
说起RPC,就不能不提到**分布式**,这个促使RPC诞生的领域。
假设你有一个计算器接口,Calculator,以及它的实现类CalculatorImpl,那么在系统还是**单体应用**时,你要调用Calculator的add方法来执行一个加运算,直接new一个CalculatorImpl,然后调用add方法就行了,这其实就是非常普通的**本地函数调用**,因为在**同一个地址空间**,或者说在同一块内存,所以通过方法栈和参数栈就可以实现。
****
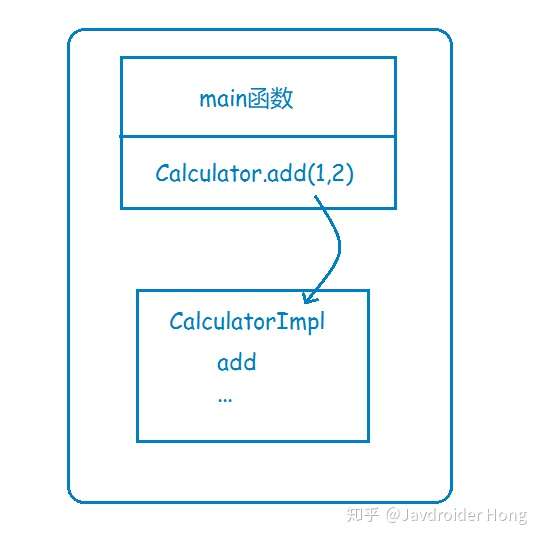
现在,基于高性能和高可靠等因素的考虑,你决定将系统改造为分布式应用,将很多可以共享的功能都单独拎出来,比如上面说到的计算器,你单独把它放到一个服务里头,让别的服务去调用它。
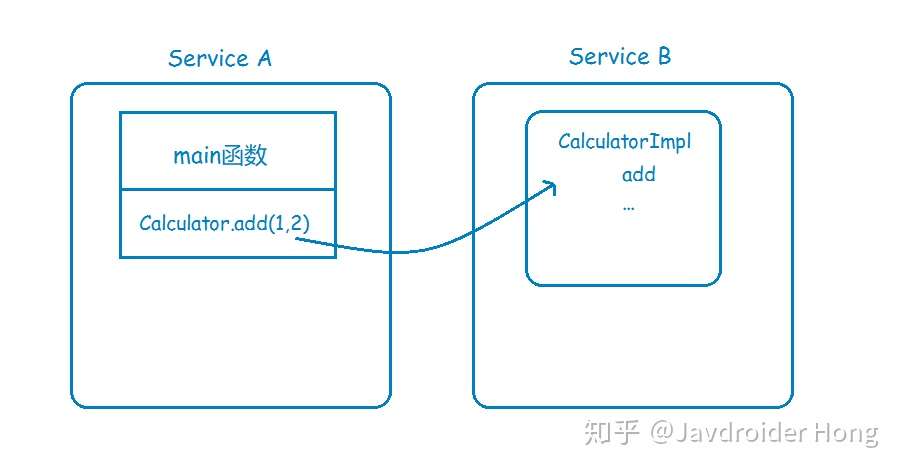
这下问题来了,服务A里头并没有CalculatorImpl这个类,那它要怎样调用服务B的CalculatorImpl的add方法呢?
有同学会说,可以模仿B/S架构的调用方式呀,在B服务暴露一个Restful接口,然后A服务通过调用这个Restful接口来间接调用CalculatorImpl的add方法。
很好,这已经很接近RPC了,不过如果是这样,那每次调用时,是不是都需要写一串发起http请求的代码呢?比如httpClient.sendRequest…之类的,能不能像本地调用一样,去发起远程调用,让使用者感知不到远程调用的过程呢,像这样:
~~~java
@Reference
private Calculator calculator;
...
calculator.add(1,2);
...
