
## 生产者 - 消费者模式
生产者消费者模式是一个经典的多线程设计模式。
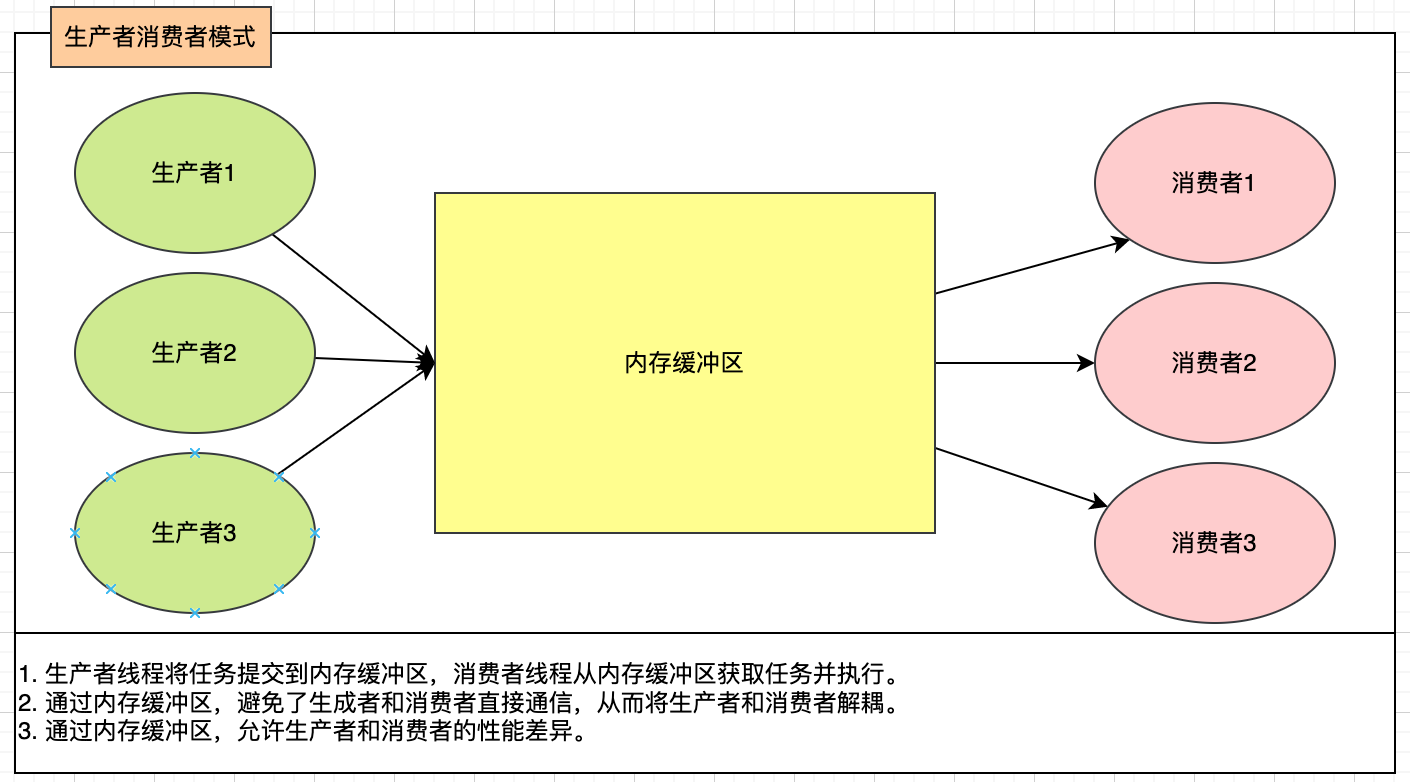
总结:
1. 生产者线程将任务提交到内存缓冲区,消费者线程从内存缓冲区获取任务并执行。
2. 通过内存缓冲区,避免了生成者和消费者直接通信,从而将生产者和消费者解耦。
3. 通过内存缓冲区,允许生产者和消费者的性能差异。
在`JDK`中提供的线程池(`ThreadPoolExecutor`)就是典型的生产者消费者模式(其中任务是线程),其中内存缓冲区的实现使用的是`BlockingQueue`阻塞队列。
## 生产者 - 消费者模式(无锁实现)
在`ThreadPoolExecutor`中使用了`BlockingQueue`阻塞队列来做内存缓冲区,但是由于使用了锁和阻塞等待来实现线程间的同步,所以新能不高。
而LMAX公司开发了一套无锁实现的高性能生产者消费者模式的框架,叫做`Disruptor`。
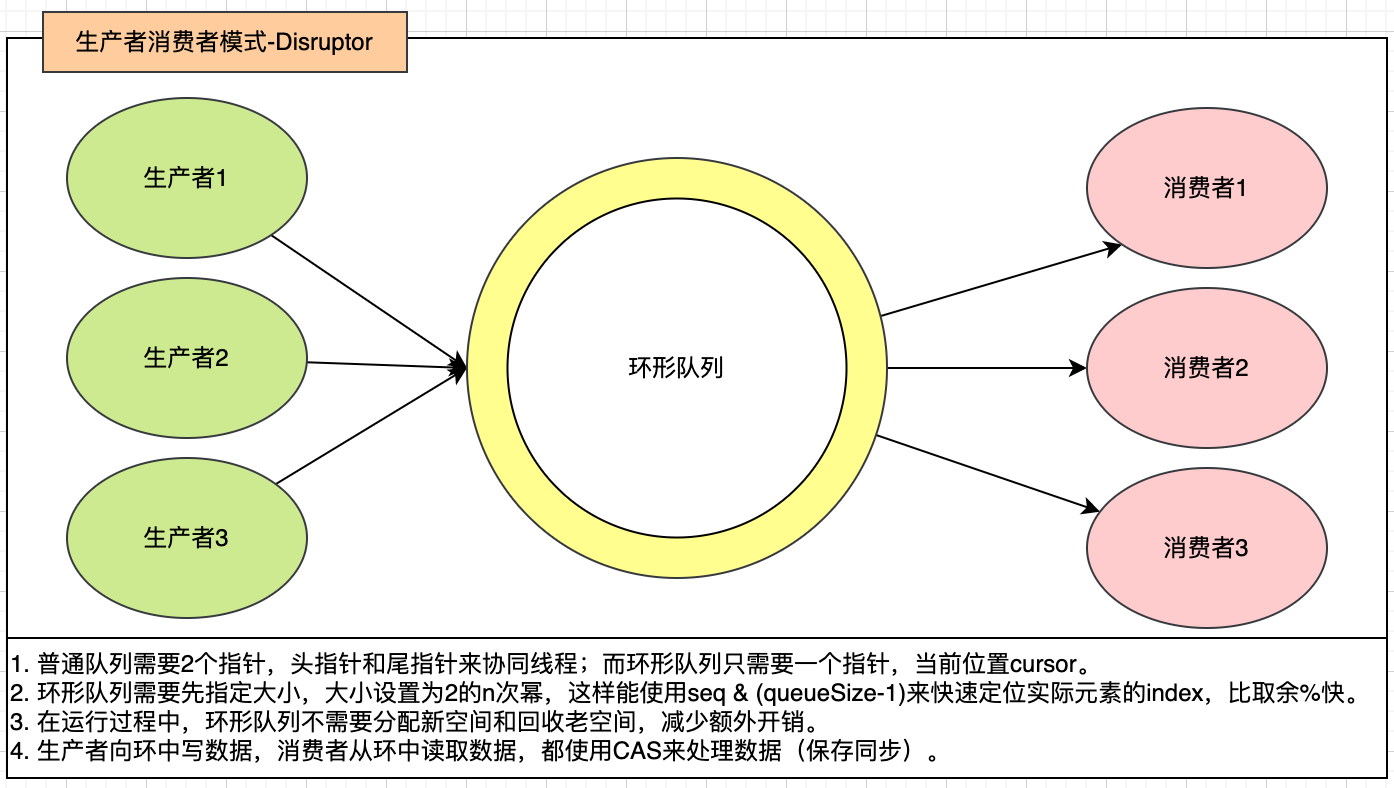
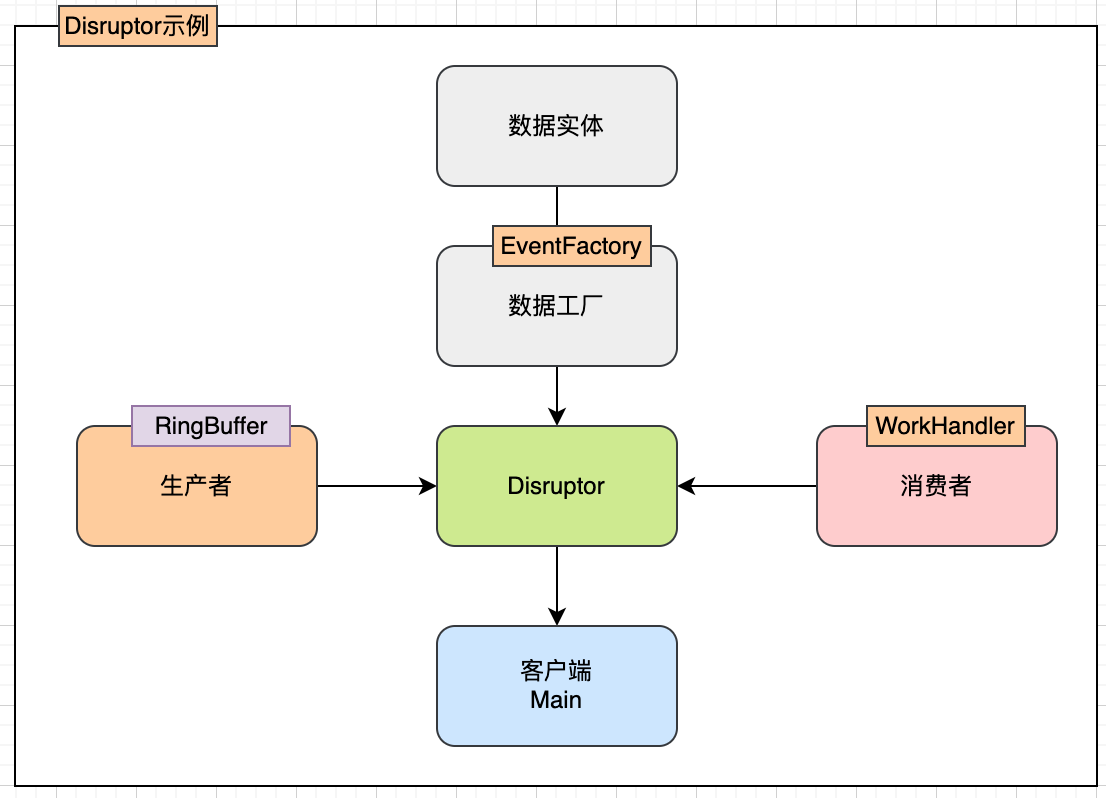
例子:(生产者生成数据,消费者计算数据平方)
引入依赖:
~~~
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.4</version>
</dependency>
~~~
数据实体:
~~~
public class PCData {
private long value;
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
}
~~~
数据工厂:
~~~
public class PCDataFactory implements EventFactory<PCData> {
@Override
public PCData newInstance() {
