
[TOC]
## 常见API
```
//数据结构
Integer
Character
//操作
contains
equlas
//栈
Stack stack = new Stack
push
peek(不出)
pop
//队列
Queue queue = new LinkedList<>();
queue.offer
queue.peek(不出 )
queue.poll
// 比较
new Comparator() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
}
//遍历
for(Map.Entry entry : valueCountMap.entrySet()) {
if (entry.getValue() > nums.length/2) {
return entry.getKey;
}
}
StringBuilder res = new StringBuilder();
res.append(s.charAt(j));
```
## 位运行
本文解法基于此性质:二叉搜索树的中序遍历为 递增序列 。位运算只有5种运算:与、或、异或、左移、右移。与、或、异或运算的规律可以用下表总结:| 与(&) | 0 & 0 = 0 | 1 & 0 = 0 | 0 & 1 = 0 | 1 & 1 = 1 || 或(|) | 0 | 0 = 0 | 1 | 0 = 1 | 0 | 1 = 1 | 1 | 1 = 1 || 异或(^) | 0 ^ 0 = 0 | 1 ^ 0 = 1 | 0 ^ 1 = 1 | 1 ^ 1 = 0 |左移运算符m<<n表示把m左移n位。在左移n位的时候,最左边的n位会被丢弃,同时在最右边补上n个0。比如:00001010 << 2 = 0010100010001010 << 3 = 01010000
##二分算法
### 普通二分
https://leetcode-cn.com/problems/binary-search/solution/er-fen-cha-zhao-xiang-jie-by-labuladong/
这个场景是最简单的,肯能也是大家最熟悉的,即搜索一个数,如果存在,返回其索引,否则返回 -1。
```
int binarySearch(int[] nums, int target) {
int left = 0;
int right = nums.length - 1; // 注意
while(left <= right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // 注意
else if (nums[mid] > target)
right = mid - 1; // 注意
}
return -1;
}
```
1、为什么 while 循环的条件中是 <=,而不是 <?
答:因为初始化 right 的赋值是 nums.length - 1,即最后一个元素的索引,而不是 nums.length。
这二者可能出现在不同功能的二分查找中,区别是:前者相当于两端都闭区间 [left, right],后者相当于左闭右开区间 [left, right),因为索引大小为 nums.length 是越界的。
我们这个算法中使用的是前者 [left, right] 两端都闭的区间。这个区间其实就是每次进行搜索的区间。
什么时候应该停止搜索呢?当然,找到了目标值的时候可以终止:
if(nums[mid] == target)
return mid;
但如果没找到,就需要 while 循环终止,然后返回 -1。那 while 循环什么时候应该终止?搜索区间为空的时候应该终止,意味着你没得找了,就等于没找到嘛。
while(left <= right) 的终止条件是 left == right + 1,写成区间的形式就是 [right + 1, right],或者带个具体的数字进去 [3, 2],可见这时候区间为空,因为没有数字既大于等于 3 又小于等于 2 的吧。所以这时候 while 循环终止是正确的,直接返回 -1 即可。
while(left < right) 的终止条件是 left == right,写成区间的形式就是 [left, right],或者带个具体的数字进去 [2, 2],这时候区间非空,还有一个数 2,但此时 while 循环终止了。也就是说这区间 [2, 2] 被漏掉了,索引 2 没有被搜索,如果这时候直接返回 -1 就是错误的。
当然,如果你非要用 while(left < right) 也可以,我们已经知道了出错的原因,就打个补丁好了:
//...
while(left < right) {
// ...
}
return nums[left] == target ? left : -1;
2、为什么 left = mid + 1,right = mid - 1?我看有的代码是 right = mid 或者 left = mid,没有这些加加减减,到底怎么回事,怎么判断?
答:这也是二分查找的一个难点,不过只要你能理解前面的内容,就能够很容易判断。
刚才明确了「搜索区间」这个概念,而且本算法的搜索区间是两端都闭的,即 [left, right]。那么当我们发现索引 mid 不是要找的 target 时,下一步应该去搜索哪里呢?
