> 蒙惠者虽知其然,而未必知其所以然也。
写了这么多,必须证明一下本书并不是一份乏味的使用文档,我们来深入看看Sea.js,搞清楚它时如何工作的吧!
## CMD规范
要想了解Sea.js的运作机制,就不得不先了解其CMD规范。
Sea.js采用了和Node相似的CMD规范,我觉得它们应该是一样的。使用require、exports和module来组织模块。但Sea.js比起Node的不同点在于,前者的运行环境是在浏览器中,这就导致A依赖的B模块不能同步地读取过来,所以Sea.js比起Node,除了运行之外,还提供了两个额外的东西:
1. 模块的管理
2. 模块从服务端的同步
即Sea.js必须分为模块加载期和执行期。加载期需要将执行期所有用到的模块从服务端同步过来,在再执行期按照代码的逻辑顺序解析执行模块。本身执行期与node的运行期没什么区别。
所以Sea.js需要三个接口:
1. define用来wrapper模块,指明依赖,同步依赖;
2. use用来启动加载期;
3. require关键字,实际上是执行期的桥梁。
> 并不太喜欢Sea.js的use API,因为其回调函数并没有使用与Define一样的参数列表。
#### 模块标识(id)
模块id的标准参考[Module Identifiers](http://wiki.commonjs.org/wiki/Modules/1.1.1#Module_Identifiers),简单说来就是作为一个模块的唯一标识。
出于学习的目的,我将它们翻译引用在这里:
1. 模块标识由数个被斜杠(/)隔开的词项组成;
2. 每次词项必须是小写的标识、“.”或“..”;
3. 模块标识并不是必须有像“.js”这样的文件扩展名;
4. 模块标识不是相对的,就是顶级的。相对的模块标识开头要么是“.”,要么是“..”;
5. 顶级标识根据模块系统的基础路径来解析;
6. 相对的模块标识被解释为相对于某模块的标识,“require”语句是写在这个模块中,并在这个模块中调用的。
#### 模块(factory)
顾名思义,factory就是工厂,一个可以产生模块的工厂。node中的工厂就是新的运行时,而在Sea.js中(Tea.js中也同样),factory就是一个函数。这个函数接受三个参数。
~~~
function (require, exports, module) {
// here is module body
}
~~~
在整个运行时中只有模块,即只有factory。
#### 依赖(dependencies)
依赖就是一个id的数组,即模块所依赖模块的标识。
## 依赖加载的原理
有很多语言都有模块化的结构,比如c/c++的`#include`语句,Ruby的`require`语句等等。模块的执行,必然需要其依赖的模块准备就绪才能顺利执行。
c/c++是编译语言,在预编译时,替换`#include`语句,将依赖的文件内容包含进来,在编译后的执行期,所有的模块才会开始执行;
而Ruby是解释型语言,在模块执行前,并不知道它依赖什么模块,待到执行到`require`语句时,执行将暂停,从外部读取并执行依赖,然后再回来继续执行当前模块。
JavaScript作为一门解释型语言,在复杂的浏览器环境中,Sea.js是如何处理CMD模块间的依赖的呢?
## node的方式-同步的`require`
想要解释这个问题,我们还是从Node模块说起,node于Ruby类似,用我们之前使用过的一个模块作为例子:
~~~
// File: usegreet.js
var greet = require("./greet");
greet.helloJavaScript();
~~~
当我们使用`node usegreet.js`来运行这个模块时,实际上node会构建一个运行的上下文,在这个上下文中运行这个模块。运行到`require('./greet')`这句话时,会通过注入的API,在新的上下文中解析greet.js这个模块,然后通过注入的`exports`或`module`这两个关键字获取该模块的接口,将接口暴露出来给usegreet.js使用,即通过`greet`这个对象来引用这些接口。例如,`helloJavaScript`这个函数。详细细节可以参看node源码中的[module.js](https://github.com/joyent/node/blob/master/lib/module.js)。
node的模块方案的特点如下:
1. 使用require、exports和module作为模块化组织的关键字;
2. 每个模块只加载一次,作为单例存在于内存中,每次require时使用的是它的接口;
3. require是同步的,通俗地讲,就是node运行A模块,发现需要B模块,会停止运行A模块,把B模块加载好,获取的B的接口,才继续运行A模块。如果B模块已经加载到内存中了,当然require B可以直接使用B的接口,否则会通过fs模块化同步地将B文件内存,开启新的上下文解析B模块,获取B的API。
实际上node如果通过fs异步的读取文件的话,require也可以是异步的,所以曾经node中有require.async这个API。
## Sea.js的方式-加载期与执行期
由于在浏览器端,采用与node同样的依赖加载方式是不可行的,因为依赖只有在执行期才能知道,但是此时在浏览器端,我们无法像node一样直接同步地读取一个依赖文件并执行!我们只能采用异步的方式。于是Sea.js的做法是,分成两个时期——加载期和执行期;
> 的确,我们可以使用同步的XHR从服务端加载依赖,但是本身就是单进程的JavaScript还需要等待文件的加载,那性能将大打折扣。