return new PCData();
}
}
~~~
生产者:
~~~
import com.lmax.disruptor.RingBuffer;
import java.nio.ByteBuffer;
public class Producer {
private final RingBuffer<PCData> ringBuffer;
public Producer(RingBuffer<PCData> ringBuffer){
this.ringBuffer = ringBuffer;
}
public void pushData(ByteBuffer bb){
// 获取环上的下一个序列
long sequence = ringBuffer.next();
PCData data = ringBuffer.get(sequence);
// 设置数据
data.setValue(bb.getLong(0));
// 发布序列
ringBuffer.publish(sequence);
}
}
~~~
消费者:
~~~
import com.lmax.disruptor.WorkHandler;
public class Consumer implements WorkHandler<PCData> {
@Override
public void onEvent(PCData pcData) throws Exception {
// 打印平方值
System.out.println(Thread.currentThread().getName() +
" -- value="+pcData.getValue() +
" -- 平方="+Math.pow(pcData.getValue(),2));
}
}
~~~
客户端:
~~~
public class Main {
public static void main(String[] args) throws InterruptedException {
// 大小需要是2的幂
int bufferSize = 1024;
Disruptor<PCData> disruptor = new Disruptor<>(
new PCDataFactory(),
bufferSize,
Executors.defaultThreadFactory(),
ProducerType.MULTI,
// 选择合适的策略,提高消费者的响应时间
new BlockingWaitStrategy() // 阻塞等待策略
// new SleepingWaitStrategy() // 休眠等待策略
// new YieldingWaitStrategy() // 谦让等待策略
// new BusySpinWaitStrategy() // 忙自旋等待策略,死循环
);
// 4个消费者
disruptor.handleEventsWithWorkerPool(
new Consumer(),
new Consumer(),
new Consumer(),
new Consumer()
);
disruptor.start();
// 生成数据
RingBuffer<PCData> ringBuffer = disruptor.getRingBuffer();
long size = 1000L;
// 2个生产者
new Thread(()->{
Producer producer = new Producer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for(long i = 0L;i<size;i++){
bb.putLong(0,i);
producer.pushData(bb);
System.out.println(Thread.currentThread().getName() + " - 产生数据:"+i);
}
}).start();
new Thread(()->{
