
相关配置如下:
```
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
#order_by_column: id #排序字段,存量数据同步时不能为空
#column_lower_case:false #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
column_underscore_to_camel: true #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
#include_columns: ID,USER_NAME,PASSWORD
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
#column_mappings: USER_NAME=account #列名称映射,多个映射关系用逗号分隔,如:USER_NAME=account 表示将字段名USER_NAME映射为account
#default_column_values: source=binlog,area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
value_encoder: json #值编码,支持json、kv-commas、v-commas;默认为json
#value_formatter: '{{.ID}}|{{.USER_NAME}}' # 值格式化表达式,如:{{.ID}}|{{.USER_NAME}},{{.ID}}表示ID字段的值、{{.USER_NAME}}表示USER_NAME字段的值
#kafka相关
kafka_topic: user_topic #rocketmq topic,可以为空,默认使用表名称
#reserve_raw_data: false #保留update之前的数据,针对rocketmq、kafka、rabbitmq有用;默认为false
```
其中,
value_encoder表示值编码格式,支持json、kv-commas、v-commas三种格式,不填写默认为json,具体如下表:
<table>
<tr>
<th width="15%">格式</th>
<th width="20%">说明</th>
<th>举例</th>
</tr>
<td>json</td>
<td>json</td>
<td>{"id": "1001","userName": "admin","password": "123456",
"createTime": "2020-07-20 14:29:19"}</td>
</tr>
<tr>
<td>kv-commas</td>
<td>key-value逗号分隔</td>
<td>id=1001,userName=admin,password=123456,createTime=2020-07-20 14:29:19</td>
</tr>
<tr>
<td>v-commas</td>
<td>value逗号分隔</td>
<td>1001,admin,123456,2020-07-20 14:29:19</td>
</tr>
</table>
value_formatter表示值的格式化表达式,具体模板语法参见"表达式模板"章节,当value_formatter不为空时value_encoder无效。
reserve_raw_data表示是否保留update之前的数据,即保留修改之前的老数据,默认不保留
# **示例**
t_user表,数据如下:
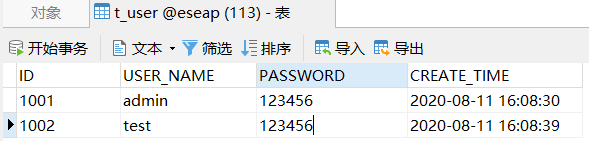
## **示例一**
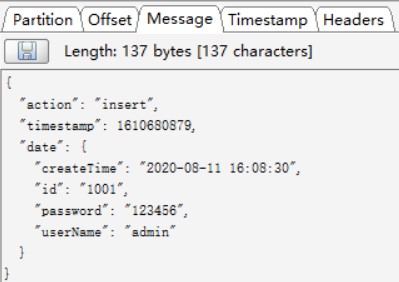
使用上述配置
insert事件,同步到Kafka的数据如下:
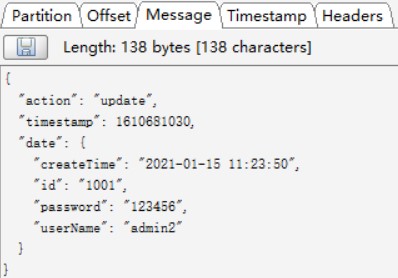
update事件,同步到Kafka的数据如下:
reserve_raw_data设置为true,update事件,同步到Kafka的数据如下:
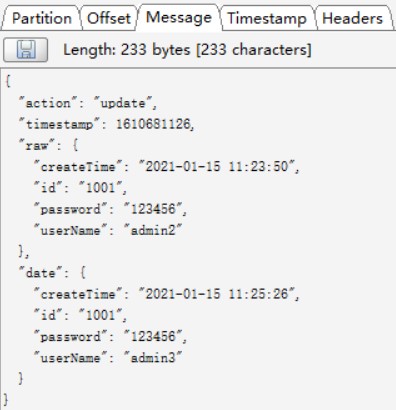
其中,raw属性为update之前的旧数据
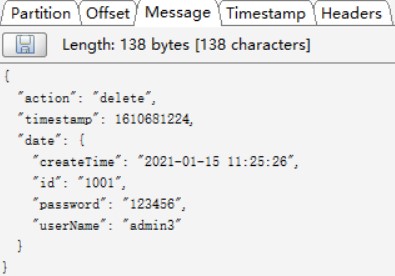
delete事件,同步到Kafka的数据如下:
## **示例二**
配置如下:
```
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
#order_by_column: id #排序字段,存量数据同步时不能为空
column_lower_case: true #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