* **加载期**:即在执行一个模块之前,将其直接或间接依赖的模块从服务器端同步到浏览器端;
* **执行期**:在确认该模块直接或间接依赖的模块都加载完毕之后,执行该模块。
### 加载期
不难想见,模块间的依赖就像一棵树。启动模块作为根节点,依赖模块作为叶子节点。下面是pixelegos的依赖树:
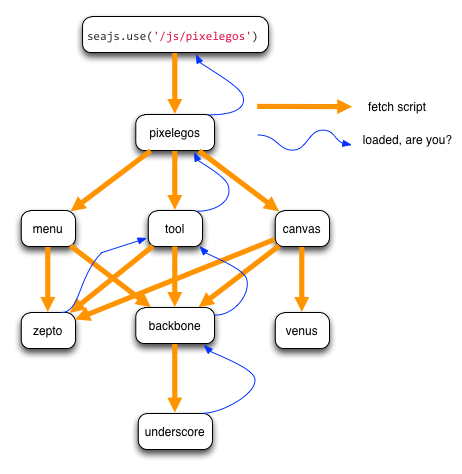
如上图,在页面中通过`seajs.use('/js/pixelegos')`调用,目的是执行pixelegos这个模块。Sea.js并不知道pixelegos还依赖于其他什么模块,只是到服务端加载pixelegos.js,将其加载到浏览器端之后,通过分析发现它还依赖于其他的模块,于是Sea.js又去加载其他的模块。随着更多的模块同步到浏览器端后,一棵依赖树才慢慢地通过递归显现出来。
> 那Sea.js如何确定pixelegos所有依赖的模块都加载好了呢?
从依赖树中可以看出,如果pixelegos.js所依赖的直接子节点加载好了(此种加载好,即为节点和其依赖的子节点都加载好),那就表示它就加载好了,于是就可以启动该模块。明显,这种加载完成的过程也是一个递归的过程。
从最底层的叶子节点开始(例如undercore),由于没有再依赖于其他模块,所以它从服务端同步过来之后,就加载好了。然后开始询问其父节点backbone是否已经加载好了,即询问backbone所依赖的所有节点都加载好了。同理对于pixelegos模块,其子节点menu、tool、canvas都会询问pixelegos其子节点加载好了没有。
如果三个依赖都已loading完毕,则pixelgos也加载完成,即其整棵依赖树都加载好了,然后就可以启动pixelegos这个模块了。
### 执行期
在执行期,执行也是从根节点开始,本质上是按照代码的顺序结构,对整棵树进行了遍历。有的模块可能已经EXECUTED,而有的还需要执行获取其exports。由于在执行期时,所有依赖的模块都加载好了,所以与node执行过程有点类似。
pixelegos通过同步的require函数获取tool、canvas和menu,后三者同样通过require来执行各自的依赖模块,于是通过这样一个递归的过程,pixelegos就执行完毕了。
## 打包模块的加载过程
在Sea.js中,为了支持模块的combo,存在一个js文件包含多个模块的情况。根据依赖情况,使用grunt-cmd-concat可以将一个模块以及其依赖的子模块打包成一个js文件。
打包的方式有三种,self,relative和all。
* self,只是自己做了transport
* relative,将多有相对路径的模块transport,concat
* all,包括相对路径模块和库模块(即在`seajs-modules`文件夹中的),transport,concat
例如,我们`seajs.use('/dist/pixelegos')`,解析为需要加载`http://127.0.0.1:81/dist/pixelegos.js`这个文件,且这个文件是all全打包的。其加载过程如下:
#### 加载方式
1. 在use时,定义一个匿名的`use_`模块,依赖于`/dist/pixelegos`模块,匿名的`use_`模块`load`依赖,开始加载`http://127.0.0.1:81/dist/pixelegos.js`模块;
2. `http://127.0.0.1:81/dist/pixelegos.js`加载执行,所有打包在里面的模块被`define`;
3. `http://127.0.0.1:81/dist/pixelegos.js`的`onload`回调执行,调用`/dist/pixelegos`模块的load,加载其依赖模块,但依赖的模块都加载好了;
4. 通知匿名的`use_`加载完成,开始执行期。
针对每一次执行期,对应的加载依赖树与整个模块依赖树是有区别的,因为子模块已经加载好了的模块,并不在加载树中。
## Sea.js的实现
### 模块的状态
由于浏览器端与Node的环境差异,模块存在加载期和执行期,所以Sea.js中为模块定义了六种状态。
~~~
var STATUS = Module.STATUS = {
// 1 - The `module.uri` is being fetched
FETCHING: 1,
// 2 - The meta data has been saved to cachedMods
SAVED: 2,
// 3 - The `module.dependencies` are being loaded
LOADING: 3,
// 4 - The module are ready to execute
LOADED: 4,
// 5 - The module is being executed
EXECUTING: 5,
// 6 - The `module.exports` is available
EXECUTED: 6
}
~~~
分别为:
* FETCHING:开始从服务端加载模块
* SAVED:模块加载完成
* LOADING:加载依赖模块中
* LOADED:依赖模块加载完成
* EXECUTING:模块执行中
* EXECUTED:模块执行完成
[module.js](https://github.com/seajs/seajs/blob/master/src/module.js)是Sea.js的核心,我们来看一下,module.js是如何控制模块加载过程的。
