
`hash表`有两种存储的数据编码:ziplist 压缩列表,ht(hashtable) 哈希表
一, ziplist 压缩列表


①、previous\_entry\_ength:记录压缩列表前一个字节的长度。previous\_entry\_ength的长度可能是1个字节或者是5个字节,如果上一个节点的长度小于254,则该节点只需要一个字节就可以表示前一个节点的长度了,如果前一个节点的长度大于等于254,则previous length的第一个字节为254,后面用四个字节表示当前节点前一个节点的长度。利用此原理即当前节点位置减去上一个节点的长度即得到上一个节点的起始位置,压缩列表可以从尾部向头部遍历。这么做很有效地减少了内存的浪费。
②、encoding:节点的encoding保存的是节点的content的内容类型以及长度,encoding类型一共有两种,一种字节数组一种是整数,encoding区域长度为1字节、2字节或者5字节长。
③、content:content区域用于保存节点的内容,节点内容类型和长度由encoding决定。
二ht(hashtable) 哈希表又或者叫字典dict
(1)hashtable 被称为字典(dictionary),它是一个数组+链表的结构
(2)为什么有 ht\[0\] 和 ht\[1\] 两个hash表,是为了扩容
字典、哈希表和哈希表节点关系图:
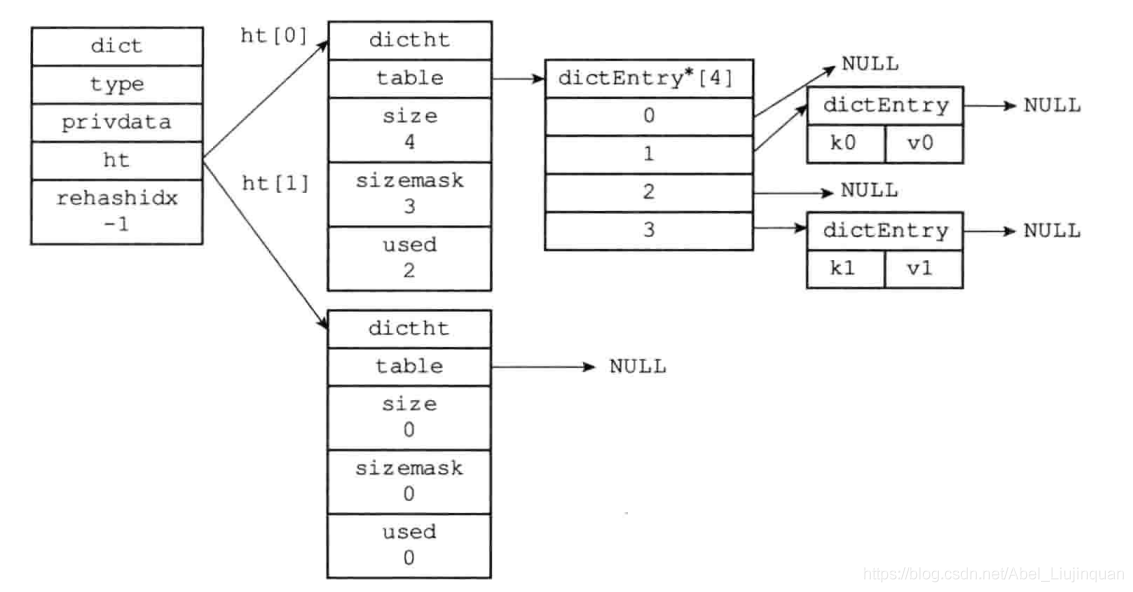
1.字典

* type属性是一个指向dictType结构的指针,每个dictType结构保存了一簇用于操作特定类型键值对的函数;
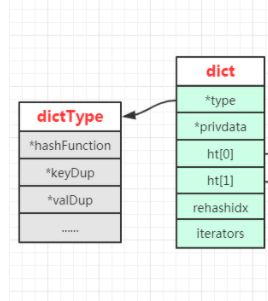
* privdata属性保存了需要传给那些类型特定函数的可选参数;
* ht属性是一个包含两个项的数组,数组中的每个项都是一个dictht哈希表,ht\[1\]只有在对ht\[0\]哈希表进行rehash操作时使用;
* trehashidx属性是rehash索引,没有进行rehash操作时值都为-1.