~~~
这时候,有同学就会说,用**代理模式**呀!而且最好是结合Spring IoC一起使用,通过Spring注入calculator对象,注入时,如果扫描到对象加了@Reference注解,那么就给它生成一个代理对象,将这个代理对象放进容器中。而这个代理对象的内部,就是通过httpClient来实现RPC远程过程调用的。
可能上面这段描述比较抽象,不过这就是很多RPC框架要解决的问题和解决的思路,比如阿里的Dubbo。
总结一下,**RPC要解决的两个问题:**
1. **解决分布式系统中,服务之间的调用问题。**
2. **远程调用时,要能够像本地调用一样方便,让调用者感知不到远程调用的逻辑。**
## 如何实现一个RPC
实际情况下,RPC很少用到http协议来进行数据传输,毕竟我只是想传输一下数据而已,何必动用到一个文本传输的应用层协议呢,我为什么不直接使用**二进制传输**?比如直接用Java的Socket协议进行传输?
不管你用何种协议进行数据传输,**一个完整的RPC过程,都可以用下面这张图来描述**:
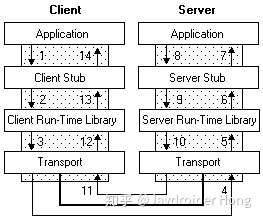
以左边的Client端为例,Application就是rpc的调用方,Client Stub就是我们上面说到的代理对象,也就是那个看起来像是Calculator的实现类,其实内部是通过rpc方式来进行远程调用的代理对象,至于Client Run-time Library,则是实现远程调用的工具包,比如jdk的Socket,最后通过底层网络实现实现数据的传输。
这个过程中最重要的就是**序列化**和**反序列化**了,因为数据传输的数据包必须是二进制的,你直接丢一个Java对象过去,人家可不认识,你必须把Java对象序列化为二进制格式,传给Server端,Server端接收到之后,再反序列化为Java对象。
下一次我也将通过代码,给大家演示一下,如何实现一个简单的RPC。
## RPC vs Restful
其实这两者并不是一个维度的概念,总得来说RPC涉及的维度更广。
如果硬要比较,那么可以从RPC风格的url和Restful风格的url上进行比较。
比如你提供一个查询订单的接口,用RPC风格,你可能会这样写:
~~~text
/queryOrder?orderId=123
~~~
用Restful风格呢?
~~~text
Get
/order?orderId=123
~~~
再精炼一点,甚至可以这样:
~~~text
Get
/order/123
~~~
**RPC是面向过程,Restful是面向资源**,并且使用了Http动词。从这个维度上看,Restful风格的url在表述的精简性、可读性上都要更好。
## RPC vs RMI
严格来说这两者也不是一个维度的。
RMI是Java提供的一种访问远程对象的协议,是已经实现好了的,可以直接用了。
而RPC呢?人家只是一种编程模型,并没有规定你具体要怎样实现,**你甚至都可以在你的RPC框架里面使用RMI来实现数据的传输**,比如Dubbo:[Dubbo - rmi协议](https://link.zhihu.com/?target=http%3A//dubbo.apache.org/books/dubbo-user-book/references/protocol/rmi.html)
## RPC没那么简单
**要实现一个RPC不算难,难的是实现一个高性能高可靠的RPC框架。**
比如,既然是分布式了,那么一个服务可能有多个实例,你在调用时,要如何获取这些实例的地址呢?
这时候就需要一个服务注册中心,比如在Dubbo里头,就可以使用Zookeeper作为注册中心,在调用时,从Zookeeper获取服务的实例列表,再从中选择一个进行调用。
那么选哪个调用好呢?这时候就需要负载均衡了,于是你又得考虑如何实现复杂均衡,比如Dubbo就提供了好几种负载均衡策略。
这还没完,总不能每次调用时都去注册中心查询实例列表吧,这样效率多低呀,于是又有了缓存,有了缓存,就要考虑缓存的更新问题,blablabla……
你以为就这样结束了,没呢,还有这些:
* 客户端总不能每次调用完都干等着服务端返回数据吧,于是就要支持异步调用;
* 服务端的接口修改了,老的接口还有人在用,怎么办?总不能让他们都改了吧?这就需要版本控制了;
* 服务端总不能每次接到请求都马上启动一个线程去处理吧?于是就需要线程池;
* 服务端关闭时,还没处理完的请求怎么办?是直接结束呢,还是等全部请求处理完再关闭呢?
