
  在软件的编码和实现中,我们可能会碰到个 一个比较头疼的问题--编码,不同字符间的编码和解码,你确定了解各种字符的编码吗?一个朋友问到了我这 个问题,我虽然能回答一两个出来,但是感觉已经有点模糊,混乱了,在网上搜了搜,在书上翻了翻,总结一下吧。首先按照字符编码的历程来看:
**1. ASCII**
  我们需要了解的最早编码是ASCII码。它用7个二进制位来表示,由于那个时期生产的大多数计算机使用8位大小的字节,因此用户不仅可以存放所有 可能的ASCII字符,而且有整整一位空余下来。如果你技艺高超,可以将该位用做自己离奇的目的:WordStar中那个发暗的灯泡实际上设置这个高位, 以指示一个单词中的最后一个字母,同时这也宣示了WordStar只能用于英语文本。
  由于字节有多达8位的空间,因此许多人在想:“呀!我们 可以把128~255之间的编码用做个人的应用目的。”问题在于,同时产生这种想法的人相当多,而且在128~255之间的各个位置上应该存放什么这一问 题上,真是仁者见仁智者见智。事实上,只要人们开始在美国以外的地方购买计算机,那么各种各样的不同OEM字符集都会进入规划设计行列,并且各人都会根据 自己的需要使用高位的128个字符。如此一来,甚至在同语种的文档之间就不容易实现互换。 ASCII可被扩展,最优秀的扩展方案是ISO 8859-1,通常称之为Latin-1。Latin-1包括了足够的附加字符集来写基本的西欧语言。
  最后,这个人人参与的OEM终于以ANSI标准的形式形成文件。在ANSI标准中,每个人都认同如何使用低端的128个编码,这与ASCII相当一致。不过,根据所在国籍的不同,处理编码128以上的字符有许多不同的方式。这些不同的系统称为代码页。
  同时,甚至更为令人头疼的事情正在逐步上演,亚洲国家的字符表有成千上万个字符,这样的字符表是用8位二进制无法表示的。该问题的解决通常有赖于称为DBCS(double byte character set,双字节字符集)的繁杂字符系统。
  不过,仍然需要指出一点,多数人还是姑且认为一个字节就是一个字符,以及一个字符就是8个二进制位,并且只要确保不将字符串从一台计算机移植到另一台计 算机,或者说一种以上的语言,那么这几乎总是可以凑合。当然,只要一进入Internet,从一台计算机向另一台计算机移植字符串就成为家常便饭了,而各 种复杂状况也随之呈现出来。令人欣慰的是,Unicode随即问世了。
  作用:表语英语及西欧语言。
  位数:ASCII是用7位表示的,能表示128个字符;其扩展使用8位表示,表示256个字符。
  范围:ASCII从00到7F,扩展从00到FF。
**2.iso8859-1**
  属于单字节编码,最多能表示的字符范围是0-255,应用于英文系列。比如,字母'a'的编码为0x61=97。
  很明显,iso8859-1编码表示的字符范围很窄,无法表示中文字符。但是,由于是单字节编码,和计算机最基础的表示单位一致,所以很多时候,仍 旧使用iso8859-1编码来表示。而且在很多协议上,默认使用该编码。比如,虽然"中文"两个字不存在iso8859-1编码,以gb2312编码为 例,应该是"d6d0 cec4"两个字符,使用iso8859-1编码的时候则将它拆开为4个字节来表示:"d6 d0 ce c4"(事实上,在进行存储的时候,也是以字节为单位处理的)。而如果是UTF编码,则是6个字节"e4 b8 ad e6 96 87"。很明显,这种表示方法还需要以另一种编码为基础。
  作用:扩展ASCII,表示西欧、希腊语等。
  位数:8位,
  范围:从00到FF,兼容ASCII字符集。
**3\. GB码字符集**
  全称是GB2312-80《信息交换用汉字编码字符集基本集》,1980年发布,是中文信息处理的国家标准,在大陆及海外使用简体中文的地区(如新加坡 等)是强制使用的唯一中文编码。P-Windows3.2和苹果OS就是以GB2312为基本汉字编码, Windows 95/98则以GBK为基本汉字编码、但兼容支持GB2312。