### 如何确定整个依赖树加载好了呢?
1. 定义A模块,如果有模块依赖于A,把该模块加入到等待A的模块队列中;
2. 加载A模块,状态变为FETCHING
3. A加载完成,获取A模块依赖的BCDEFG模块,发现B模块没有定义,而C加载中,D自己已加载好,E加载子模块中,F加载完成,运行中,G已经解析好,SAVED;
4. 由于FG本身以及子模块都已加载好,因此A模块要确定已经加载好了,必须等待BCDE加载好;开始加载必须的子模块,LOADING;
5. 针对B重复步骤1;
6. 将A加入到CDE的等待队列中;
7. BCDE加载好之后都会从自己的等待队列中取出等待自己加载好的模块,通知A自己已经加载好了;
8. A每次收到子模块加载好的通知,都看一遍自己依赖的模块是否状态都变成了加载完成,如果加载完成,则A加载完成,A通知其等待队列中的模块自己已加载完成,LOADED;
### 加载过程
* Sea.use调用Module.use构造一个没有factory的模块,该模块即为这个运行期的根节点。
~~~
// Use function is equal to load a anonymous module
Module.use = function (ids, callback, uri) {
var mod = Module.get(uri, isArray(ids) ? ids: [ids])
mod.callback = function () {
var exports = []
var uris = mod.resolve()
for (var i = 0, len = uris.length; i < len; i++) {
exports[i] = cachedMods[uris[i]].exec()
}
if (callback) {
callback.apply(global, exports)
}
delete mod.callback
}
mod.load()
}
~~~
模块构造完成,则调用mod.load()来同步其子模块;直接跳过fetching这一步;mod.callback也是Sea.js不纯粹的一点,在模块加载完成后,会调用这个callback。
* 在load方法中,获取子模块,加载子模块,在子模块加载完成后,会触发mod.onload():
~~~
// Load module.dependencies and fire onload when all done
Module.prototype.load = function () {
var mod = this
// If the module is being loaded, just wait it onload call
if (mod.status >= STATUS.LOADING) {
return
}
mod.status = STATUS.LOADING
// Emit `load` event for plugins such as combo plugin
var uris = mod.resolve()
emit("load", uris)
var len = mod._remain = uris.length
var m
// Initialize modules and register waitings
for (var i = 0; i < len; i++) {
m = Module.get(uris[i])
if (m.status < STATUS.LOADED) {
// Maybe duplicate
m._waitings[mod.uri] = (m._waitings[mod.uri] || 0) + 1
}
else {
mod._remain--
}
}
if (mod._remain === 0) {
mod.onload()
return
}
// Begin parallel loading
var requestCache = {}
for (i = 0; i < len; i++) {
m = cachedMods[uris[i]]
if (m.status < STATUS.FETCHING) {
m.fetch(requestCache)
}
else if (m.status === STATUS.SAVED) {
m.load()
}
}
// Send all requests at last to avoid cache bug in IE6-9\. Issues#808
for (var requestUri in requestCache) {
if (requestCache.hasOwnProperty(requestUri)) {
requestCache[requestUri]()
}
}
}
~~~
模块的状态是最关键的,模块状态的流转决定了加载的行为;
* 是否触发onload是由模块的_remian属性来确定,在load和子模块的onload函数中都对_remain进行了计算,如果为0,则表示模块加载完成,调用onload:
~~~
// Call this method when module is loaded
Module.prototype.onload = function () {
var mod = this
mod.status = STATUS.LOADED
if (mod.callback) {
mod.callback()
}
// Notify waiting modules to fire onload
var waitings = mod._waitings
var uri, m
for (uri in waitings) {
if (waitings.hasOwnProperty(uri)) {
m = cachedMods[uri]
m._remain -= waitings[uri]
if (m._remain === 0) {
m.onload()
}
}
}
// Reduce memory taken
delete mod._waitings
delete mod._remain
}
~~~
模块的_remain和_waitings是两个非常关键的属性,子模块通过_waitings获得父模块,通过_remain来判断模块是否加载完成。
