讨论这种方法产生随机文本的长处和短处。
3. 现在使用两种不同文体训练你的系统,使用混合文体文本做实验。讨论你的观察结果。
25. ★ 定义一个函数`find_language()`,用一个字符串作为其参数,返回包含这个字符串作为词汇的语言的列表。使用《世界人权宣言》`udhr`的语料,将你的搜索限制在 Latin-1 编码的文件中。
26. ★ 名词上位词层次的分枝因素是什么?也就是说,对于每一个具有下位词——上位词层次中的子女——的名词同义词集,它们平均有几个下位词?你可以使用`wn.all_synsets('n')`获得所有名词同义词集。
27. ★ 一个词的多义性是它所有含义的个数。利用 WordNet,使用`len(wn.synsets('dog', 'n'))`我们可以判断名词 _dog_ 有 7 种含义。计算 WordNet 中名词、动词、形容词和副词的平均多义性。
28. ★使用预定义的相似性度量之一给下面的每个词对的相似性打分。按相似性减少的顺序排名。你的排名与这里给出的顺序有多接近?[(Miller & Charles, 1998)](./bibliography.html#millercharles1998)实验得出的顺序: car-automobile, gem-jewel, journey-voyage, boy-lad, coast-shore, asylum-madhouse, magician-wizard, midday-noon, furnace-stove, food-fruit, bird-cock, bird-crane, tool-implement, brother-monk, lad-brother, crane-implement, journey-car, monk-oracle, cemetery-woodland, food-rooster, coast-hill, forest-graveyard, shore-woodland, monk-slave, coast-forest, lad-wizard, chord-smile, glass-magician, rooster-voyage, noon-string。
关于本文档...
针对 NLTK 3.0 作出更新。本章来自于 _Natural Language Processing with Python_,[Steven Bird](http://estive.net/), [Ewan Klein](http://homepages.inf.ed.ac.uk/ewan/) 和[Edward Loper](http://ed.loper.org/),Copyright © 2014 作者所有。本章依据 _Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License_ [[http://creativecommons.org/licenses/by-nc-nd/3.0/us/](http://creativecommons.org/licenses/by-nc-nd/3.0/us/)] 条款,与 _ 自然语言工具包 _ [`http://nltk.org/`] 3.0 版一起发行。
本文档构建于星期三 2015 年 7 月 1 日 12:30:05 AEST