双字节编码
范围:A1A1~FEFE
A1-A9:符号区,包含682个符号
B0-F7:汉字区,包含6763个汉字
**4.GB2312字符集**
  GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从 A1-FE,占用的码位是72\*94=6768。其中有5个空位是D7FA-D7FE。GB2312-80中共收录了7545个字符,用两个字节编码一个 字符。每个字符最高位为0。GB2312-80编码简称国标码。
  GB2312支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。
  作用:国家简体中文字符集,兼容ASCII。
  位数:使用2个字节表示,能表示7445个符号,包括6763个汉字,几乎覆盖所有高频率汉字。
  范围:高字节从A1到F7, 低字节从A1到FE。将高字节和低字节分别加上0XA0即可得到编码。
**5\. GB12345-90字符集**
  1990年制定了繁体字的编码标准GB12345-90《信息交换用汉字编码字符集第一辅助集》,目的在于规范必须使用繁体字的各种场合,以及古籍整理 等。该标准共收录6866个汉字(比GB2312多103个字,其它厂商的字库大多不包括这些字),纯繁体的字大概有2200余个。
双字节编码
范围:A1A1~FEFE
A1-A9:符号区,增加竖排符号
B0-F9:汉字区,包含6866个汉字
**6.GBK字符集**
  GBK编码(Chinese Internal Code Specification)是中国大陆制订的、等同于UCS的新的中文编码扩展国家标准。gbk编码能够用来同时表示繁体字和简体字,而gb2312只 能表示简体字,gbk是兼容gb2312编码的。GBK工作小组于1995年10月,同年12月完成GBK规范。该编码标准兼容GB2312,共收录汉字 21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。Windows95/98简体中文版的字库表层编码就采用的是GBK,通过 GBK与UCS之间一一对应的码表与底层字库联系。
英文名:Chinese Internal Code Specification
中文名:汉字内码扩展规范1.0版
双字节编码,GB2312-80的扩充,在码位上和GB2312-80兼容
范围:8140~FEFE(剔除xx7F)共23940个码位
包含21003个汉字,包含了ISO/IEC 10646-1中的全部中日韩汉字
  作用:它是GB2312的扩展,加入对繁体字的支持,兼容GB2312。
  位数:使用2个字节表示,可表示21886个字符。
  范围:高字节从81到FE,低字节从40到FE。
**7\. BIG5字符集**
  是目前台湾、香港地区普遍使用的一种繁体汉字的编码标准,包括440个符号,一级汉字5401个、二级汉字7652个,共计13060个汉字。BIG5又 称大五码或五大码,1984年由台湾财团法人信息工业策进会和五间软件公司宏碁 (Acer)、神通 (MiTAC)、佳佳、零壹 (Zero One)、大众 (FIC)创立,故称大五码。Big5码的产生,是因为当时台湾不同厂商各自推出不同的编码,如倚天码、IBM PS55、王安码等,彼此不能兼容;另一方面,台湾政府当时尚未推出官方的汉字编码,而中国大陆的GB2312编码亦未有收录繁体中文字。
  Big5字符集共收录13,053个中文字,该字符集在中国台湾使用。耐人寻味的是该字符集重复地收录了两个相同的字:“兀”(0xA461及0xC94A)、“嗀”(0xDCD1及0xDDFC)。