* 当这个没有factory的根模块触发onload之后,会调用其方法callback,callback是这样的:
~~~
mod.callback = function () {
var exports = []
var uris = mod.resolve()
for (var i = 0, len = uris.length; i < len; i++) {
exports[i] = cachedMods[uris[i]].exec()
}
if (callback) {
callback.apply(global, exports)
}
delete mod.callback
}
~~~
这预示着加载期结束,开始执行期;
* 而执行期相对比较无脑,首先是直接调用根模块依赖模块的exec方法获取其exports,用它们来调用use传经来的callback。而子模块在执行时,都是按照标准的模块解析方式执行的:
~~~
// Execute a module
Module.prototype.exec = function () {
var mod = this
// When module is executed, DO NOT execute it again. When module
// is being executed, just return `module.exports` too, for avoiding
// circularly calling
if (mod.status >= STATUS.EXECUTING) {
return mod.exports
}
mod.status = STATUS.EXECUTING
// Create require
var uri = mod.uri
function require(id) {
return Module.get(require.resolve(id)).exec()
}
require.resolve = function (id) {
return Module.resolve(id, uri)
}
require.async = function (ids, callback) {
Module.use(ids, callback, uri + "_async_" + cid())
return require
}
// Exec factory
var factory = mod.factory
var exports = isFunction(factory) ? factory(require, mod.exports = {},
mod) : factory
if (exports === undefined) {
exports = mod.exports
}
// Emit `error` event
if (exports === null && ! IS_CSS_RE.test(uri)) {
emit("error", mod)
}
// Reduce memory leak
delete mod.factory
mod.exports = exports
mod.status = STATUS.EXECUTED
// Emit `exec` event
emit("exec", mod)
return exports
}
~~~
> 看到这一行代码了么?`var exports = isFunction(factory) ? factory(require, mod.exports = {}, mod) : factory` 真的,整个Sea.js就是为了这行代码能够完美运行
### 资源定位
资源定位是Sea.js,或者说模块加载器中非常关键部分。那什么是资源定位呢?
资源定位与模块标识相关,而在Sea.js中有三种模块标识。
#### 普通路径
普通路径与网页中超链接一样,相对于当前页面解析,在Sea.js中,普通路径包有以下几种:
~~~
// 假设当前页面是 http://example.com/path/to/page/index.html
// 绝对路径是普通路径:
require.resolve('http://cdn.com/js/a');
// => http://cdn.com/js/a.js
// 根路径是普通路径:
require.resolve('/js/b');
// => http://example.com/js/b.js
// use 中的相对路径始终是普通路径:
seajs.use('./c');
// => 加载的是 http://example.com/path/to/page/c.js
seajs.use('../d');
// => 加载的是 http://example.com/path/to/d.js
~~~
#### 相对标识
在define的factory中的相对路径(`..` `.`)是相对标识,相对标识相对当前的URI来解析。
~~~
// File http://example.com/js/b.js
define(function(require) {
var a = require('./a');
a.doSomething();
});
// => 加载的是http://example.com/js/a.js
~~~
这与node模块中相对路径的解析一致。
#### 顶级标识
不以`.`或者'/'开头的模块标识是顶级标识,相对于Sea.js的base路径来解析。
~~~
// 假设 base 路径是:http://example.com/assets/
// 在模块代码里:
require.resolve('gallery/jquery/1.9.1/jquery');
// => http://example.com/assets/gallery/jquery/1.9.1/jquery.js
~~~
> 在node中即是在paths中搜索模块(node_modules文件夹中)。