2.哈希表

* table属性是一个数组,数组中的每个元素都是一个指向哈希表节点的指针,每个节点都保存着一个键值对;
* size属性记录了哈希表的大小,也就是table数组的大小;
* sizemask属性的值总是等于size-1,这个属性和哈希值一起决定一个键应该被放到table数组的那个索引上面;
* used属性记录了哈希表目前已有节点的数量。
3.哈希表节点

* key属性保存着键值对中的键;
* v属性保存着键值对中的值,其中值用union定义,支持三种数据类型。
* next属性是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一起,以此来解决键冲突的问题。
(2)哈希计算
①、哈希算法:**Redis计算哈希值和索引值方法如下:
1、使用字典设置的哈希函数,计算键 key 的哈希值hash = dict->type->hashFunction(key);
2、使用哈希表的sizemask属性和第一步得到的哈希值,计算索引值index = hash & dict->ht[x].sizemask;
②、解决哈希冲突:**这个问题上面我们介绍了,方法是链地址法。通过字典里面的 \*next 指针指向下一个具有相同索引值的哈希表节点。
③、扩容和收缩:**当哈希表保存的键值对太多或者太少时,就要通过 rerehash(重新散列)来对哈希表进行相应的扩展或者收缩。具体步骤:
1、如果执行扩展操作,会基于原哈希表创建一个大小等于 ht\[0\].used\*2n 的哈希表(也就是每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)。相反如果执行的是收缩操作,每次收缩是根据已使用空间缩小一倍创建一个新的哈希表。
2、重新利用上面的哈希算法,计算索引值,然后将键值对放到新的哈希表位置上。
3、所有键值对都迁徙完毕后,释放原哈希表的内存空间。
④、触发扩容的条件:**
1、服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于1。
2、服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于5。
ps:负载因子 = 哈希表已保存节点数量 / 哈希表大小。
⑤、渐近式 rehash**
什么叫渐进式 rehash?也就是说扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。所以Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行 增加操作,一定是在新的哈希表上进行的。
- linux
- lanmp
- lanmp
- apache
- Apache2.4.x与Apache2.2.x的一些区别
- 跨域请求 Apache 服务器配置
- apache服务器安装配置ssl数字证书,https访问
- put请求跨区
- apache允许跨域请求 & ajax 自定义header
- 自定义header
- 安装最新版openssl
- nginx
- 解决Nginx出现403 forbidden的方法
- nginx: [error] open() "/usr/local/var/run/nginx.pid" failed (2: No such file or directory)
- 如何用linux命令查看nginx是否在正常运行
- nginx反向代理
- nginx 编译安装
- nginx重定向
- 一个域名对应多个vue项目
- 关于http和https允许请求设置header问题
- nginx配置ssl证书
- 配置宝塔nginx支持tp5路由规则
- nginx获取自定义请求头header
- mysql
- 创建还量表
- 解决Navicat 出错:1130-host . is not allowed to connect to this MySql server,MySQL
- mysql慢查询
- explain
- 索引
- sphinx
- coreseek(sphinx)错误:WARNING: attribute 'id' not found - IGNORING原因及解决方法
- coreseek在windows安装问题和使用步骤
- coreseek常见错误
- coreseek php操作
- mysql5.6升级5.7.21
- sql操作
- mysql函数
- phpmyadmin上传文件大小限制
- mysql主从复制
- 单机主从配置
- 修改mysql端口后修改相应的phpmyadmin端口
- MERGE分表
- MySQL 5.7.22 多实例安装(二进制免编译安装模式)
- 解决phpmyadmin mysqli_real_connect(): (HY000/2002): No such file or directory错误
- Mysql服务器无法存emoji表情的解决方案
- /var/run/mysqld 目录每次重启后都需要手动去创建并赋权mysql用户才能起到mysql
- mysql排序
- mysql关键字冲突
- mysql备份
- mysql5.7密码修改
- 更改MySQL数据库目录位置
- mysql5.6安装
- 字符集与排序规则
- mysql 锁
- mysql事务性
- php
- centos7 升级 php 5.4 -> php5.6
- php扩展
- linux切换默认php版本(宝塔)
- vsftpd
- 关于vsftp出现Restarting vsftpd (via systemctl): Job for vsftpd.service failed because the control 的解决办法
- vdb
- fdisk
- parted
- 磁盘小知识
- CentOS7.x系统根目录分区扩容
- Linux 格式化分区 报错Could not stat --- No such file or directory 和 partprobe 命令
- 添加swap交换区
- root
- Centos创建和修改用户及密码命令
- linux 命令终端提示符显示-bash-4.2#解决方法
- firewall
- centOS7下安装GUI图形界面
- 在Linux主机上,安装上传下载工具包rz及sz
- ping: www.baidu.com: Name or service not known centos7
- linux中 you have newmail in /var/spool/mail/root
- CentOS7启动SSH服务报:Job for ssh.service failed because the control process exited with error code.......