  Big5码使用了双字节储存方法,以两个字节来编码一个字。第一个字节称为“高位字节”,第二个字节称为“低位字节”。高位字节的编码范围0xA1-0xF9,低位字节的编码范围0x40-0x7E及0xA1-0xFE。
  尽管Big5码内包含一万多个字符,但是没有考虑社会上流通的人名、地名用字、方言用字、化学及生物科等用字,没有包含日文平假名及片假字母。
  例如台湾视“着”为“著”的异体字,故没有收录“着”字。康熙字典中的一些部首用字(如“亠”、“疒”、“辵”、“癶”等)、常见的人名用字(如“堃”、“煊”、“栢”、“喆”等) 也没有收录到Big5之中。
**8.GB18030字符集**
  GB 18030-2000全称是《信息技术信息交换用汉字编码字符集基本集的扩充》,由信息产业部和原国家质量技术监督局于2000年3月17日联合发布,作为国家强制性标准自发布之日起实施。
  为了适应信息处理技术快速发展的需要,1998年10月,由信息产业部电子四所、北京大学计算机技术研究所、北大方正集团、新天地公司、四通新世纪公司、 中科院软件所、长城软件公司、中软总公司、金山软件公司和联想公司的技术人员组成标准起草组。在标准研制过程中,全国信息技术标准化技术委员会多次召集标 准起草组和知名公司对标准草案进行充分地研究论证,并且特邀了微软公司、惠普公司、Sun公司和IBM公司等参加,广泛征求意见。标准起草组经过反复斟酌 和验证,提出了标准制定原则——与GB 2312信息处理交换码所对应的事实上的内码标准兼容,在字汇上支持GB 13000.1的全部中、日、韩(CJK)统一汉字字符和全部CJK扩充A的字符,并且确定了编码体系和27484个汉字,形成兼容性、扩展性、前瞻性兼 备的方案。
  该标准采用单字节、双字节和四字节三种方式对字符编码。
  作用:它解决了中文、日文、朝鲜语等的编码,兼容GBK。
  位数:它采用变字节表示(1 ASCII,2,4字节)。可表示27484个文字。
  范围:1字节从00到7F; 2字节高字节从81到FE,低字节从40到7E和80到FE;4字节第一三字节从81到FE,第二四字节从30到39。
**9.通用字符集(UCS)** **字符集**
  ISO/IEC 10646-1 \[ISO-10646\]定义了一种多于8比特字节的字符集,称作通用字符集(UCS),它包含了世界上大多数可书写的字符系统。已定义了两种多8比特字节 编码,对每一个字符采用四个8比特字节编码的称为UCS-4,对每一个字符采用两个8比特字节编码的称为UCS-2。它们仅能够对UCS的前64K字符进 行编址,超出此范围的其它部分当前还没有分配编址。
  作用:国际标准 ISO 10646 定义了通用字符集 (Universal Character Set)。它是与UNICODE同类的组织,UCS-2和UNICODE兼容。
  位数:它有UCS-2和UCS-4两种格式,分别是2字节和4字节。
  范围:目前,UCS-4只是在UCS-2前面加了0x0000。
**10.Unicode字符集**
  Unicode字符集(简称为UCS),国际标准组织于1984年4月成立ISO/IEC JTC1/SC2/WG2工作组,针对各国文字、符号进行统一性编码。1991年美国跨国公司成立Unicode Consortium,并于1991年10月与WG2达成协议,采用同一编码字集。目前Unicode是采用16位编码体系,其字符集内容与 ISO10646的BMP(Basic Multilingual Plane)相同。Unicode于1992年6月通过DIS(Draf International Standard),目前版本V2.0于1996公布,内容包含符号6811个,汉字20902个,韩文拼音11172个,造字区6400个,保留 20249个,共计65534个。Unicode编码后的大小是一样的.例如一个英文字母 "a" 和 一个汉字 "好",编码后都是占用的空间大小是一样的,都是两个字节!