* ……
如此种种,都是一个优秀的RPC框架需要考虑的问题。
*****
*****
.
## **二,RPC的实现原理**
正如上一讲所说,RPC主要是为了解决的两个问题:
* 解决分布式系统中,服务之间的调用问题。
* 远程调用时,要能够像本地调用一样方便,让调用者感知不到远程调用的逻辑。
还是以计算器Calculator为例,如果实现类CalculatorImpl是放在本地的,那么直接调用即可:

现在系统变成分布式了,CalculatorImpl和调用方不在同一个地址空间,那么就必须要进行远程过程调用:

那么如何实现远程过程调用,也就是RPC呢,一个完整的RPC流程,可以用下面这张图来描述:

其中左边的Client,对应的就是前面的Service A,而右边的Server,对应的则是Service B。
下面一步一步详细解释一下。
1. Service A的应用层代码中,调用了Calculator的一个实现类的add方法,希望执行一个加法运算;
2. 这个Calculator实现类,内部并不是直接实现计算器的加减乘除逻辑,而是通过远程调用Service B的RPC接口,来获取运算结果,因此称之为**Stub**;
3. Stub怎么和Service B建立远程通讯呢?这时候就要用到**远程通讯工具**了,也就是图中的**Run-time Library**,这个工具将帮你实现远程通讯的功能,比如Java的**Socket**,就是这样一个库,当然,你也可以用基于Http协议的**HttpClient**,或者其他通讯工具类,都可以,**RPC并没有规定说你要用何种协议进行通讯**;
4. Stub通过调用通讯工具提供的方法,和Service B建立起了通讯,然后将请求数据发给Service B。需要注意的是,由于底层的网络通讯是基于**二进制格式**的,因此这里Stub传给通讯工具类的数据也必须是二进制,比如calculator.add(1,2),你必须把参数值1和2放到一个Request对象里头(这个Request对象当然不只这些信息,还包括要调用哪个服务的哪个RPC接口等其他信息),然后**序列化**为二进制,再传给通讯工具类,这一点也将在下面的代码实现中体现;
5. 二进制的数据传到Service B这一边了,Service B当然也有自己的通讯工具,通过这个通讯工具接收二进制的请求;
6. 既然数据是二进制的,那么自然要进行**反序列化**了,将二进制的数据反序列化为请求对象,然后将这个请求对象交给Service B的Stub处理;
7. 和之前的Service A的Stub一样,这里的Stub也同样是个“假玩意”,它所负责的,只是去解析请求对象,知道调用方要调的是哪个RPC接口,传进来的参数又是什么,然后再把这些参数传给对应的RPC接口,也就是Calculator的实际实现类去执行。很明显,如果是Java,那这里肯定用到了**反射**。
8. RPC接口执行完毕,返回执行结果,现在轮到Service B要把数据发给Service A了,怎么发?一样的道理,一样的流程,只是现在Service B变成了Client,Service A变成了Server而已:Service B反序列化执行结果->传输给Service A->Service A反序列化执行结果 -> 将结果返回给Application,完毕。
理论的讲完了,是时候把理论变成实践了。
## **三,把理论变成实践**
> *本文的示例代码,可到[Github](https://link.zhihu.com/?target=https%3A//github.com/hzy38324/simple-rpc)下载。*
首先是Client端的应用层怎么发起RPC,ComsumerApp:
~~~java
public class ComsumerApp {
public static void main(String[] args) {
Calculator calculator = new CalculatorRemoteImpl();
int result = calculator.add(1, 2);
}
}
~~~
**通过一个CalculatorRemoteImpl,我们把RPC的逻辑封装进去了,客户端调用时感知不到远程调用的麻烦**。下面再来看看CalculatorRemoteImpl,代码有些多,但是其实就是把上面的2、3、4几个步骤用代码实现了而已,CalculatorRemoteImpl:
~~~java
public class CalculatorRemoteImpl implements Calculator {
public int add(int a, int b) {
List<String> addressList = lookupProviders("Calculator.add");
String address = chooseTarget(addressList);
try {
Socket socket = new Socket(address, PORT);
// 将请求序列化
CalculateRpcRequest calculateRpcRequest = generateRequest(a, b);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());
// 将请求发给服务提供方
objectOutputStream.writeObject(calculateRpcRequest);
// 将响应体反序列化
ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream());
Object response = objectInputStream.readObject();
if (response instanceof Integer) {
return (Integer) response;
} else {
throw new InternalError();
}
} catch (Exception e) {
log.error("fail", e);
throw new InternalError();
