# 使用Orange3对图片进行数据挖掘
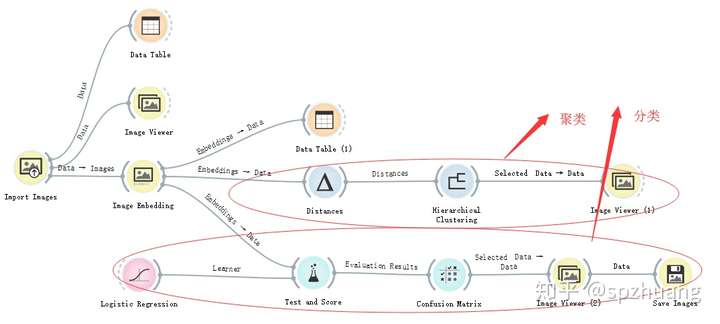
摘要:本文是Orange3进行数据挖掘的第二部分教程,本文的内容主要是使用Orange3对图片进行一些通用的处理,这些操作包括对图片数据的载入,分类,聚类。本教程应用的布局如下图:
1. 数据准备
首先,我们需要一组图片数据才可以对图片进行处理。我从必应搜索中,输入关键词“花”,选择了5个花的类别“杜鹃花”,“兰花”,“菊花”,“玫瑰”,“水仙”,每个类别5张图片,一共有25张图片,保存在本机电脑的文件“花”中(自个儿建一个)。
2\. 载入图片数据并预览
为了能够载入图片数据,需要我们先安装图片处理的包,点击“菜单”-> "Options" -> "Image Analytics"安装图片处理包,安装后需要重启Orange3, 然后我们能够在左侧的工具中找到图片处理的窗口了。
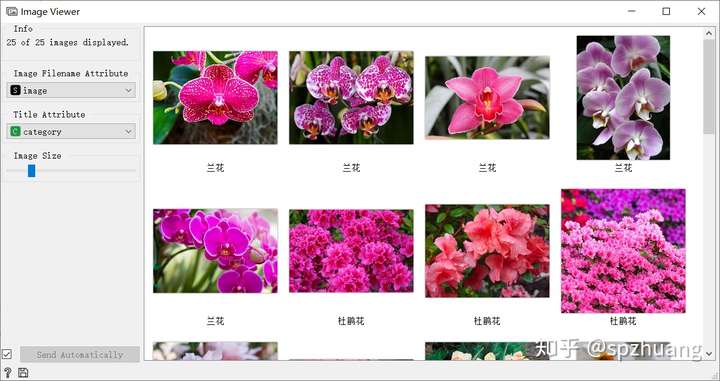
然后,我们将Import Images和Image Viewer拖到右侧的画板中,双击“Import Images",选择图片文件”花“,然后连接"Import Images"和"Image Viewer",进入“Image Viewer”就可以看到这些图片了。
3\. 使用图片embedding
为了对这些图片进行分类和聚类,我们还需要对图片进行embedding操作,这个操作的含义类似于自然语言处理中对原始文本进行embedding化,将它们转化为各个结构化的tensor。
将“Image Embedding”应用从左侧的工具窗口拖到右侧的画板中,连接“Import Images"和"Image Embedding",进入“Image Embedding”,这里可以选择不同的图片嵌入方式,不知道什么原因,其它的几个选择(“Vgg16,Inception v3”)都不会有实际的作用,尽管它们都是比较著名的图片处理网络,这里只有选择“SqueezeNet(local)”才可以真正的发挥效用。
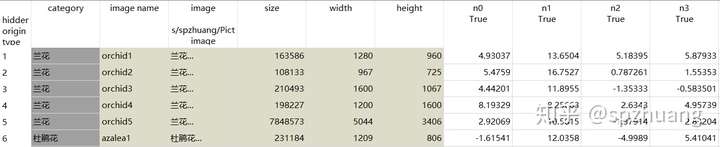
这个时候,将“Data Table”应用拖入到右侧的画板中,连接"Image Embedding"和"Data Table",就可以看到这些图片被嵌入后的数据了(没有做embedding之前,没有n0,n1这些字段)。
4\. 对图片进行聚类
将左侧“Unsupervised”窗口中的“Distances”,"Hierarc Clustering"以及"Image Analytics"的"Image Viwer"拖入到右侧的画板中,连接“Image Embedding”和“Distances”,连接“Distances”和“Hierarc Clustering”,连接“Hierarc Clustering”和“Image Viwer”。
配置了聚类组件之后,我们稍微详细的说一下具体设置。
在“Distances”中可以选择不同的距离,比如余弦距离(cosine),欧式距离(Euclidean),曼哈顿距离(Manhattan)等。对图片的处理,针对不同的数据,改变不同的距离度量对处理结果会产生影响。
