# 【翻译】示范:我的渐进阅读工作流程
> 译者:[叶峻峣](https://www.zhihu.com/people/L.M.Sherlock)
> 原文:[MasterHowToLearn - Demonstration: My Workflow of Incremental Reading](https://www.masterhowtolearn.com/2018-12-09-demonstration-my-workflow-of-incremental-reading/)
在我之前的《[SuperMemo 中渐进阅读的意义](./2450558)》中,我尽力解释了渐进阅读。在这篇文章中,我将向你展示我的 IR 工作流程。
注意:
1. 这是对渐进阅读的基本介绍。这个演示有些简化。将此视为渐进阅读 101。
2. 有很多方法,没有一个完全正确的方法。我希望你能在阅读后创建和定制自己的工作流程。
## 目录
[TOC=2,4]
## 快速术语回顾
SM = [super-memo.com](http://super-memo.com/) 的 SuperMemo;而不是 [supermemo.com](supermemo.com) 的课程、移动应用、应用。它们是不同的。
SuperMemo 中的项目 = [Anki](https://apps.ankiweb.net/)中的卡片;IR =[渐进阅读](https://www.yuque.com/supermemo/wiki/incremental_reading)
## 概要
1. 导入原材料
2. 处理
1. 第 1 次处理(摘录重要片段)
2. 第 2 次处理(可选:根据上下文修改,改变措辞等)
3. 第 3 次处理(将重要的部分转化为问答/填空)。
3. 渐进阅读的 5 个基本技巧
我就用[这篇文章](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6131264/)来做示范,也就是我在《[知识迁移介绍](https://www.masterhowtolearn.com/2018-10-30-introduction-of-transfer-of-knowledge)》中用的那篇文章。
## 1. 导入原材料
TL;DR:只要将整篇文章选中,Ctrl+C 复制,然后打开 SuperMemo,Ctrl+N 粘贴即可。
1. 选中整篇文章或你想要的部分。然后用 Ctrl+C 复制
:-: 
2. 打开 SuperMemo。按 Ctrl+N 导入文章
:-: 
3. 导入的文章有很多 HTML 标签。用 F6 过滤一下。在字体、间距和样式之间进行实验。不过,我并没有真正使用这个过滤功能。
这时你要设置参考标签:标题,日期,作者,来源,链接等。要做到这一点,选中文字,Alt+Q 设置相应的类别。最起码的就是标题,我大多数时候都是这样设置的。
:-: 
我在所有文本中都使用了统一的字体风格和大小。我的 SuperMemo 集合中的所有内容都是常规的 Calibri 和 17 号。所以无论原材料的字体样式和大小,导入时都是常规的 Calibri 和 17 号。这样就避免了字体样式和大小的不规范,也避免了 「摘录和填空字号变得比原文大」的问题。
做同样的事情:
Tools → Options → Fonts → Stylesheet → edit
这是[我的样式表](https://github.com/MasterHowToLearn/SuperMemo/blob/master/stylesheet.css)
> 译者注:可以试试我的《[渐进阅读懒人样式](./2450596)》
注意:这也会改变其他一些样式。谨慎使用。在进行任何修改之前,请先保存一份原件。
如果因为某些原因,你无法获得正确的格式,我建议先用记事本冲洗一下。在 Ctrl+N 到 SuperMemo 之前,先粘贴到记事本上,把所有的 HTML 格式剥离掉就可以了。