当然是去搜索 [left, mid-1] 或者 [mid+1, right] 对不对?因为 mid 已经搜索过,应该从搜索区间中去除。
### 求边界二分
https://leetcode-cn.com/problems/find-first-and-last-position-of-element-in-sorted-array/solution/zhe-shi-er-fen-zui-zui-zui-jing-dian-de-xlvf3/
**求左边界:向下取整,等号归右,左加一
求右边界:向上取整,等号归左,右减一**
* 求左边界
```
int left = 0, right = n-1;
while(left < right){//求左边界(注意这里不要等号)
int mid = (left+right)>>1;//向下取整
if(nums[mid] >= target) right = mid;//等号归右
else left = mid+1;//左加一
}
//此时right即为所求
```
* 求右边界
```
int left = 0, right = n-1;
while(left<right){//求右边界(注意这里不要等号)
int mid = (left + right +1)>>1;//向上取整
if(nums[mid] <= target) left = mid;//等号归左
else right = mid-1;//右减一
}
//此时right即为所求
```
### 循环数组
[剑指 Offer 11. 旋转数组的最小数字](https://leetcode-cn.com/problems/xuan-zhuan-shu-zu-de-zui-xiao-shu-zi-lcof/)
## 单例模式
~~~
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
~~~
## 生产者消费者模型
生产者生产数据到缓冲区中,消费者从缓冲区中取数据。
如果缓冲区已经满了,则生产者线程阻塞;
如果缓冲区为空,那么消费者线程阻塞。
~~~
public interface ITaskQueue{
public void add();
public int remove();
}
public class Consumer extends Thread{
ITaskQueue queue;
public Consumer(ITaskQueue queue){
this.queue = queue;
}
public void run(){
while(true){
try {
Thread.sleep((long) (1000 * Math.random()));
} catch (InterruptedException e) {
e.printStackTrace();
}
queue.remove();
}
}
}
public class Producer extends Thread{
ITaskQueue queue;
public Producer(ITaskQueue queue){
this.queue = queue;
}
public void run(){
while(true){
try {
Thread.sleep((long) (1000 * Math.random()));
} catch (InterruptedException e) {
e.printStackTrace();
}
queue.add();
}
}
~~~
### 使用synchronized wait notify
~~~
public void TaskQueue1 implements ITaskQueue{
//当前资源数量
private int num = 0;
//资源池中允许存放的资源数目
private int size = 10;
public synchronized void add(){
if(num >= size){
wait();
}else{
num ++;
notifyAll();
}
}
public synchronized void remove(){
if(num <= 0){
wait();
}else{
num --;
notifyAll();
}
}
}
~~~
### 使用BlockingQueue
~~~
public void TaskQueue2 implements ITaskQueue{
private ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<>();
public void add(){
queue.put(1);
}
public void remove(){
queue.talke();
}
}
~~~
## 排序
https://leetcode-cn.com/problems/sort-an-array/
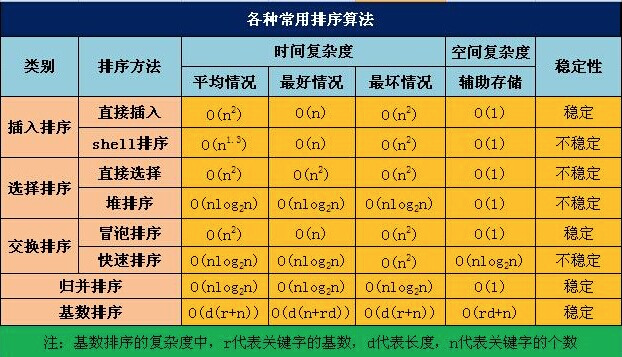
### 快排
1. 从数列中挑出一个元素,称为 “基准”(pivot);
2. 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
3. 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
```
public class QuickSort {
public static void quickSort(int[] arr,int low,int high){
int i,j,temp,t;
if(low>high){
return;
}
i=low;
j=high;
//temp就是基准位
temp = arr[low];
while (i<j) {
//先看右边,依次往左递减
while (temp<=arr[j]&&i<j) {
j--;
}
//再看左边,依次往右递增
while (temp>=arr[i]&&i<j) {
i++;
}
//如果满足条件则交换
if (i<j) {
t = arr[j];
arr[j] = arr[i];
arr[i] = t;
}
}
//最后将基准为与i和j相等位置的数字交换
arr[low] = arr[i];
arr[i] = temp;
//递归调用左半数组
quickSort(arr, low, j-1);
//递归调用右半数组
quickSort(arr, j+1, high);
}
public static void main(String[] args){
int[] arr = {10,7,2,4,7,62,3,4,2,1,8,9,19};
quickSort(arr, 0, arr.length-1);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
```
### 归并
1. 把长度为n的输入序列分成两个长度为n/2的子序列;
2. 对这两个子序列分别采用归并排序;
3. 将两个排序好的子序列合并成一个最终的排序序列。

### 大顶堆
## 二叉树
[二叉树的后序遍历(递归与非递归实现)](https://blog.csdn.net/LK274857347/article/details/77678464)
### 深度优先的遍历(栈)
#### 先序遍历
https://leetcode-cn.com/problems/binary-tree-preorder-traversal/
#### 中序遍历
https://leetcode-cn.com/problems/binary-tree-inorder-traversal/
#### 后序遍历
https://segmentfault.com/a/1190000016674584
好理解,双堆栈法
1. 用一个栈实现`根->右->左`的遍历
2. 用另一个栈将遍历顺序反过来,使之变成`左->右->根`
```
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> result = new LinkedList<>();
if (root == null) return result;
Stack<TreeNode> toVisit = new Stack<>();
Stack<TreeNode> reversedStack = new Stack<>();
toVisit.push(root);
TreeNode cur;
while (!toVisit.isEmpty()) {
cur = toVisit.pop();
reversedStack.push(cur); // result.add(cur.val);
if (cur.left != null) toVisit.push(cur.left); // 左节点入栈
if (cur.right != null) toVisit.push(cur.right); // 右节点入栈
}
while (!reversedStack.isEmpty()) {
cur = reversedStack.pop();
result.add(cur.val);
}
return result;
}
}
```
#### 层次遍历
### 广度优先的遍历(队列)
- Java
- Object
- 内部类
- 异常
- 注解
- 反射
- 静态代理与动态代理
- 泛型
- 继承
- JVM
- ClassLoader
- String
- 数据结构
- Java集合类
- ArrayList
- LinkedList
- HashSet
- TreeSet
- HashMap
- TreeMap
- HashTable
- 并发集合类
- Collections
- CopyOnWriteArrayList
- ConcurrentHashMap
- Android集合类
- SparseArray
- ArrayMap
- 算法
- 排序
- 常用算法
- LeetCode
- 二叉树遍历
- 剑指
- 数据结构、算法和数据操作
- 高质量的代码
- 解决问题的思路
- 优化时间和空间效率
- 面试中的各项能力
- 算法心得
- 并发
- Thread
- 锁
- java内存模型
- CAS
- 原子类Atomic
- volatile
- synchronized
- Object.wait-notify
- Lock
- Lock之AQS
- Lock子类
- 锁小结
- 堵塞队列
- 生产者消费者模型
- 线程池