  Unicode可以用来表示所有语言的字符,而且是定长双字节(也有四字节的)编码,包括英文字母在内。所以可以说它是不兼容iso8859-1编码的, 也不兼容任何编码。不过,相对于iso8859-1编码来说,uniocode编码只是在前面增加了一个0字节,比如字母'a'为"00 61"。
  需要说明的是,定长编码便于计算机处理(注意GB2312/GBK不是定长编码),而unicode又可以用来表示所有字符,所以在很多软件内部是使用unicode编码来处理的,比如java。
  UNICODE字符集有多个编码方式,分别是UTF-8,UTF-16,UTF-32和UTF-7编码。
**UTF-8**
  UTF:UCS Transformation Format.考虑到unicode编码不兼容iso8859-1编码,而且容易占用更多的空间:因为对于英文字母,unicode也需要两个字节来表 示。所以unicode不便于传输和存储。因此而产生了utf编码,utf编码兼容iso8859-1编码,同时也可以用来表示所有语言的字符,不 过,utf编码是不定长编码,每一个字符的长度从1-6个字节不等。另外,utf编码自带简单的校验功能。一般来讲,英文字母都是用一个字节表示,而汉字 使用三个字节。
  注意,虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是 最节省的。不过另一方面,值得说明的是,虽然utf编码对汉字使用3个字节,但即使对于汉字网页,utf编码也会比unicode编码节省,因为网页中包 含了很多的英文字符。
  UTF8编码后的大小是不一定,例如一个英文字母"a" 和 一个汉字 "好",编码后占用的空间大小就不样了,前者是一个字节,后者是三个字节!编码的方法是从低位到高位。黄色为标志位其它着色为了显示其,编码后的位置。
**UTF-16**
  采用2 字节,Unicode中不同部分的字符都同样基于现有的标准。这是为了便于转换。从 0x0000到0x007F是ASCII字符,从0x0080到0x00FF是ISO-8859-1对ASCII的扩展。希腊字母表使用从0x0370到 0x03FF 的代码,斯拉夫语使用从0x0400到0x04FF的代码,美国使用从0x0530到0x058F的代码,希伯来语使用从0x0590到0x05FF的代 码。中国、日本和韩国的象形文字(总称为CJK)占用了从0x3000到0x9FFF的代码;
  由于0x00在c语言及操作系统文件名等中有特殊意义,故很多情况下需要UTF-8编码保存文本,去掉这个0x00。举例如下:
  UTF-16: 0x0080 = 0000 0000 1000 0000
  UTF-8: 0xC280 = 1100 0010 1000 0000
**UTF-32**
  采用4字节。
**UTF-7**
  A Mail-Safe Transformation Format of Unicode(RFC1642)。这是一种使用 7 位 ASCII 码对 Unicode 码进行转换的编码。它的设计目的仍然是为了在只能传递 7 为编码的邮件网关中传递信息。 UTF-7 对英语字母、数字和常见符号直接显示,而对其他符号用修正的Base64 编码。符号 + 和 - 号控制编码过程的开始和暂停。所以乱码中如果夹有英文单词,并且相伴有 + 号和 - 号,这就有可能是 UTF-7 编码。
  作用:为世界650种语言进行统一编码,兼容ISO-8859-1。
  位数:UNICODE字符集有多个编码方式,分别是UTF-8,UTF-16和UTF-32。
  很多人以为UTF-8等和Unicode都是字符集或都是编码方式,其实这是误区。
  到以上为止,大部分常用的字符集已经基本列举完毕,再看一些其他的编码方式:
**MIME 编码**
  MIME 是“多用途网际邮件扩充协议”的缩写,在 MIME 协议之前,邮件的编码曾经有过 UUENCODE 等编码方式 ,但是由于 MIME 协议算法简单,并且易于扩展,现在已经成为邮件编码方式的主流,不仅是用来传输 8 bit 的字符,也可以用来传送二进制的文件 ,如邮件附件中的图像、音频等信息,而且扩展了很多基于MIME 的应用。从编码方式来说,MIME 定义了两种编码方法Base64与QP(Quote-Printable)
**Base64**
  按照RFC2045的定义,Base64被定义为:Base64内容传送编码被设计用来把任意序列的8位字节描述为一种不易被人直接识别的形式。
  为什么要使用Base64?
  在设计这个编码的时候,我想设计人员最主要考虑了3个问题:
1.是否加密?
2.加密算法复杂程度和效率
3.如何处理传输?