- ifconfig,netstat 命令找不到解決办法
- CentOS7系统时间与真实时间相差8小时
- Centos7:利用crontab定时执行任务
- crontab命令
- /usr/bin/curl 执行外链
- speedtest-cli命令,网速测试
- yum 卸载命令
- 用户管理
- PATH环境变量
- rpm 命令
- 防火墙和网络的安装
- nohup
- vim命令
- 清理缓存命令
- 错误集
- tar解压包的时候出现错误 gzip: stdin: not in gzip format
- 在linux下创建自定义service服务
- 时钟同步
- 查找大文件
- redis
- yum安装
- redis主从复制
- php用法
- redis表的特性
- redis 锁
- redis事务
- redis主从配置+哨兵模式
- redis应用场景
- redis高并发集群下常见问题
- redis思维导图
- 脑图1
- 脑图2
- redis编码
- redis字符串编码
- hash编码
- list编码
- set编码
- zset编码
- 内存回收和内存共享
- redis小知识点
- ffmpeg
- yum安装ffmpeg
- ffmpeg-php类库安装及使用
- make安装
- WebRTC
- 房间服务器
- 信令服务器
- 打洞服务器
- PHP识别二维码(php-zbarcode)
- centos7.4安装Imagemagick
- 第二种方式
- linux小知识
- 查看日志命令
- linux CPU使用率过高或负载过高的处理
- swoole安装
- mq安装
- RabbitMQ安装
- php-amqplib使用--基本使用
- RabbitMQ使用技巧
- tp5
- problem
- thinkphp5的mkdir() Permission denied问题
- 5.5版本以上”No input file specified“问题解决
- 路由带参数的翻页,第二页无数据
- 报错A non well formed numeric value encountered(Thinkphp5时间戳自动转换问题)
- order排序没反应
- tp5分页--搜索
- tp5文件上传---宝塔
- 小知识
- return
- volist标签中使用eq标签 下拉列表选中selected
- TP5写入避免某字段重复的问题
- tp5 --url大小写
- tp5接收数组
- json存储与查询
- 接收参数为null
- php替换str_replace的使用方法,支持多个替换
- postman传数组参数
- Request 排除变量传参
- sql连表统计查询
- php循环
- 模型column方法
- 修改器与获取器
- mysql数据库group与order不能同时使用
- mysql三表查询
- json数据
- 获取数组第一个获第二个元素的键值
- mysql除以100计算
- mysql分组统计
- tp5.1 高级查询之 表里2字段比较大小
- whereOr()用法
- param数字参数,不能用==判断相等,需要用=来判断
- if判断
- tp5随机排序
- 短链接算法
- $_FILES["file"]二进制数据获取
- 跨域
- web.config
- iis: httpd相应标头
- thikphp模板中一维数组如何循环
- tp5 视频上传及自定义命名
- 搜索附近的人
- 小程序
- uploadFile:fail Error: unable to verify the first certificate
- 安卓手机打开小程序提示:request:fail ssl hand shake error
- tp5.1引入库文件
- composer
- tp5小知识
- TP5.1隐藏public和index.php
- tp5扩展
- 二维码
- phpexcel
- 谷歌验证码
- 谷歌验证码2
- mysql时间统计
- union合并查询并分页
- tp5底层框架学习
- php未知函数
- 类的知识点
- 三大设计模式
- 反射机制
- php常用内置类
- php小知识点
- 变量,函数名,参数前加&,什么意思
- PHP中 比较 0、false、null,'' "
- php小常识
- php缓存
- Trait特性
- php -- 取路径:getcwd()、DIR、FILE 的区别
- php关于类的常用概念
- php 类与对象全面了解
- php命名空间与引入
- php常见魔法常量
- php常见魔法函数
- PHP 超级全局变量
- tp5.1本身小知识
- 框架运行流程
- 框架教程总结
- 类的自动加载
- 配置文件
- ArrayAccess用法
- yaconf学习
- yaml学习
- config类重点
- php小知识2
- 多语言切换
- jwt(token)
- redis连接池
- 百度富文本
- 图片路径转换
- layui
- 复选框
- 获取视频第几帧作为封面图
- mysql查询
- FIND_IN_SET(str,strlist)
- PHP
- 函数取整
