
# 计算机视觉----语义分割
2017年10月11日
人工智能被认为是第四次工业革命,google,facebook等全球顶尖、最有影响力的技术公司都将目光转向AI,虽然免不了存在泡沫,被部分媒体夸大宣传,神经网络在图像识别,语音识别,自然语言处理,无人车等方面的贡献是毋庸置疑的,随着算法的不断完善,部分垂直领域的研究已经落地应用。
在计算机视觉领域,目前神经网络的应用主要有图像识别,目标定位与检测,语义分割。图像识别就是告诉你图像是什么,目标定位与检测告诉你图像中目标在哪里,语义分割则是从像素级别回答上面两个问题。因为项目需要对卫星遥感影像中的小麦和玉米进行语义分割,这几天在做相关方向的研究,下面给大家简单介绍下语义分割的相关知识。
## 语义分割是什么
图像语义分割(semantic segmentation),从字面意思上理解就是让计算机根据图像的语义来进行分割,例如让计算机在输入下面左图的情况下,能够输出右图。语义在语音识别中指的是语音的意思,在图像领域,语义指的是图像的内容,对图片意思的理解,比如左图的语义就是三个人骑着三辆自行车;分割的意思是从像素的角度分割出图片中的不同对象,对原图中的每个像素都进行标注,比如右图中粉红色代表人,绿色代表自行车。
## 语义分割当前应用
目前语义分割的应用领域主要有:
* 地理信息系统
* 无人车驾驶
* 医疗影像分析
* 机器人等领域
地理信息系统:可以通过训练神经网络让机器输入卫星遥感影像,自动识别道路,河流,庄稼,建筑物等,并且对图像中每个像素进行标注。(下图左边为卫星遥感影像,中间为真实的标签,右边为神经网络预测的标签结果,可以看到,随着训练加深,预测准确率不断提升。使用ResNet FCN网络进行训练)
无人车驾驶:语义分割也是无人车驾驶的核心算法技术,车载摄像头,或者激光雷达探查到图像后输入到神经网络中,后台计算机可以自动将图像分割归类,以避让行人和车辆等障碍。
医疗影像分析:随着人工智能的崛起,将神经网络与医疗诊断结合也成为研究热点,智能医疗研究逐渐成熟。在智能医疗领域,语义分割主要应用有肿瘤图像分割,龋齿诊断等。(下图分别是龋齿诊断,头部CT扫描紧急护理诊断辅助和肺癌诊断辅助)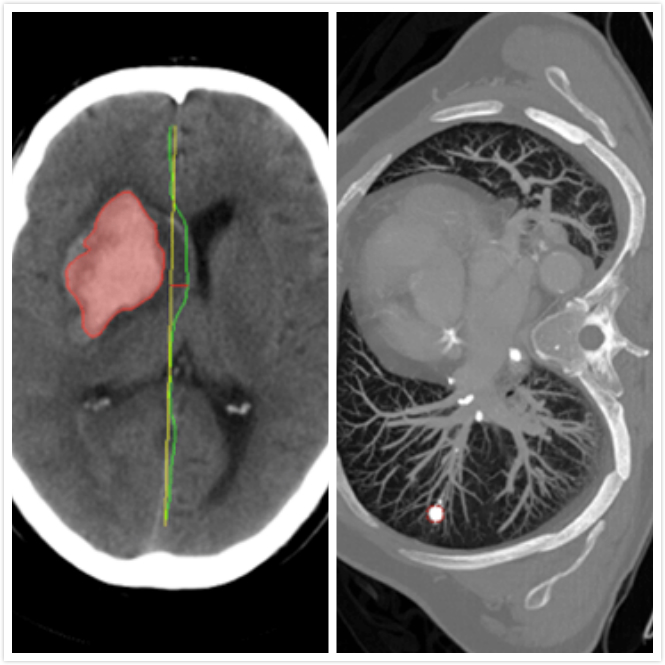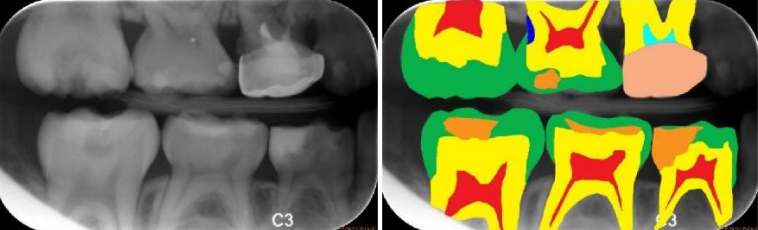
## 语义分割数据集
在“数据,算法,计算力”这AI发展的三大驱动力中,眼下最重要的就是数据,数据集在人工智能中有着[举足轻重](https://www.baidu.com/s?wd=%E4%B8%BE%E8%B6%B3%E8%BD%BB%E9%87%8D&tn=24004469_oem_dg&rsv_dl=gh_pl_sl_csd)的地位,具体根据不同的应用领域,目前的数据集主要有:
1. Pascal VOC系列: [http://host.robots.ox.ac.uk/pascal/VOC/voc2012/](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/) 通常采用PASCAL VOC 2012,最开始有1464 张具有标注信息的训练图片,2014 年增加到10582张训练图片。主要涉及了日常生活中常见的物体,包括汽车,狗,船等20个分类。