  加密是肯定的,但是加密的目的不是让用户发送非常安全的Email。这种加密方式主要就是“防君子不防小人”。即达到一眼望去完全看不出内容即可。
  基 于这个目的加密算法的复杂程度和效率也就不能太大和太低。和上一个理由类似,MIME协议等用于发送Email的协议解决的是如何收发Email,而并不 是如何安全的收发Email。因此算法的复杂程度要小,效率要高,否则因为发送Email而大量占用资源,路就有点走歪了。
  但是,如果是基于以上两点,那么我们使用最简单的恺撒法即可,为什么Base64看起来要比恺撒法复杂呢?这是因为在Email的传送过程中,由于历史原 因,Email只被允许传送ASCII字符,即一个8位字节的低7位。因此,如果您发送了一封带有非ASCII字符(即字节的最高位是1)的Email通 过有“历史问题”的网关时就可能会出现问题。网关可能会把最高位置为0!很明显,问题就这样产生了!因此,为了能够正常的传送Email,这个问题就必须 考虑!所以,单单靠改变字母的位置的恺撒之类的方案也就不行了。关于这一点可以参考RFC2046。
基于以上的一些主要原因产生了Base64编码。
  Base64编码要求把3个8位字节(3\*8=24)转化为4个6位的字节(4\*6=24),之后在6位的前面补两个0,形成8位一个字节的形式。
**QP(Quote-Printable)**
  通常缩写为“Q”方法,其原理是把一个 8 bit 的字符用两个16进制数值表示,然后在前面加“=”。所以我们看到经过QP编码后的文件通常是这个样子:=B3=C2=BF=A1=C7=E5=A3=AC=C4=FA=BA=C3=A3=A1。
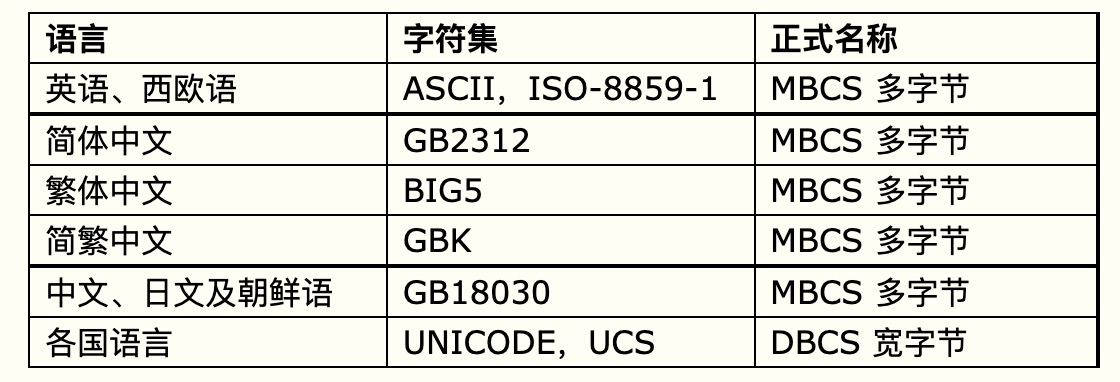
  最后,我们希望你看了这篇文章之后不要混淆字符集和字符编码的概念,还有对以上谈到的各种编码方式的原因有大致的了解,象utf-8这类是为了解析 unicode这种字符集而制定,而base64这类是为了解决实际的网络应用而制定。为了让你便于记忆,对先前介绍的字符集进行统计和分类:
- Java基础企业实践篇
- 一、Java开发环境搭建
- 1.Java的前世今生
- 2.JVM、JRE和JDK的概念及关系
- 3.Java的跨平台特性
- 4.Java运行机制
- 5.环境搭建
- 二、程序设计基础
- 1.掌握代码基本结构
- 2.熟练写注释
- 3.掌握标识符的使用
- 4.掌握关键字的使用
- 5.掌握常量的使用
- 6.认识变量
- 7.掌握数据类型的使用
- 8.掌握类型转换
- 9.掌握作用域
- 10.掌握运算符的使用
- 11.掌握顺序结构的使用
- 13.掌握循环结构的使用
- 14.掌握方法的使用
- 15.掌握数组的使用
- 16.掌握修饰符的使用
- 三、面向对象语言基础
- 1.对象的概念
- 2.类的概念
- 3.类和对象的关系
- 4.面向过程和面向对象的区别
- 5.实训项目:五子棋游戏设计与实现
- 6.案例练习
- 案例一:地址类
- 案例二:员工类
- 案例三:动物狗类
- 案例四:银行账户类
- 案例五:图书类
- 四、面向对象概念的理解,类和对象
- 1.类的构成
- 2.属性
- 3.方法和构造方法
- 4.重载和重写
- 5.变量的作用域
- 6.成员变量和局部变量
- 7.静态块的作用和加载机制
- 8.类生成对象的过程
- 9.对象参数传递过程
- 五、封装,继承,多态