#### 模块定位小演
使用seajs.use启动模块,如果不是顶级标识或者是绝对路径,就是相对于页面定位;如果是顶级标识,就从Sea.js的模块系统中加载(即base);如果是绝对路径,直接加载; 之后的模块加载都是在define的factory中,如果是相对路径,就是相对标识,相对当前模块路径加载;如果是绝对路径,直接加载; 由此可见,在Sea.js中,模块的配置被分割成2+x个地方:
* 与页面放在一起;
* 与Sea.js放在一起;
* 通过绝对路径添加更多的模块源。
> 由此可见,Sea.js确实海纳百川。
### 获取真实的加载路径
1.在Sea.js中,使用data.cwd来代表当前页面的目录,如果当前页面地址为`http://www.dianping.com/promo/195800`,则cwd为`http://www.dianping.com/promo/`;使用data.base来代表sea.js的加载地址,如果sea.js的路径为`http://i1.dpfile.com/lib/1.0.0/sea.js`,则base为`http://i1.dpfile.com/lib/`。
> [“当 sea.js 的访问路径中含有版本号或其他东西时,base 不会包含 seajs/x.y.z 字串。 当 sea.js 有多个版本时,这样会很方便”](https://github.com/seajs/seajs/issues/258)。看到这一句,我凌乱了,这Sea.js是多么的人性化!但是我觉得这似乎没有必要。
2.seajs.use是,除了绝对路径,其他都是相对于cwd定位,即如果模块标识为:
* './a',则真实加载路径为[http://www.dianping.com/promo/a.js;](http://www.dianping.com/promo/a.js%EF%BC%9B)
* '/a',则为[http://www.dianping.com/a.js;](http://www.dianping.com/a.js%EF%BC%9B)
* '../a',则为[http://www.dianping.com/a.js;](http://www.dianping.com/a.js%EF%BC%9B)
> 从需求上看,相对页面地址定位在现实生活中并不太适用,如果页面地址或者静态文件的路径稍微变化下,就跪了。
如果模块标识为绝对路径:
* '[https://a.alipayobjects.com/ar/a',则加载路径就是'https://a.alipayobjects.com/ar/a.js'。](https://a.alipayobjects.com/ar/a'%EF%BC%8C%E5%88%99%E5%8A%A0%E8%BD%BD%E8%B7%AF%E5%BE%84%E5%B0%B1%E6%98%AF'https://a.alipayobjects.com/ar/a.js'%E3%80%82)
如果模块标识是顶级标识,就基于base来加载:
* 'jquery',则加载路径为'[http://i1.dpfile.com/lib/jquery.js'。](http://i1.dpfile.com/lib/jquery.js'%E3%80%82)
3.除此之外,就是factory中的模块标识了:
* '[https://a.alipayobjects.com/ar/b',加载路径为'https://a.alipayobjects.com/ar/b.js](https://a.alipayobjects.com/ar/b'%EF%BC%8C%E5%8A%A0%E8%BD%BD%E8%B7%AF%E5%BE%84%E4%B8%BA'https://a.alipayobjects.com/ar/b.js)'
* '/c',加载路径为'[http://www.dianping.com/c.js';](http://www.dianping.com/c.js'%EF%BC%9B)
* './d',如果父模块的加载路径是'[http://i1.dpfile.com/lib/e.js',则加载路径为'http://i1.dpfile.com/lib/d.js](http://i1.dpfile.com/lib/e.js'%EF%BC%8C%E5%88%99%E5%8A%A0%E8%BD%BD%E8%B7%AF%E5%BE%84%E4%B8%BA'http://i1.dpfile.com/lib/d.js)'
> 在模块系统中使用'/c'绝对路径是什么意思?Sea.js会将其解析为相对页面的模块,有点牛马不相及的感觉。
#### factory的依赖分析
在Sea.js的API中,`define(factory)`,并没有指明模块的依赖项,那Sea.js是如何获得的呢?
这段是Sea.js的源码:
~~~
/**
* util-deps.js - The parser for dependencies
* ref: tests/research/parse-dependencies/test.html
*/
var REQUIRE_RE = /"(?:\\"|[^"])*"|'(?:\\'|[^'])*'|\/\*[\S\s]*?\*\/|\/(?:\\\/|[^\/\r\n])+\/(?=[^\/])|\/\/.*|\.\s*require|(?:^|[^$])\brequire\s*\(\s*(["'])(.+?)\1\s*\)/g
var SLASH_RE = /\\\\/g
function parseDependencies(code) {
var ret = []
code.replace(SLASH_RE, "")
.replace(REQUIRE_RE, function(m, m1, m2) {
if (m2) {
ret.push(m2)
}
})
return ret
}
~~~
`REQUIRE_RE`这个硕大无比的正则就是关键。推荐使用[regexper](http://www.regexper.com/)来看看这个正则表达式。非native的函数factory我们可以通过的toString()方法获取源码,Sea.js就是使用`REQUIRE_RE`在factory的源码中匹配出该模块的依赖项。
> 从`REQUIRE_RE`这么长的正则来看,这里坑很多;在CommonJS的wrapper方案中可以使用JS语法分析器来获取依赖会更准确。