Producer producer = new Producer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for(long i = size;i<2*size;i++){
bb.putLong(0,i);
producer.pushData(bb);
System.out.println(Thread.currentThread().getName() + " - 产生数据:"+i);
}
}).start();
}
}
~~~
总结:
1. 选择合适的策略,提高消费者的响应时间
```
new BlockingWaitStrategy() // 阻塞等待策略,省CPU
new SleepingWaitStrategy() // 休眠等待策略,中等延迟,自旋等待失败后休眠,不占用太多CPU
new YieldingWaitStrategy() // 谦让等待策略,低延迟,CPU物理核大于线程数
new BusySpinWaitStrategy() // 忙自旋等待策略,死循环,吃掉所有CPU资源
```
2. `Disruptor`对`Sequence`使用对齐填充的方式解决CPU缓存伪共享问题。
## CPU缓存伪共享
看下图,能知道`CPU缓存伪共享`的问题
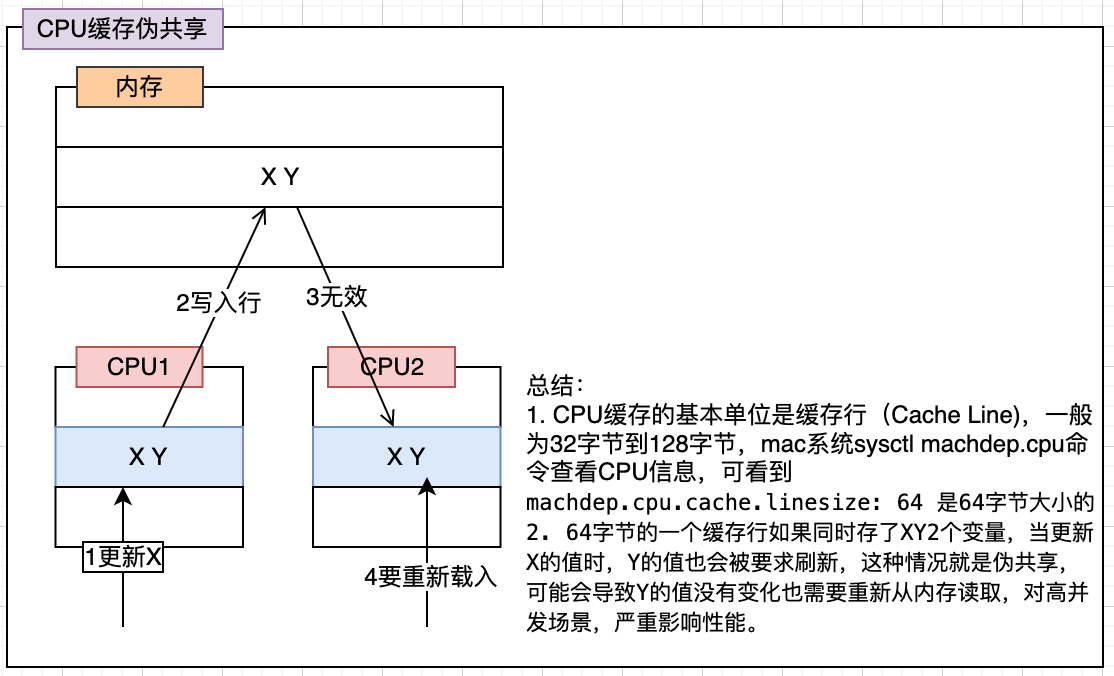
可以通过将存储的数据使用填充对齐到缓存行(64字节)大小,使得每个缓存行只存一个数据。
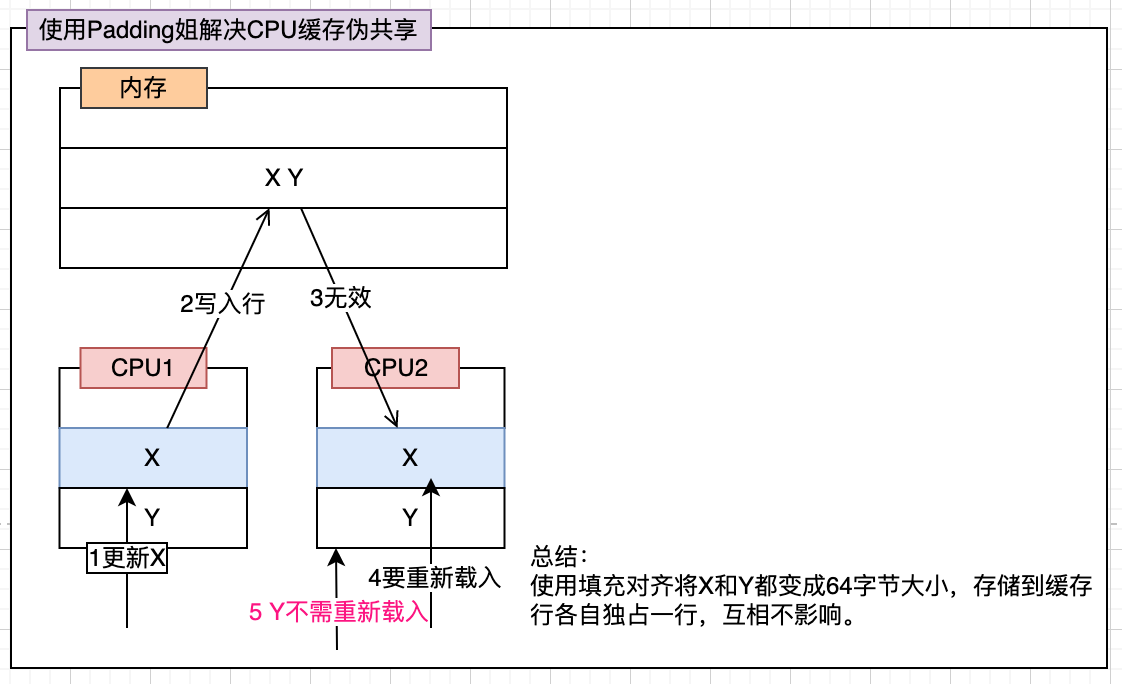
如下代码片段是`Disruptor`中`Sequence`继承的`RhsPadding`类,里面填充了7个`long`类型的值(一个`long`类型64位即8字节,补7个加上自己的一个工8个,合计64字节,刚好占一个缓存行大小)
~~~
class RhsPadding extends Value {
protected long p9;