#column_underscore_to_camel: true #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
#include_columns: ID,USER_NAME,PASSWORD
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
column_mappings: USER_NAME=account #列名称映射,多个映射关系用逗号分隔,如:USER_NAME=account 表示将字段名USER_NAME映射为account
default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
value_encoder: json #值编码,支持json、kv-commas、v-commas;默认为json
#value_formatter: '{{.ID}}|{{.USER_NAME}}' # 值格式化表达式,如:{{.ID}}|{{.USER_NAME}},{{.ID}}表示ID字段的值、{{.USER_NAME}}表示USER_NAME字段的值
#kafka相关
kafka_topic: user_topic #rocketmq topic,可以为空,默认使用表名称
#reserve_raw_data: false #保留update之前的数据,针对rocketmq、kafka、rabbitmq有用;默认为false
```
其中,
column_mappings表示对列名称进行重新映射
insert事件,同步到Kafka的数据如下:
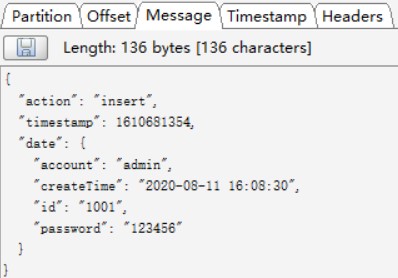
其中,属性名称USER\_NAME变为了account
## **示例三**
配置如下:
```
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
#order_by_column: id #排序字段,存量数据同步时不能为空
column_lower_case: true #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
#column_underscore_to_camel: true #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
#include_columns: ID,USER_NAME,PASSWORD
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
#column_mappings: USER_NAME=account #列名称映射,多个映射关系用逗号分隔,如:USER_NAME=account 表示将字段名USER_NAME映射为account
default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
value_encoder: v-commas #值编码,支持json、kv-commas、v-commas;默认为json
#value_formatter: '{{.ID}}|{{.USER_NAME}}|{{.REAL_NAME}}|{{if eq .STATUS 0}}停用{{else}}启用{{end}}'
#kafka相关
kafka_topic: user_topic #rocketmq topic,可以为空,默认使用表名称
#reserve_raw_data: false #保留update之前的数据,针对rocketmq、kafka、rabbitmq有用;默认为false
```
其中,
value_encoder表示消息编码方式
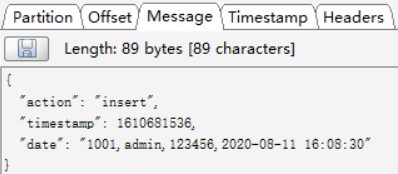
insert事件,同步到Kafka的数据如下:
- 简介
- 部署运行
- 高可用集群
- 同步数据到Redis
- Redis配置
- 基于规则同步
- 基于Lua脚本同步
- 同步数据到MongoDB
- MongoDB配置
- 基于规则同步
- 基于Lua脚本同步
- 同步数据到RocketMQ
- RocketMQ配置
- 基于规则同步
- 基于Lua脚本同步
- 同步数据到Kafka
- Kafka配置
- 基于规则同步
- 基于Lua脚本同步
- 同步数据到RabbitMQ
- RabbitMQ配置
- 基于规则同步
- 基于Lua脚本同步
- 同步数据到Elasticsearch
- Elasticsearch配置
- 基于规则同步
- 基于Lua脚本同步
- 全量数据导入
- Lua脚本
- 基础模块
- Json模块
- HttpClient模块
- DBClient模块
- 监控
- 性能测试
- 常见问题
- 更新记录开发计划