- 消息堆太多内存暴涨
- 用redis mode 实现高可用
> 为什么需要缓存
一般使用目的是通过缓存数据库查询结果,减少数据库访问次数,以提高动态 Web 应用的速度、提高可扩展性。像首页频繁访问的数据,搜索筛选列表以及表格数据,每次都去请求数据库,不仅查询速度慢,频率高的话还会造成阻塞甚至服务宕机. 即使第二次查询数据库会有缓存,但是读写速度还是很难达到 Redis 的十分之一。
> Redis 和 Memcached 对比分析
对于缓存技术,提到最多的是 Redis 和 Memcached,两者都是将数据存放在内存中(内存数据库)。
Memcached 数据结构就一种,add/set 去添加/修改键值对,以及围绕键值对的追加,删除等指令操作,适合缓存大对象数据,列如图片,视频等等。在早些时候是不支持数据持久化的,服务重启会导致缓存数据丢失,在 1.5.18 和之后版本可以在服务重启时恢复缓存数据,新版本还通过 DAX 文件系统挂载来实现缓存持久性功能。
- Tips:在搜索 Memcached 资料时,会出现 Memcache 和 Memcached,用的软件是 Memcached。PHP 在操作 Memcached 时有两个扩展一个是 Memcache,另一个是 Memcached。
Redis 不仅支持简单的 k/v 类型的数据,同时还支持 list、set、zset、sorted set、hash 等数据结构的存储和 Redis Modules 实现自己的数据类型,使得它拥有更广阔的应用场景。
> 数据结构
Redis 有五种基本数据结构,分别是字符串(String)、 哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)。高级数据结构 HyperLogLog 用来做基数统计的算法,GEO 将用户给定的地理位置(经度和纬度)信息储存起来,并对这些信息进行操作,pub/sub 发布订阅的通信模式。另外还可以用 Redis Modules 外部模块进行功能性扩展,像 BloomFilter(布隆过滤器),RediSearch(搜索引擎),Redis-ML(机器学习)……
- 更多模块:[https://redis.io/modules](https://redis.io/modules)
- [Redis 数据结构应用场景](https://www.cnblogs.com/pangzizhe/tag/Redis/)
> 有序集合、消息队列、延迟队列、订阅模式
Redis 使用双向链表实现 List 数据结构,可以在列表的头部(左边)或者尾部(右边)添加或移除元素(LPush RPush LPop RPop)我们可以用 List 模拟出 栈,有限集合,队列,消息队列。
~~~
RPush + RPop = Statck (栈) //当然用 LPush + LPop 也是可以的, 符合先进先去
RPush + RTrim = Capped Collection(有限集合)
RPush + LPop = Queue(队列)
//RPush 生成消息, LPop 消费消息, 在没有消息的时候需要 Sleep 一会再重试
//BLPop 在没有消息的时候,它会阻塞主直到有消息来
RPush + BLPop = Message Queue(消息队列)
~~~
延迟队列是用 SortedSet 数据结构模拟的,时间戳作为 Score,消息的内容作为 Key,调用 Zadd 来生成消息,消费者使用 ZRangeByScore 指令获取 N 秒之前的数据今夕处理,处理完后再获取 N+M 下一个时间段数据进行处理。Redis 发布订阅是实时消费的,服务端不会保存生产的消息,也不会记录客户端消费到哪一条。如果客户端宕机,消息就会丢失。这时就需要用到高级的消息队列,如 RocketMQ、Kafka 等。
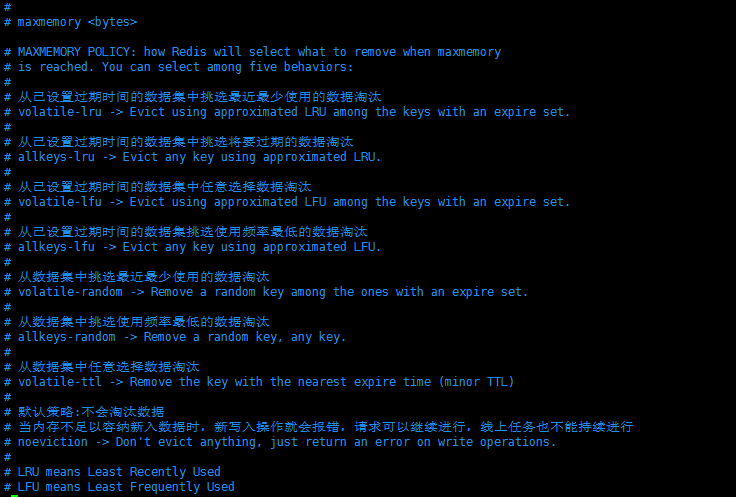
> 内存淘汰策略
Redis 的内存淘汰策略有八种,默认策略是不会淘汰数据,当内存不足以容纳新入数据时,新写入操作就会报错,要修改的数据比原来大很多也是会报错的,但是查询类请求可以正常操作。
前面根据策略选出要淘汰的 key,这时还没有删除 Key,相当于给 Key 做了个标记。对于 Key 的删除,Redis 有三种策略,如下:
* 定时删除:在创建 Key 的时候,设置了 Key 的过期时间(一过期就删除,内存占用时间少,但定时器的创建需要占用更多 CPU 时间)
* 定期删除:每隔一顿时间去删除标记过的 Key
* 惰性删除:Key 标记完后不去管它, 每次获取 Key 的时候再去检查它是否有标记,有就删除,返回 null
