#### 1. 各浏览器使用的JavaScript引擎以及它们的异同点、如何在代码中进行区分
#### 2. 请求数据到请求结束与服务器了几次交互
#### 3. 可详细描述浏览器从输入URL到页面展现的详细过程
1. 浏览器根据输入的URL地址交给DNS服务器进行域名解析,得到服务器IP地址
2. 与服务器建立TCP连接,浏览器发起请求
3. 服务器响应浏览器请求,浏览器根据解析DOM,响应内的内容如果有CSS,JS,IMG等资源继续向服务器进行请求
4. 将响应回来的结果进行渲染合成,布局、绘制,最后在浏览器进行呈现
#### 4. 浏览器解析HTML代码的原理,以及构建DOM树的流程
#### 5. 浏览器如何解析CSS规则,并将其应用到DOM树上
#### 6. 浏览器如何解析好的带有样式的DOM树进行绘制
#### 7. 浏览器的运行机制,如何配置资源异步同步加载
#### 8. 浏览器回流与重绘的底层原理,引发原因,如何有效避免
1. 重绘:当render tree的一些元素属性需要更新,而这些属性只是影响元素的外观,风格,而不会影响布局的,比如background-color。则称为重绘
2. 回流:页面元素的大小位置发生改变,则会触发回流
1. 盒子模型相关属性会触发重布局
2. 定位属性及浮动也会触发重布局
3. 改变节点内部文字结构也会触发重布局
4. width height padding margin top bottom text-align overflow-y line-height...
3. -----回流必将会引起重绘,而重绘不一定会引起回流-----
#### 9. 浏览器的垃圾回收机制,如何避免内存泄漏
1. 垃圾回收:是程序运行时所需要占用的内存,当程序中的变量不需要时应该释放掉,或者多个对象循环引用,但程序也用不到他们,它们也应该被释放掉
2. JS常用垃圾回收机制法:标记清除法、引用计数法
3. 标记清除法:js中最常用的垃圾回收方式就是标记清除。当变量进入环境时,例如,在一个函数中声明一个变量,就将这个变量标记为"进入环境",从逻辑上讲,永远不能释放进入环境变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为"离开环境"。
```
function test(){
var a = 10 //被标记"进入环境"
var b = "hello" //被标记"进入环境"
}
test() //执行完毕后之后,a和b又被标记"离开环境",被回收
```
4. 引用计数法:JS引擎有一张"引用表",保存了内存里面所有资源(通常是各种值)的引用次数。如果一个值的引用次数是0,就表示这个值不再用到了,因此可以将这块内存释放。
5. 虽然有了垃圾回收机制,但还是需要关注内存占用:那些很占空间的值,一旦不再用到,你必须检查是否还存在对它们的引用。如果是的话,就必须手动解除引用
#### 10. 浏览器采用的缓存方案,如何选择和控制合适的缓存方案
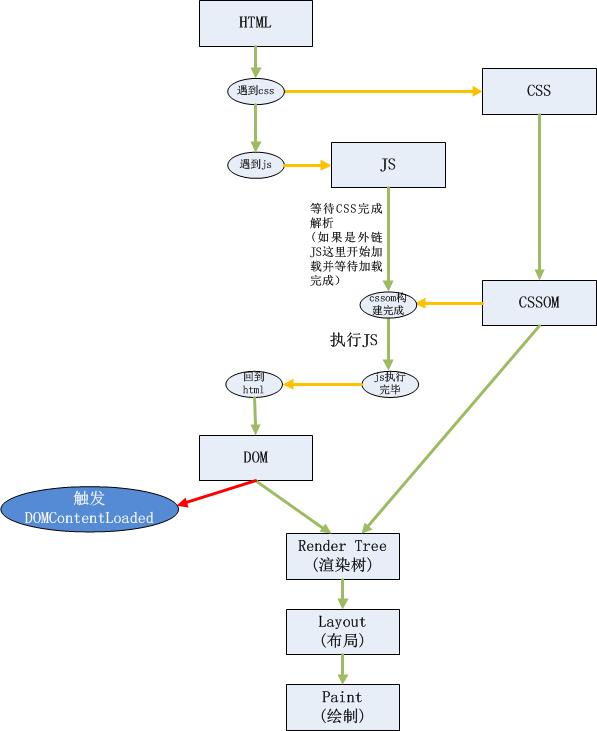
### 浏览器从网络中接收HTML文件之后的一系列转换过程
1. 在网络传输中传输的都是0和1这类字节
2. 浏览器接收到这些字节将其转换为字符串,字符串就是我们写的代码
3. 浏览器会先将这些字符串通过词法分析转换为标记,给每一段代码打上标记
4. 标记结束后,会紧接着转换为Node节点,构成DOM树