> 译者注:更多材料的导入方法,可以参考《[渐进阅读材料导入与预处理](./2450595)》
### 一定要用 IE 浏览器吗?
官方指南建议并使用 Internet Explorer。但这不是必须的。我使用的是 Firefox。Chrome 也可以。SuperMemo 现在支持 Edge。据我所知,最大的区别是,用 Internet Explorer/Edge,你可以从所有打开的标签页中导入所有的文章,而用 Firefox/Chrome,你必须一个一个导入。我一个一个导入,更喜欢手动选择我想要的部分。如果你的所有来源都是来自Wiki,那么一次导入是很好的;如果不是这样,就会变得很混乱。
### 带有图片的文章
你导入一篇文章的图片,只有在有互联网连接的情况下,它们才会出现。当你不这样做的时候,它们会变成 X 这样。
:-: 
这个问题我花了很长时间,也花了很多运气才弄明白:[如何在离线时,在渐进阅读时显示文章中的嵌入图片?](http://supermemopedia.com/wiki/How_do_I_display_embedded_images_in_articles_during_Incremental_Reading_when_offline%3F)
tl;dr:在线时,保存文章。然后,打开保存的文章,复制并粘贴到 SuperMemo 中。即使离线时也会显示图片。不需要下载图片。有一点要注意:你不能移动你保存的 html 及其文件夹的位置。一旦移动了,SuperMemo 中的图片将不会再显示。
## 2. 处理
### 初步处理
导入后,我按 Alt+P 定义其优先级。
> \_使用 Alt+P 来设置每个元素的优先级,从 0% 到 100%。注意,0% 对应的是高优先级。
注意:这是另一个不直观的操作。当你在调整元素优先级时,请记住 0% 意味着最高的优先级,而 100% 意味着最低的优先级。
:-: 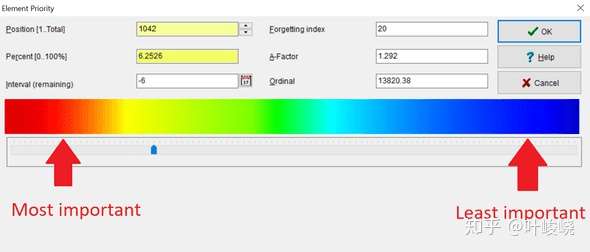
如果你不想记住这种反直觉的规则,你可以直接滑动条。重要的就往左滑,不重要的就往右滑。我大多数时候都是直接滑动条。
如果是一篇比较难的文章,我会 Ctrl+J 安排在 2 周以后。为什么是 2 周呢?个人喜好。对于某一篇文章,我可能认为 2 周的时间足够我在处理它之前获得足够的预备知识。如果是一篇重要的文章,我就会把滑块向左滑动;如果是一篇有点意思但不重要的网络文章,我就会把滑块滑到最右边。
#### 阅读文章
你可以立即开始阅读文章,也可以等到 SuperMemo 给你看(默认间隔是一天,也就是说 SuperMemo 明天就会给你看那篇文章)。你自己决定。为了演示的目的,我现在就阅读它。
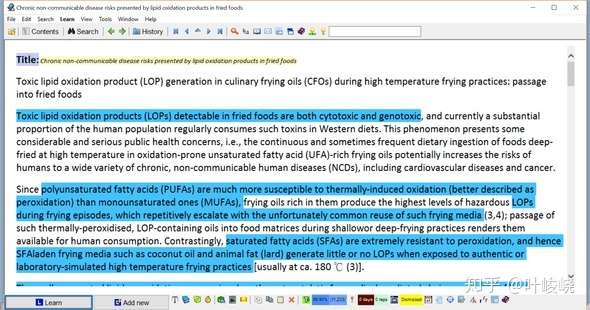
在阅读的过程中,我会摘录(Alt +X)重要的句子或段落。摘录的句子或段落仍然是摘录卡片。记住你的最终目标是将摘录卡片转化为项目。
这就是结果:
:-: 
:-: 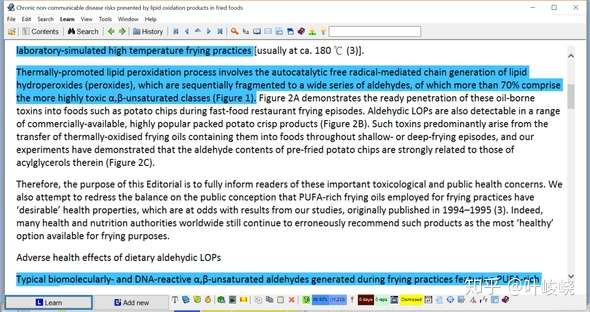