}
}
}
~~~
add方法的前面两行,lookupProviders和chooseTarget,可能大家会觉得不明觉厉。
分布式应用下,一个服务可能有多个实例,比如Service B,可能有ip地址为198.168.1.11和198.168.1.13两个实例,lookupProviders,其实就是在寻找要调用的服务的实例列表。在分布式应用下,通常会有一个**服务注册中心**,来提供查询实例列表的功能。
查到实例列表之后要调用哪一个实例呢,只时候就需要chooseTarget了,其实内部就是一个**负载均衡**策略。
由于我们这里只是想实现一个简单的RPC,所以暂时不考虑服务注册中心和负载均衡,因此代码里写死了返回ip地址为127.0.0.1。
代码继续往下走,我们这里用到了Socket来进行远程通讯,同时利用**ObjectOutputStream**的writeObject和**ObjectInputStream**的readObject,来实现序列化和反序列化。
最后再来看看Server端的实现,和Client端非常类似,ProviderApp:
~~~java
public class ProviderApp {
private Calculator calculator = new CalculatorImpl();
public static void main(String[] args) throws IOException {
new ProviderApp().run();
}
private void run() throws IOException {
ServerSocket listener = new ServerSocket(9090);
try {
while (true) {
Socket socket = listener.accept();
try {
// 将请求反序列化
ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream());
Object object = objectInputStream.readObject();
log.info("request is {}", object);
// 调用服务
int result = 0;
if (object instanceof CalculateRpcRequest) {
CalculateRpcRequest calculateRpcRequest = (CalculateRpcRequest) object;
if ("add".equals(calculateRpcRequest.getMethod())) {
result = calculator.add(calculateRpcRequest.getA(), calculateRpcRequest.getB());
} else {
throw new UnsupportedOperationException();
}
}
// 返回结果
ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());
objectOutputStream.writeObject(new Integer(result));
} catch (Exception e) {
log.error("fail", e);
} finally {
socket.close();
}
}
} finally {
listener.close();
}
}
}
~~~
Server端主要是通过ServerSocket的accept方法,来接收Client端的请求,接着就是反序列化请求->执行->序列化执行结果,最后将二进制格式的执行结果返回给Client。
**就这样我们实现了一个简陋而又详细的RPC。**
说它简陋,是因为这个实现确实比较挫,在下一小节会说它为什么挫。
说它详细,是因为它一步一步的演示了一个RPC的执行流程,方便大家了解RPC的内部机制。
## 为什么说这个RPC实现很挫
这个RPC实现只是为了给大家演示一下RPC的原理,要是想放到生产环境去用,那是绝对不行的。
1、缺乏通用性
我通过给Calculator接口写了一个CalculatorRemoteImpl,来实现计算器的远程调用,下一次要是有别的接口需要远程调用,是不是又得再写对应的远程调用实现类?这肯定是很不方便的。
那该如何解决呢?先来看看使用Dubbo时是如何实现RPC调用的:
~~~java
@Reference
private Calculator calculator;
...
calculator.add(1,2);
...
~~~
Dubbo通过和Spring的集成,在Spring容器初始化的时候,如果扫描到对象加了@Reference注解,那么就给这个对象生成一个代理对象,这个代理对象会负责远程通讯,然后将代理对象放进容器中。所以代码运行期用到的calculator就是那个代理对象了。
我们可以先不和Spring集成,也就是先不采用依赖注入,但是我们要做到像Dubbo一样,无需自己手动写代理对象,怎么做呢?那自然是要求所有的远程调用都遵循一套模板,**把远程调用的信息放到一个RpcRequest对象里面,发给Server端,Server端解析之后就知道你要调用的是哪个RPC接口、以及入参是什么类型、入参的值又是什么**,就像Dubbo的RpcInvocation:
~~~java
public class RpcInvocation implements Invocation, Serializable {
private static final long serialVersionUID = -4355285085441097045L;
private String methodName;
private Class<?>[] parameterTypes;
private Object[] arguments;
private Map<String, String> attachments;
private transient Invoker<?> invoker;
...