protected long p10;
protected long p11;
protected long p12;
protected long p13;
protected long p14;
protected long p15;
RhsPadding() {
}
}
~~~
## 参考资料
* 书籍 葛一鸣 * 《Java高并发程序设计》
- 面试突击
- Java虚拟机
- 认识字节码
- 000Java发展历史
- 000Macos10.15.7上编译OpenJDK8u
- 001熟悉Java内存区域
- 002熟悉HotSpot中的对象
- 003Java如何计算对象大小
- 004垃圾判定算法与4大引用
- 005回收堆和方法区中对象
- 006垃圾收集算法
- 007HotSpot虚拟机垃圾算法实现篇1
- 007HotSpot虚拟机垃圾算法实现篇2
- 007HotSpot虚拟机垃圾算法实现篇3
- 008垃圾收集器
- 009内存分配与回收策略
- 010Java虚拟机相关工具
- 011调优案例分析
- 012一次IDEA的启动速度调优
- 013类文件Class的结构
- 014熟悉字节码指令
- 015类加载机制(过程)
- 016类加载器
- IDEA的JVM参数
- Java基础
- Java自动装箱与拆箱
- Java基础数据类型
- Java方法的参数传递
- Java并发
- 001走入并行的世界
- 002并行程序基础
- 003熟悉Java内存模型JMM
- 004Java并发之volatile关键字
- 005线程池入门到精通
- 006Java多线程间的同步控制方法
- 007Java维基准测试框架JMH
- 008Java并发容器
- 009Java的线程实现
- 010Java关键字synchronized
- 011一些并行模式的熟悉
- 单例模式和不变模式
- 生产者消费者模式
- Future模式
- 012一些并行算法的熟悉
- 面试总结
- 长亮一面