这就像你在传统的阅读中所做的那样:当你看到重要的东西时,你会用荧光笔来突出它。这在 SuperMemo 中没有什么区别。那些蓝色的摘录是我认为重要的部分。
:-: 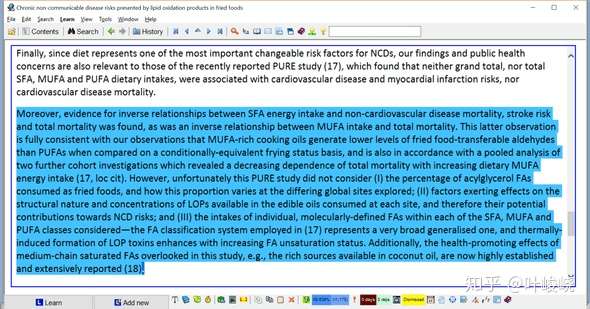
摘录整段的原因:
1. 对目前的我来说,太难理解了
2. 我想跳过这一段继续读,但我觉得其中有重要的内容
匆匆一瞥之后,我会摘录整个段落。SuperMemo 会在以后(几天或几周)将它作为一个摘录卡片显示给我。然后我可以阅读它,并决定它是否真的重要到可以变成项目。如果不重要,我可以直接按删除键删除该摘录卡片的段落(不使用活动窗口)。
#### 你的回合
记住,哪些句子要摘录,哪些句子要省略,完全取决于你。我们有不同的先验知识:我认为重要的东西可能与你无关;你可能认为某些东西很重要,但我没有摘录;你可能会少做许多填空。这完全没问题。这一切都取决于你。
在这个阅读环节结束后(我还没读/读完整篇文章),在进入下一个元素之前,记得用 Ctrl+F7 设置阅读点。下次看到同一篇文章时,SuperMemo 会显示你最后的阅读点,这样你就可以继续阅读了。
### 第 2 次处理
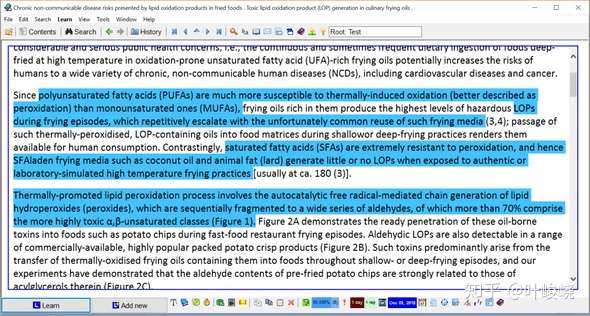
你可以在其摘录后立即开始处理你的摘录卡片,或者等到 SuperMemo 向你展示它们。同样,你的决定。就我个人而言,如果我知道如何将一个特定的摘录卡片(句子)变成一个项目,我会立即这样做;对于整个段落的摘录卡片,我通常会等到 SuperMemo 向我展示它们。
再参考一下这个例子:
:-: 
下面是第一句话的演示:
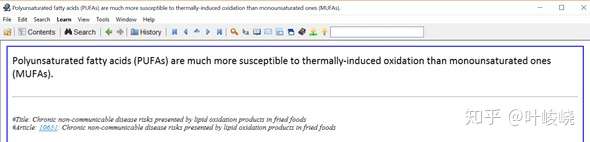
这是原汁原味的,没有任何修改:
:-: 
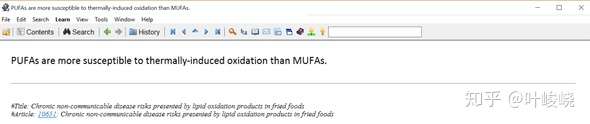
改写成:
:-: 
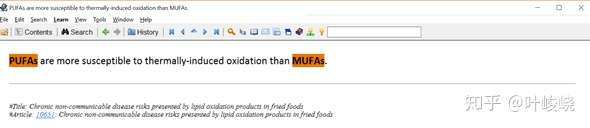
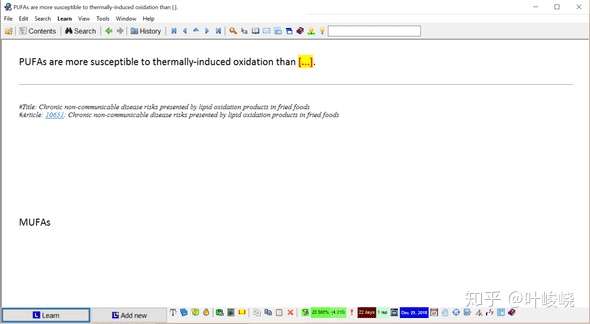
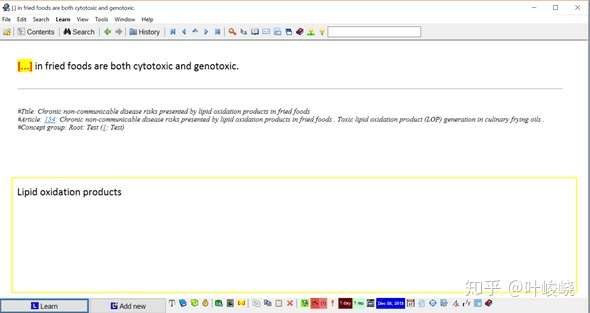
然后我做了两个填空(Alt+Z)。
:-: 
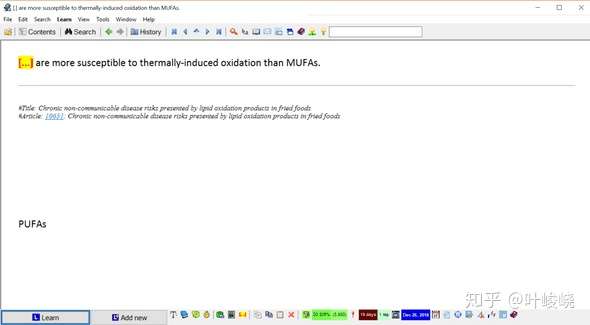
产生两个填空:
:-: 
:-: 
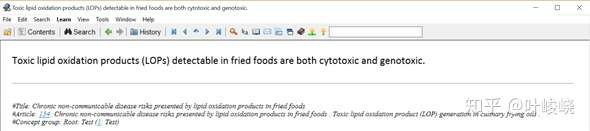
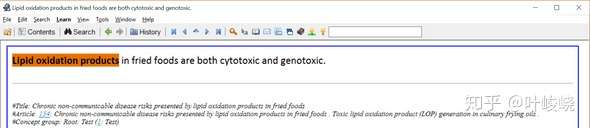
另一个例子:
:-: 
:-: 
:-: 
对于每一个经过处理的摘录卡片,无论是通过制作填空还是问答,你都必须通过 Ctrl+D 来忽略该摘录卡片。忽略意味着SuperMemo 将不会再向你展示该摘录卡片。它的目的已经达到了,你已经把它变成了可再调用的信息。
你的目标是把所有的摘录卡片变成填空或问答。这是我的知识树的最终结果:
:-: 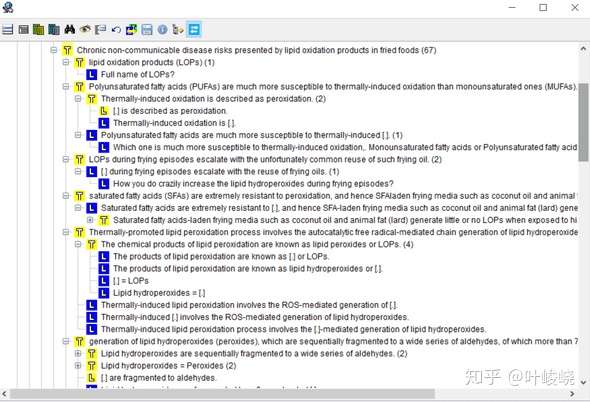
你看所有的 T 都是黄色的,意思是所有的摘录卡片都被忽略了。蓝色的 L 是指项目,我在记忆这些项目。