5. 字符数据 => 字符串数据 => token(标记) => Node(节点) => DOM
### 浏览器解析CSS
1. span { color: red }
浏览器只需要找到所有span标签所设置样式即可,效率高
2. div > p > span { color: red }
浏览器需要递归去寻找符合条件的元素,查找效率低,先找到所有的span标签,再找到span上的p标签,再找到p标签上的div标签,给这些符合条件的span标签设置样式,所以尽量避免写过于复杂的CSS选择器
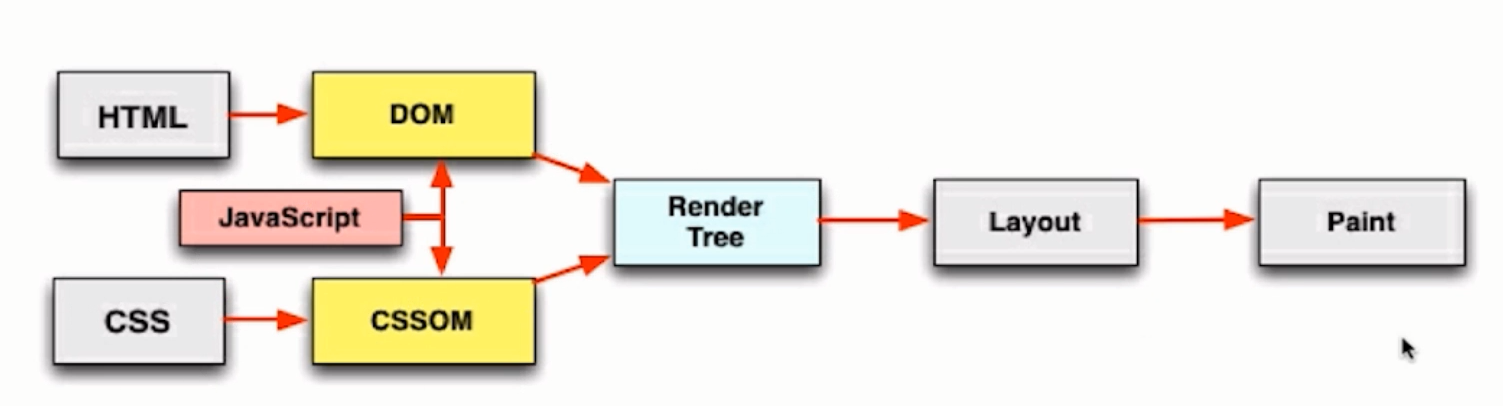
### RenderTree:渲染树
1. DOM树与CSSOM树生成之后浏览器将其生成RenderTree(渲染树),渲染树只会生成需要显示的元素,
生成渲染树之后,浏览器就会根据渲染树来进行布局,也可以叫**回流**
#### CSS阻塞
1. CSS head中阻塞页面的渲染
2. CSS阻塞JS的执行,因为JS的操作很有可能是操作HTML与CSS合成后的DOM,所以会阻塞理论上是可行的
3. CSS不阻塞JS的加载
#### JS阻塞
1. 直接引入的JS阻塞页面的渲染:因为JS很有可能会操作页面文档,所以HTML parse会停止解析,等待JS执行完成再继续渲染
2. JS不阻塞其它资源的加载
3. JS顺序执行,阻塞后续JS逻辑的执行
### URL中的参数
1. 路径参数:/url/:id/url2/:id2
2. 查询参数:?后面的key value
#### Chrome创建图层的条件
----图层不能滥用,会造成图层合成时间过久,频繁渲染的元素包裹在一个图层里面是有助于区域重绘回流的---
1. 3D或透视变换CSS属性( perspective transform )
2. 使用加速视频解码的<video>节点
3. 拥有3D( WebGL )上下文或加速的2D上下文的<canvas>节点
4. 对元素触发图层:transform:translateZ || will-change:transform
#### 文档页面加载事件
1. DOMContentLoaded:触发时机:DOM解析完成时触发 DOMContentLoaded 事件
2. load:触发时机:页面上的资源都加载完成时才会触发
#### 9. 改变阻塞模式:defer && async
1. defer:加载与async相同,不同的是加载完并非立即执行,而是在页面解析完成,`DOMContentLoaded`事件之前进行加载,多个defer属性的外链脚本会按照顺序执行
2. async:当遇到<script async src="1.js">时,与其它并行加载,加载完成后立即执行,不管HTML处于解析阶段还是DOMContentLoaded事件之后,执行1.js,但一定会在 load 事件之前进行执行
3. 动态创建DOM
4. 按需异步引入JS
5. defer、async对于inline->script标签无效
#### 10. JS延迟加载的方式:
1. doucment.createElement( 'script' ) //动态创建的脚本就是异步的,可以将些脚本设置为同步
2. XMLHttpRequest异步请求JS文件
#### 2. 为什么操作DOM慢:
1. 因为JS引擎和渲染引擎是两个不同的引擎,需要跨引擎通信,不管是操作还是获取