2. Microsoft COCO: [http://link.zhihu.com/?target=http%3A//mscoco.org/explore/](http://link.zhihu.com/?target=http%3A//mscoco.org/explore/) 一共有80个类别。这个数据集主要用于实例级别的分割(Instance-level Segmentation)以及图片描述Image Caption)。
3. Cityscapes: [https://www.cityscapes-dataset.com/](https://www.cityscapes-dataset.com/) 适用于汽车自动驾驶的训练数据集,包括19种都市街道场景:road、side-walk、building、wal、fence、pole、traficlight、trafic sign、vegetation、terain、sky、person、rider、car、truck、bus、train、motorcycle 和 bicycle。该数据库中用于训练和校验的精细标注的图片数量为3475,同时也包含了 2 万张粗糙的标记图片。
## 语义分割中的深度学习技术
* 全卷积神经网络 FCN(2015)
论文:[Fully Convolutional Networks for Semantic Segmentation](https://link.zhihu.com/?target=https://arxiv.org/abs/1411.4038) FCN 所追求的是,输入是一张图片是,输出也是一张图片,学习像素到像素的映射,端到端的映射,网络结构如下图所示: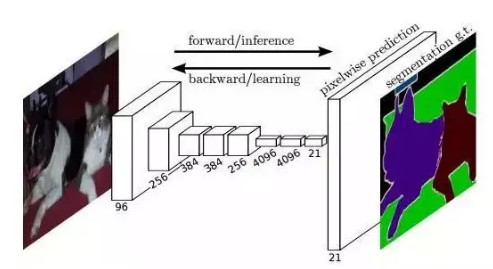
全卷积神经网络主要使用了三种技术:
1. 卷积化(Convolutional)
2. 上采样(Upsample)
3. 跳跃结构(Skip Layer)
卷积化(Convolutional) 卷积化即是将普通的分类网络,比如VGG16,ResNet50/101等网络丢弃全连接层,换上对应的卷积层即可。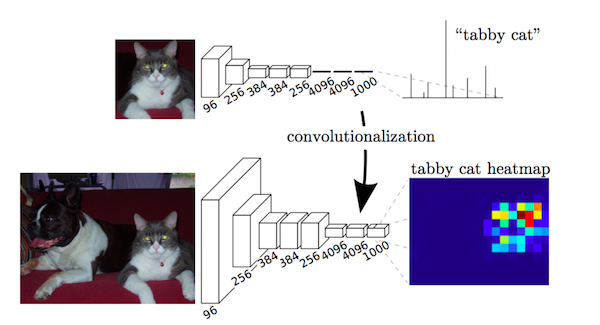
上采样(Upsample) 有的说叫conv\_transpose更为合适。因为普通的池化会缩小图片的尺寸,比如VGG16 五次池化后图片被缩小了32倍。为了得到和原图等大的分割图,我们需要上采样/反卷积。反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和后向传播,只用颠倒卷积的前后向传播即可。图解如下: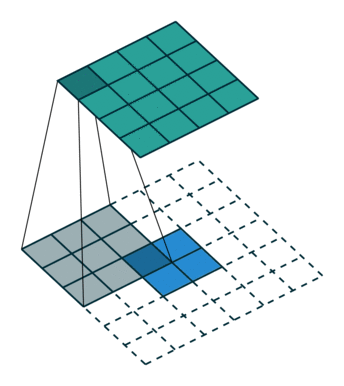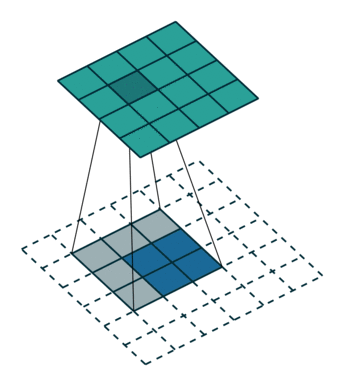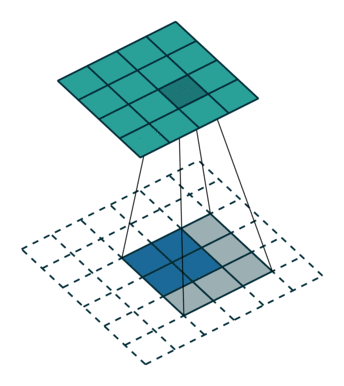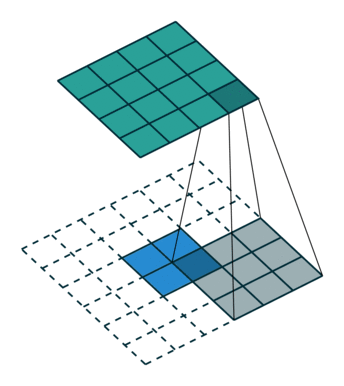
跳跃结构(Skip Layer) 这个结构的作用就在于优化结果,因为如果将全卷积之后的结果直接上采样得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后来优化输出。具体结构如下: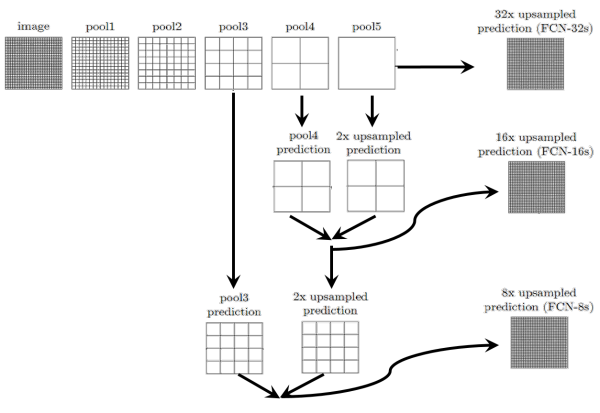而不同上采样结构得到的结果对比如下:
这是第一种结构,也是深度学习应用于图像语义分割的开山之作,获得了CVPR2015的最佳论文。但还是无法避免有很多问题,比如,精度问题,对细节不敏感,以及像素与像素之间的关系,忽略空间的一致性等,后面的研究极大的改善了这些问题。
* SegNet(2015) 论文:[A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation](https://arxiv.org/abs/1511.00561) 主要贡献:将最大池化指数转移至解码器中,改善了分割分辨率。
* 空洞卷积(2015) 论文:[Multi-Scale Context Aggregation by Dilated Convolutions](https://arxiv.org/abs/1511.07122)主要贡献:使用了空洞卷积,这是一种可用于密集预测的卷积层;提出在多尺度聚集条件下使用空洞卷积的“背景模块”。
* DeepLab(2016) 论文:[DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs](https://link.zhihu.com/?target=https://arxiv.org/abs/1606.00915) 主要贡献:使用了空洞卷积;提出了在空间维度上实现金字塔型的空洞池化atrous spatial pyramid pooling(ASPP);使用了全连接[条件随机场](https://www.baidu.com/s?wd=%E6%9D%A1%E4%BB%B6%E9%9A%8F%E6%9C%BA%E5%9C%BA&tn=24004469_oem_dg&rsv_dl=gh_pl_sl_csd)。
参考: 1. [https://blog.csdn.net/sinat_35496345/article/details/79609529](https://blog.csdn.net/sinat_35496345/article/details/79609529)
> 注意: https://zhuanlan.zhihu.com/p/27794982 这篇博文梳理了语义分割的深度学习方法,是根据论文发表的顺序来总结的。大家必须看一下。
# 语义分割要实现的目标:
1. **识别出不同对象**
2. **给出对象边界(像素级别的分类能力)**
所以这一节的论文都是围绕着这一目标来进行改进的。
- 序言
- 第一章 机器学习概述
- 第二章 机器学习环境搭建
- 环境搭建
- 第三章 机器学习之基础算法
- 第一节:基础知识
- 第二节:k近邻算法
- 第三节:决策树算法
- 第四节:朴素贝叶斯
- 第五节:逻辑斯蒂回归
- 第六节:支持向量机
- 第四章 机器学习之深度学习算法
- 第一节: CNN
- 4.1.1 CNN介绍
- 4.1.2 CNN反向传播
- 4.1.3 DNN实例
- 4.1.4 CNN实例
- 第五章 机器学习论文与实践
- 第一节: 语义分割
- 5.1 FCN
- 5.1.1 FCN--------实现FCN16S
- 5.1.2 FCN--------优化FCN16S
- 5.2 DeepLab
- 5.2.1 DeepLabv2
- 第六章 机器学习在实际项目中的应用