- 1.理解封装、继承、多态的概念和目的
- 2.理解封装、继承、多态的实现方法和步骤
- 3.掌握Java访问修饰符
- 4.理解什么是内部类
- 5.理解this、static、final关键字
- 6.实训项目:租车系统设计与实现
- 六、抽象类和接口
- 1.理解抽象类的概念,为什么要有抽象类
- 2.掌握抽象类的声明格式
- 3.理解什么是接口,为什么要有接口
- 4.掌握接口的定义与实现
- 5.理解接口和抽象类的区别
- 6.实训案例
- 案例一:电脑模型(OO实现)
- 案例二:银行转账(OO实现)
- 七、Object类和常用API
- 1.理解什么是API
- 2.掌握Java API文档的使用
- 3.理解Java类库的概念
- 4.掌握Object类并掌握该类中的方法
- 5.掌握String类的应用
- 6.掌握StringBuffer、StringBuilder类的应用
- 7.掌握基本数据类型及其包装类
- 8.掌握Java日期类
- 八、泛型、集合
- 1.理解泛型的概念和实现语法
- 2.理解Java集合框架三大接口:List、Set、Map
- 3.掌握List接口的实现类ArrayList、LinkedList的使用
- 4.掌握HashSet的使用
- 5.掌握HashMap的使用
- 6.掌握Collections类中提供的静态方法
- 九、异常和IO技术
- 1.理解异常的概念
- 2.掌握异常的分类和Java常见的异常
- 3.理解掌握Java的异常处理机制
- 4.掌握自定义异常
- 5.理解文件系统和File类
- 6.理解I/O概念和分类
- 7.掌握常见的I/O流对象
- 8.掌握文件流与缓冲流
- 十、泛型的延伸
- 1.理解并掌握泛型的基本原理与具体运作过程
- 2.掌握泛型类的定义
- 3.掌握泛型方法的定义
- 十一、流的延伸
- 1.理解数据流的作用
- 2.掌握对象流的作用
- 3.理解对象序列化的概念
- 5.理解线程死锁
- 4.理解对象反序列化的概念
- 十二、反射技术
- 1.理解反射的概念
- 2.理解反射的工作原理
- 3.理解Reflection API中相关类的作用
- 十三、多线程技术
- 1.理解多线程的概念
- 2.理解线程的状态与生命周期
- 3.理解多线程通信
- 4.理解线程同步
- 十四、网络编程技术
- 1.理解网络编程常用协议TCP/UDP/HTTP/FTP等基础知识
- 2.掌握TCP网络编程连接建立的3次握手和4次挥手的具体过程
- 3.掌握UDP网络通信工作原理
- 4.掌握Socket通信模型的工作原理
- 十五、图形化界面
- 5.理解线程死锁
- 十六、JDBC技术
- 1.熟练掌握JDBCAPI中常用接口的基本概念
- 2.理解JDBC连接数据库的思路和实现方法
- 3.熟练掌握JDBC连接数据库的基本步骤
- 4.理解并掌握数据库连接公共类的设计思路和方法
- 5.熟练掌握JDBC使用公共类连接数据库的基本步骤
- 6.熟练掌握JDBC操作数据库的基本步骤
- 7.熟练掌握JDBC操作数据库的SQL语句
- 8.熟练掌握JDBC操作单表的方法及SQL语句
- 9.熟练掌握JDBC操作多表的方法及SQL语句
- 10.理解事务的基本概念
- 11.熟练掌握JDBC在综合项目的使用方法(包含:基本数据、业务处理等)
- 十七、课外补充
- 附录1.各种字符集和编码详解
- 项目实训
- 项目2:汽车销售系统