
## 列表生成式
~~~
a = [i+1 for i in range(10)]
~~~
通过列表生成式,我们可以直接快速的创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就可以直接创建一个对象而不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
## 生成器
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的`[]`改成`()`,就创建了一个generator:

我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?如果要一个一个打印出来,可以通过`next()`函数获得generator的下一个返回值:
我们讲过,generator保存的是算法,每次调用`next()`,就计算出a的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出`StopIteration`的错误。
当然,也使用`for`循环,因为generator也是可迭代对象:
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的`for`循环无法实现的时候,还可以用函数来实现。比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
~~~
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
~~~
~~~
>>> fib(10)
1
1
2
3
5
8
13
21
34
55
done
~~~
仔细观察,可以看出,`fib`函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
也就是说,上面的函数和generator仅一步之遥。要把`fib`函数变成generator,只需要把`print(b)`改为`yield b`就可以了:
~~~
def fib(max):
n,a,b = 0,0,1
while n < max:
yield b
a,b = b,a+b
n += 1
return 'done'
~~~
~~~
>>> f = fib(6)
>>> f
<generator object fib at 0x104feaaa0>
~~~
这就是定义generator的另一种方法。如果一个函数定义中包含`yield`关键字,那么这个函数就不再是一个普通函数,而是一个generator。这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到`return`语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用`next()`的时候执行,遇到`yield`语句返回,再次执行时从上次返回的`yield`语句处继续执行。同样的我们也可以用`next()方法`来获取下一个返回值,或者也可以直接使用`for`循环来迭代。
PS:用`for`循环调用generator时,拿不到generator的`return`语句的返回值。如果想要拿到返回值,必须捕获`StopIteration`错误,返回值会包含在`StopIteration`的`value`中:
~~~
>>> g = fib(6)
>>> while True:
... try:
... x = next(g)
... print('g:', x)
... except StopIteration as e:
... print('Generator return value:', e.value)
... break
...
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done
~~~
## 可迭代对象
我们已经知道,可以直接作用于`for`循环的数据类型有以下几种:
一类是集合数据类型,如`list`、`tuple`、`dict`、`set`、`str`等;
一类是`generator`,包括生成器和带`yield`的generator function。
这些可以直接作用于`for`循环的对象统称为可迭代对象:`Iterable`。可以使用`isinstance()`判断一个对象是否是`Iterable`对象:
~~~
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
~~~
而生成器不但可以作用于`for`循环,还可以被`next()`函数不断调用并返回下一个值,直到最后抛出`StopIteration`错误表示无法继续返回下一个值了。
**所以,可以被`next()`函数调用并不断返回下一个值的对象称为迭代器:`Iterator`**。
## 迭代器
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件
特点:
1. 访问者不需要关心迭代器内部的结构,仅需通过next()方法不断去取下一个内容
2. 不能随机访问集合中的某个值 ,只能从头到尾依次访问
3. 访问到一半时不能往回退
4. 便于循环比较大的数据集合,节省内存
可以使用`isinstance()`判断一个对象是否是`Iterator`对象:
~~~
>>> from collections import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True
>>> isinstance([], Iterator)
False
>>> isinstance({}, Iterator)
False
>>> isinstance('abc', Iterator)
False
~~~
生成器都是`Iterator`对象,但`list`、`dict`、`str`虽然是`Iterable`,却不是`Iterator`。
把`list`、`dict`、`str`等`Iterable`变成`Iterator`可以使用`iter()`函数:
~~~
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True
~~~
你可能会问,为什么`list`、`dict`、`str`等数据类型不是`Iterator`?
这是因为Python的`Iterator`对象表示的是一个数据流,Iterator对象可以被`next()`函数调用并不断返回下一个数据,直到没有数据时抛出`StopIteration`错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过`next()`函数实现按需计算下一个数据,所以`Iterator`的计算是惰性的,只有在需要返回下一个数据时它才会计算。
`Iterator`甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
## 小结

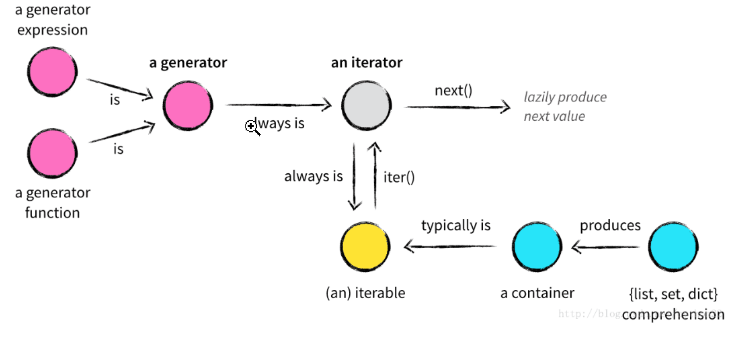
* 凡是可作用于`for`循环的对象都是`Iterable`类型;
* 凡是可作用于`next()`函数的对象都是`Iterator`类型;
* 迭代器对象一定是可迭代对象,但是可迭代对象不一定是迭代器对象;
* 生成器对象一定是迭代器对象,但是迭代器对象不一定是生成器对象;
* 集合数据类型如`list`、`dict`、`str`等是`Iterable`但不是`Iterator`,不过可以通过`iter()`函数获得一个`Iterator`对象;
- Python学习
- Python基础
- Python初识
- 列表生成式,生成器,可迭代对象,迭代器详解
- Python面向对象
- Python中的单例模式
- Python变量作用域、LEGB、闭包
- Python异常处理
- Python操作正则
- Python中的赋值与深浅拷贝
- Python自定义CLI三方库
- Python并发编程
- Python之进程
- Python之线程
- Python之协程
- Python并发编程与IO模型
- Python网络编程
- Python之socket网络编程
- Django学习
- 反向解析
- Cookie和Session操作
- 文件上传
- 缓存的配置和使用
- 信号
- FBV&&CBV&&中间件
- Django补充
- 用户认证
- 分页
- 自定义搜索组件
- Celery
- 搭建sentry平台监控
- DRF学习
- drf概述
- Flask学习
- 项目拆分
- 三方模块使用
- 爬虫学习
- Http和Https区别
- 请求相关库
- 解析相关库
- 常见面试题
- 面试题
- 面试题解析
- 网络原理
- 计算机网络知识简单介绍
- 详解TCP三次握手、四次挥手及11种状态
- 消息队列和数据库
- 消息队列之RabbitMQ
- 数据库之Redis
- 数据库之初识MySQL
- 数据库之MySQL进阶
- 数据库之MySQL补充
- 数据库之Python操作MySQL
- Kafka常用命令
- Linux学习
- Linux基础命令
- Git
- Git介绍
- Git基本配置及理论
- Git常用命令
- Docker
- Docker基本使用
- Docker常用命令
- Docker容器数据卷
- Dockerfile
- Docker网络原理
- docker-compose
- Docker Swarm
- HTML
- CSS
- JS
- VUE