~~~
2、集成Spring
在实现了代理对象通用化之后,下一步就可以考虑集成Spring的IOC功能了,通过Spring来创建代理对象,这一点就需要对Spring的bean初始化有一定掌握了。
3、长连接or短连接
总不能每次要调用RPC接口时都去开启一个Socket建立连接吧?是不是可以保持若干个长连接,然后每次有rpc请求时,把请求放到任务队列中,然后由线程池去消费执行?只是一个思路,后续可以参考一下Dubbo是如何实现的。
4、 服务端线程池
我们现在的Server端,是单线程的,每次都要等一个请求处理完,才能去accept另一个socket的连接,这样性能肯定很差,是不是可以通过一个线程池,来实现同时处理多个RPC请求?同样只是一个思路。
5、服务注册中心
正如之前提到的,要调用服务,首先你需要一个服务注册中心,告诉你对方服务都有哪些实例。Dubbo的服务注册中心是可以配置的,官方推荐使用Zookeeper。如果使用Zookeeper的话,要怎样往上面注册实例,又要怎样获取实例,这些都是要实现的。
6、负载均衡
如何从多个实例里挑选一个出来,进行调用,这就要用到负载均衡了。负载均衡的策略肯定不只一种,要怎样把策略做成可配置的?又要如何实现这些策略?同样可以参考Dubbo,[Dubbo - 负载均衡](https://link.zhihu.com/?target=http%3A//dubbo.apache.org/books/dubbo-user-book/demos/loadbalance.html)
7、结果缓存
每次调用查询接口时都要真的去Server端查询吗?是不是要考虑一下支持缓存?
8、多版本控制
服务端接口修改了,旧的接口怎么办?
9、异步调用
客户端调用完接口之后,不想等待服务端返回,想去干点别的事,可以支持不?
10、优雅停机
服务端要停机了,还没处理完的请求,怎么办?
……
诸如此类的优化点还有很多,这也是为什么实现一个高性能高可用的RPC框架那么难的原因。
当然,我们现在已经有很多很不错的RPC框架可以参考了,我们完全可以借鉴一下前人的智慧。
**后面如果有(dian)机(zan)会(duo)的话**,也将和大家分享一下如何一步一步优化现有的这块RPC代码,把它做成一个小型RPC框架!
- 前言
- 服务器开发设计
- Reactor模式
- 一种心跳,两种设计
- 聊聊 TCP 长连接和心跳那些事
- 学习TCP三次握手和四次挥手
- Linux基础
- Linux的inode的理解
- 异步IO模型介绍
- 20个最常用的GCC编译器参数
- epoll
- epoll精髓
- epoll原理详解及epoll反应堆模型
- epoll的坑
- epoll的本质
- socket的SO_REUSEADDR参数全面分析
- 服务器网络
- Protobuf
- Protobuf2 语法指南
- 一种自动反射消息类型的 Protobuf 网络传输方案
- 微服务
- RPC框架
- 什么是RPC
- 如何科学的解释RPC
- RPC 消息协议
- 实现一个极简版的RPC
- 一个基于protobuf的极简RPC
- 如何基于protobuf实现一个极简版的RPC
- 开源RPC框架
- thrift
- grpc
- brpc
- Dubbo
- 服务注册,发现,治理
- Redis
- Redis发布订阅
- Redis分布式锁
- 一致性哈希算法
- Redis常见问题
- Redis数据类型
- 缓存一致性
- LevelDB
- 高可用
- keepalived基本理解
- keepalived操做
- LVS 学习
- 性能优化
- Linux服务器程序性能优化方法
- SRS性能(CPU)、内存优化工具用法
- centos6的性能分析工具集合
- CentOS系统性能工具 sar 示例!
- Linux性能监控工具集sysstat
- gdb相关
- Linux 下如何产生core文件(core dump设置)