
[TOC]
> ### `redis`五种数据结构
* `string`
```sh
set asd "123"
get asd
> 123
```
* `list
`
```sh
lpush asd_list aaa
lpush asd_list bbb
lrange asd_list 0 2
lpop/rpop asd_list //移除并返回列表中的首/尾元素
```
* `hash
`
```sh
hmset hash_asd t1 "111" t2 "222"
hgetall hash_asd
>1) t1
>2) 111
>3) t2
>4) 222
hget hash_asd t1
111
```
* `set
`
* `zset`(Sorted Set)
* Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
* zset都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
<br/>
> ### `Redis` [持久化](https://juejin.im/post/5b70dfcf518825610f1f5c16)
* 快照(snapshotting)持久化(`RDB`),快照持久化是Redis默认采用的持久化方式
* `save`:会阻塞当前Redis服务器,直到持久化完成,线上应该禁止使用。
* `bgsave`:该触发方式会fork一个子进程,由子进程负责持久化过程,因此阻塞只会发生在fork子进程的时候。
* 自动触发:根据`save m n` 配置规则自动触发;执行`debug reload`时;执行`shutdown`时,如果没有开启aof,也会触发;从节点全量复制时,主节点发送rdb文件给从节点完成复制操作,主节点会触发 bgsave;
* `AOF`(append-only file)持久化,与快照持久化相比,`AOF`持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启`AOF`。开启`AOF`持久化后每执行一条会更改Redis中的数据的命令,`Redis`就会将该命令写入硬盘中的`AOF`文件
<br/>
> ### 缓存雪崩
* 造成缓存雪崩一般有两个原因:
* 对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。
* 解决方法,在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
* `Redis`挂了
* 事发前:实现`Redis`的高可用(主从架构+Sentinel 或者Redis Cluster)
* 事发中:万一`Redis`真的挂了,我们可以设置本地缓存(`ehcache`) + 限流(`hystrix`),尽量避免我们的数据库被干掉
* 事发后:redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
<br/>
> ### 缓存穿透
* 一般是黑客故意去请求缓存中不存在的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
* 有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的`bitmap`中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
* 一种简单的方式,如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
<br/>
> ### 缓存与数据库双写一致性
* 先删除缓存,再更新数据库,在高并发下表现不如意,在原子性被破坏时表现优异,如下:
```
线程A删除了缓存
线程B查询,发现缓存已不存在
线程B去数据库查询得到旧值
线程B将旧值写入缓存
线程A将新值写入数据库
```
* 并发下解决数据库与缓存不一致的思路,将删除缓存、修改数据库、读取缓存等的操作积压到**队列**里边,实现**串行化**。
* 先更新数据库,再删除缓存,在高并发下表现优异,在原子性被破坏时表现不如意
```
缓存刚好失效
线程A查询数据库,得一个旧值
线程B将新值写入数据库
线程B删除缓存
线程A将查到的旧值写入缓存
```
<br/>
> ### [`Memcached`与`Redis`比较](https://www.zhihu.com/question/19645807)
* 数据类型支持不同
* `Memcached`仅支持简单的key-value结构的数据
* `redis`支持String、Hash、List、Set、ZSet
* 内存管理机制不同
* 在`Redis`中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别。
* `Memcached`默认使用Slab Allocation机制管理内存,其主要思想是按照预先规定的大小,将分配的内存分割成特定长度的块以存储相应长度的key-value数据记录,以完全解决内存碎片问题。
* 数据持久化支持
* Redis虽然是基于内存的存储系统,但是它本身是支持内存数据的持久化的,而且提供两种主要的持久化策略:RDB快照和AOF日志。而memcached是不支持数据持久化操作的。
* 集群管理不同
* Memcached本身并不支持分布式,因此只能在客户端通过像一致性哈希这样的分布式算法来实现Memcached的分布式存储。
* Redis支持分布式存储功能,Redis Cluster
<br/>
> ### `Redis`底层存储原理
* **`SDS`(simple dynamic string),动态字符串**。每个`sds`都会比它真实占用的字符长度都长,通过一个空闲标识符表示`sds`当前空闲字符有多少,如此设计,在一定长度范围的内的字符串都可以使用此`sds`,而且不会频繁的进行内存分配,直到此`sds`不能容纳分配的字符串,如果遇到这种情况情况,才需要进行扩容;这是redis的最基础的,所有的redis `k-v` 中的字符串都是依托于`sds`。
* **`dict`字典**,类似于java中的`hashmap`,两个哈希数组,一个是正常使用的,另一个是扩容时需要的,`redis`的扩容是渐进式,不影响当前`dict`的访问,即扩容的数组逐渐迁移,迁移完成之后再切换。
* **跳跃表**,跳跃表是由N层链表组成,最底层是最完整的的数据,每次数据插入,率先进入到这个链表(**有序的**),然后针对这个节点`1/2`的概率被添加到上层的列表。
* 在随机搜索方面略低于`B+`树,但是对于数据插入优于`B+`树
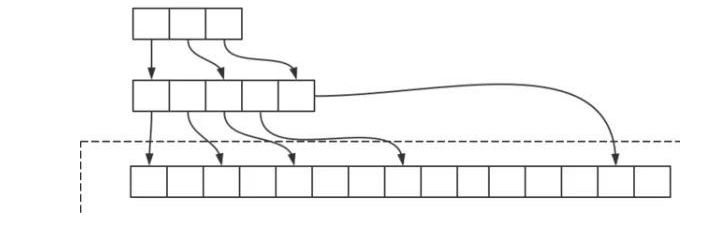
* **单线程,多路I/O复用模型**,也是java 的`NIO`体系使用的`IO`模型,也是linux诸多`IO`模型中的一种,当一个请求来访问redis后,redis去组织数据要返回给请求,这个时间段,redis的请求入口不是阻塞的,其他请求可以继续向redis发送请求,等到redis io流完成后,再向调用者返回数据,这样一来,单线程也不怕会影响速度了。**相当于多个`IO`请求复用一个真正执行`IO`读写操作的线程**。
***
参考:
[面试前必须要知道的Redis面试题](https://zhuanlan.zhihu.com/p/54840101)
[一窥redis之谜](https://zhuanlan.zhihu.com/p/34762100)
- asD
- Java
- Java基础
- Java编译器
- 反射
- collection
- IO
- JDK
- HashMap
- ConcurrentHashMap
- LinkedHashMap
- TreeMap
- 阻塞队列
- java语法
- String.format()
- JVM
- JVM内存、对象、类
- JVM GC
- JVM监控
- 多线程
- 基础概念
- volatile
- synchronized
- wait_notify
- join
- lock
- ThreadLocal
- AQS
- 线程池
- Spring
- IOC
- 特性介绍
- getBean()
- creatBean()
- createBeanInstance()
- populateBean()
- AOP
- 基本概念
- Spring处理请求的过程
- 注解
- 微服务
- 服务注册与发现
- etcd
- zk
- 大数据
- Java_spark
- 基础知识
- Thrift
- hdfs
- 计算机网络
- OSI七层模型
- HTTP
- SSL
- 数据库
- Redis
- mysql
- mybatis
- sql
- 容器
- docker
- k8s
- nginx
- tomcat
- 数据结构/算法
- 排序算法
- 快排
- 插入排序
- 归并排序
- 堆排序
- 计算时间复杂度
- leetcode
- LRU缓存
- B/B+ 树
- 跳跃表
- 设计模式
- 单例模式
- 装饰者模式
- 工厂模式
- 运维
- git
- 前端
- thymeleaf
- 其他
- 代码规范
- work_project
- Interview