> * 内存占用时间:定时 < 定期 < 惰性
> * CPU 占用时间:定时 > 定期 > 惰性
定时删除是主动设置的。在删除标记 Key 方面,Redis 是同时使用了惰性删除和定期删除。另外 Redis 中的淘汰机制是从性能和可用性方面考虑的,并不是完全可靠,我们在开发中应尽量对不需要永久保存的数据主动设置或更新 key 的过期时间。通过主动删除这部分数据,来提升 Redis 整体性能和空间。
> 缓存雪崩、击穿、穿透
Redis 缓存雪崩、击穿、穿透造成的主要原因是在高并发下绕过 Redis 直接请求数据库造成的。如果本身不加缓存,数据库都扛得了,现先加上 Redis 提高性能,这样是不会造成缓存雪崩、击穿、穿透的。
缓存雪崩是因为在设置 Key 的时候加了过期时间,并且这些 Key 的过期时间是一样的。在某一时间点,这些 Key 都过期了,在高并发请求的时候,发现 Key 不存在,就会直接打在数据库上,数据库支撑不了而崩溃。多个服务的缓存同时过期,每一个服务就像一个雪球在那里滚,最终造成缓存雪崩。解决方案是给 Key 设置过期时间的时候再加个随机值,保证同一时间缓存不会大面积失效。或者设置这些热点数据的 Key 永不过期,当数据发生变化的时候再去主动更新缓存。
缓存击穿和缓存雪崩类似,缓存雪崩说的多个热点 Key 过期,而缓存击穿说的是一个热点 Key 过期。缓存雪崩是造成大面积缓存失效,基本上是所有服务都不能用了。缓存击穿只是对某个服务或某个功能用到这个 Key 的访问异常。解决的方案是设置热点数据的 Key 永不过期,数据发生变化的时候再去主动更新缓存。
缓存穿透式是用户不断发送请求数据库中不存在的数据,数据库都没有的数据,Redis 也不会有,就可以绕过 Redis,直接访问数据库,导致数据库压力过大,甚至击垮数据库。解决方案是增加参数校验或者用 BloomFilter(布隆过滤器),利用高效的数据结构和算法快速判断这个 Key 是否存在数据库中。
> 数据持久化 RDB 和 AOF 以及机器断电对数据的影响
Redis 支持两种持久化方式: 全量模式 RDB 冷备份(Snapshot 内存快照)和 增量模式 AOF 热备份(append only file 文件追加)
RDB 是默认的持久化方式,按照配置里的策略将内存中的数据生成快照保存到磁盘。自动触发时 Redis 主进程会 fork 一个子进程将数据保存到 RDB 文件中,同步完数据之后,对原文件进行替换,然后通知主进程完成同步。如下图,Redis 默认是 900 秒内有 1 个 key 发送变化或 300 秒内有 10 个 key 发生变化或者 60 秒内有 1W 个 key 发生变化就会触发机制。在只开启 RDB 情况下服务宕机了,最多只会丢失 15 分钟数据,不超过 1W 个 Key 的修改。这时候如果想重启 Redis 服务,又不想丢失数据,可以手动执行 save 或 bgsave 命令触发机制。其中 save 命令是阻塞的,bgsave 和 自动触发一样会 fork 一个子进程将数据保存到 RDB 文件中。

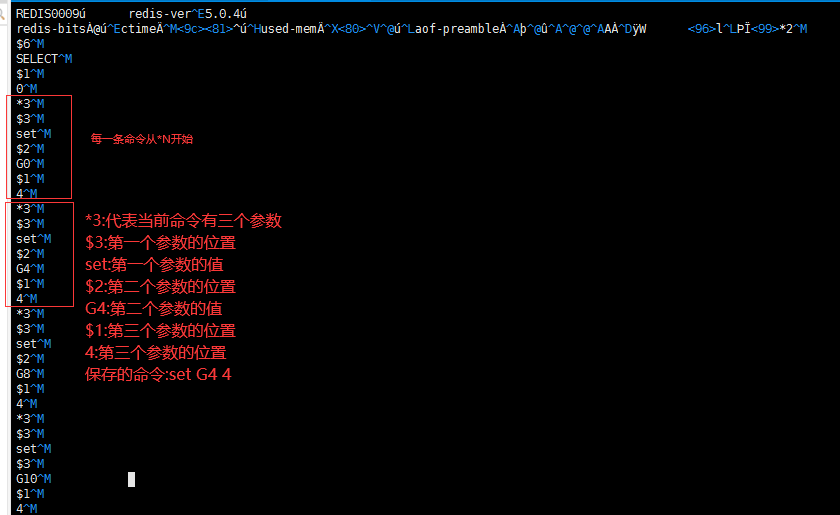
AOF 默认是不开启的,在启动时 Redis 会将每一个收到的修改命令通过 Write 函数追加到文件最后,追加的数据如下图 1。写入的频率一般设置成每秒写一次(如下图 2),如果 Redis 宕机了,最多就丢失 1 秒的数据。如果设置成每条命令执行一次写入,就只会丢失一条命令,但写入太频繁从而影响性能。Redis 实例在跑一段时间后,AOF 可能增加到几百 M,甚至几个 G。有些操作命令是对某个 key 频繁操作,关一个 Key 就增加了几十 M 数据。这时可以配置 auto-aof-rewrite-min-size 当达到某个阀值自动重写或手动执行 bgrewriteaof 命令执行重写。重写的时候关于这个 Key 的几十 M 数据最终会被重写成这个 key 最新一个值的命令。

RDB 文件小,适合定时备份,用于灾难恢复。因为 RDB 文件存储的是内存数据,而 AOF 文件存储的是一条条命。在恢复的时候,Redis 加载 RDB 文件的速度比 AOF 快很多。一般在使用的过程中 RDB 和 AOF 两个都是开启的,如果 Redis 宕机了,在恢复的时候先用 RDB 的最后一个备份实例,再用 AOF 去逐条更新最近的数据。开启混合模式时,AOF 文件内容如下如图:

> Redis Sentinel 和 Redis Cluster
