
>[success] # Set
1. `java.util.Set`集合是Collection集合的子集合,与List集合平级,该集合中元素**没有先后放入次序,且不允许重复**
2. 该集合的主要实现类是:`HashSet`类 和 `TreeSet`类以及`LinkedHashSet`类
3. `HashSet`类的底层是采用**哈希表**进行数据管理的
4. `TreeSet`类的底层是采用**红黑树**进行数据管理的
5. `LinkedHashSet`了一个**双向链表**,链表中记录了元素的迭代顺序,也就是元素插入集合中的**先后顺序,因此便于迭代**
>[info] ## 常用方法
* 和 `Collection` 集合中的方法一样
|方法声明 |功能介绍|
|--|--|
|boolean add(E e); |向集合中添加对象|
|boolean addAll(Collection<? extends E> c)|用于将参数指定集合c中的所有元素添加到当前集合中|
|boolean contains(Object o); |判断是否包含指定对象|
|boolean containsAll(Collection<?> c) |判断是否包含参数指定的所有对象|
|boolean retainAll(Collection<?> c) |保留当前集合中存在且参数集合中存在的所有对象|
|boolean remove(Object o); |从集合中删除对象|
|boolean removeAll(Collection<?> c) |从集合中删除参数指定的所有对象|
|void clear(); |清空集合|
|int size();| 返回包含对象的个数|
|boolean isEmpty(); |判断是否为空|
|boolean equals(Object o)| 判断是否相等|
|int hashCode() |获取当前集合的哈希码值|
|Object[] toArray()| 将集合转换为数组|
|Iterator iterator()| 获取当前集合的迭代器|
>[success] # HashSet 使用
~~~
import java.util.Set;
import java.util.HashSet;
import java.util.LinkedHashSet;
public class HashSetTest {
public static void main(String[] args) {
// Set s1 = new HashSet(); // 默认 Object 泛型
Set<String> s1 = new HashSet<>(); // String 泛型
// add 添加元素
boolean b1 = s1.add("two");
System.out.println("b1 = " + b1); // true 添加成功返回true
System.out.println("s1 = " + s1); // [two]
// 从打印结果上可以看到元素没有先后放入次序(表面)
b1 = s1.add("one");
System.out.println("b1 = " + b1); // true
System.out.println("s1 = " + s1); // [one, two] [two, one]
// 验证元素不能重复
b1 = s1.add("one");
System.out.println("b1 = " + b1); // false 元素已经存在返回false
System.out.println("s1 = " + s1); // [one, two]
// 打印有顺序且不重复 LinkedHashSet
Set<String> s2 = new LinkedHashSet<>(); // 将放入的元素使用双链表连接起来
b1 = s2.add("two");
System.out.println("b1 = " + b1); // true 添加成功返回true
System.out.println("s2 = " + s2); // [two]
b1 = s2.add("one");
System.out.println("b1 = " + b1); // true 添加成功返回true
System.out.println("s2 = " + s2); // [two, one]
b1 = s2.add("one");
System.out.println("b1 = " + b1); // false 元素已经存在返回false
}
}
~~~
>[info] ## HashSet集合的原理
1. 使用元素调用hashCode方法获取对应的**哈希码值**,再由某种哈希算法计算出该元素在数组中的**索引位置**。
2. 若该位置没有元素,则将该元素直接放入即可
3. 若该位置有元素,则使用新元素与已有元素依次**比较哈希值**,**若哈希值不相同**,则将该元素直接放入。
4. 若新元素与已有元素的哈希值相同,则使用新元素调用**equals方法与已有元素依次比较**
5. 若相等则添加元素失败,否则将元素直接放入即可
* 哈希表结构
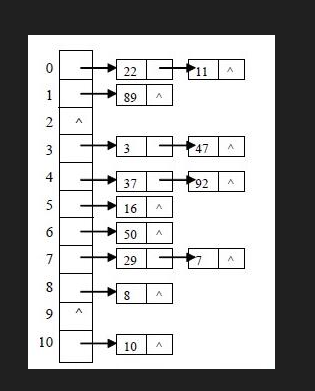
**总结**:当两个元素调用**equals方法相等时证明这两个元素相**同,重写hashCode方法后保证这两个元素得到的哈**希码值相同**,由同一个哈希算法生成的索引位置相同,此时只需要与该索引位置已有元素比较即可,从而**提高效率并避免重复元素的出现**
>[success] # TreeSet
1. **TreeSet集合**的底层采用**红黑树**进行数据的管理,当有新元素插入到TreeSet集合时,需要使用新元素与集合中已有的元素**依次比较来确定新元素的合理位置**
