> YZMCMS跟大多数CMS一样,所以具体如何使用不多做介绍,只介绍局部。
> 使用YZMCMS的人群基础不同,但后台对所有人来讲,只要能看懂中文,应该都没问题。
> 如果有疑问,也请先把后台所有功能先看一遍,亲自尝试。
* ### 采集模块
YZMCMS自带的采集只具备基础功能,所以不要有过高期待,如果要采集大量文章,请联系群主定制功能更好的采集功能。
个人觉得DOM采集方式最方便,具体可参考DZ的DXC采集插件。
项目名称:随意填写
采集页面编码:查看采集页面源代码可看到,要保持一致
列表规则:可变化的页数网址用通配符代替
区域开始HTML:
区域结束HTML:
这个是为了识别到开始和结束区域内的内容页链接,要求HTML具有页面唯一性,这样才能正确识别到。
网址中包含:因为规则中没有具体指明以什么标记识别网址,所以这个区域内所有的超链接都会被识别到,可能会有我们不需要的网址。比如示例中会识别到作者链接http://bbs.yzmcms.com/member/myhome/init/userid/198.html
而我们需要的内容页链接为http://bbs.yzmcms.com/bbs/index/show/id/190.html,所以查看区别后,我们需要网址中包含/id/,这样才是我们要的网址
网址中不包含:道理一样
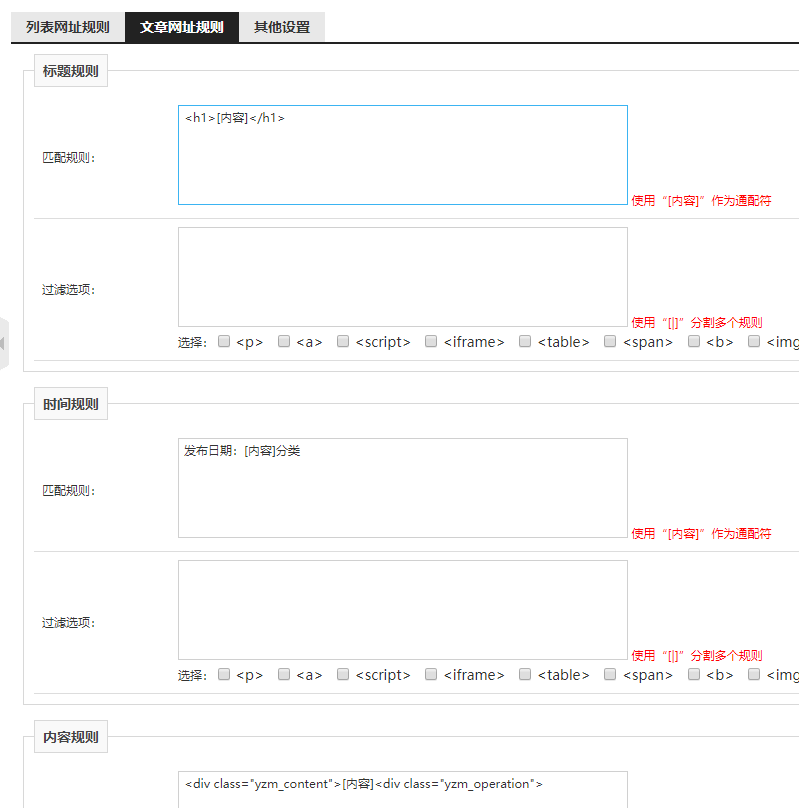
标题规则:包含在h1中,且唯一
时间规则:在“发布日期:”和“分类”之间。
内容规则:包含在和中(如果内容里没有其他DIV标签,我们也可以以为结束标签,即使它不唯一。)
* **
### 欢迎补充