Redis Sentinel(哨兵模式)是 Redis 官方推荐的高可用方案,当 Master 宕机时会自动将 Slave 提升为 Master,从而继续提供服务。如下表格,我们只需要连接 Sentinel 就可有去访问 Redis 服务。Sentinel 会去监控这三台 Redis,当主的 Redis 宕机后,会从可用的 Slave 里选举出新的 Master。当然 Sentinel 服务也有可能宕机,所以要配置多台。
| 服务类型 | IP 地址 | 端口 |
| --- | --- | --- |
| Redis | 192.168.1.170 | 6379 |
| Redis | 192.168.1.171 | 6379 |
| Redis | 192.168.1.172 | 6379 |
| Sentinel | 192.168.1.170 | 26379 |
| Sentinel | 192.168.1.171 | 26379 |
| Sentinel | 192.168.1.172 | 26379 |
在使用的过程中,业务不断的增加,这就不可避免需要对 Redis 进行扩容。扩容的方式有两种分别是垂直扩容和水平扩容,垂直扩容是通过加内存方式来增加整个缓存体系的容量比,但是机器的内存是有限的,不能一直增加。水平扩容是通过增加 Redis 机器数来增加整个缓存体系的容量。Redis Sentinel 对于水平扩容是个难点,针对这个问题,Redis Cluster 就应运而生。
Redis Cluster 是 Redis 的分布式解决方案,采用哈希划分槽到每一个 Redis 服务。Redis Cluster 槽的范围是 0~16383,所有的 Key 根据哈希函数映射到 0~16383,计算公式是:
~~~
slot = CRC16(key)&16383
~~~
如下文本内容是 Redis Cluster 的创建过程,六台 Redis 机器三主三从。三台主的 Slots 区间分别是 0~5460、5461~10922、10923~16383。在操作 Key 的时候,会算出这个 Key 对应的 slot,在从对应 slot 区间的 Master 服务里存取数据。
~~~
[root@VM_0_17_centos redis-5.0.4]# /usr/local/redis-5.0.4/src/redis-cli --cluster create 127.0.0.1:8001 127.0.0.1:8002 127.0.0.1:8003 127.0.0.1:8004 127.0.0.1:8005 127.0.0.1:8006 --cluster-replicas 1c
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:8005 to 127.0.0.1:8001
Adding replica 127.0.0.1:8006 to 127.0.0.1:8002
Adding replica 127.0.0.1:8004 to 127.0.0.1:8003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: bb5a9dc1bacad9ded849c2c6293e8569c39a9946 127.0.0.1:8001
slots:[0-5460] (5461 slots) master
M: 075b6e5666712947871bfffdd49208ad7ca700ec 127.0.0.1:8002
slots:[5461-10922] (5462 slots) master
M: ead7c5022960fbb157f512bc9059f32d724d2d2c 127.0.0.1:8003
slots:[10923-16383] (5461 slots) master
S: 47ab708ffb95ccfb2981e72ccd0e7e077801305b 127.0.0.1:8004
replicates 075b6e5666712947871bfffdd49208ad7ca700ec
S: 9249c68d60568378e877d579539e940d7b2c0dda 127.0.0.1:8005
replicates ead7c5022960fbb157f512bc9059f32d724d2d2c
S: 5071a01e39deead8d42a0812388d0b5a2697fa28 127.0.0.1:8006
replicates bb5a9dc1bacad9ded849c2c6293e8569c39a9946
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
....