* 红黑树是一种**平衡二叉树**,二叉树主要概念,每个节点最多只有两个子节点的树形结构,**左子树中的任意节点元素都小于根节点元素值,右子树中的任意节点元素都大于根节点元素值**
2. **TreeSet** 遵循红黑树的规则,那么就要去实现其比较的规则书写,这里分两种
* 使用元素的自然排序规则进行比较并排序,让元素类型实现**java.lang.Comparable**接口(String 内部就继承了该接口并实现了 compareTo 方法因此可以从小到大排序)
* 使用比较器规则进行比较并排序,构造TreeSet集合时传入**java.util.Comparator**接口
>[danger] ##### 案例
1. String 内部就继承了**java.lang.Comparable**接口并实现了 `compareTo` 方法因此可以从小到大排序
~~~
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet<String> s1 = new TreeSet<>();
// 添加元素
boolean a1 = s1.add("aa");
System.out.println(a1); // true 添加成功
a1 = s1.add("aa");
System.out.println(a1); // false 已存在添加失败
s1.add("cc");
s1.add("bb");
// TreeSet集合的底层是采用红黑树实现的,因此元素有大小次序,默认从小到大打印
System.out.println(s1); // [aa, bb, cc]
}
}
~~~
>[danger] ##### 自定义类实现**java.lang.Comparable**接口
1. 如果没有去实现自定类中**java.lang.Comparable**接口 直接使用**TreeSet** 打印会提示报错`Exception in thread "main" java.lang.ClassCastException: class cannot be cast to class java.lang.Comparable`
2. Set 是**不允许重复**,因此比较时符合 `compareTo` 规则重复会被忽略
~~~
import java.util.TreeSet;
public class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Person o) {
// return 0; // 调用对象和参数对象相等,调用对象就是新增加的对象
// return -1; // 调用对象小于参数对象
// return 1; // 调用对象大于参数对象
// return this.getName().compareTo(o.getName()); // 比较姓名
// return this.getAge() - o.getAge(); // 比较年龄
// 姓名相同则按照年龄比价
int ia = this.getName().compareTo(o.getName());
return ia == 0 ? this.getAge() - o.getAge() : ia;
}
public static void main(String[] args) {
TreeSet<Person> tp = new TreeSet<>();
Person p = new Person("w", 15);
Person p1 = new Person("e", 10);
Person p2 = new Person("r", 16);
Person p3 = new Person("q", 10);
Person p4 = new Person("q", 10);
tp.add(p);
tp.add(p1);
tp.add(p2);
tp.add(p3);
Boolean b = tp.add(p4);
System.out.print(b); // false
// 自定义类如果没用实现接口 java.lang.Comparable 会报错
// Exception in thread "main" java.lang.ClassCastException: class Person cannot
// be cast to class java.lang.Comparable
System.out.println(tp); // [Person{name='e', age=10}, Person{name='q', age=10}, Person{name='r', age=16}, Person{name='w', age=15}] 重复的比较规则P4 被忽略
}
}
~~~
>[danger] ##### java.util.Comparator 接口形式比较
1. 自定义实现类没有实现接口**java.lang.Comparable**,但通过 `Lambda` 表达式 和`匿名内部类` 作为比较条件参数传入
~~~
import java.util.TreeSet;
import java.util.Comparator;
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public static void main(String[] args) {
// // 准备一个比较器对象作为参数传递给构造方法
// // 匿名内部类: 接口/父类类型 引用变量名 = new 接口/父类类型() { 方法的重写 };
// Comparator<Person> c = new Comparator<Person>() {