- array
- 日期
- header
- php获取一维,二维数组长度的方法
- php中数组和字符串的相互转换
- php对数组开头与末尾的元素进行插入与移除
- 队列
- PHP substr截取中文字符出现乱码的问题解疑
- foreach遍历数组并添加属性(下标)
- 数组排序
- PHP实现保留两位小数的三种方法
- 对象转数组
- php小知识
- 阻塞IO和非阻塞IO,异步与同步的区别
- 后台运行
- 超时
- php 高精度计算的问题
- move_uploaded_file
- PHP SplQueue 队列简介
- @,&&等php符号
- PHP命令行脚本接收传入参数的三种方式
- php执行linux命令
- 一些封装函数
- PHP获取文件大小
- PHP 生成随机字符串与唯一字符串
- PHP去除emoji表情
- ip
- php把时间计算成几分钟前,几小时前,几天前的函数
- https
- ssl证书
- 远程登入密码和端口修改
- apache配置https
- problems
- 响应状态status为canceled,解决办法
- PHP Restful PUT方法的参数提交及接收
- HTTP之预检,两种请求
- http增删改查理解
- js
- js数组与字符串的相互转换
- js移除Array中指定元素
- 使用sessionStorage、localStorage存储数组与对象
- 子页面调用父页面方法
- input文件上传
- 随机字符串
- 数组操作
- js 传递数组
- token接入验证
- 用文件来保存token
- 删除用户资料
- 微信function
- 接入验证及点击事件
- 基础token
- 获取用户资料
- curl
- 链接分享
- 网页授权登入
- 微信被动回复用户消息
- 生成微信二维码
- WxPay
- 单一文件,不能加额外参数
- tp5引用微信支付官方库文件
- 微信二维码支付
- 其他
- 手机端发送ajax请求,后台有可能会接收不到到请求(360浏览器和ie浏览器)
- 短信发送
- git
- postman无法正常返回结果Could not get any response
- web服务器配置
- 高并发方案
- nginx防盗链和限制请求速度
- 高并发概念与测试工具
- 定时秒杀方案
- web接口
- yzdd
- 接口1
- 接口2
- spx
- 接口说明
- 新闻表sbh_artnews字段说明
- 用户表sbh_homeuser
- 用户认证表sbh_usertrue
- txsh
- 接口_txsh_1
- chat消息格式
- 表字段
- txsh_第三方接口
- GatewayWorker
- 向对方发送消息,对方会掉线
- 负载均衡
- html
- html中引入调用另一个html的方法
- python
- linux安装--python3.6
- Centos7卸载Python2.7之后恢复yum
- pycharm汉化
- python错误集
- fatal error: Python.h: No such file or directory
- Python小知识
- python中两个重要的工具setuptools和pip的安装
- 基础知识点
- 学习笔记
- tornado基础流程
- 请求与响应
- 以太坊
- 以太坊账户管理
- 一些方法的更新弃用
- 小知识点
- web3.eth.accounts 和 web3.eth.personal 创建account的区别
- web3.py中sendTransaction和sendRawTransaction之间的区别
- 测试网和主网区别
- 以太坊gas、gaslimit、gasPrice、gasUsed详解
- web安全
- web渗透--全面介绍
- 大概介绍
- xss--介绍
- sql注入-介绍
- 文件上传下载-介绍
- 越权--介绍
- xxe--介绍
- 暴力破解
- xss漏洞安全编码系列详解
- 反射型
- DOM型
- 存储型
- 图片隐写
- sql注入详解
- 数据库和其他--介绍
- mysql爆破
- web安全--工具
- sqlmap
- 介绍与安装
- sqlmap攻击方式
- Sqlmap中的其他
- sqlmap--get攻击
- sqlmap--post攻击
- sqlmap--常用选项及命令
- sqlmap--详解
- sqlmap--查看
- web安全简单总结
- api功能扩展
- 阿里云短信
- 阿里云短信sdk新版用法
- 阿里云对象存储 OSS
- 七牛云上传
- qq邮箱发送短信验证码
- 通过ip获取归属地
- 支付插件
- zoujingli
- swoole
- swoole启动关闭方案
- swoole服务端主动推送消息
- 创建websocket--systemctl自定义启动服务
- 创建php脚本来启动关闭websocket服务
- swoole小知识
- 进程/线程结构图
- 区块链
- 区块链概念理解
- usdt小知识点1
- 区块链架构1.0、2.0与3.0梳理
- 理解usdt和代币,智能合约,基础货币
- 波场tron
- 账号创建
- 代币转账