>>> Performing Cluster Check (using node 127.0.0.1:8001)
M: bb5a9dc1bacad9ded849c2c6293e8569c39a9946 127.0.0.1:8001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 075b6e5666712947871bfffdd49208ad7ca700ec 127.0.0.1:8002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 5071a01e39deead8d42a0812388d0b5a2697fa28 127.0.0.1:8006
slots: (0 slots) slave
replicates bb5a9dc1bacad9ded849c2c6293e8569c39a9946
S: 9249c68d60568378e877d579539e940d7b2c0dda 127.0.0.1:8005
slots: (0 slots) slave
replicates ead7c5022960fbb157f512bc9059f32d724d2d2c
M: ead7c5022960fbb157f512bc9059f32d724d2d2c 127.0.0.1:8003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 47ab708ffb95ccfb2981e72ccd0e7e077801305b 127.0.0.1:8004
slots: (0 slots) slave
replicates 075b6e5666712947871bfffdd49208ad7ca700ec
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@VM_0_17_centos redis-5.0.4]#
~~~
> 操作集群有时能成功, 有时出现类似 MOVED 6373 127.0.0.1:8002 错误
在连接 Redis Cluste 集群的时候, 如果是用单机 Redis 的连接方式去操作是不会报错的, 但是你要操作的这个 Key 算出来的 slot 不属于这台单机的 Redis 的 slot 区间时, 会提示类似 MOVED 6373 127.0.0.1:8002 错误,6373 是这个 key 算出来的 slot 值,对应的 Redis 机器是 127.0.0.1:8002。如果算出来的 slot 值属于当前 Redis 则操作成功。另外从的只负责同步数据,往这个 Key 对应的 slot 的从数据库写入数据也是会提示错误的。
> 总结
在部署 Redis Cluster 开了六个 Redis 实例,三主三从交叉配对在三台服务器上。三对主从实例,只要不是同一对主从 Redis 实例都挂了,服务可以正常运行。代码连接 Redis 时,填了六台 Redis 的地址。当然填一台也是可以的,因为可以从这一台 Redis 里获取到集群 Redis 主从信息和 slot。要是刚好你配的这一台 Redis 宕机了,你就连不上 Redis 了,集群是可以正常提供服务的。
有一段时间我在困惑是不是 Redis Sentinel 和 Redis Cluste 要搭配使用,这样代码就可以通过一个哨兵 IP 地址去访问六 Redis 服务。NO,NO,NO,这是两种模式,不能配合使用的。我动手试了下,配置完后 Redis 服务启动不了了,有个配置项冲突了。Redis Sentinal 需要设置 cluster-enabled no,Redis Cluster 需要设置 cluster-enabled yes。而且就算你配置成功了,一台哨兵有可能宕机,作为高可用你还得配置多台哨兵,然后在代码上用哨兵的连接方式写上多台哨兵的地址,那还不是一样要陪多台 IP。如果想要连接的时候只配置一个 IP 地址,可以用虚拟 VIP+Keeplived+Haproxy 的方式,但是虚拟 IP 不是所有云服务器运营商都由提供,但是一般会提供收费的负载均衡 SLB 服务
总的来说 Redis Sentinel 通过哨兵确保高可用,Redis Cluster 通过 slot 分配确保高并发,内置哨兵机制,主的宕机了会自动切换到从,所以也是高可用。