同时打开“Hierarc Clustering”和“Image Viewer”,当我们选择了“Hierarc Clustering”中的一些聚类的结果时,在“Image Viewer”中会显示出被选择聚类结果对应的“花”。如下图:
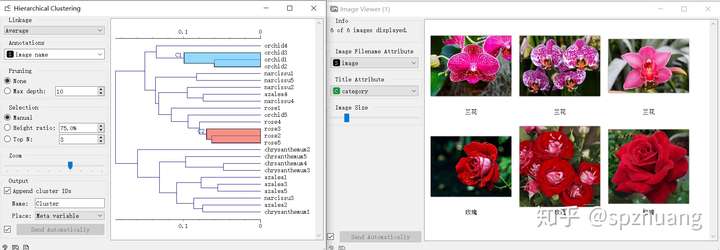
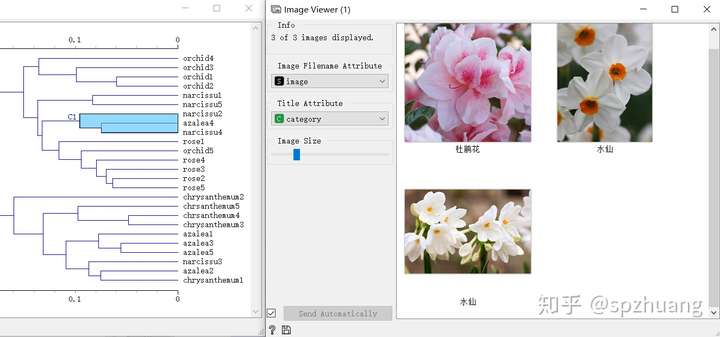
通过这种方式,能够非常高效的分析聚类结果。从图片中可以看出,兰花和玫瑰确实区别比较大,因此它们被划分到不同的簇中;另一方面,这种聚类将某个杜鹃花和二张水仙花的图片分到了一个簇中,从右侧的Image Viewer中,可看出它们确实非常相似。这同协同反应,我觉得时Oragne3非常吸引人的地方。
5 对图片进行分类
将左侧窗口中“Evaluate”下的几个应用“Test and Score”,"Confusion Matrix", 将“Image Analysis”中的“Image Viewer”,“Save Images”,将“Model”中的“Logistic Regression”共7个应用拖入到右侧画板中。连接“Image Embedding"-"Test and Score”,"Logistic Regression"-"Test and Score","Test and Score"-"Confusion Matrix","Confusion Matrix"-"Image Viewer","Image Viewer"-"Save Images",这样分类的应用部署就完成了。
在“Logistic Regression”中,可以调节它的正则化系数,为L1范数还是L2范数,以及惩罚稀疏的大小。在“Test and score”中,可以看模型Logistic回归对图片的分类结果,包括AUC,F1,Precision,Recall等常用指标,并且还可以调节交叉验证的参数,只要调节"Cross Validation"下"Number of Folds"下的参数即可。
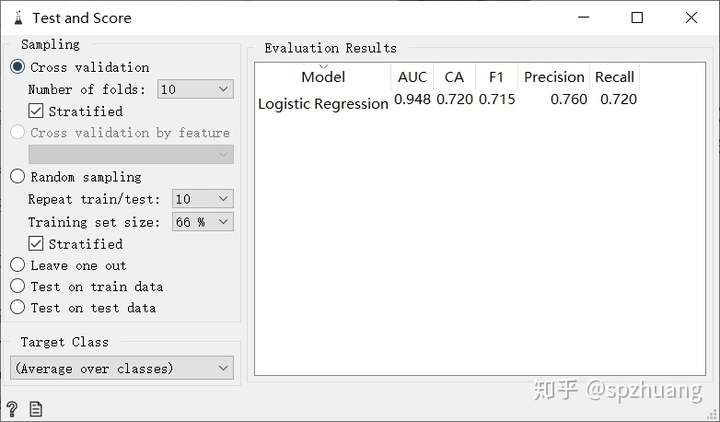
为了查看具体分错的样本,我们可以同时打开“Confusion Matrix”和“Image Viewer”。混肴矩阵的含义这里不再讨论,感兴趣的读者可自行百度。在混肴矩阵中,对角线上的数字代表正确分类的,而非对角线上的数字,代表的时错误的分类。
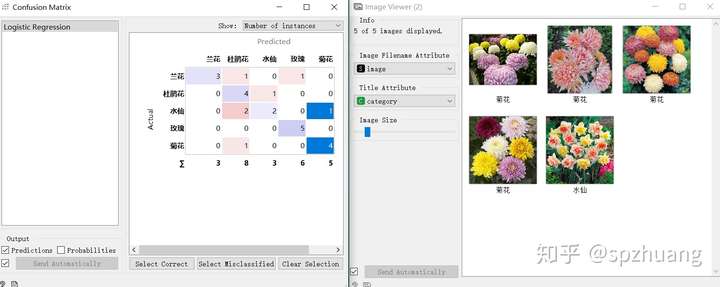
深蓝色的时我选择的数据,它们会在右侧的Image Viewer中出现。从混肴矩阵中有,第3行第5列的1代表的时Logistics将水仙花预测成了菊花,从右侧的Image Viewer,直观上看,图片上的水仙花,确实和菊花很相似,因此这个样本并不容易划分。
最后的"save image"可以将图片Image Viwer中的图片保存到本机中。
6\. 总结
本本讲述了如何使用Orange对图片进行读取,查看,embedding,聚类和分类,以及分类或者聚类后查看出错的数据。揭示了Orange可以高效的分析异常图片的特性。这些是吸引我们使用Orange3处理数据一个点。
