
**1. 流量消峰**
举个例子,如果订单系统最多能处理一万次订单,这个处理能力应付正常时段的下单时绰绰有余,正常时段我们下单一秒后就能返回结果。但是在高峰期,如果有两万次下单操作系统是处理不了的,只能限制订单超过一万后不允许用户下单。<mark>使用消息队列做缓冲</mark>,我们可以取消这个限制,把一秒内下的订单分散成一段时间来处理,这时有些用户可能在下单十几秒后才能收到下单成功的操作,但是比不能下单的体验要好。
<br/>
**2.应用解耦**
以电商应用为例,应用中有订单系统、库存系统、物流系统、支付系统。用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障,都会造成下单操作异常。当转变成基于消息队列的方式后,系统间调用的问题会减少很多,比如物流系统因为发生故障,需要几分钟来修复。在这几分钟的时间里,物流系统要处理的内存被缓存在消息队列中,用户的下单操作可以正常完成。当物流系统恢复后,继续处理订单信息即可,中单用户感受不到物流系统的故障,<mark>提升系统的可用性</mark>。
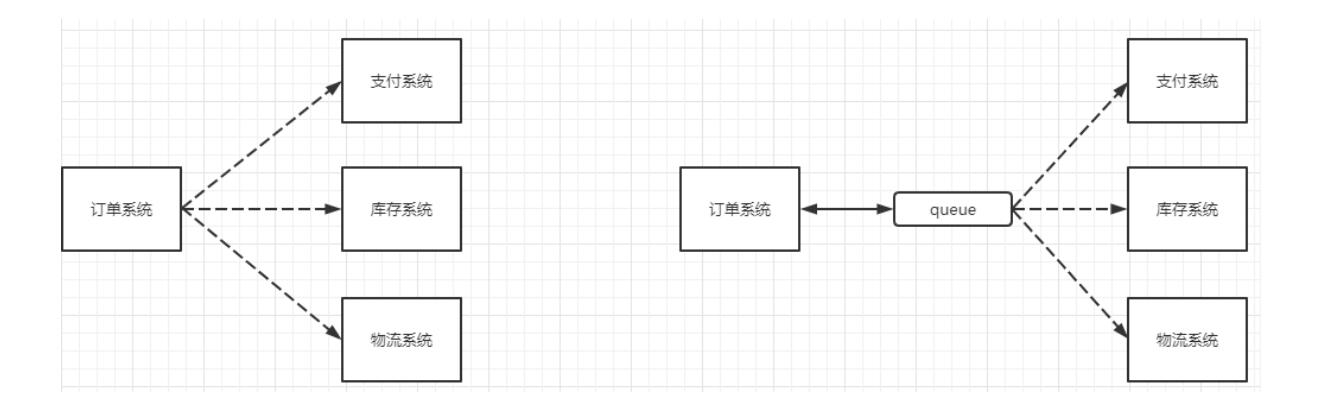
<br/>
**3.异步处理**
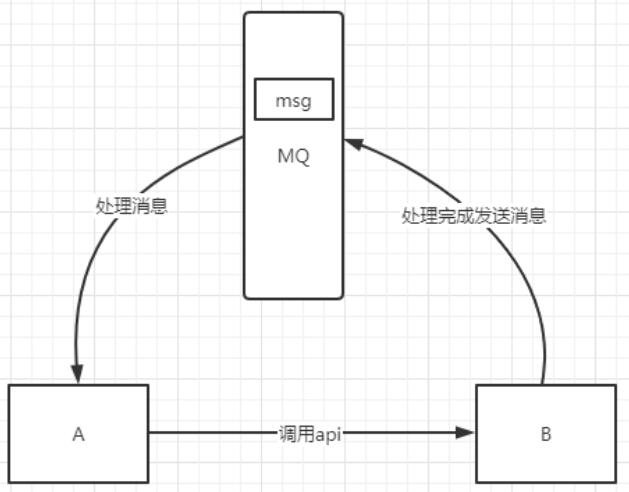
有些服务间调用是异步的,例如 A 调用 B,B 需要花费很长时间执行,但是 A 需要知道 B 什么时候可以执行完,以前一般有两种方式,A 过一段时间去调用 B 的查询 api 查询。或者 A 提供一个 callback api, B 执行完之后调用 api 通知 A 服务。这两种方式都不是很优雅,使用消息总线,可以很方便解决这个问题,A 调用 B 服务后,只需要监听 B 处理完成的消息,当 B 处理完成后,会发送一条消息给 MQ,MQ 会将此消息转发给 A 服务。这样 A 服务既不用循环调用 B 的查询 api,也不用提供 callback api。同样 B 服务也不用做这些操作。A 服务还能及时的得到异步处理成功的消息。
:-: 
- 消息队列
- 什么是MQ
- MQ的作用
- MQ的分类
- MQ的选择
- RabbitMQ
- RabbitMQ是什么
- 四大核心概念
- 工作原理
- 环境搭建
- windows系统下的搭建
- centos7系统下的搭建
- 常用命令
- 服务相关命令
- 管理用户命令
- 管理队列命令
- 第一个RabbitMQ程序
- 工作队列
- 轮询分发消息
- 消息应答
- 持久化
- 发布确认
- 发布确认原理
- 发布确认策略
- 交换机概念
- 交换机类型
- 无名交换机
- Fanout交换机
- Direct交换机
- Topic交换机
- 死信队列
- 死信概念
- 死信来源
- 死信实战
- 延迟队列
- 什么是延迟队列
- TTL设置方式
- 队列TTL延迟队列
- 消息TTL延迟队列
- 插件打造延迟队列
- 延迟队列总结
- 发布确认高级
- 代码实现
- 回退消息
- 备份交换机
- 幂等性
- 幂等性概念
- 消息重复消费
- 消费端幂等性保障
- 优先级队列
- 使用场景
- 设置优先级
- 惰性队列
- 什么是惰性队列
- 队列的两种模式
- 声明惰性队列
- RabbitMQ集群
- 为什么要搭建集群
- 集群搭建步骤
- 集群工作方式
- 脱离集群
- 镜像队列
- 高可用负载均衡