// @Override
// public int compare(Person o1, Person o2) { // o1表示新增加的对象 o2表示集合中已有的对象
// return o1.getAge() - o2.getAge(); // 表示按照年龄比较
// }
// };
// 使用从Java8开始支持Lambda表达式: (参数列表) -> { 方法体 }
Comparator<Person> c = (Person o1, Person o2) -> {
return o1.getAge() - o2.getAge();
};
TreeSet<Person> tp = new TreeSet<>(c);
Person p = new Person("w", 15);
Person p1 = new Person("e", 10);
Person p2 = new Person("r", 16);
Person p3 = new Person("q", 10);
Person p4 = new Person("q", 10);
tp.add(p);
tp.add(p1);
tp.add(p2);
tp.add(p3);
tp.add(p4);
/*
* [Person{name='e', age=10}, Person{name='w', age=15}, Person{name='r',
* age=16}]
*/
System.out.println(tp);
}
}
~~~
>[danger] ##### 总结
自然排序的规则比较单一,而比较器的规则比较多元化,而且比较器优先于自然排序
- windows -- 环境变量
- Vscode -- 编写java
- 初始java
- java -- 关键字
- 编写第一个java程序
- java -- 注释
- 计算机存储 -- 进制
- java -- 类型
- java -- 变量
- 数字类型
- 布尔类型
- 字符类型
- 类型转换
- 双等比较是什么
- java -- 运算符
- 算数运算符
- 字符串拼接
- 关系/比较运算符
- 自增减运算符
- 逻辑运算符
- 三目运算
- 赋值运算符
- 移位运算符
- 位运算符
- 运算符优先级
- java -- 流程控制语句
- if /else if /if -- 判断
- switch case分支结构
- for -- 循环
- 用双重for循环
- while -- 循环
- do while -- 循环
- 案例练习
- java -- 数组
- 数组的存储
- 数组的增删改查
- 数组的特点
- 数组案例
- 二维数组
- 数组的工具方法
- java -- 方法
- java -- 方法的重载
- java -- 方法的调用流程
- java -- 类方法传参注意事项
- java -- 方法练习案例
- 对比 return break continue
- for each循环
- java -- 基础练习
- java -- 面向对象
- java -- 创建类和对象
- java -- 访问控制符
- java -- 类成员方法
- java -- 构造方法
- java -- this
- java -- 封装
- java -- 对象内存图
- java -- 创建对象案例
- java -- static
- java -- 继承
- super -- 关键字
- java -- 构造块和静态代码块
- java -- 重写
- java -- final
- java -- 多态
- java -- 抽象类
- java -- 接口
- 引用类型数据转换
- 综合案例
- java -- 内部类
- java -- 回调模式
- java -- 枚举类型
- java -- switch 使用枚举
- java -- 枚举方法使用
- java -- 枚举类实现接口
- java -- javaBean
- java -- package 包
- java -- import
- java -- 递归练习
- java -- 设计模式
- 单例模式
- java -- 注解
- java -- 元注解
- Java -- 核心类库
- java -- 处理字符串
- Java -- String
- String -- 常用方法
- String -- 正则
- Java -- StringBuilder 和 StringBuffer
- 知识点
- Java -- StringJoiner 字符串拼接
- 练习题
- 字符串的总结
- Java -- 包装类
- Integer
- Double
- Boolean
- Character
- java -- 集合类
- java -- util.Collection
- Iterator接口
- java -- util.List
- java -- ArrayList
- java -- util.Queue
- java -- util.Set
- java -- util.Map
- java -- util.Collections
- Java -- Math
- Java -- java.lang
- Java -- Object
- Java -- 获取当前时间戳
- Java -- 异常
- Java -- java.util
- java -- Date
- java -- Calender
- Java -- java.text
- Java -- SimpleDateFormat
- Java -- java.time
- Java -- java.io
- java -- io.File
- java -- 泛型
- IDEA -- 用法