
相关配置如下:
```
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
#order_by_column: id #排序字段,存量数据同步时不能为空
#column_lower_case: true #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
column_underscore_to_camel: true #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
#include_columns: ID,USER_NAME,PASSWORD
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
#default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
#Elasticsearch相关
es_index: user_index #Index名称,可以为空,默认使用表(Table)名称
#es_mappings: #索引映射,可以为空,为空时根据数据类型自行推导ES推导
# -
# column: REMARK #数据库列名称
# field: remark #映射后的ES字段名称
# type: text #ES字段类型
# analyzer: ik_smart #ES分词器,type为text此项有意义
# #format: #日期格式,type为date此项有意义
# -
# column: USER_NAME #数据库列名称
# field: account #映射后的ES字段名称
# type: keyword #ES字段类型
```
# **示例**
t_user表,数据如下:

## **示例一**
使用上述配置
自动创建的Mapping,如下:
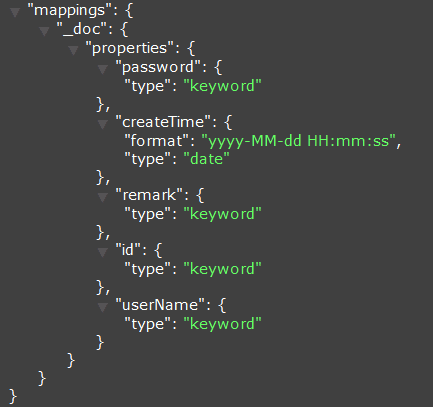
同步到Elasticsearch的数据如下:

## **示例二**
配置如下:
```
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
order_by_column: id #排序字段,存量数据同步时不能为空
column_lower_case: true #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
#column_underscore_to_camel: true #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
#include_columns: ID,USER_NAME,PASSWORD
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
#Elasticsearch相关
es_index: user_index #Index名称,可以为空,默认使用表(Table)名称
es_mappings: #索引映射,可以为空,为空时根据数据类型自行推导ES推导
-
column: REMARK #数据库列名称
field: remark #映射后的ES字段名称
type: text #ES字段类型
analyzer: ik_smart #ES分词器,type为text此项有意义
#format: #日期格式,type为date此项有意义
-
column: USER_NAME #数据库列名称
field: account #映射后的ES字段名称
type: keyword #ES字段类型
```
es_mappings配置项表示定义索引的mappings(映射关系),不定义es_mappings则使用列类型自动创建索引的mappings(映射关系)。
创建的Mapping,如下:
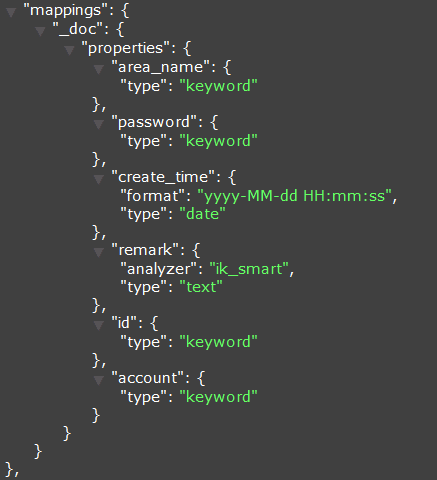
同步到Elasticsearch的数据如下:

- 简介
- 部署运行
- 高可用集群
- 同步数据到Redis
- Redis配置
- 基于规则同步
- 基于Lua脚本同步
- 同步数据到MongoDB
- MongoDB配置
- 基于规则同步
- 基于Lua脚本同步
- 同步数据到RocketMQ
- RocketMQ配置
- 基于规则同步
- 基于Lua脚本同步
- 同步数据到Kafka
- Kafka配置
- 基于规则同步
- 基于Lua脚本同步
- 同步数据到RabbitMQ
- RabbitMQ配置
- 基于规则同步
- 基于Lua脚本同步
- 同步数据到Elasticsearch
- Elasticsearch配置
- 基于规则同步
- 基于Lua脚本同步
- 全量数据导入
- Lua脚本
- 基础模块
- Json模块
- HttpClient模块
- DBClient模块
- 监控
- 性能测试
- 常见问题
- 更新记录开发计划