一开始可能看起来令人生畏,这样的过程需要很多时间。但你可以循序渐进,分几个星期甚至几个月来做。IR 最突出的特点是间隔算法。SuperMemo 为你安排好一切。你不必一气呵成,从头到尾地编辑。我主要是根据间隔算法把摘录卡片变成填空和问答。
### 第 3 次加工
过了一段时间(大概几天),复习的时候,SuperMemo 会给我看我从摘录卡片中制作的填空/问答。我将对这些项目进行复习和评分。你可以重新制定措辞,删除它,把它做成更多的填空,随你喜欢。
然后再过一段时间,SuperMemo 会给我显示原文最后的阅读点。我该怎么办呢?继续阅读文章,摘录我认为重要的部分。第 3 次处理基本上是重复和交替第 1 次和第 2 次处理。
当你真正读完整篇文章后,按 Ctrl+D 忽略文章。
恭喜你!你已经完成了渐进阅读。
## 3. 渐进阅读的5个基本技巧
### 1. 渐进阅读的渐进
记住每个步骤和过程之间是有间隔的:
1. 导入原材料
2. 处理:摘录重要片段;根据上下文修改,改变措辞等;将重要片段转化为问答/填空
导入一篇文章后,通常是一天后才可以开始阅读。
在第一次阅读之后,可能是一周之后才能在复习环节看到并阅读同一篇文章。
摘录完重要的句子后,可能要一周后才能在复习环节上看到你的摘录卡片。
在知道如何将摘录卡片变成填空或问答之前,你可能需要几次被动复习(几周)。在制作填空或问答之前,你要允许一些时间来沉淀。有时,我在决定一个摘录卡片值得变成填空或知道如何挖空之前,会被动地复习多次。有时候,我曾摘录过一些我认为很重要的句子;然后第二天,当 SuperMemo 呈现在我面前时,我认为它不重要,会直接删除。
所有这些间隔的好处是选项:你可以决定在一个小时内压缩所有这些步骤,或者让 SuperMemo 为你安排这些步骤。所以叫渐进阅读。
当你刚开始,原始资料少的时候,似乎并没有什么好处,甚至不喜欢等上一天才能再读同一篇文章。但是,随着时间的推移,拥有越来越多的文章、研究论文、参考书等收藏,你就会明白和体会到让 SuperMemo 自动为你安排复习任务的意义和必要性。排期的事情交给 SuperMemo 来做,你可以专注于重要的部分:阅读和记忆。
### 2. 摘录的终极目标:填空或问答
主动回忆——所有的信息片段最终都将转化为主动回忆的材料,如问答对、隐语删除、图片识别测试等。
复习摘录卡片属于被动复习。这与填空或问答有明显的区别,因为你不会从中检索答案。你可以被动地复习几遍摘录卡片,但它的最终归宿是填空或问答。
对于一篇文章:
文章→(可选:段落)→摘录(句子)→缩短和修改的句子→填空/问答。
摘录卡片可能很长(段落)或很短(单句)。对于较长的摘录卡片,你要阅读并摘录更多的摘录卡片(句子);对于非常短的摘录卡片,你可以立即生成填空或问答。无论怎样,它们的最终目的都是要转化为填空或问答。
这就是知识提炼。想象一下,就像把一块石头雕琢成雕塑一样:你必须削去多余的部分。
### 3. 夯实基础
《[有效学习:形成知识的二十条规则](./2454060)》的规则 3 适用于渐进阅读:
> 学习整体的大局越简单越好。简单的模型更容易理解和吸收。你以后总可以在它们的基础上继续发展。
> 不要忽视基础知识。记忆看似明显的东西并不是浪费时间。
从上面的例子中可以看出,我总是从基本概念、术语、中心思想开始摘录,然后再往上走。这与 Michael Nielsen 在《[增强长期记忆](https://zhuanlan.zhihu.com/p/65131722)》中提到的他使用 Anki 的做法很类似:
> 我关于 AlphaGo 的问题从简单的“围棋棋盘的大小?”发展到关于系统设计的高阶概念性问题——AlphaGo 是如何避免过度推广训练数据的,卷积神经网络的局限性等等。
这与我在《[SuperMemo 中渐进阅读的意义:第一部分](./2450558)》中提到的想法类似
:-: 
### 4. 添加上下文
由于你是从文章的一段话中摘录句子,上下文必然会丢失。你必须自己添加,才能提供足够的检索线索。
比如说
> 「骨鱼最早出现在志留纪」
> 「骨鱼最早出现在\[...\](纪)」
如果没有检索线索(纪),答案也可以是一个地方。这种歧义是非常不可取的。当复习时,你的脑海中开始出现其他类型的答案时,你就知道你应该增加更多的上下文提示。
你不一定要在第一次就把它完美地独立出来。我是循序渐进的。顾名思义,关键是循序渐进。
> 渐进主义——所有的改变都会随着时间的推移而逐渐发生,与你选择的材料的优先级有关,并与逐渐增加的记忆痕迹的强度相一致。
### 5. 简化你的摘录卡片/填空/问答
以下修改后的文字来自《[渐进阅读导论](https://www.yuque.com/supermemo/wiki/incremental_reading)》:
> 在将摘录卡片转换成问答的同时,你应该确保你的问题简单明了。
例如,如果你有以下摘录卡片:
> 互联网是在1969年由高级研究计划局(ARPA)签订的一份合同下建立的,该公司连接了美国西南部大学(UCLA、斯坦福研究所、UCSB和犹他大学)的四台主要计算机
你可能会发现,当复习间隔变得足够长时,你可能实际上无法回忆起ARPA机构的名称,甚至忘记互联网开始的年份。然后,您可以选择一个重要的关键字,例如1969,并使用挖空生成以下问答:
> **问题**:互联网是在**\[…\]**年根据高级研究计划署(ARPA)的合同开始的,该机构将美国西南部大学(UCLA、斯坦福研究所、UCSB和犹他大学)的四台主要计算机连接起来。
> **答案**:1969年
在学习过程中,您需要通过手动编辑将上述问答卡片修改成更简洁易懂的形式:
> **问题**:互联网是根据ARPA代理的一份合同于**\[…\]****年**启动的
> **答案**:1969年
或者更好:
> **问题**:互联网始于**\[…\]****年**
> **答案**:1969年
主要原因是简洁。去掉不相关的信息,你就不会把时间浪费在被动复习那些不可能被记住的信息上,因为只有主动回忆的材料才会被记住。
## 结束语
就当这是《渐进阅读101》吧。这是我希望在我刚开始探索渐进阅读时读到和知道的。希望这能澄清「到底什么是渐进阅读?」,这些技巧对你有帮助。
